

أمس هو اليوم الثالث من أسبوع المصادر المفتوحة، وقد أصدرت DeepSeek رسميًا مكتبة DeepGEMM مفتوحة المصدر.
هذه مكتبة حسابات FP8 GEMM مصممة خصيصًا للنماذج الكثيفة ونماذج MoE، مما يوفر دعمًا قويًا لتدريب واستنتاج النماذج الكمية FP8 مثل DeepSeek - V3/R1.
DeepGEMM تم تحسينها بشكل عميق لوحدات معالجة الرسوميات من بنية NVIDIA Hopper (مثل H100 وH200 وH800).
تشمل الميزات الرئيسية كودًا موجزًا (الجزء الأساسي يبلغ حوالي 300 سطر فقط) مع أداء متميز، يمكن أن يتفوق على المكتبات المعدلة يدويًا عبر أشكال مصفوفات مختلفة.
باعتبارها منصة سحابية مكرسة لتقديم خدمات حوسبة ذكاء اصطناعي عالية الأداء، قامت Novita AI بنشر عدد كبير من النماذج الكمية FP8 من نوع MoE (مثل إصدار DeepSeek FP8).
لاستخدام تقنية DeepGEMM بشكل أفضل وتعزيز كفاءة استنتاج هذه النماذج، أجرت Novita AI اختبارات أداء شاملة على DeepGEMM فور توفره.
قبل الخوض في بيانات الاختبار المحددة، دعنا نتعرف أولاً على بعض المفاهيم الأساسية ذات الصلة.
ما هو GEMM؟
GEMM (ضرب المصفوفات العام) هو العامل الحسابي الأساسي والأهم في التعلم العميق، وتحسين GEMM هو جوهر الحوسبة عالية الأداء في الذكاء الاصطناعي.
DeepGEMM هي مكتبة مفتوحة المصدر مصممة خصيصًا لتسريع عمليات GEMM الرئيسية في التعلم العميق، وتعزيز الأداء العام لنظام الذكاء الاصطناعي من خلال تحسين كفاءة حسابات GEMM.
المزايا الفريدة لـ DeepGEMM
بالمقارنة مع مكتبات القوالب الناضجة مثل CUTLASS وCuTe، تتبع DeepGEMM نهجًا تصميميًا خفيف الوزن: لا تهدف إلى التوافق الواسع مع جميع وحدات معالجة الرسوميات وسيناريوهات الحوسبة، بل تركز على الاستفادة الكاملة من قدرات الحوسبة FP8 في بنية Hopper، مع تحسين دقيق لأشكال المصفوفات الشائعة في النماذج الكبيرة مثل DeepSeek R1 وV3.
الابتكارات التكنولوجية لـ DeepGEMM
تحقق DeepGEMM اختراقات في الأداء من خلال الابتكارات التكنولوجية الأربعة التالية:
- الترجمة في الوقت المناسب (JIT)
تتطلب الطرق التقليدية تجميع كود CUDA مسبقًا قبل استدعائه، بينما تقوم تقنية JIT في DeepGEMM بإخفاء عملية التجميع في وقت التشغيل، مما يلغي الحاجة إلى التجميع اليدوي.
لا يحتاج المطورون إلى إنشاء واجهات Python معقدة، مما يبسط عملية التطوير ويتطلب بضعة أسطر فقط من الكود لتحقيق الوظائف.
- تحسين تداخل الحساب والنقل
تقوم DeepGEMM بتنفيذ عمليات نقل البيانات والحساب في وقت واحد، مستفيدة بالكامل من ميزة مسرع نقل الذاكرة (TMA) في بنية Hopper، مما يحسن كفاءة نقل البيانات. بالإضافة إلى ذلك، تستخدم DeepGEMM تعليمات PTX منخفضة المستوى لتحقيق أداء متطرف.
- دعم أحجام المصفوفات التعسفية
تتطلب تطبيقات GEMM التقليدية أن تكون أحجام المصفوفات قوى للعدد 2 (مثل 128 و256)، بينما تدعم DeepGEMM أحجام الكتل غير المنتظمة للمصفوفات. تتجنب هذه الميزة هدر الذاكرة وتحسن الكفاءة الحسابية الإجمالية.
- تحسين تعليمات FFMA SASS
من خلال تعديل بتات العائد وإعادة الاستخدام لتعليمات FFMA، يتم إنشاء فرص أكبر لتداخل تعليمات MMA مع تعليمات FFMA الترقيعية، مما يؤدي إلى تحسينات في الأداء تزيد عن 10% في بعض السيناريوهات، حتى مع فهم محدود للبنية الأساسية.
تقييم Novita AI المباشر: عمومية DeepGEMM
في سيناريوهات استنتاج نماذج MoE، أجرت Novita AI اختبارات أداء مفصلة لـ DeepGEMM على وحدات معالجة الرسوميات H100 وH200 وقارنت النتائج مع بيانات H800 الرسمية.
أولاً، لخصنا المعايير الرئيسية لوحدات معالجة الرسوميات H100 وH200 وH800 التي تؤثر على أداء DeepGEMM:
| المقياس | H100 SXM | H200 SXM | H800 SXM |
|---|---|---|---|
| قوة حوسبة FP8 | 3958 TFLOPS | 3958 TFLOPS | 3958 TFLOPS |
| عرض نطاق الذاكرة | 3.35 تيرابايت/ثانية | 4.8 تيرابايت/ثانية | 3.35 تيرابايت/ثانية |
نموذج MoE: GEMM مجمّع مع تخطيط تخزين مستمر (مرور التدريب الأمامي، ملء الاستنتاج)
في شبكات MoE التي تستخدم تخطيط التخزين المستمر، تكون الاختلافات في الأداء بين H100 وH200 وH800 (الرسمية) ضئيلة.
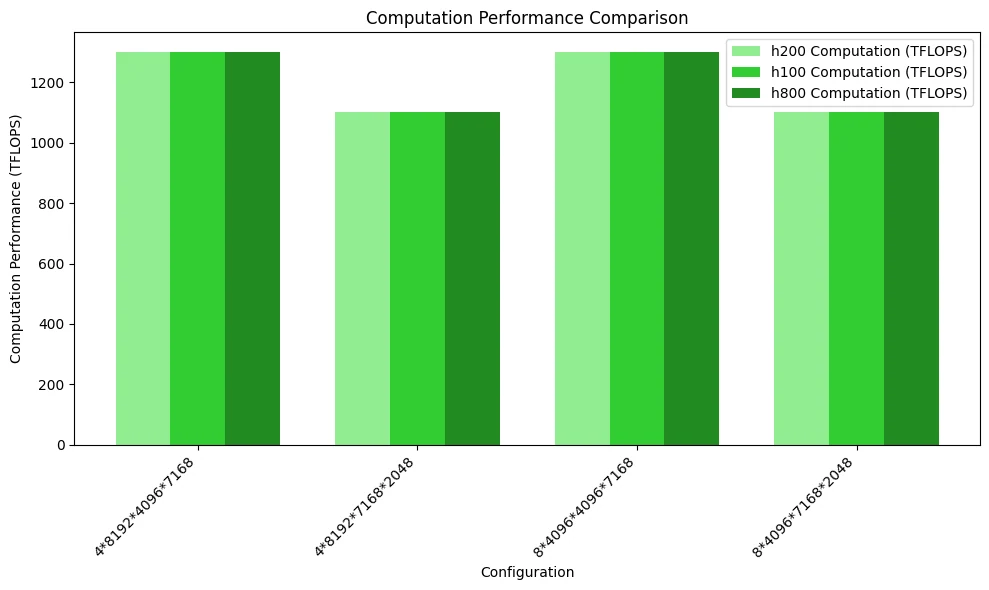
يوضح الشكل أدناه اختبار مقارنة استخدام عرض نطاق الذاكرة. بسبب الاختناقات الحسابية وقوة حوسبة FP8 المتشابهة لوحدات المعالجة الرسومية الثلاث، لا تظهر أداؤها أي اختلافات كبيرة.
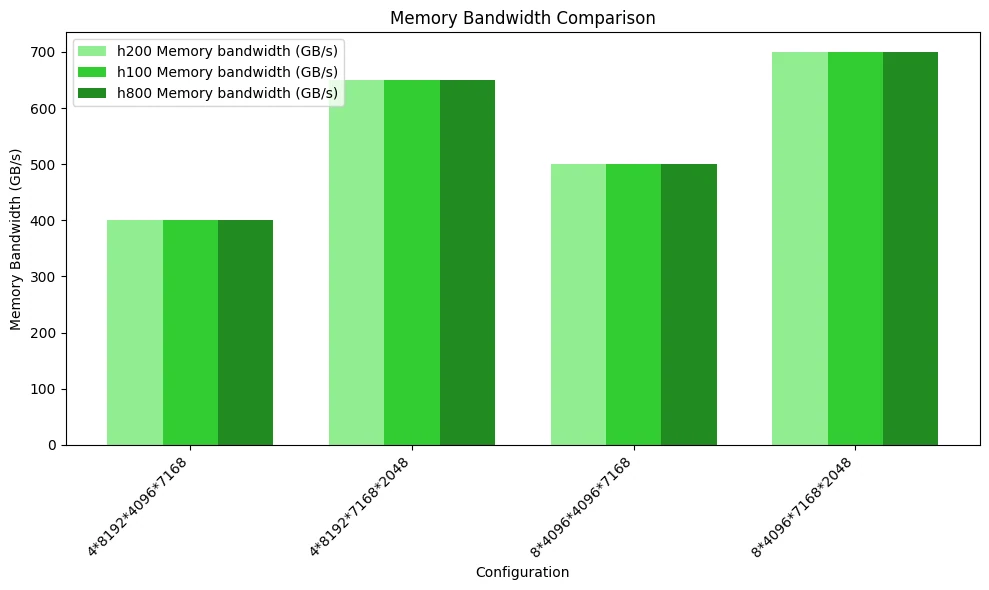
يوضح الشكل أدناه مقارنة الأداء الحسابي. نظرًا لعدم الوصول إلى اختناق الوصول إلى الذاكرة، لا تظهر اختلافات ملحوظة في أداء وحدات المعالجة الرسومية الثلاث.
نموذج MoE: GEMM مجمّع مع تخطيط تخزين مقنّع (فك تشفير الاستنتاج)
في شبكات MoE التي تستخدم تخطيط التخزين المقنّع، يظهر H200 أفضل أداء، بينما تكون الاختلافات بين H100 وH800 صغيرة جدًا.
يوضح الشكل أدناه اختبار مقارنة استخدام عرض نطاق الذاكرة. نظرًا لأن تخطيط التخزين المقنّع يستهلك عرض نطاق ذاكرة أكبر من التخزين المستمر، فقد وصلت بعض السيناريوهات إلى اختناق الوصول إلى الذاكرة، مما يؤدي إلى اختلافات في الأداء بين وحدات المعالجة الرسومية الثلاث:
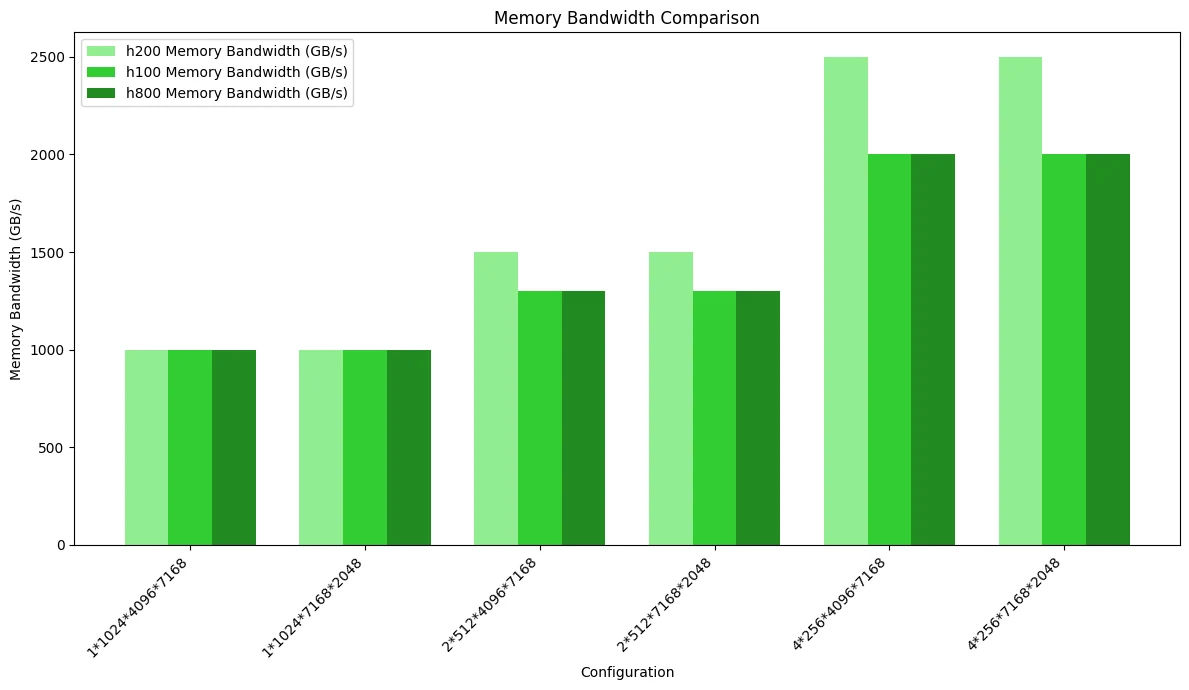
يوضح الشكل أدناه اختبار مقارنة الأداء الحسابي، مسلطًا الضوء على الاختلافات الناجمة عن عرض النطاق:
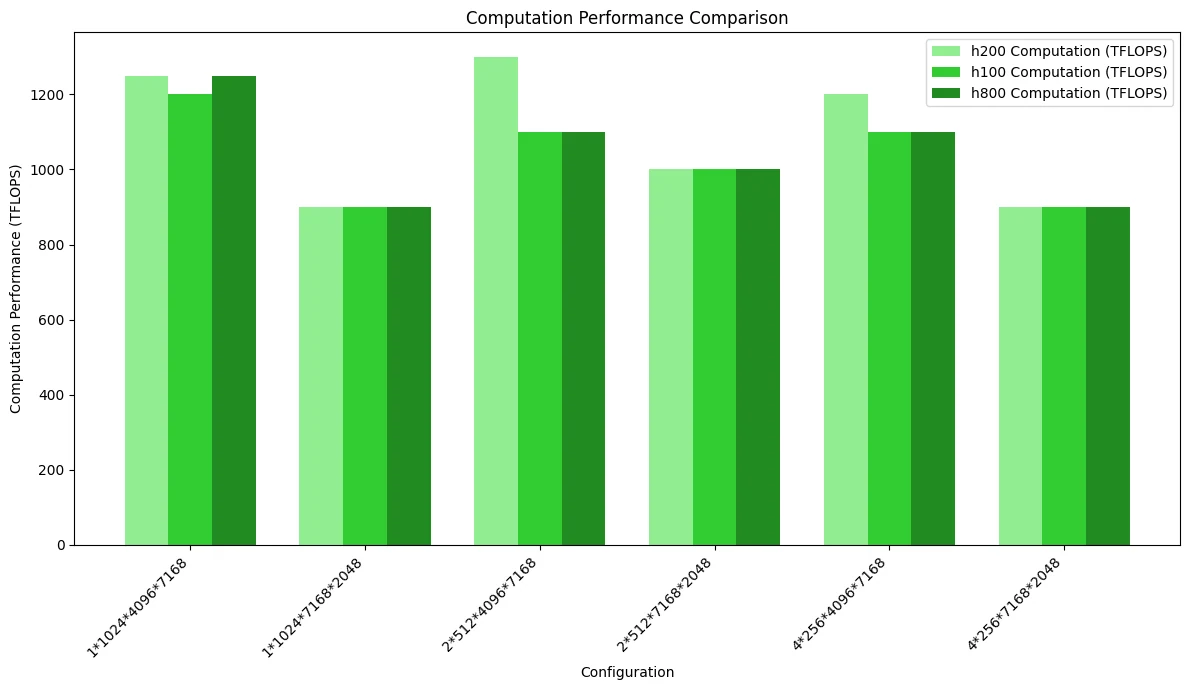
مقارنة أداء DeepGEMM مقابل SGLang Triton
حاليًا، تستخدم أطر الاستنتاج السائدة عمليات GEMM المجمعة المطورة بناءً على SGLang Triton لوحدة MoE. أجرينا اختبارات مقارنة أداء بين DeepGEMM وSGLang Triton على أجهزة H200:
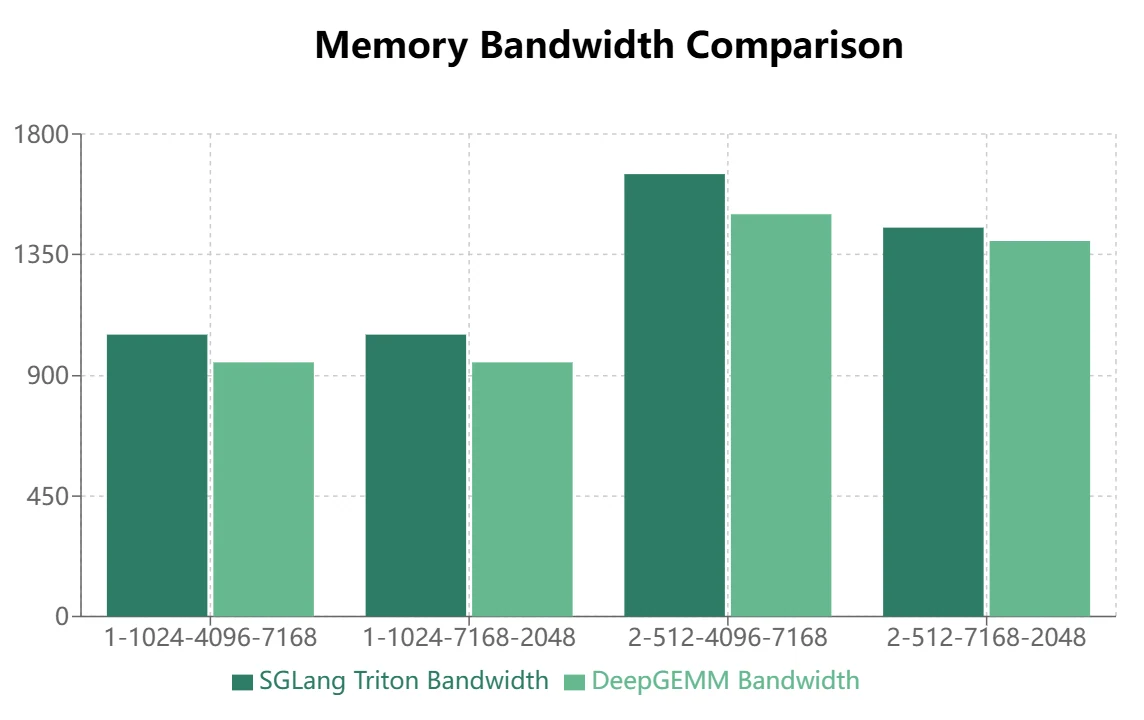
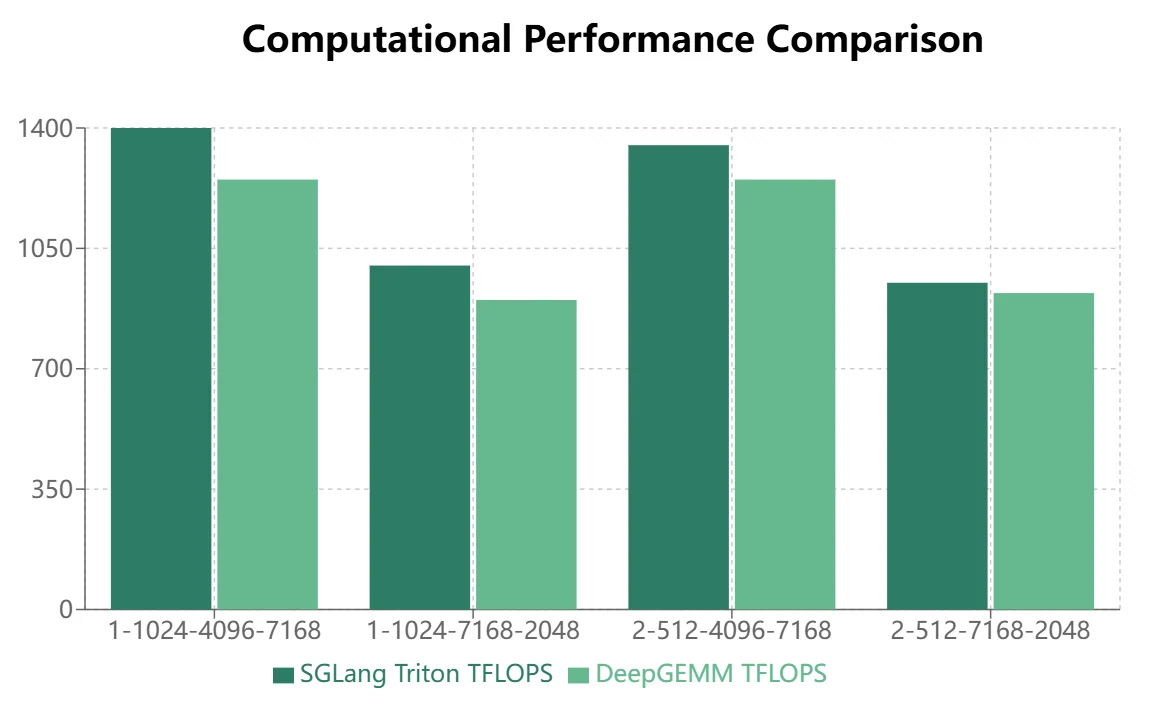
يُظهر DeepGEMM مزايا معينة في تخطيط التخزين المستمر، لكن SGLang Triton يؤدي بشكل أفضل في تخطيط التخزين المقنّع. حاليًا، يتم تطبيق بعض عمليات SGLang Triton بشكل أساسي على سيناريوهات التخزين المقنّع. لذلك، يتطلب DeepGEMM مزيدًا من التحسين لاستبدال SGLang Triton في أطر الاستنتاج.
- بالنسبة لنماذج MoE التي تستخدم تخطيط التخزين المستمر (مرور التدريب الأمامي، ملء الاستنتاج)، تظهر مزايا DeepGEMM بشكل أكثر وضوحًا.
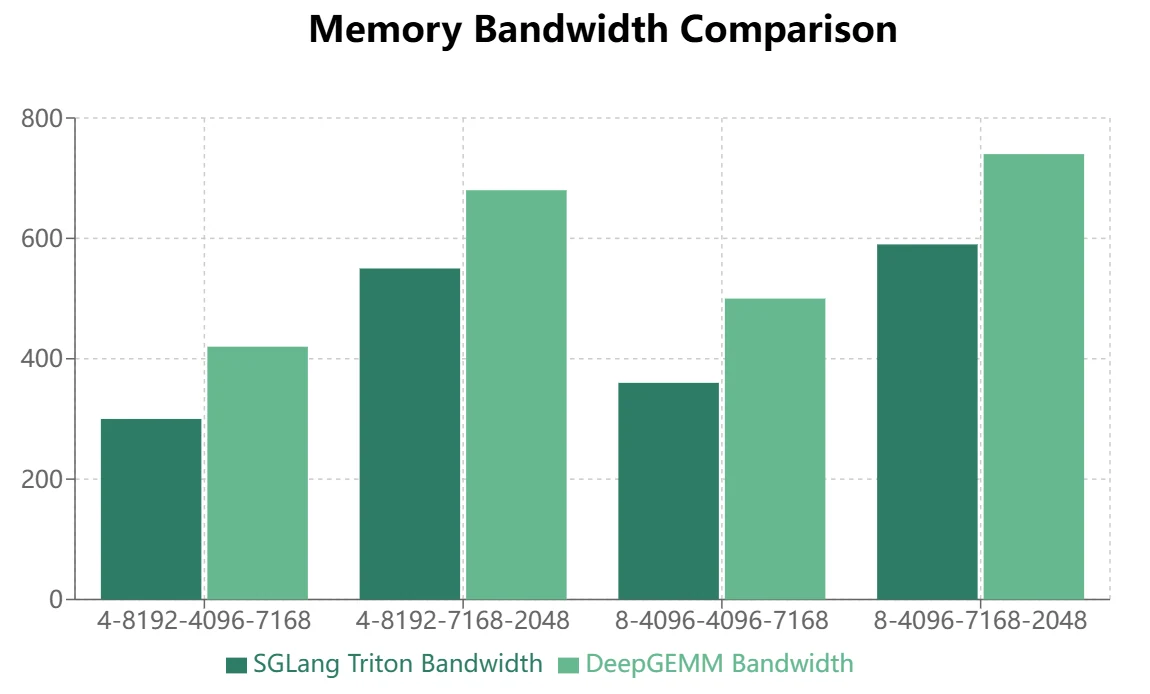
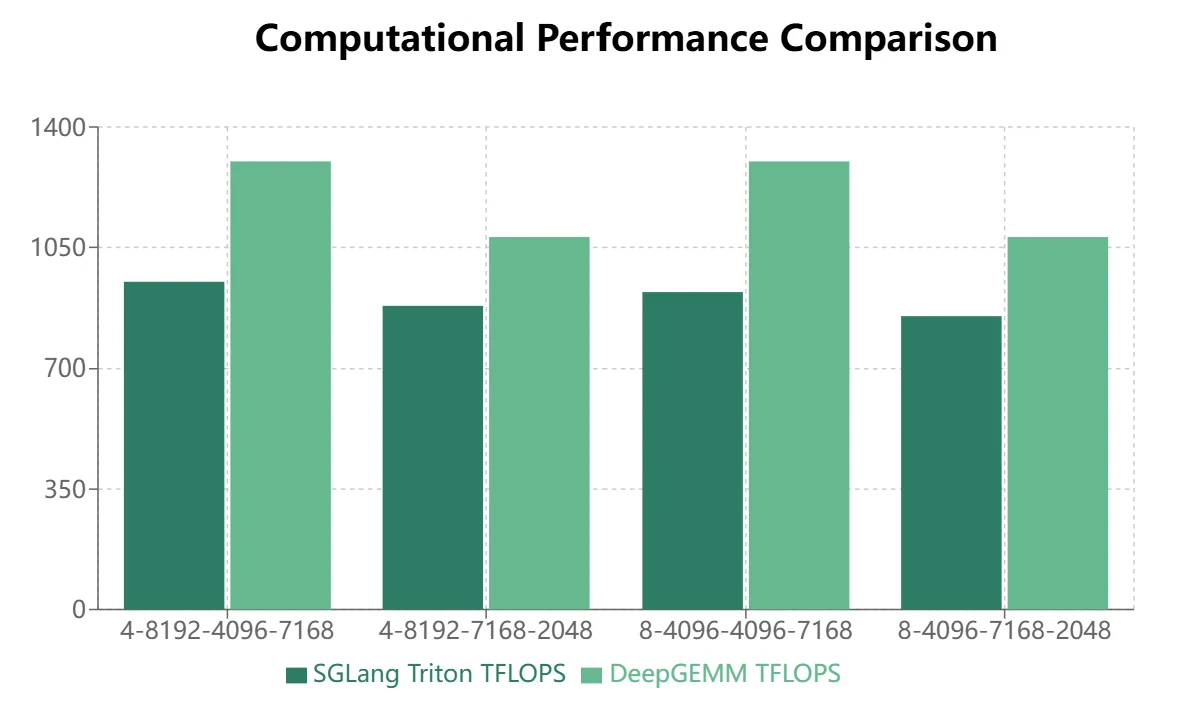
- بالنسبة لنماذج MoE التي تستخدم تخطيط التخزين المقنّع (فك تشفير الاستنتاج)، يظهر Triton أداءً متفوقًا:
الخلاصة
تُظهر نتائج التقييم أن DeepGEMM يُظهر قدرات تحسين أداء كبيرة عبر وحدات معالجة رسومية متعددة، بما في ذلك H100 وH200 وH800، مما يبرز عموميته القوية.
بالنسبة لنماذج سلسلة MoE (مثل DeepSeek V3 وR1) التي تعمل على بنية Hopper، يُتوقع أن يؤدي دمج DeepGEMM في إطار الاستنتاج عن طريق استبدال GEMMات المجمعة من إصدار CUTLASS الأصلية إلى تحقيق تسريع يبلغ حوالي 1.2x في استنتاج النموذج، مما يعزز الأداء العام.
حاليًا، لا يمكن لـ DeepGEMM استبدال SGLang Triton بالكامل، ويتطلب مزيدًا من التحسين لتوسيع نطاق تطبيقه. في فك تشفير الاستنتاج، يظل SGLang Triton أكثر كفاءة، بينما يُظهر DeepGEMM مزايا أكبر في مرورات التدريب الأمامية ومراحل ملء الاستنتاج.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة لدينا، مع توفير سحابة GPU موثوقة وبأسعار معقولة للبناء والتوسع.
احصل على 20 دولارًا ائتمانًا وجرب DeepSeek الآن!



