

Wichtige Highlights
DeepSeek R1: Mit 671B Parametern und einer Mixture-of-Experts (MoE)-Architektur zeichnet sich DeepSeek R1 durch fortschrittliches logisches Denken und spezialisierte Aufgaben wie Mathematik, Programmierung und Allgemeinwissen aus. Es unterstützt ein 128K-Token-Kontextfenster, benötigt jedoch erhebliche Rechenressourcen.
QWQ 32B: Kompakt und effizient mit 32,5B Parametern ist QwQ-32B für breitere Anwendungen optimiert. Es unterstützt ein 32K-Token-Kontextfenster und verfügt über eine leistungsstarke Transformer-Architektur (RoPE, SwiGLU, RMSNorm). Es bietet schnellere Ausgaben, geringere Hardwareanforderungen und kostengünstige Lösungen für Bildung, Softwareentwicklung und Forschung.
Wenn Sie DeepSeek R1 und QWQ 32B für Ihre eigenen Anwendungsfälle evaluieren möchten – nach der Registrierung erhalten Sie bei Novita AI ein Guthaben von $0,5, um loszulegen!
Dieser Artikel bietet einen praktischen, informativen und technischen Vergleich zweier führender Reasoning-Modelle: DeepSeek R1 und QwQ-32B. Obwohl beide Modelle darauf ausgelegt sind, die KI-Reasoning-Fähigkeiten voranzutreiben, unterscheiden sie sich erheblich in Architektur, Trainingsmethoden und Hardwareanforderungen. Insbesondere wurde QwQ-32B kurz nach DeepSeeks Open-Source-Woche veröffentlicht, was darauf hindeutet, dass es möglicherweise von DeepSeeks Innovationen inspiriert wurde. Dieser Artikel untersucht diese Unterschiede, um Benutzern zu helfen, das Modell zu finden, das am besten zu ihren spezifischen Anforderungen passt.
Grundlegende Einführung der Modelle
Um mit unserem Vergleich zu beginnen, verstehen wir zunächst die grundlegenden Eigenschaften jedes Modells.
DeepSeek R1
- Veröffentlichungsdatum: 21. Januar 2025
- Modellskalierung:
- Hauptmerkmale:
- Modellgröße: 671B Parameter (37B aktiv/Token)
- Tokenizer: Verbesserter Tokenizer mit Self-Reflection-Tags
- Unterstützte Sprachen: Mehrsprachig mit kultureller Anpassung
- Multimodal: Nur Text
- Kontextfenster: 128K Tokens
- Speicherformate: Unterstützung für Q8/Q5-Quantisierung
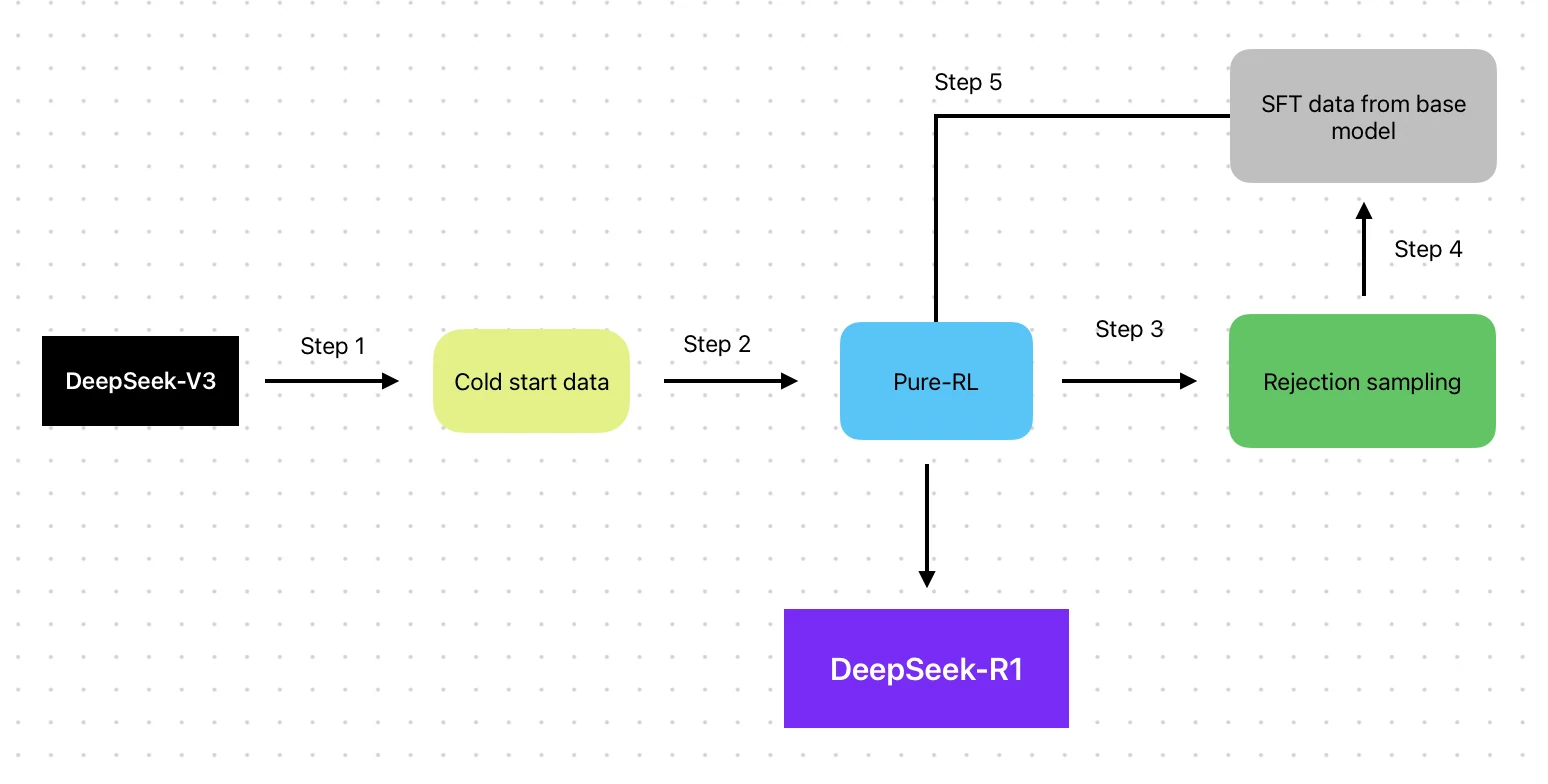
- Architektur: Mixture of Experts (MoE) + RL-verbesserte Trainingspipeline
- Trainingsmethode: Auf V3-Basis mit RL-Pipeline (SFT → RL → SFT → RL)
- Trainingsdaten: V3-Basis + RL-Optimierungsdaten
QWQ 32B
- Veröffentlichungsdatum: 5. März 2025
- Modellskalierung:
- Hauptmerkmale:
- Modellgröße: Insgesamt 32,5 Milliarden Parameter, davon 31,0 Milliarden Nicht-Embedding-Parameter.
- Unterstützte Sprachen: Deckt über 29 Sprachen ab für globale Zugänglichkeit und Anwendung.
- Multimodal: Nur Text
- Kontextfenster: Unterstützt bis zu 32.768 Tokens.
- Architektur: QwQ-32B verwendet eine Transformer-Architektur mit 64 Schichten, 40 Attention-Heads für Queries und 8 für Key-Values. Basierend auf Transformern mit RoPE (Rotary Positional Embeddings) integriert QwQ-32B die SwiGLU-Aktivierungsfunktion, verwendet RMSNorm zur Normalisierung und beinhaltet Bias in den Attention-QKV-Berechnungen.
QwQ-32B konzentriert sich auf reine RL-Optimierung für Effizienz und Unabhängigkeit.
DeepSeek R1 integriert sowohl SFT als auch RL in einem ausgewogenen, iterativen Prozess, behält aber eine teilweise SFT-Abhängigkeit bei.
Geschwindigkeitsvergleich
Wenn Sie es selbst testen möchten, starten Sie eine kostenlose Testversion auf der Novita AI Website.
Jetzt DeepSeek R1 und QWQ 32B Demo testen!
Geschwindigkeitsvergleich
Kostenvergleich
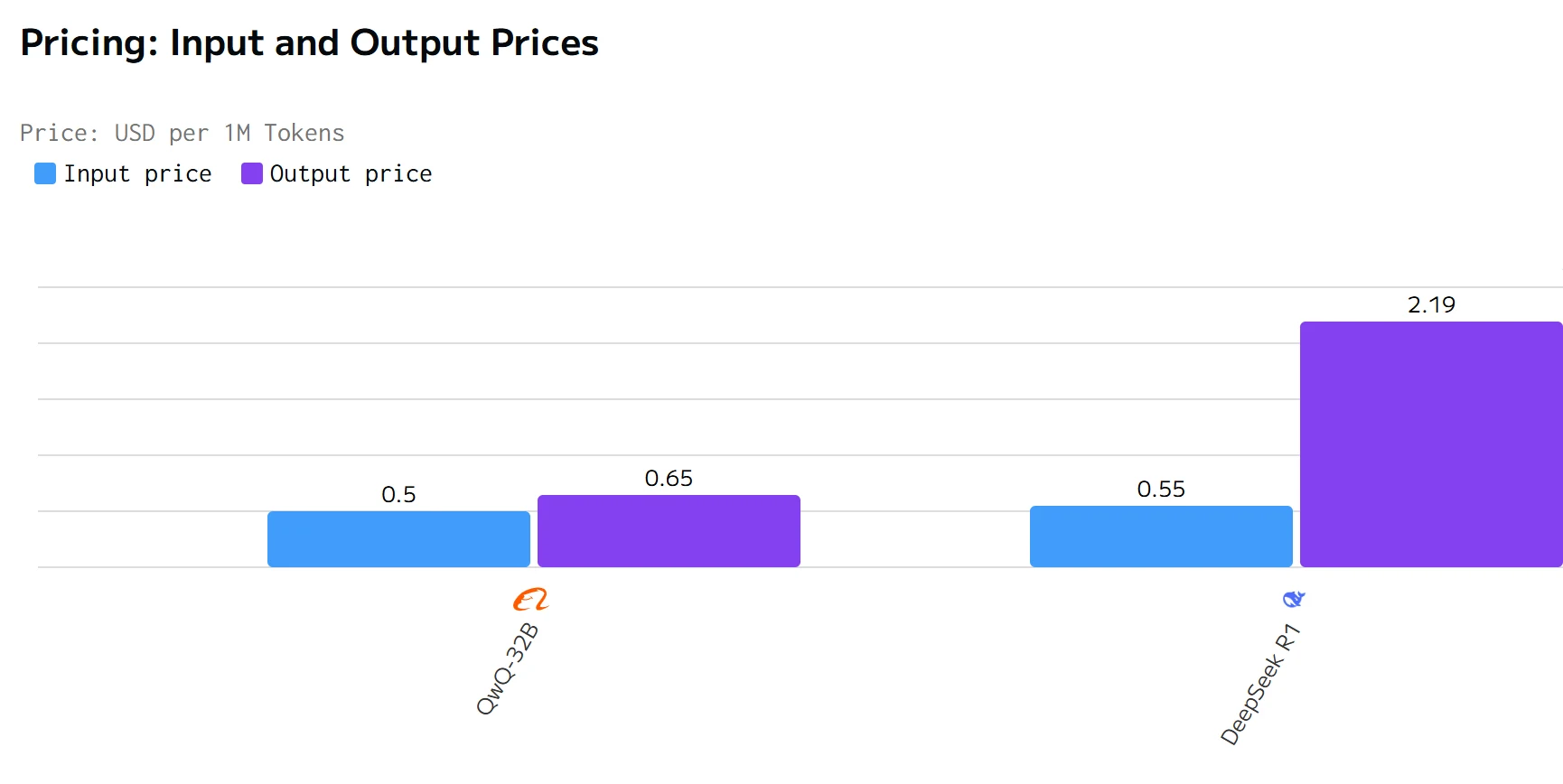
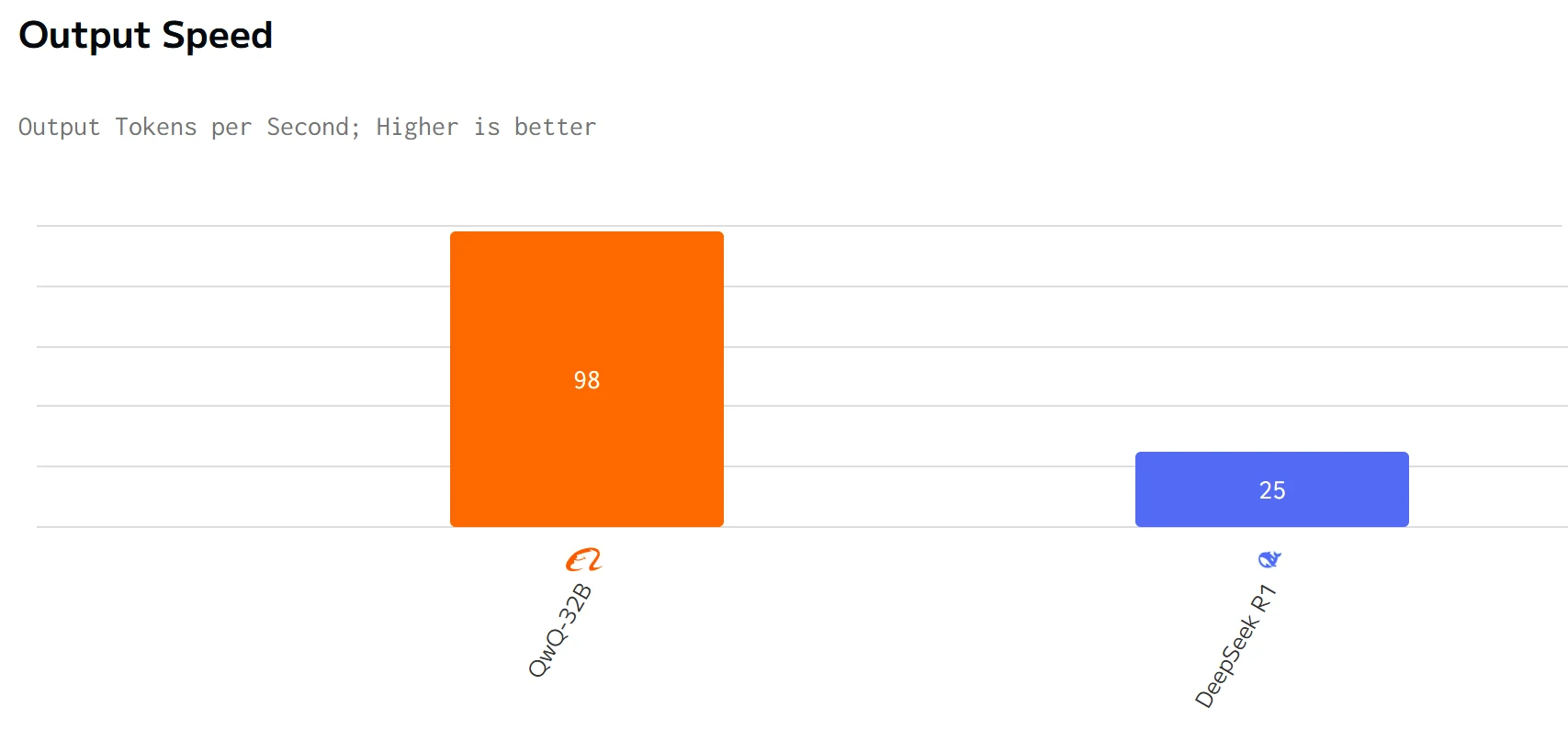
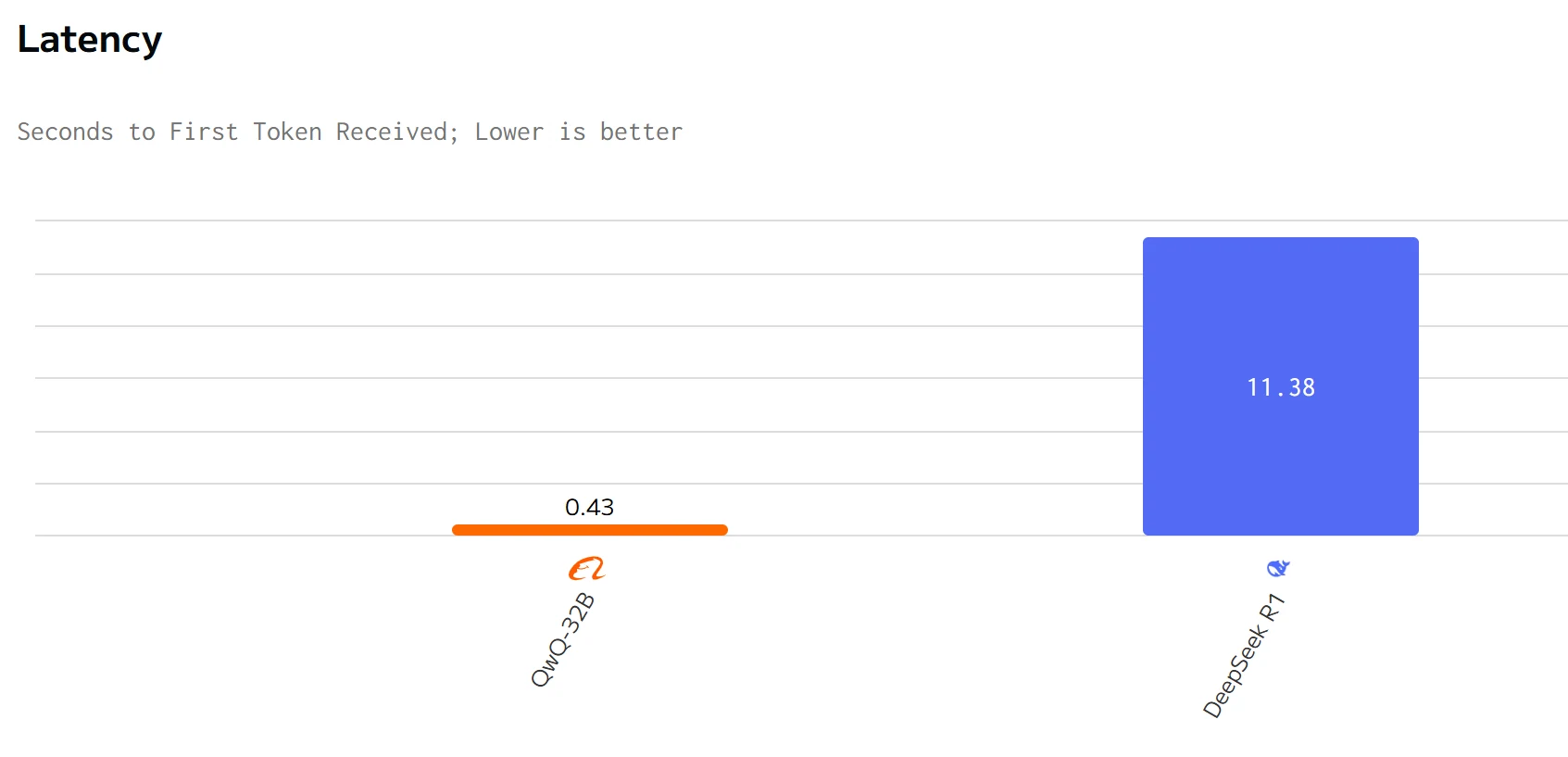
QWQ 32B übertrifft DeepSeek R1 in Ausgabegeschwindigkeit und Latenz. Die Eingabe- und Ausgabepreise von DeepSeek R1 sind deutlich höher als die von QWQ 32B.
Es ist erwähnenswert, dass Novita AI eine Turbo-Version mit 3-fachem Durchsatz und einem zeitlich begrenzten Rabatt von 20% anbietet!

Benchmark-Vergleich
Nachdem wir die grundlegenden Eigenschaften jedes Modells dargelegt haben, wollen wir uns nun mit ihrer Leistung in verschiedenen Benchmarks befassen. Dieser Vergleich hilft, ihre Stärken in verschiedenen Bereichen zu veranschaulichen.
| Benchmark | DeepSeek-R1 (%) | QWQ 32B (%) |
|---|---|---|
| LiveCodeBench (Programmierung) | 62 | 22 |
| GPQA Diamond | 71 | 59 |
| MATH-500 | 96 | 91 |
| MMLU-Pro | 84 | 76 |
Diese Ergebnisse deuten darauf hin, dass der maschinengesteuerte iterative Verstärkungslernansatz von DeepSeek R1 besonders effektiv sein könnte, um stärkere Fähigkeiten in spezialisierten technischen Bereichen zu entwickeln, die präzises Denken und strukturierte Problemlösungsfähigkeiten erfordern.
Wenn Sie weitere Vergleiche sehen möchten, können Sie sich diese Artikel ansehen:
- Deepseek v3 vs Llama 3.3 70b: Sprachaufgaben vs. Code & Mathematik
- DeepSeek R1 vs OpenAI o1: Unterschiedliche Architekturen von GRPO und PPO
- QwQ 32B: Ein kompakter KI-Konkurrent zu DeepSeek R1
Hardwareanforderungen
| Modell | Parametergröße | GPU-Konfiguration |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4,9B | 1 x NVIDIA RTX 4090 (24GB VRAM) mit Model Sharding |
| DeepSeek-R1-Distill-Qwen-14B | 9,0B | 1 x NVIDIA A100 (80GB VRAM) oder 2 x RTX 4090 (24GB VRAM) mit Tensor Parallelism |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 2 x NVIDIA A100 (80GB VRAM) oder 1 x NVIDIA H100 (80GB VRAM) oder 4 x RTX 4090 (24GB VRAM) mit Tensor Parallelism |
| DeepSeek-R1-Distill-Llama-70B | 70B | 4 x NVIDIA A100 (80GB VRAM) oder 2 x NVIDIA H100 (80GB VRAM) oder 8 x RTX 4090 (24GB VRAM) mit starkem Parallelismus |
| DeepSeek-R1:671B | 671B (37 Milliarden aktive Parameter) | 16 x NVIDIA A100 (80GB VRAM) oder 8 x NVIDIA H100 (80GB VRAM), erfordert einen verteilten GPU-Cluster mit InfiniBand |
| QwQ-32B (4-Bit-Präzision) | 32B | 1 x NVIDIA RTX 3090/4090 (24GB VRAM), kompatibel mit 4-Bit-Quantisierung |
| 1 x NVIDIA RTX 6000 (48GB VRAM), kompatibel mit 4-Bit-Quantisierung | ||
| 1 x NVIDIA H100 (80GB VRAM) oder 2 x NVIDIA A100 (80GB VRAM) |
Anwendungen und Anwendungsfälle
DeepSeek R1
- Mathematik: Kann fortgeschrittene mathematische Probleme lösen, einschließlich symbolischem Denken, Gleichungslösung und Optimierungsaufgaben, und eignet sich daher gut für MINT-bezogene Anwendungen.
- Programmierung: Hervorragend geeignet zum Generieren komplexen Codes, Verstehen komplizierter Logik und Debuggen großer Softwareprojekte – ein wertvolles Werkzeug für Entwickler und Ingenieure.
- Allgemeinwissen: Zeigt starkes Denkvermögen in einem breiten Themenspektrum und ist ideal für Aufgaben, die tiefes Verständnis und genaue Synthese verschiedener Wissensdomänen erfordern.
QWQ 32B
- Bildung: Bietet hochgradig personalisierte Nachhilfe in Mathematik und Programmierung mit schrittweisen Erklärungen und adaptivem Lernen basierend auf dem Fortschritt und den Bedürfnissen des Benutzers.
- Softwareentwicklung: Unterstützt Entwickler durch das Generieren genauer und effizienter Code-Snippets, das Debuggen von Fehlern und das Anbieten von Optimierungs- und Leistungsverbesserungsempfehlungen.
- Forschung: Unterstützt Forscher mit fortgeschrittener Datenanalyse, Zusammenfassung akademischer Literatur und Einblicken in komplexe Datensätze – ein leistungsstarker Assistent für Forschungsaufgaben.
Zugänglichkeit und Bereitstellung über Novita AI
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig die erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Loggen Sie sich in Ihr Konto ein und klicken Sie auf die Schaltfläche Modellbibliothek.

Jetzt DeepSeek R1 und QWQ 32B Demo testen!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Einstellungen“ und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Nach der Registrierung stellt Novita AI ein Guthaben von $0,5 zur Verfügung, um loszulegen!
Wenn das kostenlose Guthaben aufgebraucht ist, können Sie bezahlen und weiter nutzen.
Sowohl DeepSeek R1 als auch QwQ-32B sind fortschrittliche Reasoning-Modelle mit jeweils einzigartigen Stärken.
- DeepSeek R1: Mit seiner großen Parameterzahl und der MoE-Architektur (Mixture of Experts) ist es für hochkomplexe Reasoning-Aufgaben konzipiert. Diese Fähigkeit geht jedoch mit einem erheblichen Bedarf an Rechenressourcen einher.
- QwQ-32B: Im Gegensatz dazu bietet QwQ-32B eine kompaktere und hardwareeffizientere Lösung, die konkurrierende Leistung liefert und gleichzeitig auf weniger anspruchsvollen Hardware-Setups zugänglich ist.
Die Entscheidung zwischen den beiden Modellen hängt letztendlich von den spezifischen Anwendungsanforderungen, der verfügbaren Hardware und dem Budget ab.
Häufig gestellte Fragen
Was macht QwQ-32B einzigartig?
QwQ-32B zeichnet sich durch die Verwendung von Reinforcement Learning ohne überwachtes Feintuning aus und erzielt außergewöhnliche Leistungen bei Reasoning-Aufgaben, insbesondere in Mathematik und Programmierung.
Was ist der Hauptunterschied zwischen QwQ-32B und Qwen2.5?
QwQ-32B baut auf Qwen2.5 auf und fügt eine Reinforcement-Learning-Optimierung speziell für Reasoning-Aufgaben hinzu, ohne traditionelle überwachte Feintuning-Ansätze zu verwenden.
Wie kann ich QWQ 32B über die API nutzen?
Novita AI bietet Ihnen die erschwingliche und zuverlässige QWQ 32B API an.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, Serverless, GPU-Instanz – die kosteneffektiven Tools, die Sie brauchen. Verzichten Sie auf Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



