

Puntos clave
DeepSeek R1: Con 671 mil millones de parámetros y una arquitectura de mezcla de expertos (MoE), DeepSeek R1 sobresale en razonamiento avanzado y tareas especializadas como matemáticas, programación y conocimiento general. Soporta una ventana de contexto de 128 mil tokens, pero requiere importantes recursos computacionales.
QWQ 32B: Compacto y eficiente con 32.5 mil millones de parámetros, QwQ-32B está optimizado para aplicaciones más amplias. Soporta una ventana de contexto de 32 mil tokens y cuenta con una arquitectura transformer de alto rendimiento (RoPE, SwiGLU, RMSNorm). Ofrece salidas más rápidas, menores requisitos de hardware y soluciones rentables para educación, desarrollo de software e investigación.
Si estás buscando evaluar DeepSeek R1 y QWQ 32B en tus propios casos de uso, al registrarte, Novita AI te proporciona un crédito de $0.5 para empezar.
Este artículo ofrece una comparación práctica, informativa y técnica de dos modelos de razonamiento líderes: DeepSeek R1 y QwQ-32B. Aunque ambos modelos están diseñados para avanzar en las capacidades de razonamiento de la IA, difieren significativamente en arquitectura, métodos de entrenamiento y requisitos de hardware. Cabe destacar que QwQ-32B fue lanzado poco después de la semana de código abierto de DeepSeek, lo que sugiere que pudo haberse inspirado en las innovaciones de DeepSeek. Este artículo explora estas diferencias para ayudar a los usuarios a determinar qué modelo se adapta mejor a sus necesidades específicas.
Introducción básica de los modelos
Para comenzar nuestra comparación, primero comprendamos las características fundamentales de cada modelo.
DeepSeek R1
- Fecha de lanzamiento: 21 de enero de 2025
- Escala del modelo:
- Características principales:
- Tamaño del modelo: 671B parámetros (37B activos por token)
- Tokenizador: Tokenizador mejorado con etiquetas de autorreflexión
- Idiomas compatibles: Multilingüe con adaptación cultural
- Multimodal: Solo texto
- Ventana de contexto: 128K tokens
- Formatos de almacenamiento: Soporte de cuantización Q8/Q5
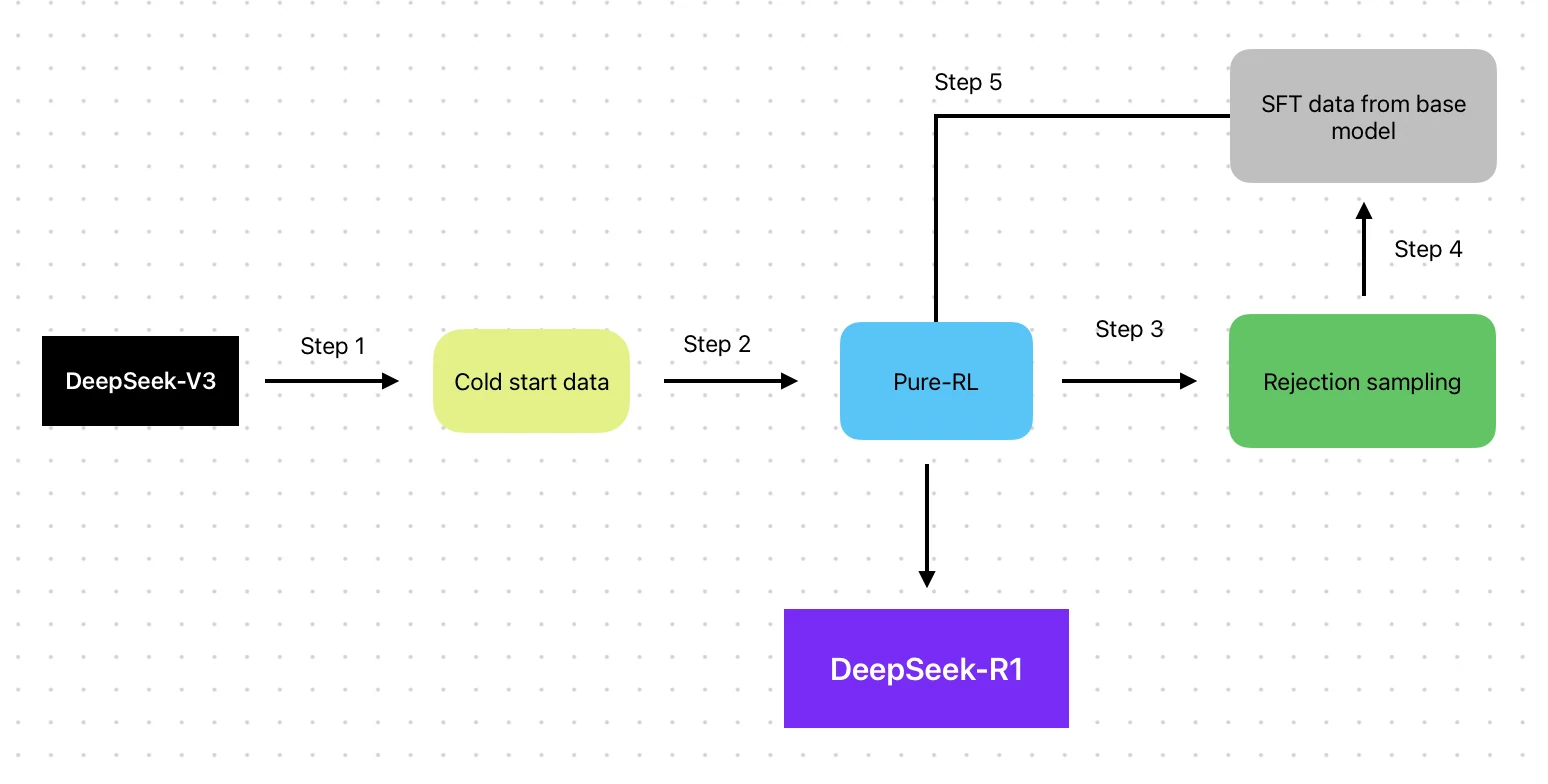
- Arquitectura: Mezcla de expertos (MoE) + pipeline de entrenamiento mejorado con RL
- Método de entrenamiento: Construido sobre la base V3 con pipeline RL (SFT → RL → SFT → RL)
- Datos de entrenamiento: Base V3 + datos de optimización RL
QWQ 32B
- Fecha de lanzamiento: 5 de marzo de 2025
- Escala del modelo:
- Características principales:
- Tamaño del modelo: Un total de 32.5 mil millones de parámetros, con 31.0 mil millones de parámetros no incrustados.
- Idiomas compatibles: Cubre más de 29 idiomas para accesibilidad y aplicación global.
- Multimodal: Solo texto
- Ventana de contexto: Soporta hasta 32,768 tokens.
- Arquitectura: QwQ-32B utiliza una arquitectura transformer con 64 capas, 40 cabezas de atención para consultas y 8 para clave-valor. Construido sobre transformers con RoPE (Embeddings Posicionales Rotativos), QwQ-32B integra la función de activación SwiGLU, emplea RMSNorm para normalización e incluye sesgo en los cálculos de QKV de atención.
QwQ-32B se centra en la optimización solo con RL para eficiencia e independencia.
DeepSeek R1 integra tanto SFT como RL en un proceso iterativo equilibrado, pero conserva cierta dependencia de SFT.
Comparación de velocidad
Si deseas probarlo tú mismo, puedes iniciar una prueba gratuita en el sitio web de Novita AI.
¡Prueba DeepSeek R1 y QWQ 32B ahora!
Comparación de velocidad
Comparación de costos
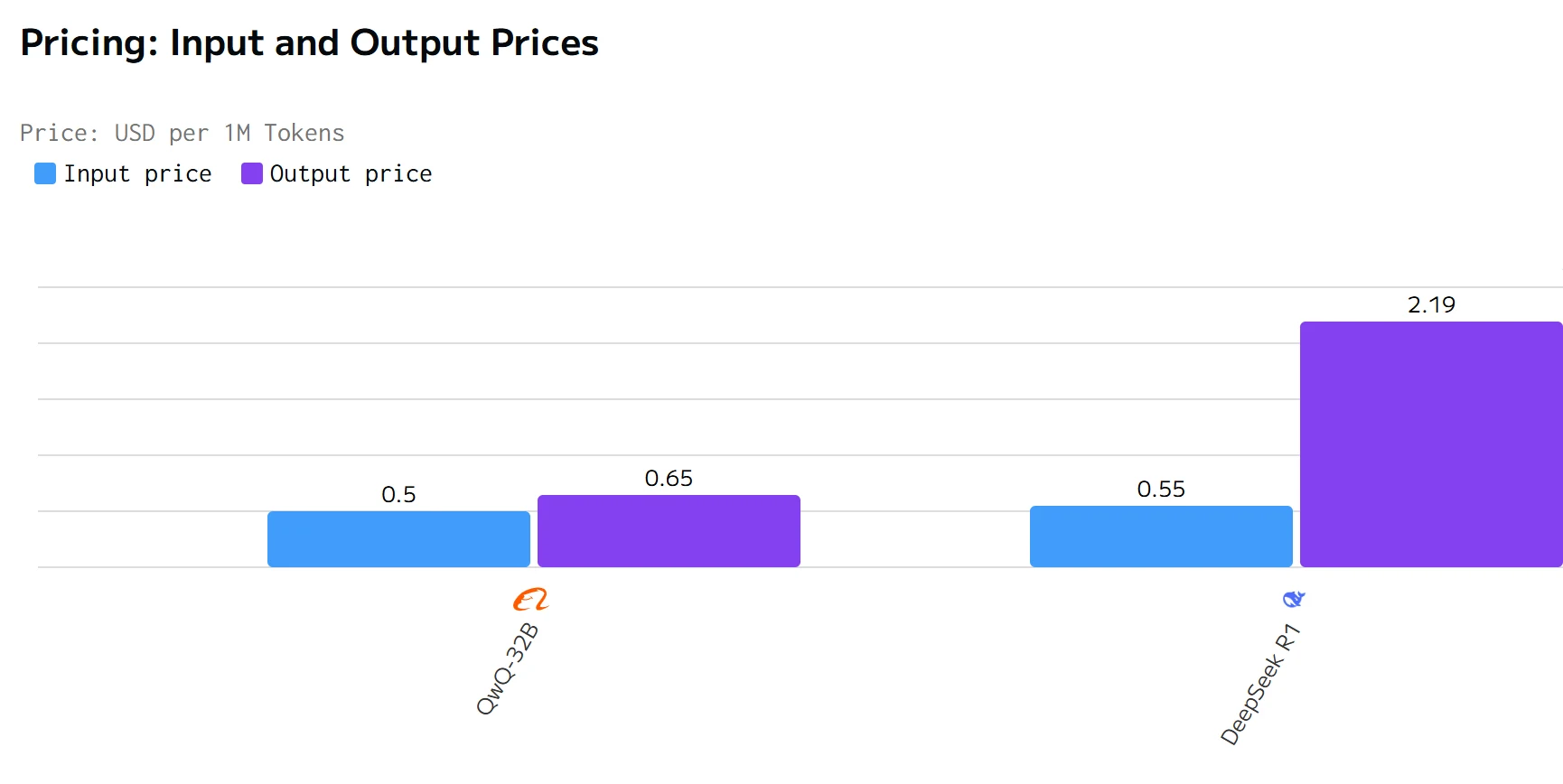
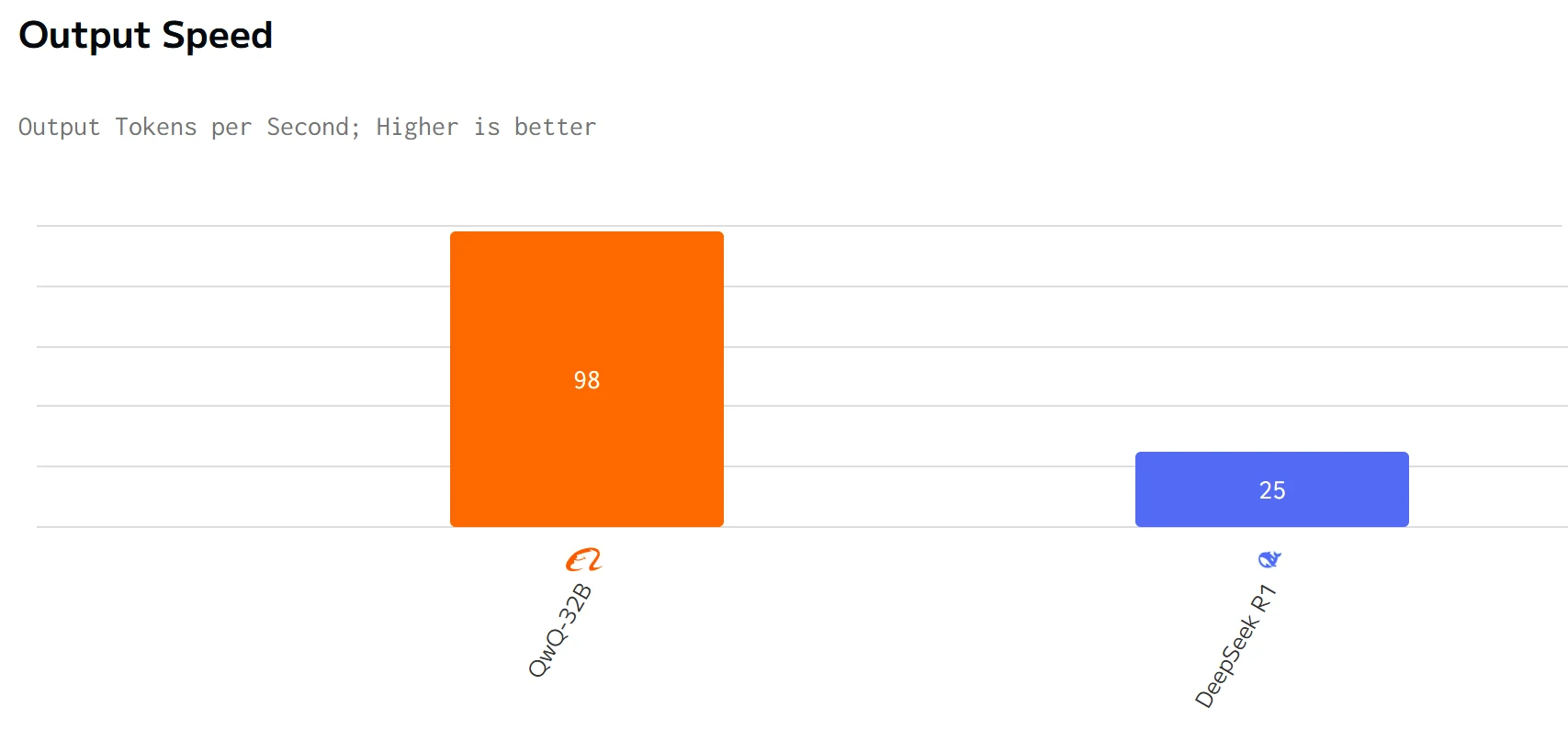
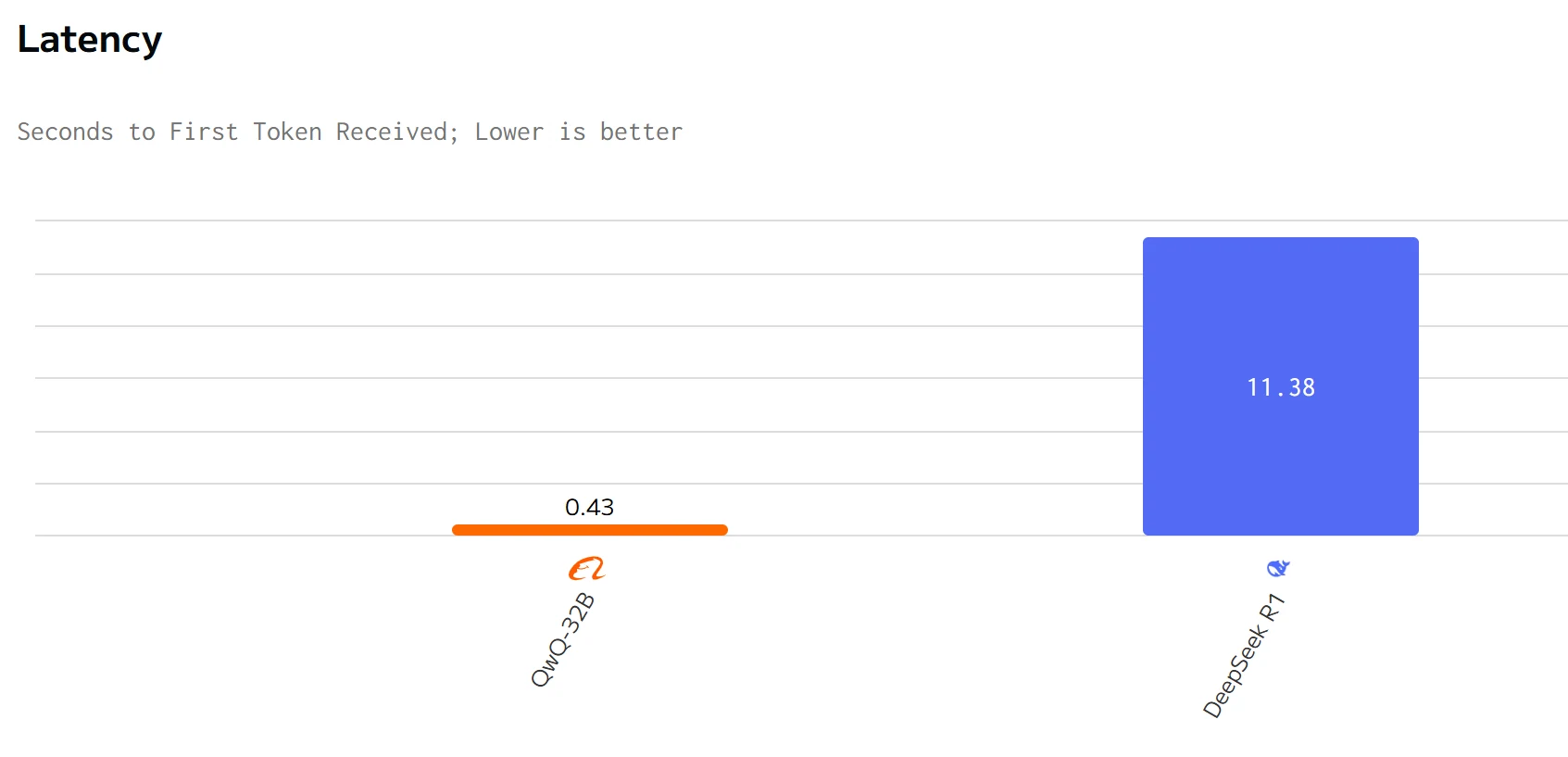
QWQ 32B supera a DeepSeek R1 en velocidad de salida y latencia. Los precios de entrada y salida de DeepSeek R1 son significativamente más altos que los de QWQ 32B.
Vale la pena señalar que Novita AI lanza una versión Turbo con 3x de rendimiento y un 20% de descuento por tiempo limitado.

Comparación de benchmarks
Ahora que hemos establecido las características básicas de cada modelo, profundicemos en su rendimiento en varios benchmarks. Esta comparación ayudará a ilustrar sus fortalezas en diferentes áreas.
| Benchmark | DeepSeek-R1 (%) | QWQ 32B (%) |
|---|---|---|
| LiveCodeBench (Programación) | 62 | 22 |
| GPQA Diamond | 71 | 59 |
| MATH-500 | 96 | 91 |
| MMLU-Pro | 84 | 76 |
Estos resultados sugieren que el enfoque de aprendizaje por refuerzo iterativo impulsado por máquina de DeepSeek R1 puede ser particularmente efectivo para desarrollar capacidades más sólidas en dominios técnicos especializados que requieren razonamiento preciso y habilidades de resolución de problemas estructuradas.
Si deseas ver más comparaciones, puedes consultar estos artículos:
- Deepseek v3 vs Llama 3.3 70b: Tareas de lenguaje vs Código y Matemáticas
- DeepSeek R1 vs OpenAI o1: Arquitecturas distintas de GRPO y PPO
- QwQ 32B: Un rival compacto de IA para DeepSeek R1
Requisitos de hardware
| Modelo | Tamaño de parámetros | Configuración de GPU |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4.9B | 1 x NVIDIA RTX 4090 (24GB VRAM) con fragmentación de modelo |
| DeepSeek-R1-Distill-Qwen-14B | 9.0B | 1 x NVIDIA A100 (80GB VRAM) o 2 x RTX 4090 (24GB VRAM) con paralelismo tensorial |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 2 x NVIDIA A100 (80GB VRAM) o 1 x NVIDIA H100 (80GB VRAM) o 4 x RTX 4090 (24GB VRAM) con paralelismo tensorial |
| DeepSeek-R1-Distill-Llama-70B | 70B | 4 x NVIDIA A100 (80GB VRAM) o 2 x NVIDIA H100 (80GB VRAM) o 8 x RTX 4090 (24GB VRAM) con paralelismo pesado |
| DeepSeek-R1:671B | 671B (37 mil millones de parámetros activos) | 16 x NVIDIA A100 (80GB VRAM) o 8 x NVIDIA H100 (80GB VRAM), requiere un clúster de GPU distribuido con InfiniBand |
| QwQ-32B (precisión de 4 bits) | 32B | 1 x NVIDIA RTX 3090/4090 (24GB VRAM), compatible con cuantización de 4 bits |
| 1 x NVIDIA RTX 6000 (48GB VRAM), compatible con cuantización de 4 bits | ||
| 1 x NVIDIA H100 (80GB VRAM) o 2 x NVIDIA A100 (80GB VRAM) |
Aplicaciones y casos de uso
DeepSeek R1
- Matemáticas: Capaz de resolver problemas matemáticos avanzados, incluyendo razonamiento simbólico, resolución de ecuaciones y tareas de optimización, lo que lo hace adecuado para aplicaciones relacionadas con STEM.
- Programación: Sobresale en la generación de código complejo, comprensión de lógica intrincada y depuración de proyectos de software a gran escala, lo que lo convierte en una herramienta valiosa para desarrolladores e ingenieros.
- Conocimiento general: Demuestra un razonamiento sólido en una amplia gama de temas, ideal para tareas que requieren una comprensión profunda y una síntesis precisa de diversos dominios de conocimiento.
QWQ 32B
- Educación: Proporciona tutoría altamente personalizada en matemáticas y programación, ofreciendo explicaciones paso a paso y aprendizaje adaptativo basado en el progreso y las necesidades del usuario.
- Desarrollo de software: Ayuda a los desarrolladores generando fragmentos de código precisos y eficientes, depurando errores y ofreciendo recomendaciones para optimizar y mejorar el rendimiento del código.
- Investigación: Apoya a los investigadores con análisis de datos avanzados, resúmenes de literatura académica e ideas sobre conjuntos de datos complejos, lo que lo convierte en un asistente potente para tareas de investigación.
Accesibilidad e implementación a través de Novita AI
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una manera fácil de implementar modelos de IA a través de nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

¡Prueba DeepSeek R1 y QWQ 32B ahora!
Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página de “Configuración”, puedes copiar la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completions de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Al registrarte, Novita AI te proporciona un crédito de $0.5 para empezar.
Si se agotan los créditos gratuitos, puedes pagar para seguir usándolo.
Tanto DeepSeek R1 como QwQ-32B son modelos de razonamiento avanzados, cada uno con fortalezas únicas.
- DeepSeek R1: Con su gran tamaño de parámetros y arquitectura MoE (Mezcla de Expertos), está diseñado para manejar tareas de razonamiento altamente complejas. Sin embargo, esta capacidad conlleva la necesidad de recursos computacionales sustanciales.
- QwQ-32B: En contraste, QwQ-32B proporciona una solución más compacta y eficiente en cuanto a hardware, ofreciendo un rendimiento competitivo mientras es accesible en configuraciones de hardware menos exigentes.
La decisión entre los dos modelos depende en última instancia de los requisitos específicos de la aplicación, el hardware disponible y las consideraciones presupuestarias.
Preguntas frecuentes
¿Qué hace único a QwQ-32B?
QwQ-32B se destaca por su uso de aprendizaje por refuerzo sin ajuste fino supervisado, logrando un rendimiento excepcional en tareas de razonamiento, particularmente en matemáticas y programación.
¿Cuál es la diferencia clave entre QwQ-32B y Qwen2.5?
QwQ-32B se basa en Qwen2.5, agregando optimización de aprendizaje por refuerzo específicamente para tareas de razonamiento, sin utilizar enfoques tradicionales de ajuste fino supervisado.
¿Cómo acceder a QWQ 32B a través de API?
Novita AI te ofrece la API de QWQ 32B asequible y confiable.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. API integradas, sin servidor, instancia de GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



