

Points clés
DeepSeek R1 : Avec ses 671B paramètres et une architecture Mixture of Experts (MoE), DeepSeek R1 excelle dans le raisonnement avancé et les tâches spécialisées comme les mathématiques, le codage et les connaissances générales. Il prend en charge une fenêtre de contexte de 128K tokens mais nécessite des ressources de calcul importantes.
QWQ 32B : Compact et efficace avec 32,5B paramètres, QwQ-32B est optimisé pour des applications plus larges. Il prend en charge une fenêtre de contexte de 32K tokens et dispose d’une architecture transformer haute performance (RoPE, SwiGLU, RMSNorm). Il offre des sorties plus rapides, des besoins matériels réduits et des solutions économiques pour l’éducation, le développement logiciel et la recherche.
Si vous souhaitez évaluer DeepSeek R1 et QWQ 32B pour vos propres cas d’usage — lors de votre inscription, Novita AI vous offre un crédit de 0,5 $ pour démarrer !
Cet article propose une comparaison pratique, informative et technique de deux modèles de raisonnement leaders : DeepSeek R1 et QwQ-32B. Bien que les deux modèles soient conçus pour faire progresser les capacités de raisonnement de l’IA, ils diffèrent considérablement par leur architecture, leurs méthodes d’entraînement et leurs besoins matériels. Notamment, QwQ-32B a été lancé peu après la semaine open source de DeepSeek, ce qui suggère qu’il pourrait s’être inspiré des innovations de DeepSeek. Cet article explore ces distinctions pour aider les utilisateurs à déterminer quel modèle correspond le mieux à leurs besoins spécifiques.
Présentation générale des modèles
Pour commencer notre comparaison, comprenons d’abord les caractéristiques fondamentales de chaque modèle.
DeepSeek R1
- Date de sortie : 21 janvier 2025
- Échelles du modèle :
- Caractéristiques principales :
- Taille du modèle : 671B paramètres (37B actifs/token)
- Tokenizer : Tokenizer amélioré avec balises d’autoréflexion
- Langues supportées : Multilingue avec adaptation culturelle
- Multimodal : Texte uniquement
- Fenêtre de contexte : 128K tokens
- Formats de stockage : Prise en charge de la quantification Q8/Q5
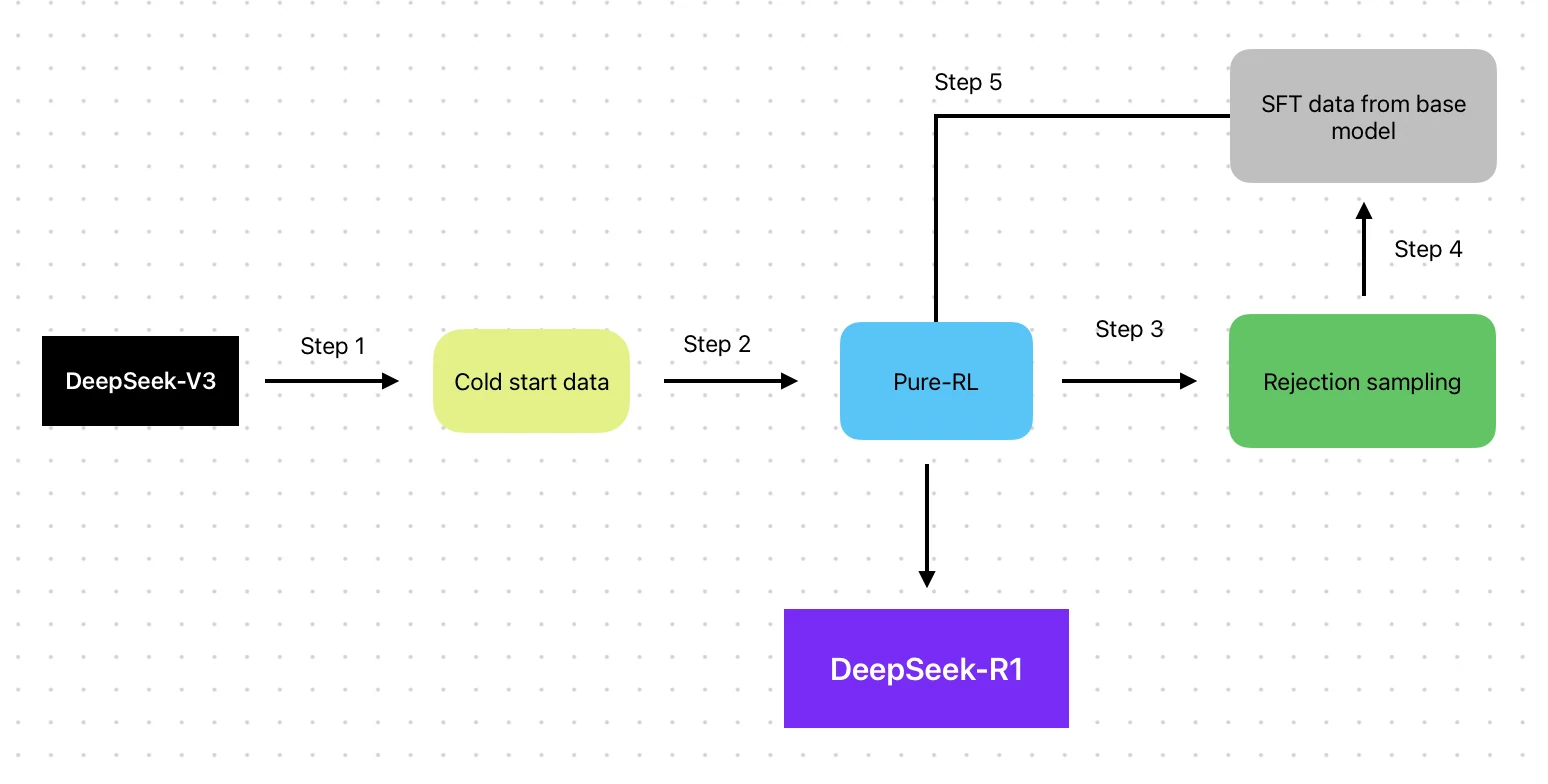
- Architecture : Mixture of Experts (MoE) + pipeline d’entraînement renforcé par RL
- Méthode d’entraînement : Basé sur V3 avec pipeline RL (SFT → RL → SFT → RL)
- Données d’entraînement : Base V3 + données d’optimisation RL
QWQ 32B
- Date de sortie : 5 mars 2025
- Échelles du modèle :
- Caractéristiques principales :
- Taille du modèle : 32,5 milliards de paramètres au total, dont 31,0 milliards pour les paramètres hors embedding.
- Langues supportées : Couvre plus de 29 langues pour une accessibilité et une application mondiales.
- Multimodal : Texte uniquement
- Fenêtre de contexte : Prend en charge jusqu’à 32 768 tokens.
- Architecture : QwQ-32B utilise une architecture transformer avec 64 couches, 40 têtes d’attention pour les requêtes et 8 pour les clés-valeurs. Construit sur des transformers avec RoPE (Rotary Positional Embeddings), QwQ-32B intègre la fonction d’activation SwiGLU, utilise RMSNorm pour la normalisation et inclut un biais dans les calculs QKV de l’attention.
QwQ-32B se concentre sur une optimisation uniquement par RL pour plus d’efficacité et d’indépendance.
DeepSeek R1 intègre à la fois SFT et RL dans un processus équilibré et itératif, mais conserve une dépendance partielle à SFT.
Comparaison de vitesse
Si vous souhaitez le tester vous-même, vous pouvez lancer un essai gratuit sur le site Novita AI.
Essayez DeepSeek R1 et QWQ 32B dès maintenant !
Comparaison de vitesse
Comparaison des coûts
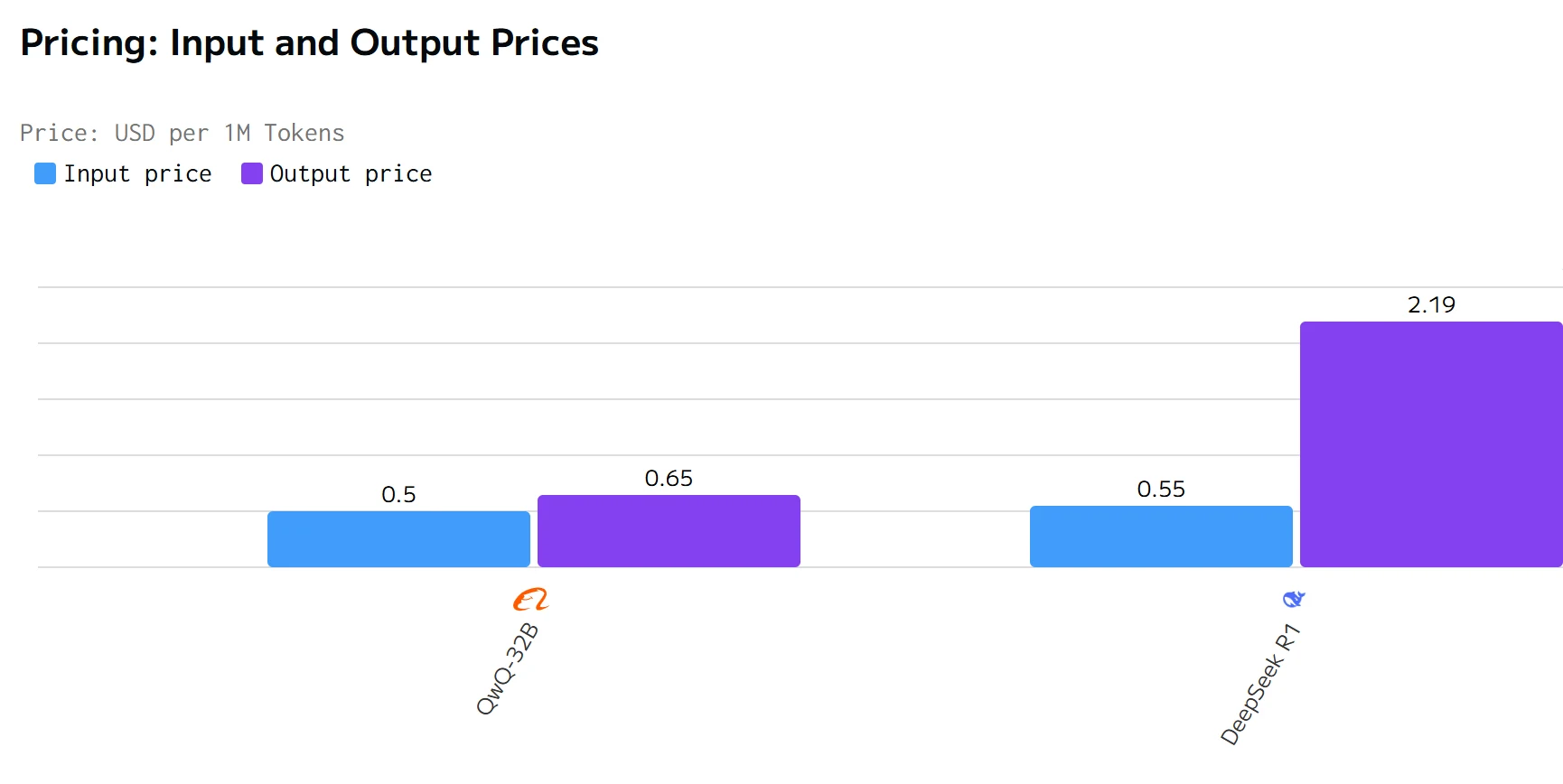
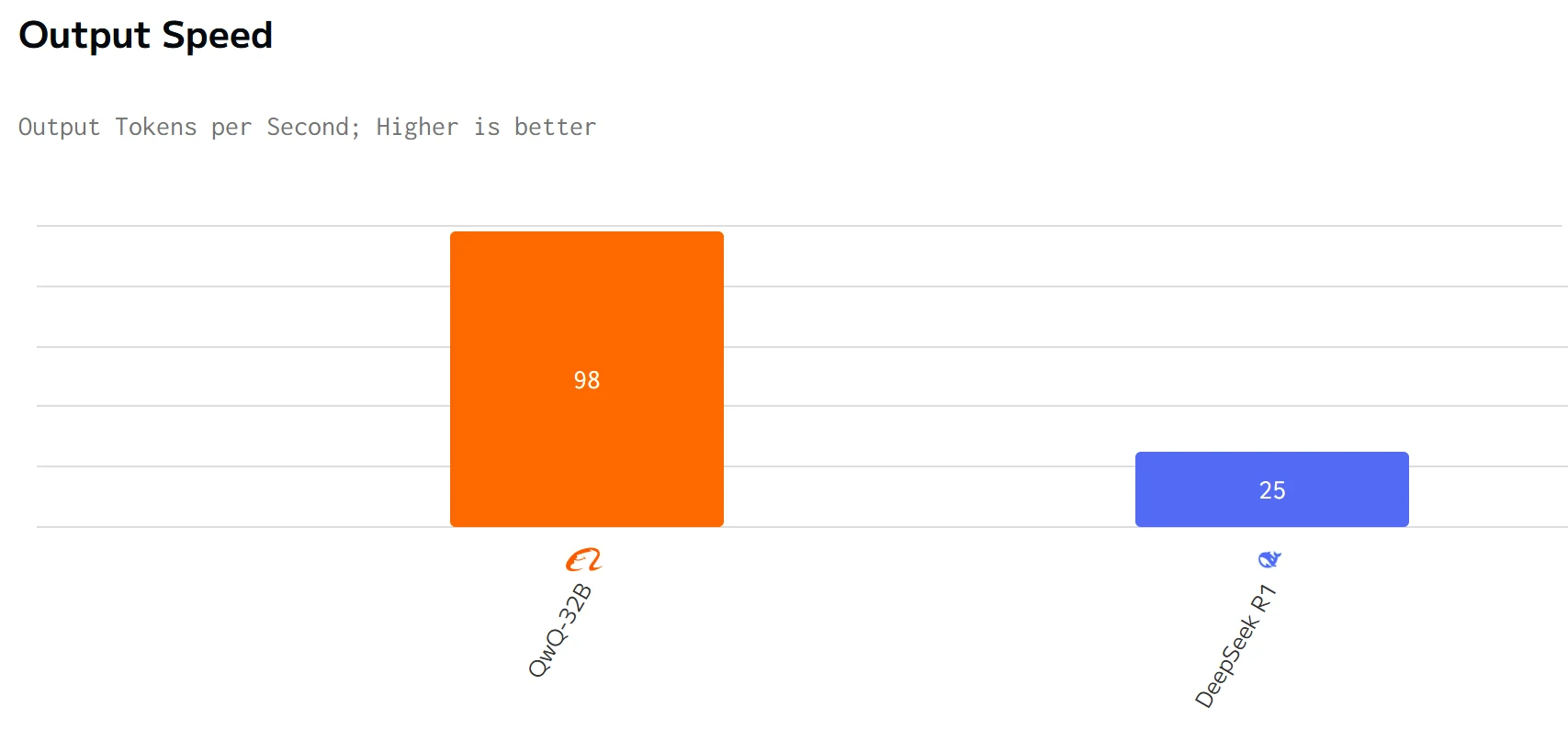
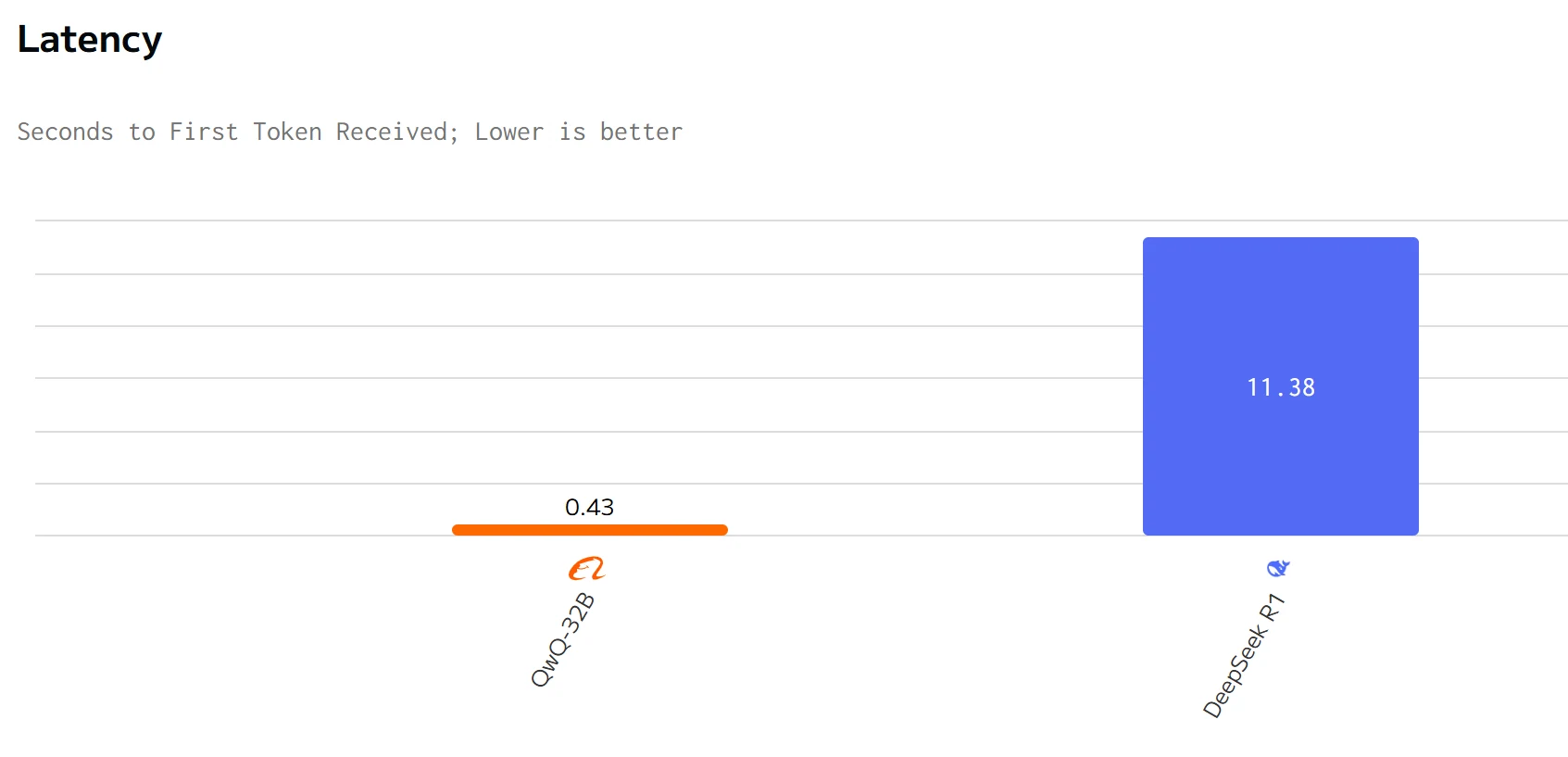
QWQ 32B surpasse DeepSeek R1 en termes de vitesse de sortie et de latence. Les prix d’entrée et de sortie de DeepSeek R1 sont nettement plus élevés que ceux de QWQ 32B.
Il est à noter que Novita AI propose une version Turbo avec un débit 3x et une réduction de 20 % à durée limitée !

Comparaison des benchmarks
Maintenant que nous avons établi les caractéristiques de base de chaque modèle, examinons leurs performances sur différents benchmarks. Cette comparaison aidera à illustrer leurs points forts dans différents domaines.
| Benchmark | DeepSeek-R1 (%) | QWQ 32B (%) |
|---|---|---|
| LiveCodeBench (Coding) | 62 | 22 |
| GPQA Diamond | 71 | 59 |
| MATH-500 | 96 | 91 |
| MMLU-Pro | 84 | 76 |
Ces résultats suggèrent que l’approche d’apprentissage par renforcement itératif piloté par machine de DeepSeek R1 pourrait être particulièrement efficace pour développer des capacités plus solides dans des domaines techniques spécialisés nécessitant un raisonnement précis et des compétences structurées de résolution de problèmes.
Si vous souhaitez voir plus de comparaisons, consultez ces articles :
- Deepseek v3 vs Llama 3.3 70b : Tâches linguistiques vs Code et Mathématiques
- DeepSeek R1 vs OpenAI o1 : Architectures distinctes de GRPO et PPO
- QwQ 32B : Un concurrent IA compact de DeepSeek R1
Configuration matérielle requise
| Modèle | Taille des paramètres | Configuration GPU |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4,9B | 1 x NVIDIA RTX 4090 (24 Go VRAM) avec sharding de modèle |
| DeepSeek-R1-Distill-Qwen-14B | 9,0B | 1 x NVIDIA A100 (80 Go VRAM) ou 2 x RTX 4090 (24 Go VRAM) avec parallélisme de tenseur |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 2 x NVIDIA A100 (80 Go VRAM) ou 1 x NVIDIA H100 (80 Go VRAM) ou 4 x RTX 4090 (24 Go VRAM) avec parallélisme de tenseur |
| DeepSeek-R1-Distill-Llama-70B | 70B | 4 x NVIDIA A100 (80 Go VRAM) ou 2 x NVIDIA H100 (80 Go VRAM) ou 8 x RTX 4090 (24 Go VRAM) avec parallélisme lourd |
| DeepSeek-R1:671B | 671B (37 milliards de paramètres actifs) | 16 x NVIDIA A100 (80 Go VRAM) ou 8 x NVIDIA H100 (80 Go VRAM), nécessite un cluster GPU distribué avec InfiniBand |
| QwQ-32B (précision 4 bits) | 32B | 1 x NVIDIA RTX 3090/4090 (24 Go VRAM), compatible avec quantification 4 bits |
| 1 x NVIDIA RTX 6000 (48 Go VRAM), compatible avec quantification 4 bits | ||
| 1 x NVIDIA H100 (80 Go VRAM) ou 2 x NVIDIA A100 (80 Go VRAM) |
Applications et cas d’usage
DeepSeek R1
- Mathématiques : Capable de résoudre des problèmes mathématiques avancés, y compris le raisonnement symbolique, la résolution d’équations et des tâches d’optimisation, ce qui le rend bien adapté aux applications STEM.
- Codage : Excelle dans la génération de code complexe, la compréhension de logiques complexes et le débogage de projets logiciels à grande échelle, ce qui en fait un outil précieux pour les développeurs et les ingénieurs.
- Connaissances générales : Démontre un raisonnement solide sur un large éventail de sujets, ce qui le rend idéal pour les tâches nécessitant une compréhension approfondie et une synthèse précise de divers domaines de connaissances.
QWQ 32B
- Éducation : Fournit un tutorat hautement personnalisé en mathématiques et en programmation, avec des explications étape par étape et un apprentissage adaptatif basé sur les progrès et les besoins de l’utilisateur.
- Développement logiciel : Aide les développeurs en générant des extraits de code précis et efficaces, en déboguant les erreurs et en proposant des recommandations pour optimiser et améliorer les performances du code.
- Recherche : Soutient les chercheurs avec une analyse avancée des données, la synthèse de littérature académique et des perspectives sur des ensembles de données complexes, ce qui en fait un assistant puissant pour les tâches de recherche.
Accessibilité et déploiement via Novita AI
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU fiable et abordable pour construire et passer à l’échelle.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Essayez DeepSeek R1 et QWQ 32B dès maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Lancez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page Settings et copiez la clé API comme indiqué dans l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Ceci est un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Lors de l’inscription, Novita AI offre un crédit de 0,5 $ pour démarrer !
Si le crédit gratuit est épuisé, vous pouvez payer pour continuer à l’utiliser.
Les modèles DeepSeek R1 et QwQ-32B sont tous deux des modèles de raisonnement avancés, chacun avec ses forces uniques.
- DeepSeek R1 : Avec sa grande taille de paramètres et son architecture MoE (Mixture of Experts), il est conçu pour gérer des tâches de raisonnement très complexes. Cependant, cette capacité nécessite des ressources de calcul importantes.
- QwQ-32B : En revanche, QwQ-32B offre une solution plus compacte et plus efficace en termes de matériel, offrant des performances compétitives tout en étant accessible sur des configurations matérielles moins exigeantes.
Le choix entre les deux modèles dépend en fin de compte des exigences spécifiques de l’application, du matériel disponible et des considérations budgétaires.
Questions fréquentes
Qu’est-ce qui rend QwQ-32B unique ?
QwQ-32B se distingue par son utilisation de l’apprentissage par renforcement sans fine-tuning supervisé, atteignant des performances exceptionnelles dans les tâches de raisonnement, en particulier en mathématiques et en codage.
Quelle est la principale différence entre QwQ-32B et Qwen2.5 ?
QwQ-32B s’appuie sur Qwen2.5, en ajoutant une optimisation par apprentissage par renforcement spécifiquement pour les tâches de raisonnement, sans utiliser les approches traditionnelles de fine-tuning supervisé.
Comment accéder à QWQ 32B via API ?
Novita AI vous fournit une API QWQ 32B fiable et abordable.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions IA. API intégrées, serverless, instance GPU — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



