

Gestern war der dritte Tag der Open Source Week, und DeepSeek hat die Open-Source-Bibliothek DeepGEMM offiziell veröffentlicht.
Dabei handelt es sich um eine FP8-GEMM-Bibliothek, die speziell für dichte und MoE-Modelle entwickelt wurde und die Schulung und Inferenz von MoE-FP8-quantisierten Modellen wie DeepSeek-V3/R1 stark unterstützt.
DeepGEMM wurde für NVIDIA-Hopper-Architektur-GPUs (z. B. H100, H200, H800) intensiv optimiert.
Zu den Hauptmerkmalen gehören prägnanter Code (der Kern umfasst nur etwa 300 Zeilen) bei dennoch herausragender Leistung, die in verschiedenen Matrixformen mit expertenoptimierten Bibliotheken mithalten oder diese sogar übertreffen kann.
Als Cloud-Plattform, die sich auf die Bereitstellung leistungsstarker KI-Computing-Dienste spezialisiert hat, hat Novita AI eine große Anzahl von MoE-FP8-quantisierten Modellen (wie die DeepSeek-FP8-Version) bereitgestellt.
Um die DeepGEMM-Technologie besser zu nutzen und die Inferenzeffizienz dieser Modelle zu steigern, führte Novita AI umfassende Leistungstests mit DeepGEMM durch, sobald es verfügbar war.
Bevor wir uns mit den konkreten Testergebnissen befassen, machen wir uns zunächst mit einigen relevanten Grundkonzepten vertraut.
Was ist GEMM?
GEMM (General Matrix Multiplication) ist der grundlegendste und wichtigste Rechenoperator im Deep Learning, und die Optimierung von GEMM ist der Kern des leistungsstarken KI-Computings.
DeepGEMM ist eine Open-Source-Bibliothek, die speziell entwickelt wurde, um wichtige GEMM-Operationen im Deep Learning zu beschleunigen und die Gesamtleistung des KI-Systems durch die Verbesserung der GEMM-Berechnungseffizienz zu steigern.
Einzigartige Vorteile von DeepGEMM
Im Vergleich zu ausgereiften Template-Bibliotheken wie CUTLASS und CuTe verfolgt DeepGEMM einen schlanken Designansatz: Es strebt keine breite Kompatibilität mit allen GPUs und Berechnungsszenarien an, sondern konzentriert sich darauf, die FP8-Rechenfähigkeiten der Hopper-Architektur voll auszuschöpfen, mit sorgfältiger Optimierung für die Matrixformen, die in großen Modellen wie DeepSeek R1 und V3 häufig verwendet werden.
Technologische Innovationen von DeepGEMM
DeepGEMM erzielt Leistungsdurchbrüche durch die folgenden vier zentralen technologischen Innovationen:
- Just-In-Time-Kompilierung (JIT)
Traditionelle Methoden erfordern das Vorkompilieren von CUDA-Code vor dem Aufruf, während die JIT-Technologie von DeepGEMM den Kompilierungsprozess zur Laufzeit verbirgt, sodass keine manuelle Kompilierung erforderlich ist.
Entwickler müssen keine komplexen Python-Schnittstellen erstellen, was den Entwicklungsprozess vereinfacht und mit nur wenigen Codezeilen Funktionalität ermöglicht.
- Optimierung der Überlappung von Berechnung und Transfer
DeepGEMM führt Datenübertragung und Berechnungsoperationen gleichzeitig aus und nutzt die Tensor Memory Accelerator (TMA)-Funktion der Hopper-Architektur voll aus, um die Effizienz der Datenübertragung weiter zu optimieren. Zudem verwendet DeepGEMM Low-Level-PTX-Befehle, um extreme Leistung zu erzielen.
- Unterstützung beliebiger Matrixgrößen
Traditionelle GEMM-Implementierungen erfordern, dass Matrixgrößen Potenzen von 2 sind (z. B. 128, 256), während DeepGEMM nicht ausgerichtete Blockgrößen für Matrizen unterstützt. Diese Funktion vermeidet Speicherverschwendung und verbessert die allgemeine Berechnungseffizienz.
- FFMA-SASS-Befehlsebene-Optimierung
Durch die Modifizierung der Yield- und Reuse-Bits der FFMA-Befehle werden mehr Möglichkeiten zur Überlappung von MMA-Befehlen mit Promotion-FFMA-Befehlen geschaffen, was in bestimmten Szenarien zu Leistungssteigerungen von über 10 % führt – selbst bei begrenztem Verständnis der zugrunde liegenden Architektur.
Novita AIs erste Bewertung: DeepGEMM-Universalität
In den Inferenzszenarien von MoE-Modellen führte Novita AI detaillierte Leistungstests von DeepGEMM auf den GPUs H100 und H200 durch und verglich die Ergebnisse mit den offiziellen H800-Benchmark-Daten.
Zunächst fassen wir die wichtigsten Hardware-Parameter der GPUs H100, H200 und H800 zusammen, die die Leistung von DeepGEMM beeinflussen:
| Kennzahl | H100 SXM | H200 SXM | H800 SXM |
|---|---|---|---|
| FP8-Rechenleistung | 3958 TFLOPS | 3958 TFLOPS | 3958 TFLOPS |
| Speicherbandbreite | 3,35 TB/s | 4,8 TB/s | 3,35 TB/s |
MoE-Modell: Gruppiertes GEMM mit kontinuierlichem Speicherlayout (Trainingsvorwärtspass, Inferenz-Prefill)
In MoE-Netzwerken mit kontinuierlichem Speicherlayout sind die Leistungsunterschiede zwischen H100, H200 und H800 (offiziell) minimal.
Die folgende Abbildung zeigt den Vergleichstest der Speicherbandbreitennutzung. Aufgrund von Rechenengpässen und der ähnlichen FP8-Rechenleistung der drei GPUs zeigen sich keine signifikanten Leistungsunterschiede.
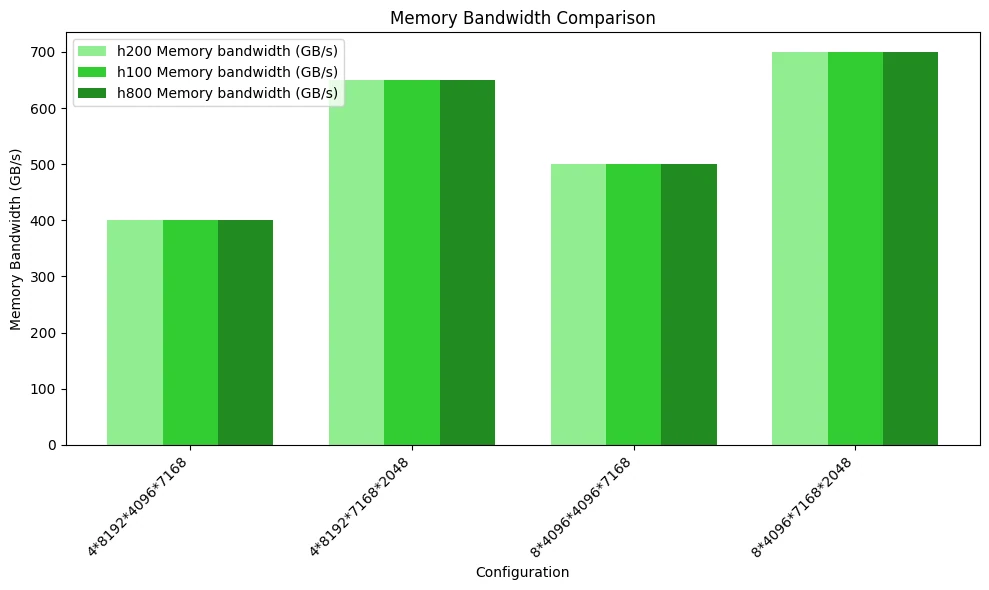
Die folgende Abbildung zeigt den Vergleich der Rechenleistung. Da der Speicherzugriffsengpass nicht erreicht wurde, weisen die drei GPUs keine nennenswerten Unterschiede auf.
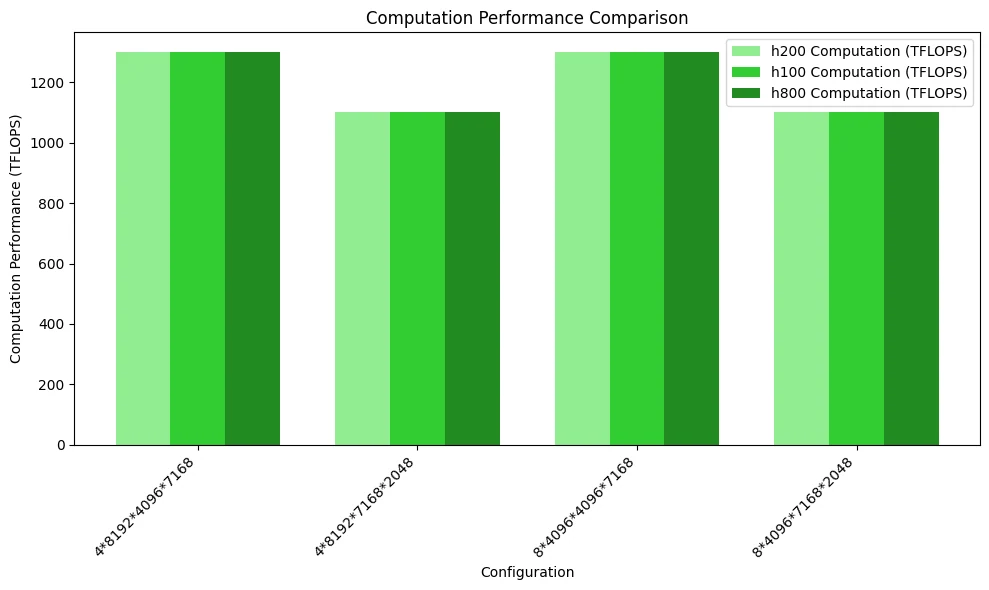
MoE-Modell: Gruppiertes GEMM mit maskiertem Speicherlayout (Inferenz-Decoding)
In MoE-Netzwerken mit maskiertem Speicherlayout zeigt die H200 die beste Leistung, während die Unterschiede zwischen H100 und H800 sehr gering sind.
Die folgende Abbildung zeigt den Vergleichstest der Speicherbandbreitennutzung. Da das maskierte Speicherlayout mehr Speicherbandbreite verbraucht als das kontinuierliche Layout, wurde in einigen Szenarien der Speicherzugriffsengpass erreicht, was zu Leistungsunterschieden zwischen den drei GPUs führt:
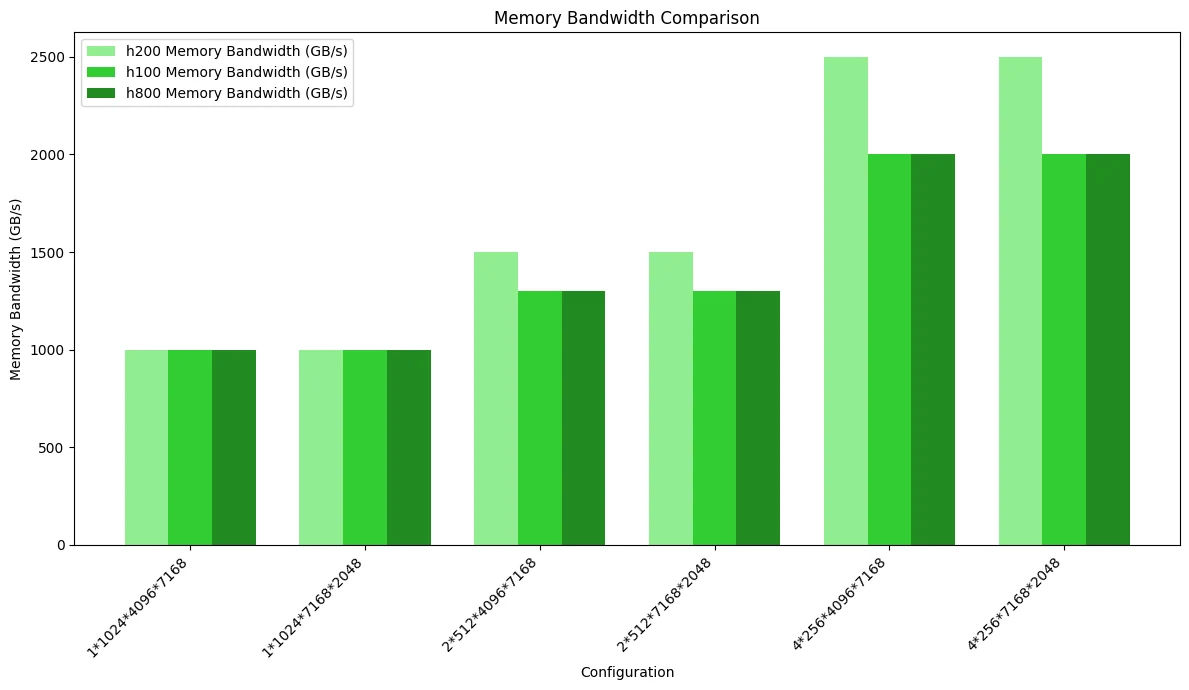
Die folgende Abbildung zeigt den Vergleich der Rechenleistung, der die durch die Bandbreite verursachten Unterschiede hervorhebt:
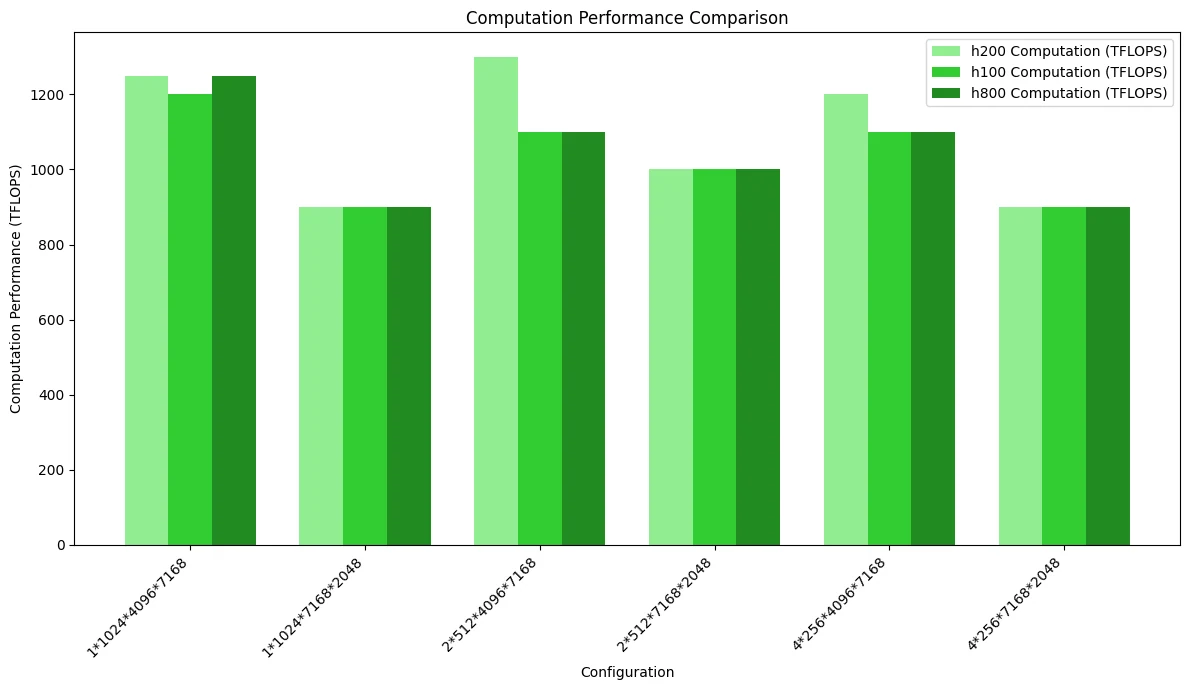
DeepGEMM vs. SGLang Triton Leistungsvergleich
Derzeit verwenden gängige Inferenz-Frameworks für das MoE-Modul gruppierte GEMM-Operatoren, die auf SGLang Triton basieren. Wir führten Leistungsvergleichstests zwischen DeepGEMM und SGLang Triton unter H200-Hardware durch:
DeepGEMM zeigt gewisse Vorteile im kontinuierlichen Speicherlayout, aber SGLang Triton schneidet im maskierten Speicherlayout besser ab. Derzeit werden einige der SGLang-Triton-Operatoren hauptsächlich in maskierten Speicherszenarien eingesetzt. Daher benötigt DeepGEMM weitere Optimierungen, um SGLang Triton in Inferenz-Frameworks zu ersetzen.
- Für MoE-Modelle mit kontinuierlichem Speicherlayout (Trainingsvorwärtspass, Inferenz-Prefill) zeigt DeepGEMM deutlichere Vorteile.
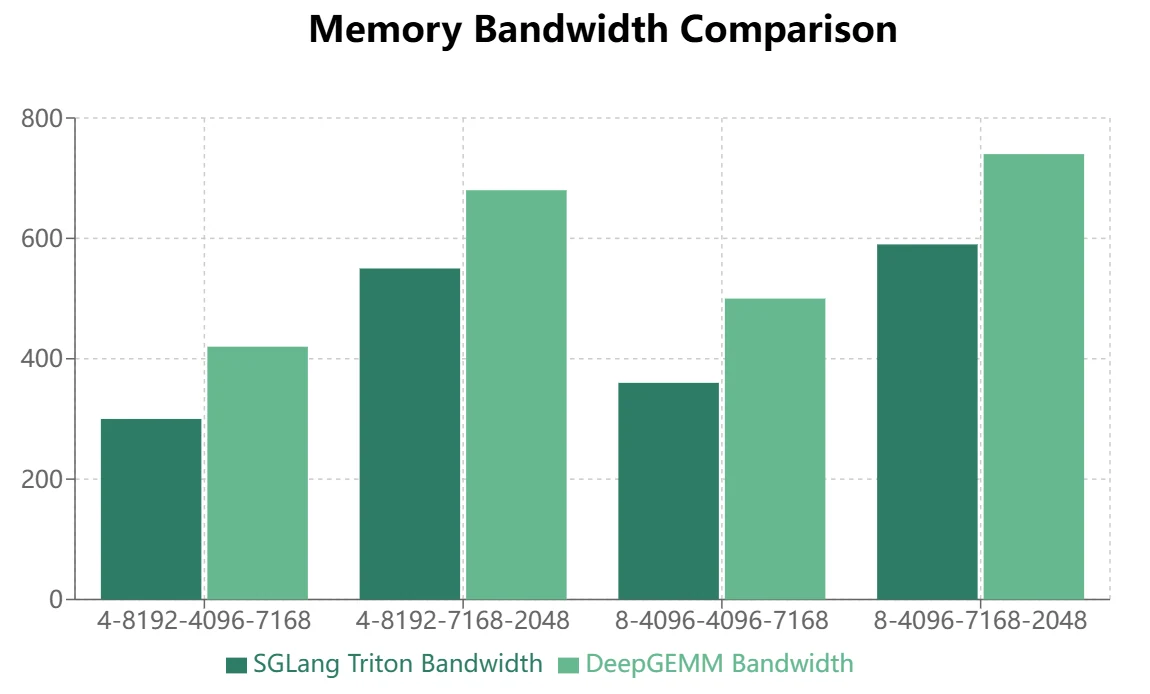
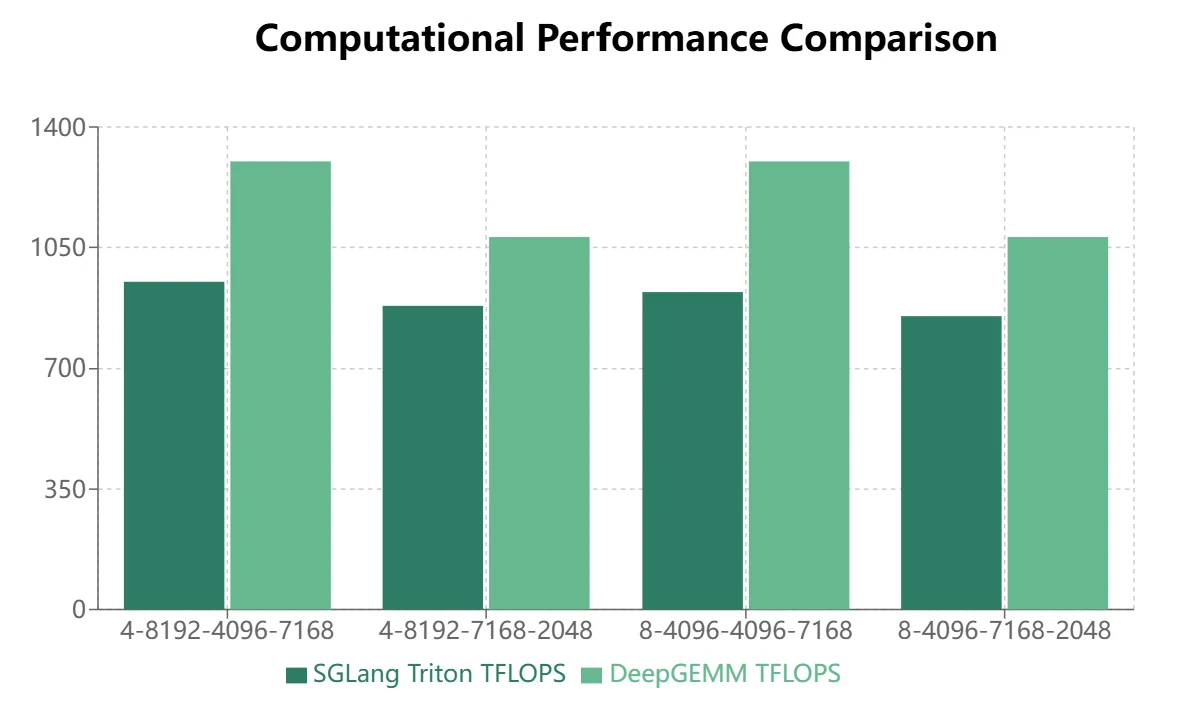
- Für MoE-Modelle mit maskiertem Speicherlayout (Inferenz-Decoding) zeigt Triton eine überlegene Leistung:
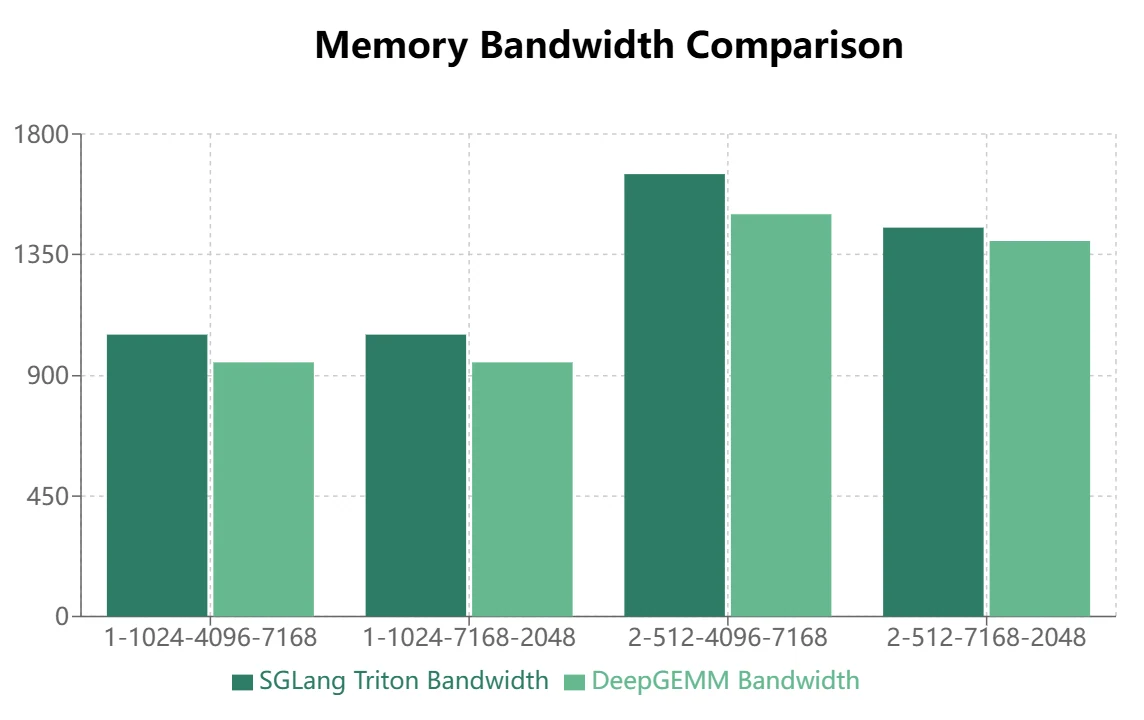
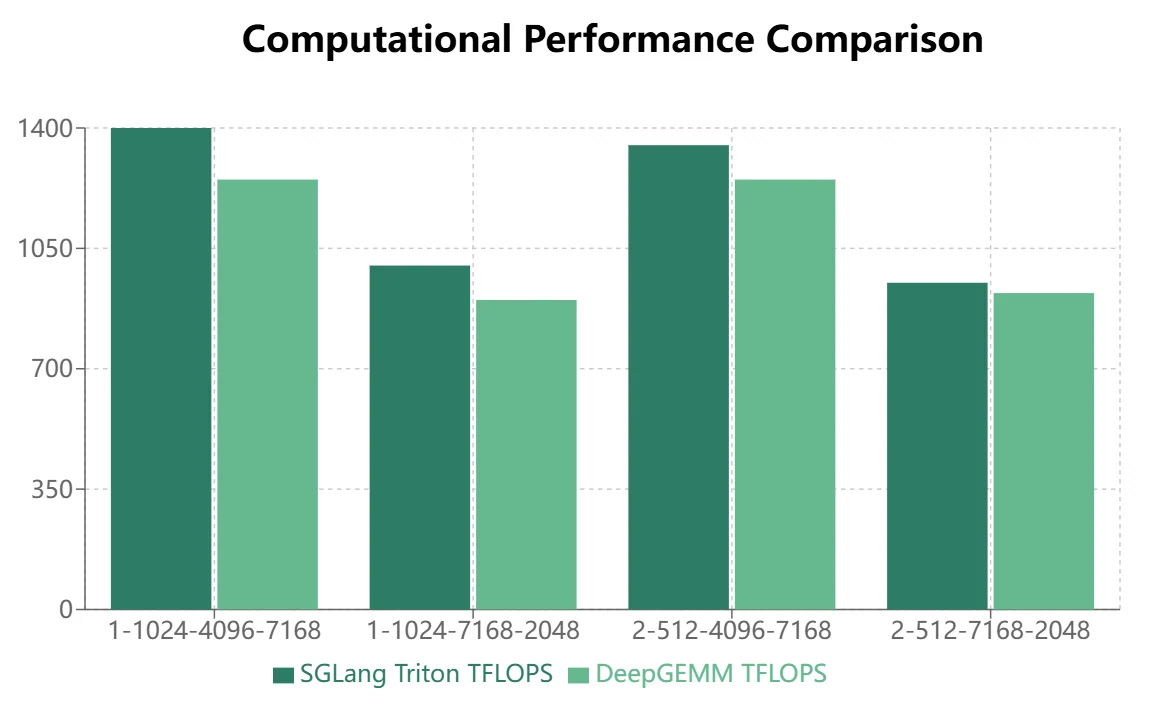
Fazit
Die Evaluierungsergebnisse zeigen, dass DeepGEMM auf mehreren GPUs, darunter H100, H200 und H800, erhebliche Leistungsoptimierungsfähigkeiten aufweist, was seine starke Vielseitigkeit unterstreicht.
Für MoE-Serienmodelle (wie DeepSeek V3 und R1), die auf der Hopper-Architektur laufen, ist durch die Integration von DeepGEMM in das Inferenz-Framework – durch den Austausch der ursprünglichen CUTLASS-Version von gruppierten GEMMs – eine etwa 1,2-fache Beschleunigung der Modellinferenz zu erwarten, was die Gesamtleistung steigert.
Derzeit kann DeepGEMM SGLang Triton nicht vollständig ersetzen und benötigt weitere Optimierungen, um seinen Anwendungsbereich zu erweitern. Bei der Inferenz-Decodierung bleibt SGLang Triton effizienter, während DeepGEMM bei Trainingsvorwärtspässen und Inferenz-Prefill-Phasen größere Vorteile zeigt.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über eine einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung bereitstellt.
Holen Sie sich $20 Guthaben und testen Sie DeepSeek jetzt!



