

Ayer fue el tercer día de la Semana de Código Abierto, y DeepSeek ha publicado oficialmente la biblioteca de código abierto DeepGEMM.
Se trata de una biblioteca de computación GEMM FP8 diseñada específicamente para modelos densos y MoE, que proporciona un sólido soporte para el entrenamiento e inferencia de modelos cuantizados FP8 tipo MoE como DeepSeek - V3/R1.
DeepGEMM ha sido profundamente optimizado para las GPU con arquitectura Hopper de NVIDIA (como H100, H200, H800).
Las principales características incluyen código conciso (la parte central tiene solo unas 300 líneas) y un rendimiento excepcional, que puede igualar o incluso superar a bibliotecas ajustadas por expertos en diversas formas de matrices.
Como plataforma en la nube dedicada a proporcionar servicios de computación de IA de alto rendimiento, Novita AI ha desplegado una gran cantidad de modelos cuantizados FP8 tipo MoE (como la versión FP8 de DeepSeek).
Para aprovechar mejor la tecnología DeepGEMM y mejorar la eficiencia de inferencia de estos modelos, Novita AI realizó pruebas de rendimiento exhaustivas en DeepGEMM tan pronto como estuvo disponible.
Antes de profundizar en los datos específicos de las pruebas, primero familiaricémonos con algunos conceptos básicos relevantes.
¿Qué es GEMM?
GEMM (Multiplicación de Matrices General) es el operador computacional más fundamental e importante en el aprendizaje profundo, y la optimización de GEMM es el núcleo de la computación de IA de alto rendimiento.
DeepGEMM es una biblioteca de código abierto diseñada específicamente para acelerar operaciones clave de GEMM en el aprendizaje profundo, mejorando el rendimiento general del sistema de IA al aumentar la eficiencia computacional de GEMM.
Ventajas Únicas de DeepGEMM
En comparación con bibliotecas de plantillas maduras como CUTLASS y CuTe, DeepGEMM adopta un enfoque de diseño ligero: no apunta a una amplia compatibilidad con todas las GPU y escenarios computacionales, sino que se centra en aprovechar al máximo las capacidades de computación FP8 de la arquitectura Hopper, con una optimización meticulosa para las formas de matrices comúnmente utilizadas en modelos grandes como DeepSeek R1 y V3.
Innovaciones Tecnológicas de DeepGEMM
DeepGEMM logra avances de rendimiento a través de las siguientes cuatro innovaciones tecnológicas principales:
- Compilación Just-In-Time (JIT)
Los métodos tradicionales requieren precompilar código CUDA antes de llamarlo, mientras que la tecnología JIT de DeepGEMM oculta el proceso de compilación en tiempo de ejecución, eliminando la necesidad de compilación manual.
Los desarrolladores no necesitan crear interfaces complejas de Python, simplificando el proceso de desarrollo y logrando funcionalidad con solo unas pocas líneas de código.
- Optimización de Superposición de Cómputo y Transferencia
DeepGEMM realiza operaciones de transferencia de datos y cómputo simultáneamente, utilizando al máximo la función Acelerador de Memoria Tensorial (TMA) de la arquitectura Hopper, optimizando aún más la eficiencia de la transferencia de datos. Además, DeepGEMM utiliza instrucciones PTX de bajo nivel para lograr un rendimiento extremo.
- Soporte para Tamaños de Matriz Arbitrarios
Las implementaciones tradicionales de GEMM requieren que los tamaños de matriz sean potencias de 2 (como 128, 256), mientras que DeepGEMM admite tamaños de bloque no alineados para matrices. Esta característica evita el desperdicio de memoria y mejora la eficiencia computacional general.
- Optimización a Nivel de Instrucciones SASS FFMA
Al modificar los bits de yield y reutilización de las instrucciones FFMA, se crean más oportunidades para superponer instrucciones MMA con instrucciones FFMA de promoción, lo que resulta en mejoras de rendimiento de más del 10% en ciertos escenarios, incluso con un conocimiento limitado de la arquitectura subyacente.
Evaluación de Primera Mano de Novita AI: Universalidad de DeepGEMM
En los escenarios de inferencia de modelos MoE, Novita AI realizó pruebas de rendimiento detalladas de DeepGEMM en las GPU H100 y H200 y comparó los resultados con los datos de referencia oficiales de H800.
Primero, resumimos los parámetros clave de hardware de las GPU H100, H200 y H800 que afectan el rendimiento de DeepGEMM:
| Métrica | H100 SXM | H200 SXM | H800 SXM |
|---|---|---|---|
| Potencia de Cómputo FP8 | 3958 TFLOPS | 3958 TFLOPS | 3958 TFLOPS |
| Ancho de Banda de Memoria | 3.35 TB/s | 4.8 TB/s | 3.35 TB/s |
Modelo MoE: GEMM Agrupado con Disposición de Almacenamiento Continuo (Pase Adelante de Entrenamiento, Prefill de Inferencia)
En redes MoE que utilizan la disposición de almacenamiento continuo, las diferencias de rendimiento entre H100, H200 y H800 (oficial) son mínimas.
La siguiente figura muestra la prueba comparativa de utilización del ancho de banda de memoria. Debido a los cuellos de botella computacionales y la potencia de cómputo FP8 similar de las tres GPU, su rendimiento no muestra diferencias significativas.
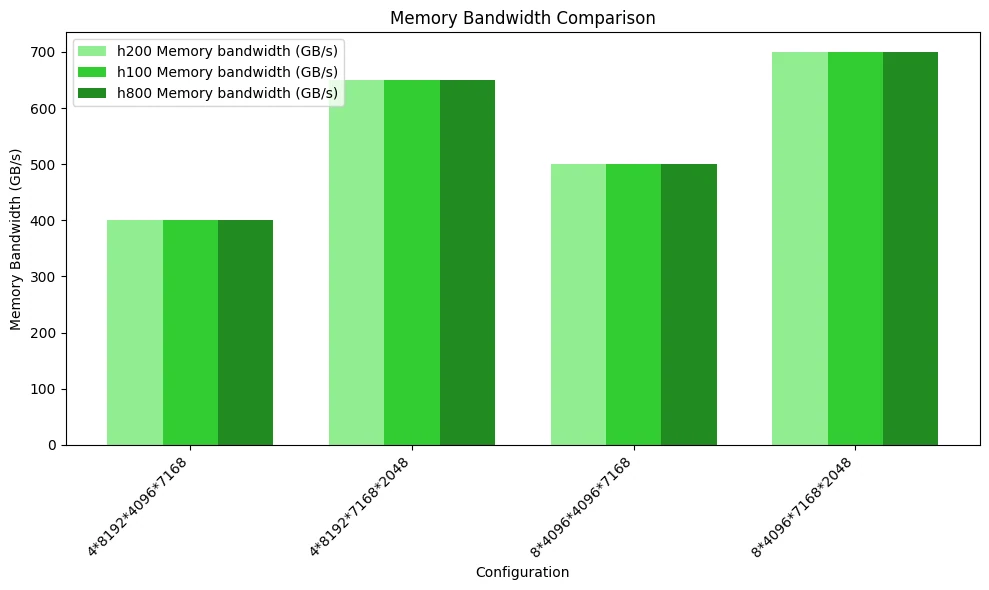
La siguiente figura ilustra la comparación del rendimiento computacional. Dado que no se alcanzó el cuello de botella de acceso a memoria, el rendimiento de las tres GPU no muestra diferencias notables.
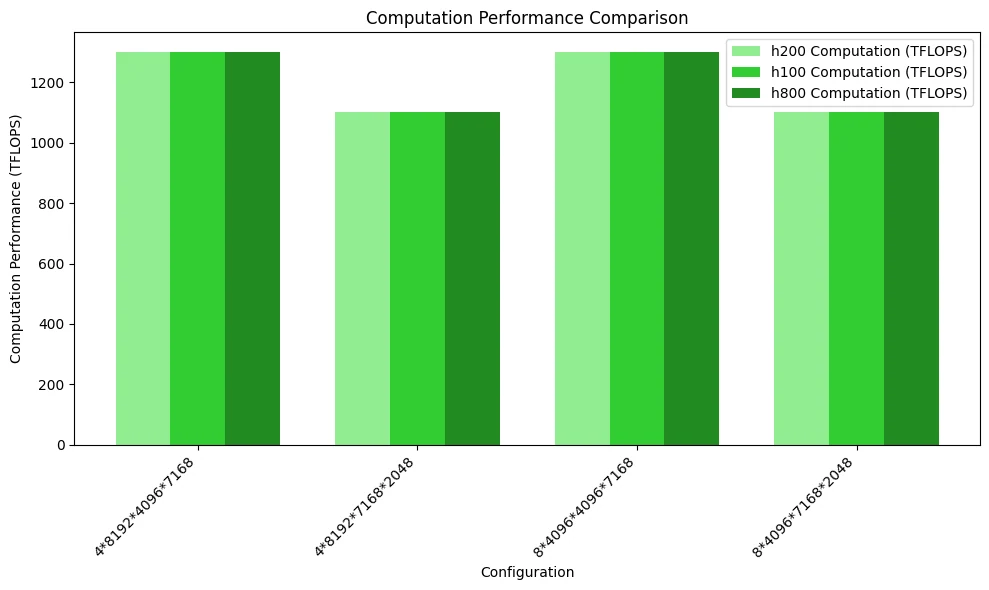
Modelo MoE: GEMM Agrupado con Disposición de Almacenamiento Enmascarada (Decodificación de Inferencia)
En redes MoE que utilizan la disposición de almacenamiento enmascarada, la H200 muestra el mejor rendimiento, mientras que las diferencias entre H100 y H800 son muy pequeñas.
La siguiente figura muestra la prueba comparativa de utilización del ancho de banda de memoria. Dado que la disposición de almacenamiento enmascarada consume más ancho de banda de memoria que la disposición de almacenamiento continuo, algunos escenarios han alcanzado el cuello de botella de acceso a memoria, lo que resulta en diferencias de rendimiento entre las tres GPU:
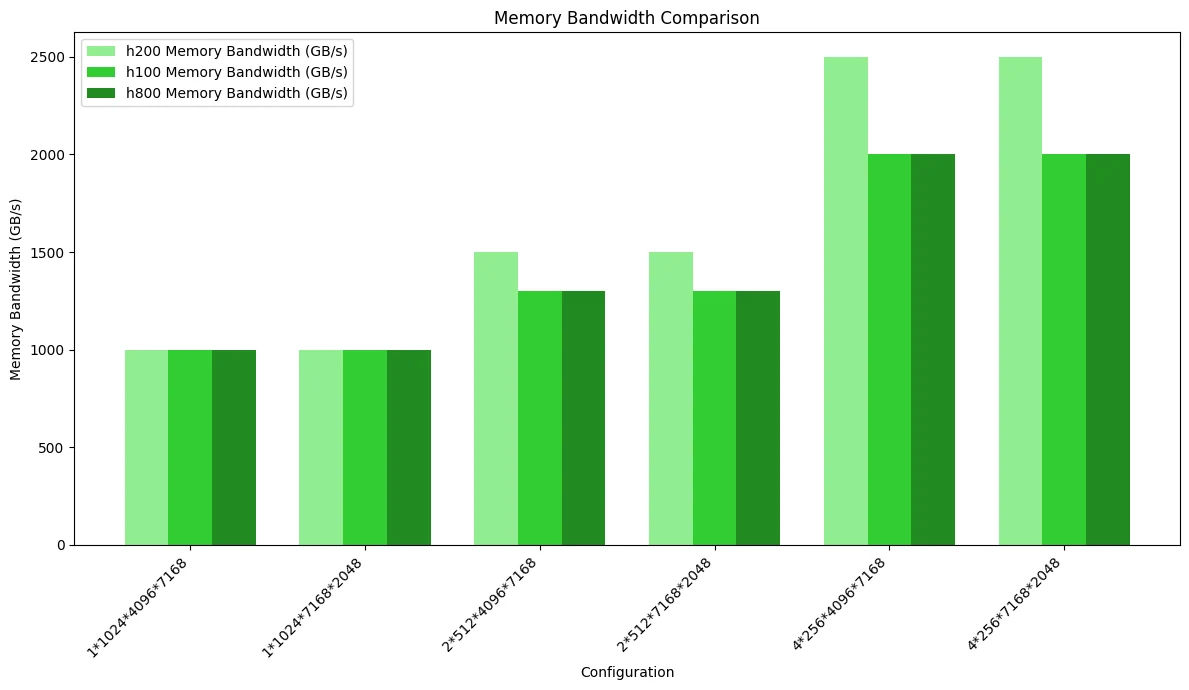
La siguiente figura es la prueba comparativa de rendimiento computacional, que destaca las diferencias causadas por el ancho de banda:
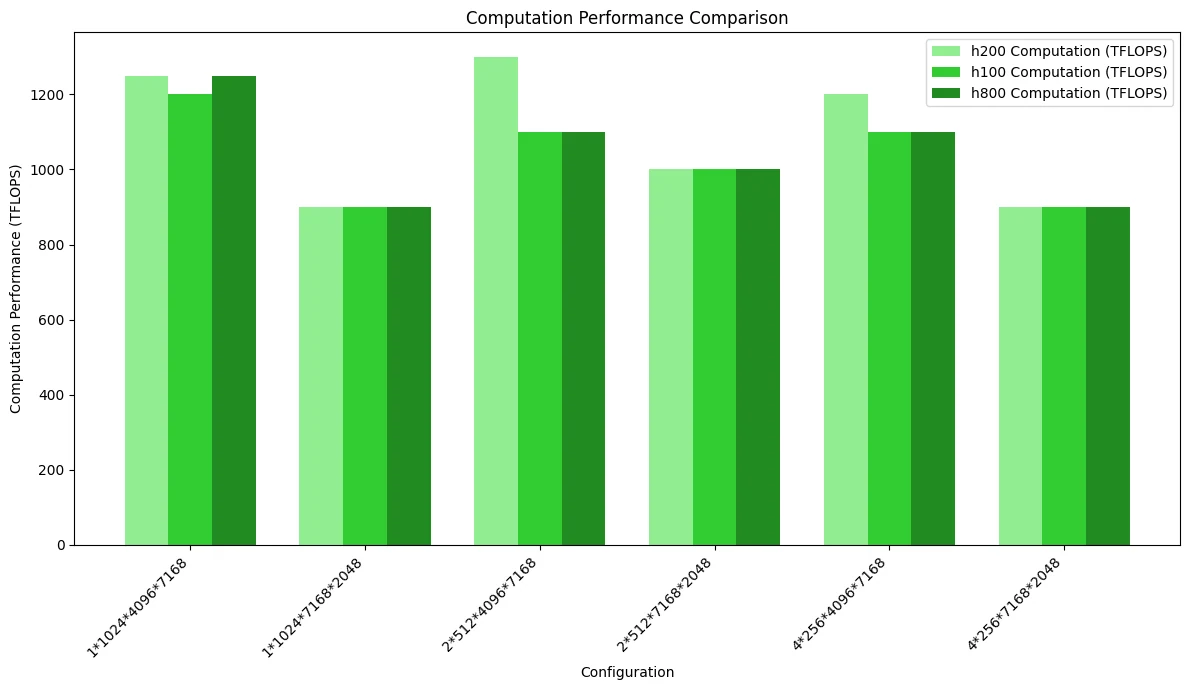
Comparación de Rendimiento entre DeepGEMM y SGLang Triton
Actualmente, los frameworks de inferencia principales utilizan operadores GEMM agrupados desarrollados basados en SGLang Triton para el módulo MoE. Realizamos pruebas de comparación de rendimiento entre DeepGEMM y SGLang Triton bajo condiciones de hardware H200:
DeepGEMM muestra ciertas ventajas en la disposición de almacenamiento continuo, pero SGLang Triton tiene un mejor rendimiento en la disposición de almacenamiento enmascarada. Actualmente, algunos de los operadores de SGLang Triton se aplican principalmente a escenarios de almacenamiento enmascarado. Por lo tanto, DeepGEMM requiere una optimización adicional para reemplazar a SGLang Triton en los frameworks de inferencia.
- Para modelos MoE que utilizan la disposición de almacenamiento continuo (pase adelante de entrenamiento, prefill de inferencia), DeepGEMM muestra ventajas más significativas.
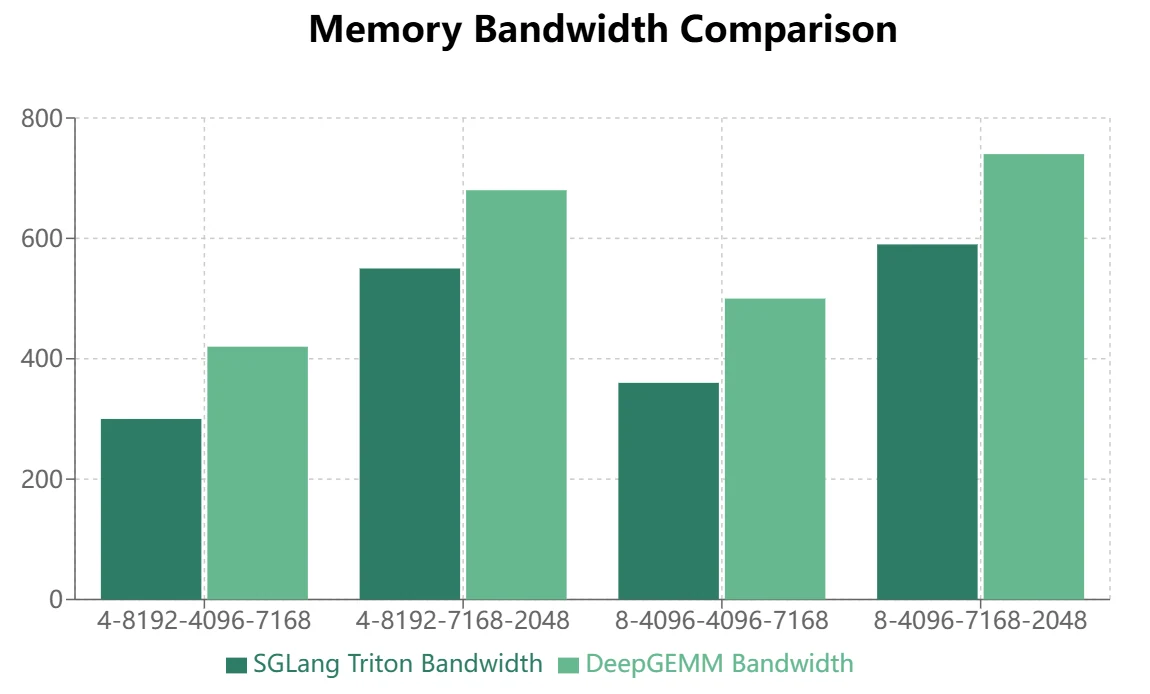
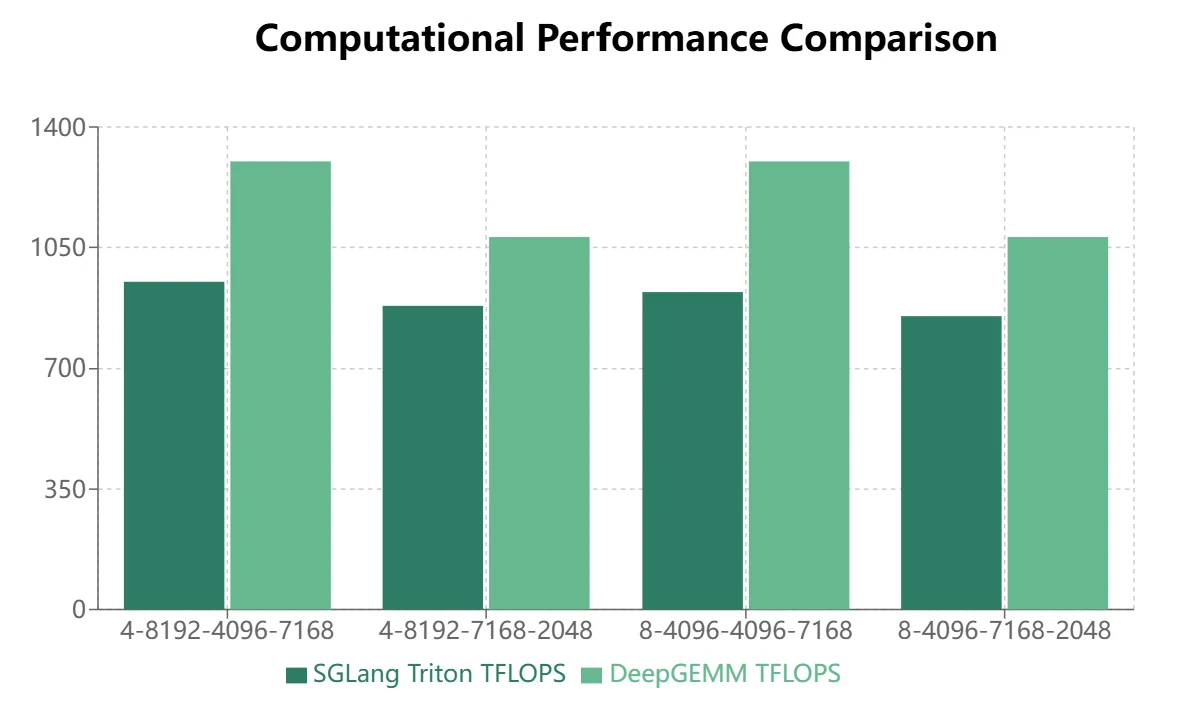
- Para modelos MoE que utilizan la disposición de almacenamiento enmascarada (decodificación de inferencia), Triton demuestra un rendimiento superior:
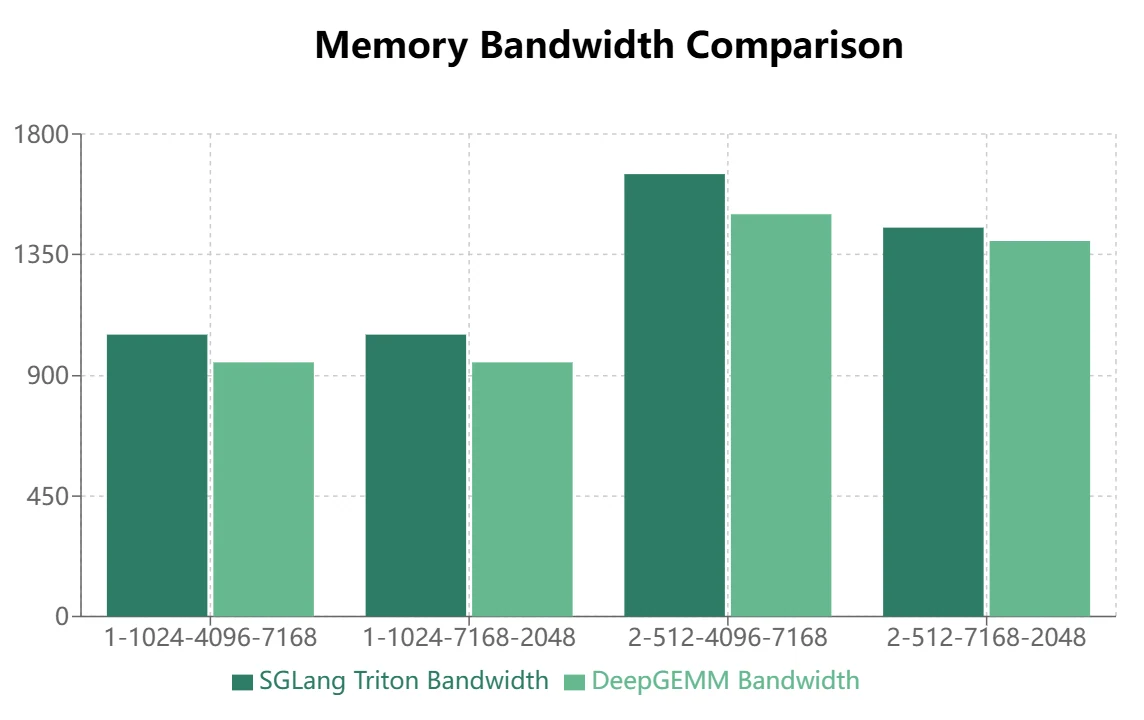
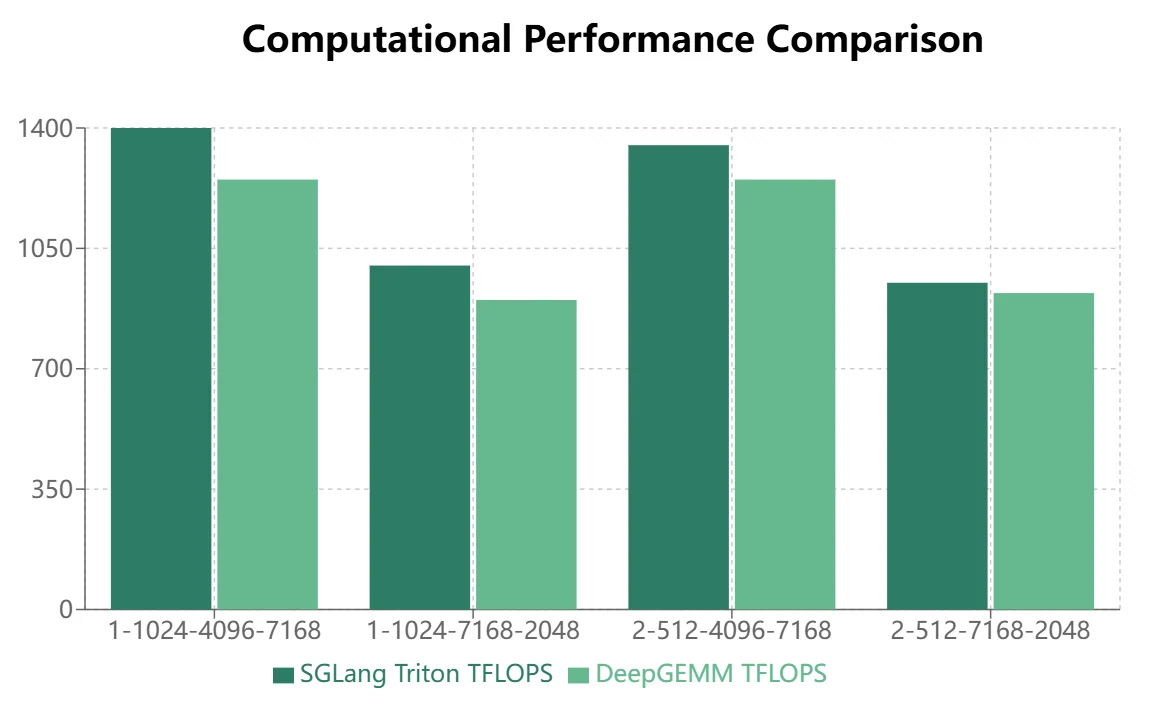
Conclusión
Los resultados de la evaluación demuestran que DeepGEMM exhibe capacidades de optimización de rendimiento significativas en múltiples GPU, incluyendo H100, H200 y H800, lo que destaca su fuerte versatilidad.
Para los modelos de la serie MoE (como DeepSeek V3 y R1) que se ejecutan en la arquitectura Hopper, integrar DeepGEMM en el framework de inferencia reemplazando los GEMM agrupados de la versión CUTLASS original podría proporcionar aproximadamente 1.2 veces de aceleración en la inferencia del modelo, mejorando el rendimiento general.
Actualmente, DeepGEMM no puede reemplazar completamente a SGLang Triton y requiere una optimización adicional para expandir su alcance de aplicación. En la decodificación de inferencia, SGLang Triton sigue siendo más eficiente, mientras que DeepGEMM muestra mayores ventajas en los pases adelante de entrenamiento y las etapas de prefill de inferencia.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona la GPU en la nube asequible y confiable para construir y escalar.
¡Obtén $20 en créditos y prueba DeepSeek ahora!



