

主なハイライト
DeepSeek R1: 671BパラメータとMixture of Experts (MoE) アーキテクチャを備えたDeepSeek R1は、数学、コーディング、一般知識といった高度な推論および専門タスクに優れています。128Kトークンのコンテキストウィンドウをサポートしますが、かなりの計算リソースが必要です。
QWQ 32B: 32.5Bパラメータのコンパクトで効率的なモデルであるQwQ-32Bは、幅広いアプリケーション向けに最適化されています。32Kトークンのコンテキストウィンドウをサポートし、高性能トランスフォーマーアーキテクチャ(RoPE、SwiGLU、RMSNorm)を採用。高速な出力、低いハードウェア要件、教育・ソフトウェア開発・研究分野におけるコスト効率の高いソリューションを提供します。
ご自身のユースケースでDeepSeek R1とQWQ 32Bを評価したい場合 — ご登録いただくと、Novita AI から0.5ドルのクレジットを提供いたします。これを使ってすぐに始められます!
この記事では、2つの主要な推論モデル、DeepSeek R1とQwQ-32Bについて、実用的かつ情報豊富で技術的な比較を行います。どちらのモデルもAIの推論能力を向上させるために設計されていますが、アーキテクチャ、トレーニング方法、ハードウェア要件において大きく異なります。特に、QwQ-32BはDeepSeekのオープンソース週間の直後にリリースされており、DeepSeekの革新からヒントを得ている可能性があります。この記事では、これらの違いを探り、ユーザーが自分の特定のニーズに最適なモデルを判断するのに役立てます。
モデルの基本紹介
比較を始めるにあたり、まず各モデルの基本的な特徴を理解しましょう。
DeepSeek R1
- リリース日:2025年1月21日
- モデル規模:
- 主な特徴:
- モデルサイズ:671Bパラメータ(アクティブパラメータは37B/トークン)
- トークナイザー:自己内省タグを備えた拡張トークナイザー
- 対応言語:多言語、文化適応対応
- マルチモーダル:テキストのみ
- コンテキストウィンドウ:128Kトークン
- ストレージ形式:Q8/Q5量子化サポート
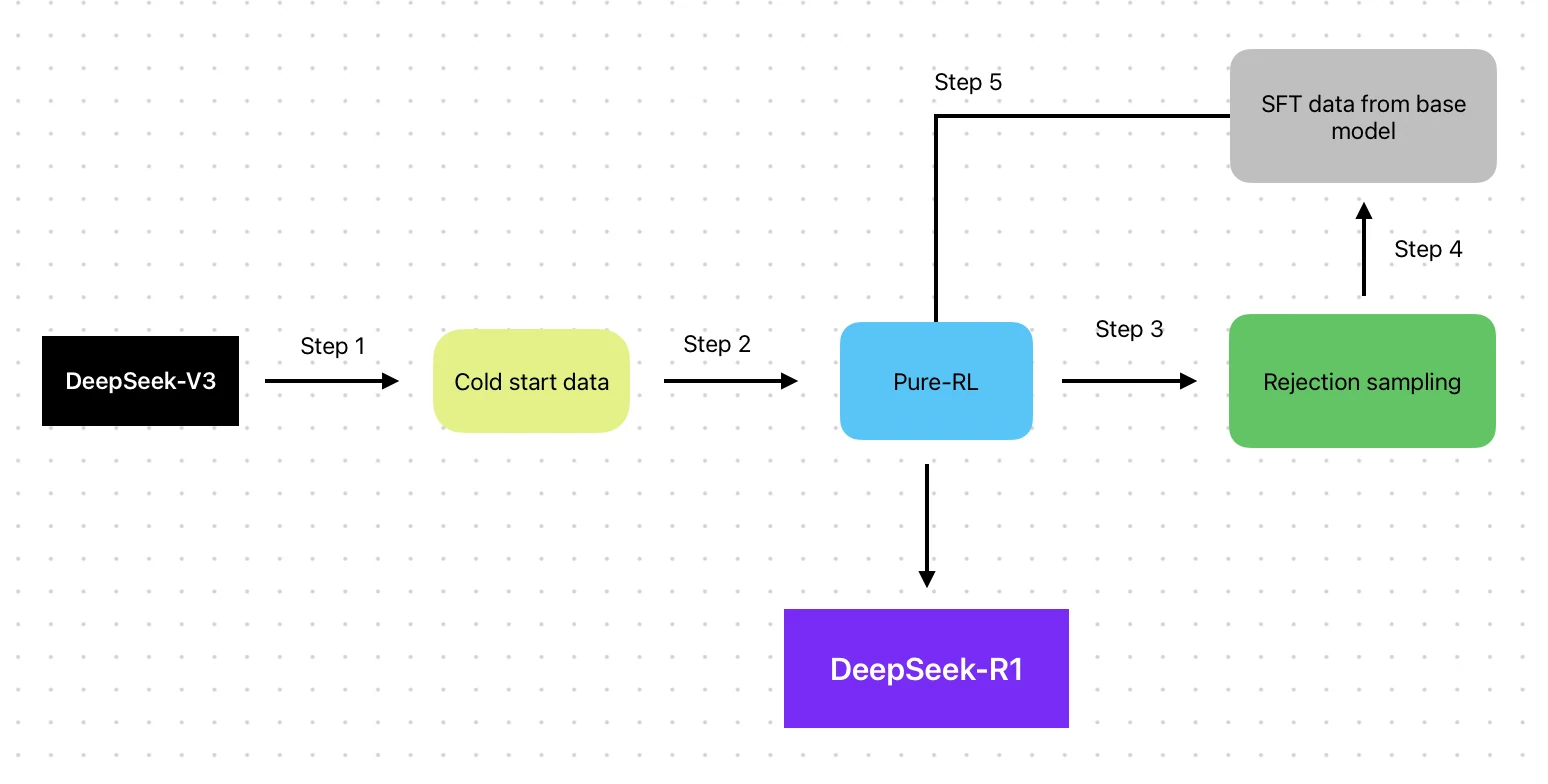
- アーキテクチャ:Mixture of Experts (MoE) + 強化学習強化トレーニングパイプライン
- トレーニング手法:V3ベースにRLパイプライン(SFT → RL → SFT → RL)を構築
- トレーニングデータ:V3ベース + RL最適化データ
QWQ 32B
- リリース日:2025年3月5日
- モデル規模:
- 主な特徴:
- モデルサイズ:合計325億パラメータ、うち310億が非埋め込みパラメータ。
- 対応言語:29以上の言語をカバーし、グローバルなアクセスと応用を実現。
- マルチモーダル:テキストのみ
- コンテキストウィンドウ:最大32,768トークンをサポート。
- アーキテクチャ:QwQ-32Bは、64層、クエリ用40アテンションヘッド、キーバリュー用8アテンションヘッドを持つトランスフォーマーアーキテクチャを採用。RoPE(回転位置埋め込み)、SwiGLU活性化関数、RMSNorm正規化、アテンションQKV計算におけるバイアスを統合。
QwQ-32B は、効率と独立性を重視したRLのみの最適化に焦点を当てています。
DeepSeek R1 は、SFTとRLの両方をバランスよく反復プロセスで統合していますが、部分的なSFTへの依存を残しています。
速度比較
ご自身でテストしたい場合は、Novita AIのウェブサイトで無料トライアルを開始できます。
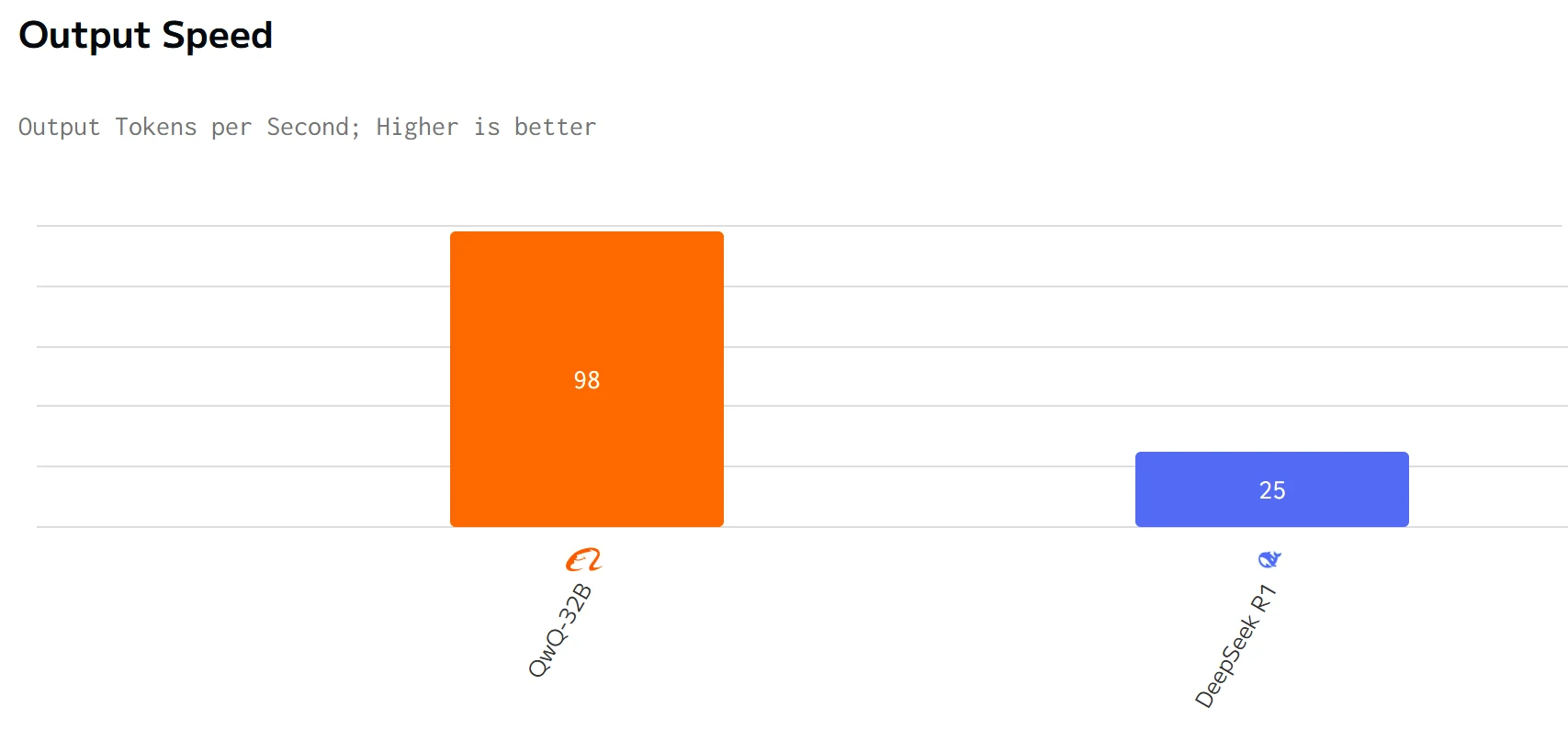
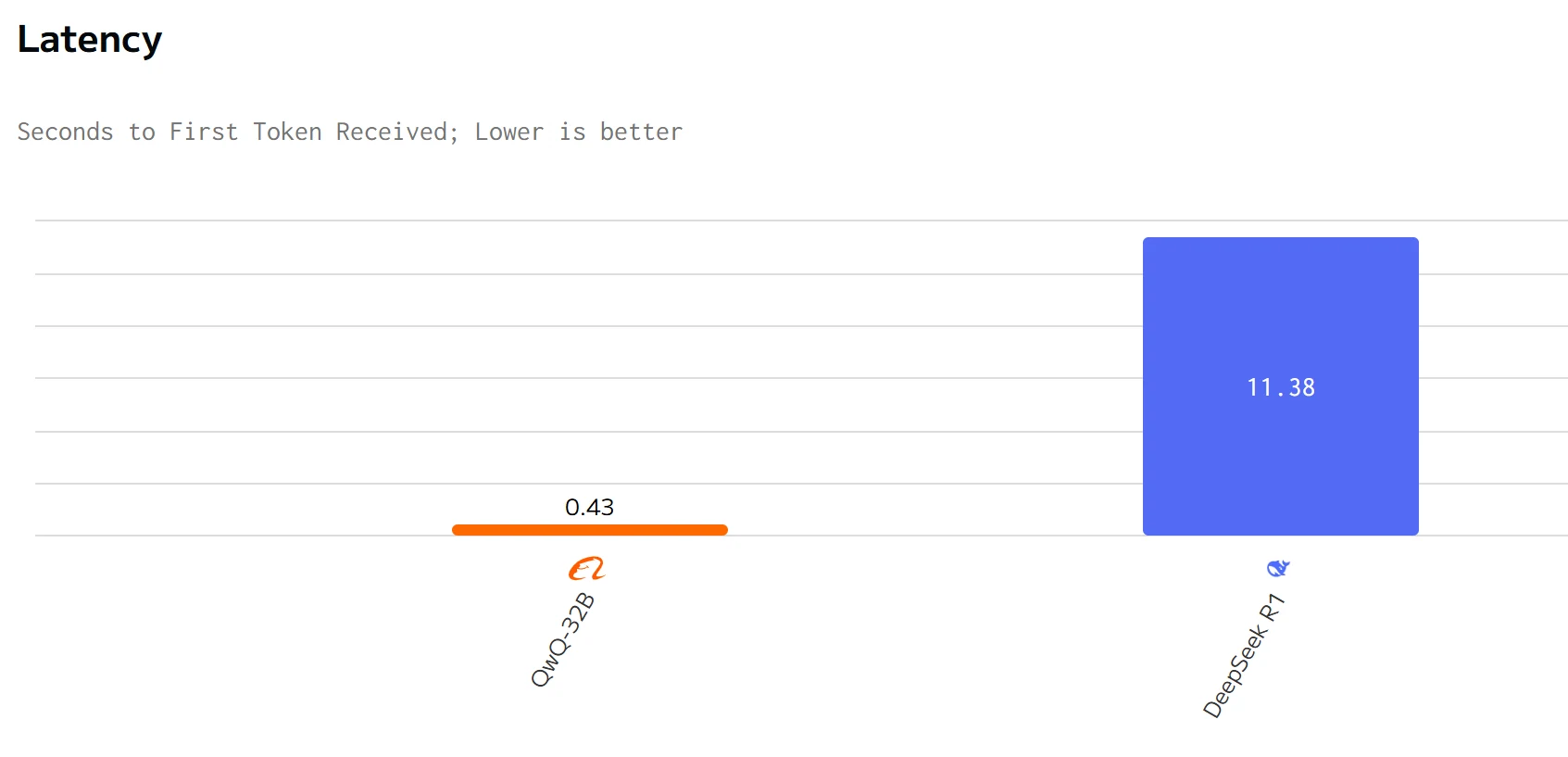
速度比較
コスト比較
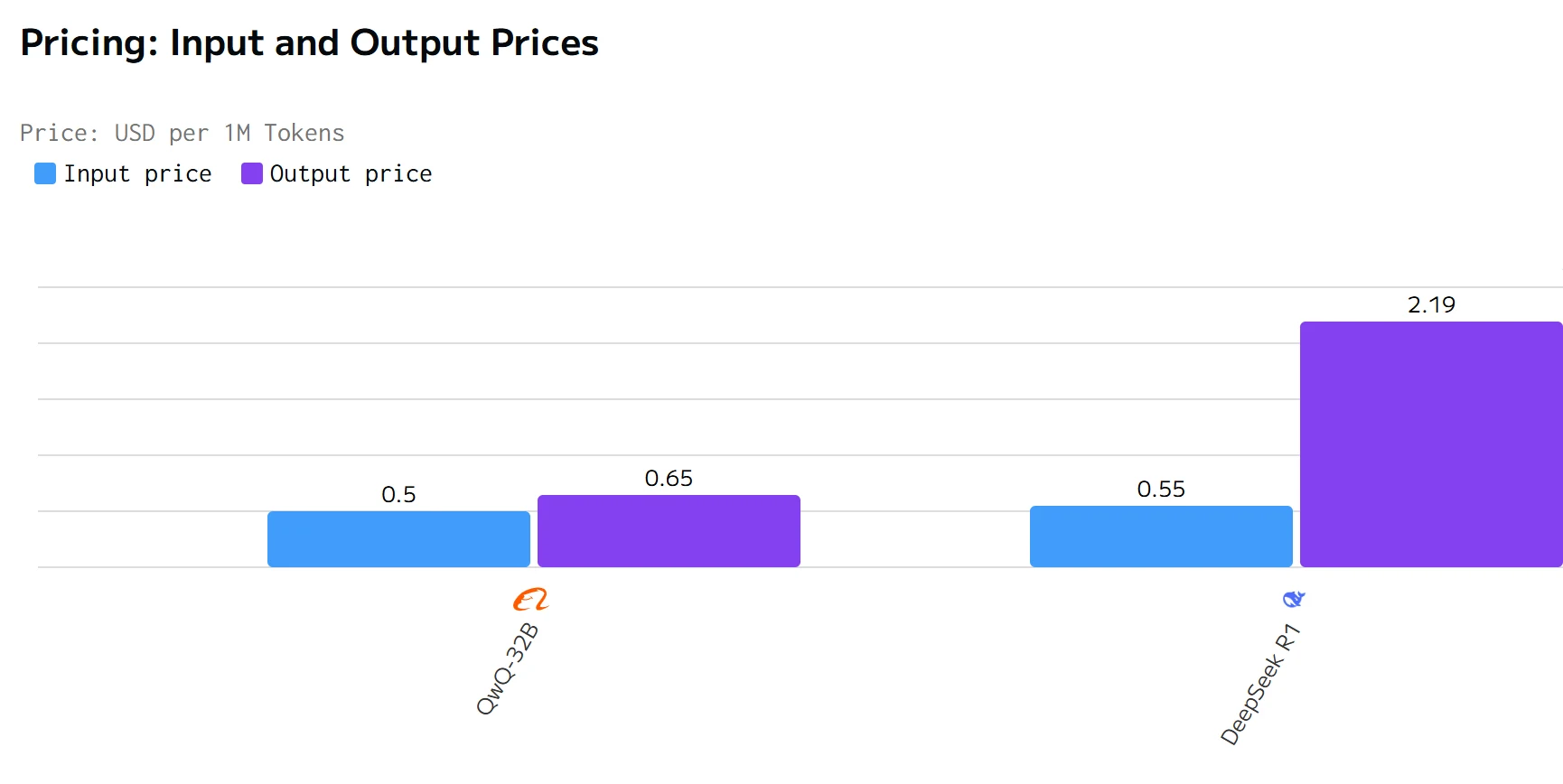
QWQ 32Bは、出力速度とレイテンシにおいてDeepSeek R1を上回っています。DeepSeek R1の入力および出力価格は、QWQ 32Bよりも大幅に高くなっています。
Novita AIは、3倍のスループットと期間限定20%割引のTurboバージョンを提供していることに注目してください!

ベンチマーク比較
各モデルの基本的な特性を確認したところで、さまざまなベンチマークにおけるパフォーマンスを詳しく見ていきましょう。この比較は、それぞれの強みを明確にするのに役立ちます。
| ベンチマーク | DeepSeek-R1 (%) | QWQ 32B (%) |
|---|---|---|
| LiveCodeBench(コーディング) | 62 | 22 |
| GPQA Diamond | 71 | 59 |
| MATH-500 | 96 | 91 |
| MMLU-Pro | 84 | 76 |
これらの結果は、DeepSeek R1の機械駆動型反復強化学習アプローチが、正確な推論と構造化された問題解決スキルを必要とする専門的な技術領域において、特に強力な能力を発揮するのに効果的である可能性を示唆しています。
さらに比較をご覧になりたい場合は、以下の記事もご参照ください。
- Deepseek v3 vs Llama 3.3 70b:言語タスク vs コード・数学
- DeepSeek R1 vs OpenAI o1:GRPOとPPOの異なるアーキテクチャ
- QwQ 32B:DeepSeek R1に対抗するコンパクトAI
ハードウェア要件
| **モデル ** | ** パラメータサイズ ** | GPU構成 |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4.9B | 1 x NVIDIA RTX 4090(24GB VRAM)、モデルシャーディング使用 |
| DeepSeek-R1-Distill-Qwen-14B | 9.0B | 1 x NVIDIA A100(80GB VRAM)または2 x RTX 4090(24GB VRAM)、テンソル並列処理使用 |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 2 x NVIDIA A100(80GB VRAM)または1 x NVIDIA H100(80GB VRAM)または4 x RTX 4090(24GB VRAM)、テンソル並列処理使用 |
| DeepSeek-R1-Distill-Llama-70B | 70B | 4 x NVIDIA A100(80GB VRAM)または2 x NVIDIA H100(80GB VRAM)または8 x RTX 4090(24GB VRAM)、高度な並列処理使用 |
| DeepSeek-R1:671B | 671B(アクティブパラメータ370億) | 16 x NVIDIA A100(80GB VRAM)または8 x NVIDIA H100(80GB VRAM)、InfiniBand対応の分散GPUクラスタが必要 |
| QwQ-32B(4ビット精度) | 32B | 1 x NVIDIA RTX 3090/4090(24GB VRAM)、4ビット量子化対応 |
| 1 x NVIDIA RTX 6000(48GB VRAM)、4ビット量子化対応 | ||
| 1 x NVIDIA H100(80GB VRAM)または2 x NVIDIA A100(80GB VRAM) |
アプリケーションとユースケース
DeepSeek R1
- 数学: 記号推論、方程式解法、最適化タスクを含む高度な数学的問題を解決でき、STEM関連アプリケーションに最適です。
- コーディング: 複雑なコードの生成、複雑なロジックの理解、大規模ソフトウェアプロジェクトのデバッグに優れており、開発者やエンジニアにとって貴重なツールとなります。
- 一般知識: 幅広いトピックにわたる強力な推論力を発揮し、深い理解と多様な知識領域の正確な統合を必要とするタスクに最適です。
QWQ 32B
- 教育: 数学とプログラミングにおいて高度にパーソナライズされた個別指導を提供し、ユーザーの進捗とニーズに基づいたステップバイステップの説明と適応型学習を実現します。
- ソフトウェア開発: 正確で効率的なコードスニペットの生成、エラーのデバッグ、コードパフォーマンスの最適化と改善のための推奨事項を提供することで、開発者を支援します。
- 研究: 高度なデータ分析、学術文献の要約、複雑なデータセットへの洞察を提供し、研究タスクの強力なアシスタントとして機能します。
Novita AI によるアクセシビリティとデプロイ
Novita AI は、シンプルなAPIを使用してAIモデルを簡単にデプロイできる機能を開発者に提供するとともに、構築とスケーリングのための手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、「Model Library」 ボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
ステップ3:無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
ステップ4:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「Settings」 ページに進み、画像の指示に従ってAPIキーをコピーできます。

ステップ5:APIをインストール
使用するプログラミング言語に応じたパッケージマネージャーを使用してAPIをインストールします。

インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。以下は、Pythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
ご登録いただくと、Novita AIから0.5ドルのクレジットが提供され、すぐに始められます!
無料クレジットを使い切った場合は、課金して引き続きご利用いただけます。
DeepSeek R1 と QwQ-32B は、どちらも高度な推論モデルであり、それぞれに独自の強みがあります。
- DeepSeek R1: 大規模なパラメータサイズとMoE(Mixture of Experts)アーキテクチャにより、非常に複雑な推論タスクを処理するように設計されています。ただし、この能力には相当な計算リソースが必要です。
- QwQ-32B: 対照的に、QwQ-32Bはよりコンパクトでハードウェア効率の高いソリューションを提供し、競争力のあるパフォーマンスを発揮しながら、それほど要求の厳しくないハードウェア設定でもアクセス可能です。
2つのモデルの選択は、最終的には特定のアプリケーション要件、利用可能なハードウェア、および予算の考慮事項に依存します。
よくある質問
QwQ-32Bの独自性は何ですか?
QwQ-32Bは、教師ありファインチューニングを行わずに強化学習を採用している点で際立っており、特に数学やコーディングにおける推論タスクで優れたパフォーマンスを発揮します。
QwQ-32BとQwen2.5の主な違いは何ですか?
QwQ-32BはQwen2.5をベースに、従来の教師ありファインチューニングアプローチを使用せずに、推論タスク向けに強化学習の最適化を追加しています。
APIを介してQWQ 32Bにアクセスするにはどうすればよいですか?
Novita AI が、手頃で信頼性の高いQWQ 32B APIを提供しています。
Novita AI は、AIの野心を実現するオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — コスト効率の高いツールを提供します。インフラストラクチャを排除し、無料で開始して、AIのビジョンを現実にしましょう。



