

Вчера был третий день Недели открытого исходного кода, и DeepSeek официально выпустил библиотеку с открытым исходным кодом DeepGEMM.
Это библиотека вычислений GEMM с FP8, специально разработанная для плотных и MoE-моделей, обеспечивающая мощную поддержку обучения и инференса MoE-моделей с FP8-квантованием, таких как DeepSeek-V3/R1.
DeepGEMM глубоко оптимизирован для графических процессоров архитектуры NVIDIA Hopper (например, H100, H200, H800).
Основные особенности включают лаконичный код (основная часть — всего около 300 строк) и выдающуюся производительность, которая может соответствовать или даже превосходить экспертно настроенные библиотеки для различных форм матриц.
Будучи облачной платформой, предоставляющей высокопроизводительные AI-вычислительные услуги, Novita AI развернула большое количество MoE-моделей с FP8-квантованием (например, DeepSeek FP8 версии).
Чтобы лучше использовать технологию DeepGEMM и повысить эффективность инференса этих моделей, Novita AI сразу же провела всестороннее тестирование производительности DeepGEMM.
Прежде чем углубиться в конкретные данные тестов, давайте сначала ознакомимся с некоторыми релевантными базовыми понятиями.
Что такое GEMM?
GEMM (General Matrix Multiplication) — это самый фундаментальный и важный вычислительный оператор в глубоком обучении, а оптимизация GEMM является ядром высокопроизводительных AI-вычислений.
DeepGEMM — это библиотека с открытым исходным кодом, предназначенная для ускорения ключевых операций GEMM в глубоком обучении, повышающая общую производительность AI-системы за счёт улучшения эффективности вычислений GEMM.
Уникальные преимущества DeepGEMM
По сравнению с зрелыми библиотеками-шаблонами, такими как CUTLASS и CuTe, DeepGEMM использует легковесный подход к проектированию: он не стремится к широкой совместимости со всеми GPU и вычислительными сценариями, а сосредоточен на полном использовании вычислительных возможностей FP8 архитектуры Hopper с тщательной оптимизацией для форм матриц, обычно используемых в больших моделях, таких как DeepSeek R1 и V3.
Технологические инновации DeepGEMM
DeepGEMM достигает прорывов в производительности благодаря следующим четырём ключевым технологическим инновациям:
- Just-In-Time компиляция (JIT)
Традиционные методы требуют предварительной компиляции кода CUDA перед вызовом, в то время как технология JIT в DeepGEMM скрывает процесс компиляции во время выполнения, устраняя необходимость в ручной компиляции.
Разработчикам не нужно создавать сложные интерфейсы Python, что упрощает процесс разработки и позволяет достичь функциональности всего несколькими строками кода.
- Оптимизация перекрытия вычислений и передачи данных
DeepGEMM выполняет операции передачи данных и вычислений одновременно, полностью используя функцию Tensor Memory Accelerator (TMA) архитектуры Hopper, что дополнительно оптимизирует эффективность передачи данных. Кроме того, DeepGEMM использует низкоуровневые инструкции PTX для достижения экстремальной производительности.
- Поддержка произвольных размеров матриц
Традиционные реализации GEMM требуют, чтобы размеры матриц были степенями двойки (например, 128, 256), в то время как DeepGEMM поддерживает невыровненные размеры блоков для матриц. Эта функция позволяет избежать потерь памяти и повышает общую вычислительную эффективность.
- Оптимизация на уровне инструкций FFMA SASS
Путём изменения битов yield и reuse инструкций FFMA создаётся больше возможностей для перекрытия инструкций MMA с инструкциями promotion FFMA, что приводит к повышению производительности более чем на 10% в некоторых сценариях, даже при ограниченном понимании базовой архитектуры.
Первая оценка Novita AI: универсальность DeepGEMM
В сценариях инференса MoE-моделей Novita AI провела детальное тестирование производительности DeepGEMM на GPU H100 и H200 и сравнила результаты с официальными эталонными данными H800.
Сначала мы обобщили ключевые аппаратные параметры GPU H100, H200 и H800, влияющие на производительность DeepGEMM:
| Параметр | H100 SXM | H200 SXM | H800 SXM |
|---|---|---|---|
| Вычислительная мощность FP8 | 3958 TFLOPS | 3958 TFLOPS | 3958 TFLOPS |
| Пропускная способность памяти | 3,35 ТБ/с | 4,8 ТБ/с | 3,35 ТБ/с |
MoE-модель: Grouped GEMM с непрерывным размещением в памяти (прямой проход обучения, префилл инференса)
В MoE-сетях, использующих непрерывное размещение в памяти, различия в производительности между H100, H200 и H800 (официальные данные) минимальны.
На рисунке ниже показан сравнительный тест использования пропускной способности памяти. Из-за вычислительных узких мест и схожей вычислительной мощности FP8 трёх GPU их производительность не имеет значительных различий.
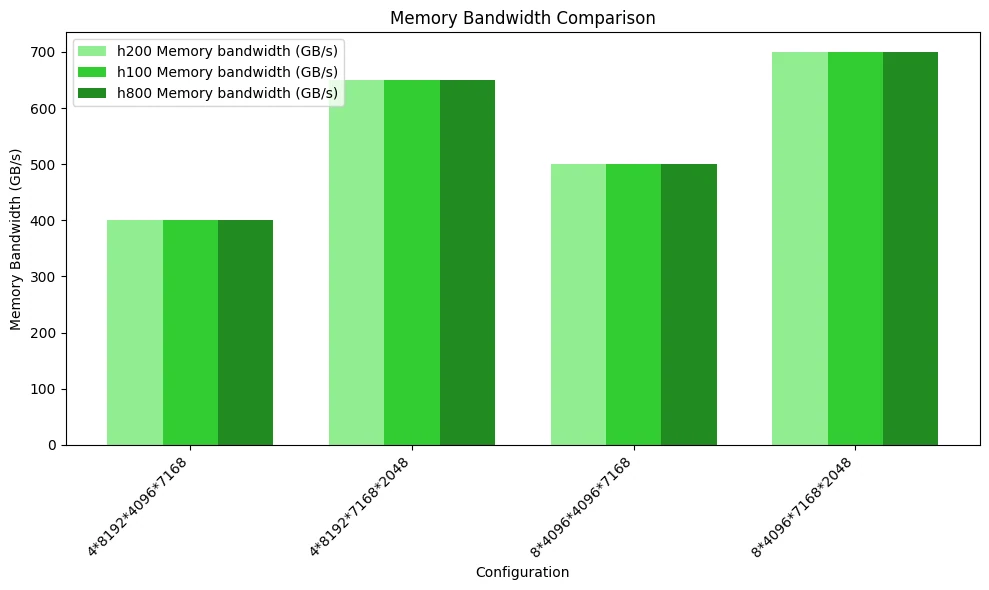
На рисунке ниже показано сравнение вычислительной производительности. Поскольку узкое место по доступу к памяти не было достигнуто, производительность трёх GPU не имеет заметных различий.
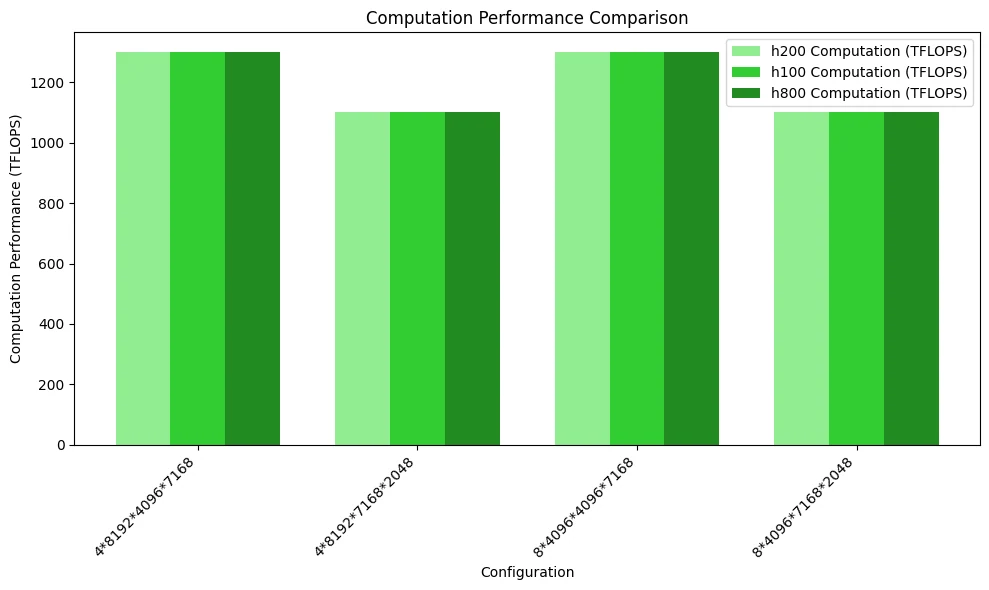
MoE-модель: Grouped GEMM с маскированным размещением в памяти (декодинг инференса)
В MoE-сетях, использующих маскированное размещение в памяти, H200 демонстрирует наилучшую производительность, в то время как различия между H100 и H800 очень малы.
На рисунке ниже показан сравнительный тест использования пропускной способности памяти. Поскольку маскированное размещение потребляет больше пропускной способности памяти, чем непрерывное, некоторые сценарии достигли узкого места по доступу к памяти, что приводит к различиям в производительности трёх GPU:
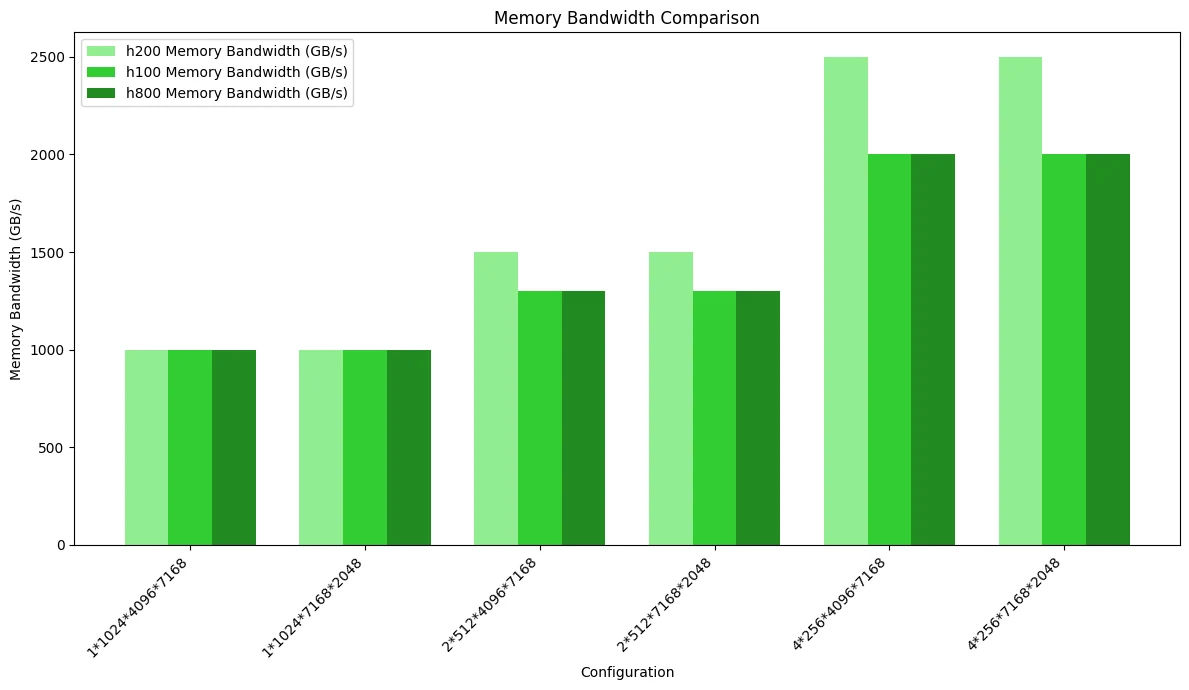
На рисунке ниже — тест сравнения вычислительной производительности, подчёркивающий различия, вызванные пропускной способностью:
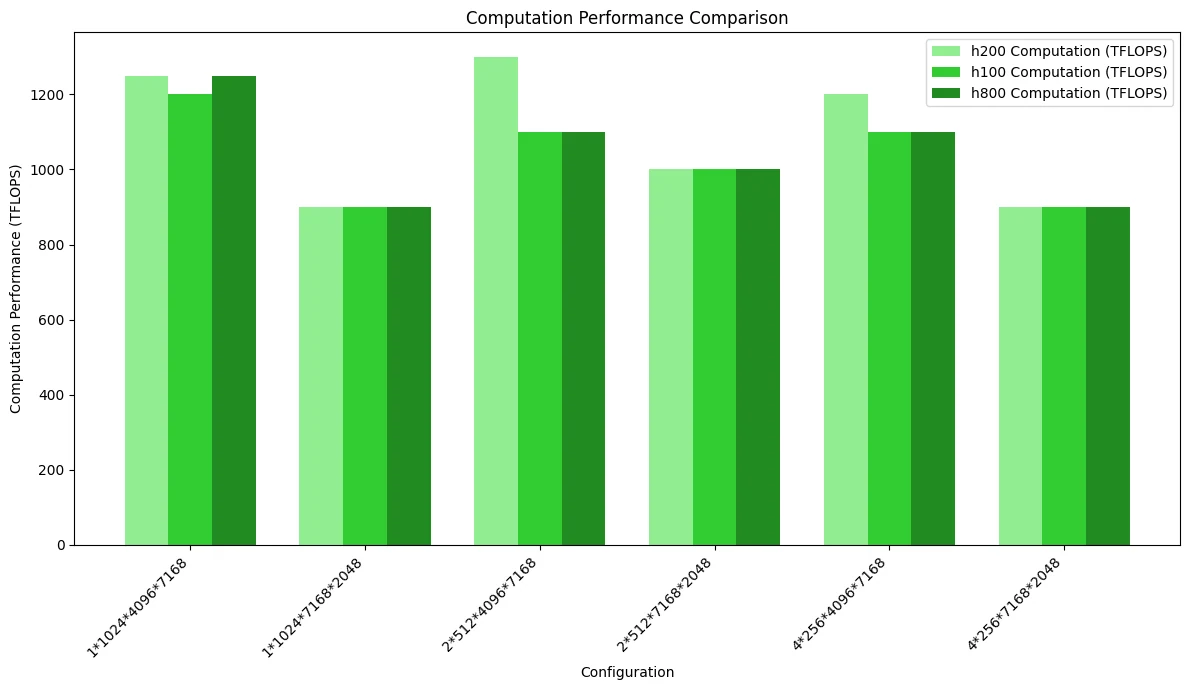
Сравнение производительности DeepGEMM и SGLang Triton
В настоящее время основные фреймворки инференса используют операторы grouped GEMM, разработанные на основе SGLang Triton для модуля MoE. Мы провели сравнительное тестирование производительности DeepGEMM и SGLang Triton на оборудовании H200:
DeepGEMM демонстрирует определённые преимущества при непрерывном размещении, но SGLang Triton показывает лучшие результаты при маскированном размещении. В настоящее время некоторые операторы SGLang Triton в основном применяются в сценариях с маскированным размещением. Поэтому DeepGEMM требует дальнейшей оптимизации, чтобы заменить SGLang Triton в фреймворках инференса.
- Для MoE-моделей, использующих непрерывное размещение в памяти (прямой проход обучения, префилл инференса), DeepGEMM демонстрирует более значительные преимущества.
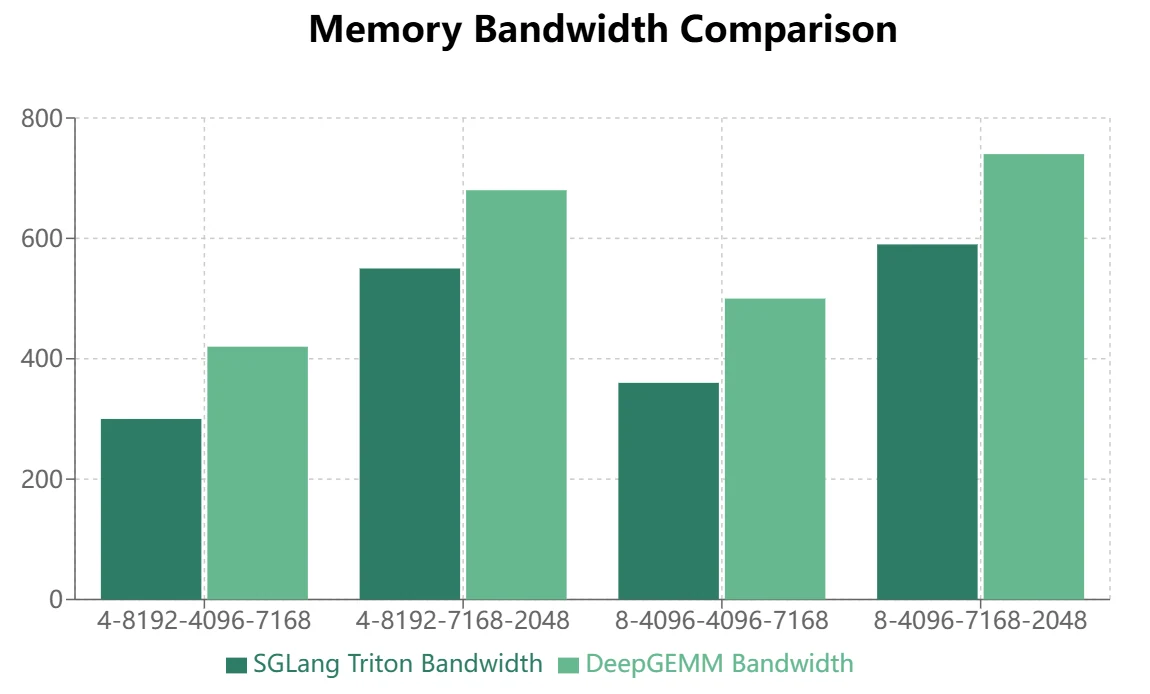
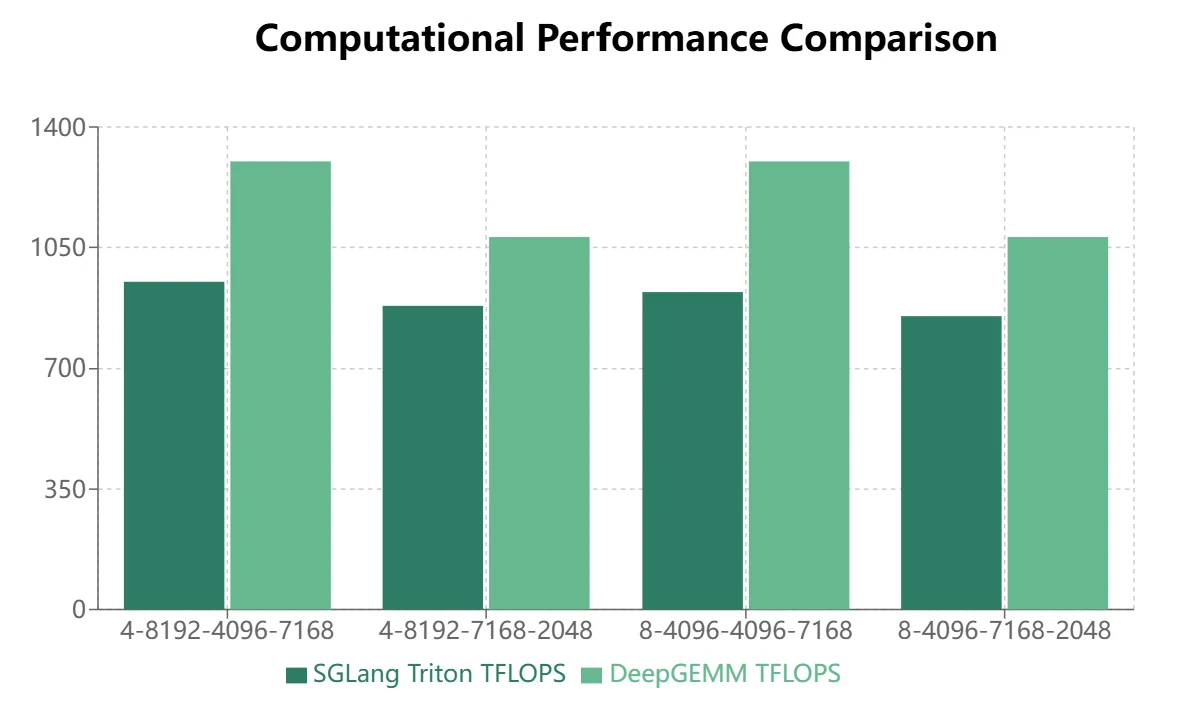
- Для MoE-моделей, использующих маскированное размещение в памяти (декодинг инференса), Triton показывает превосходную производительность:
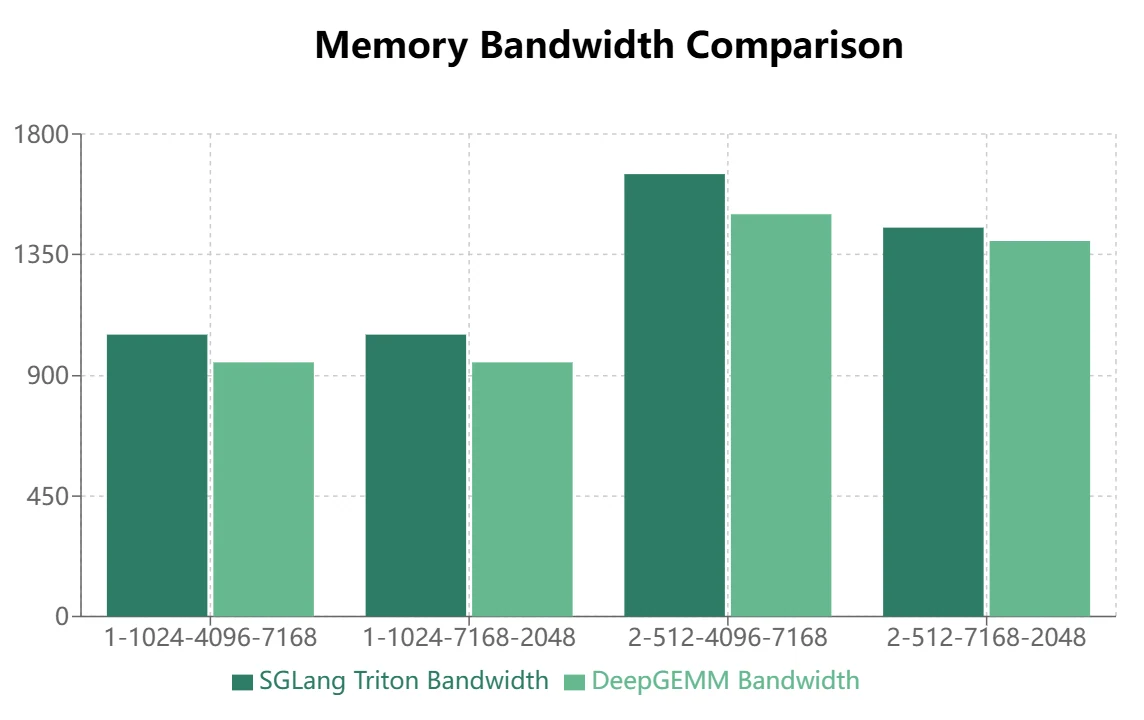
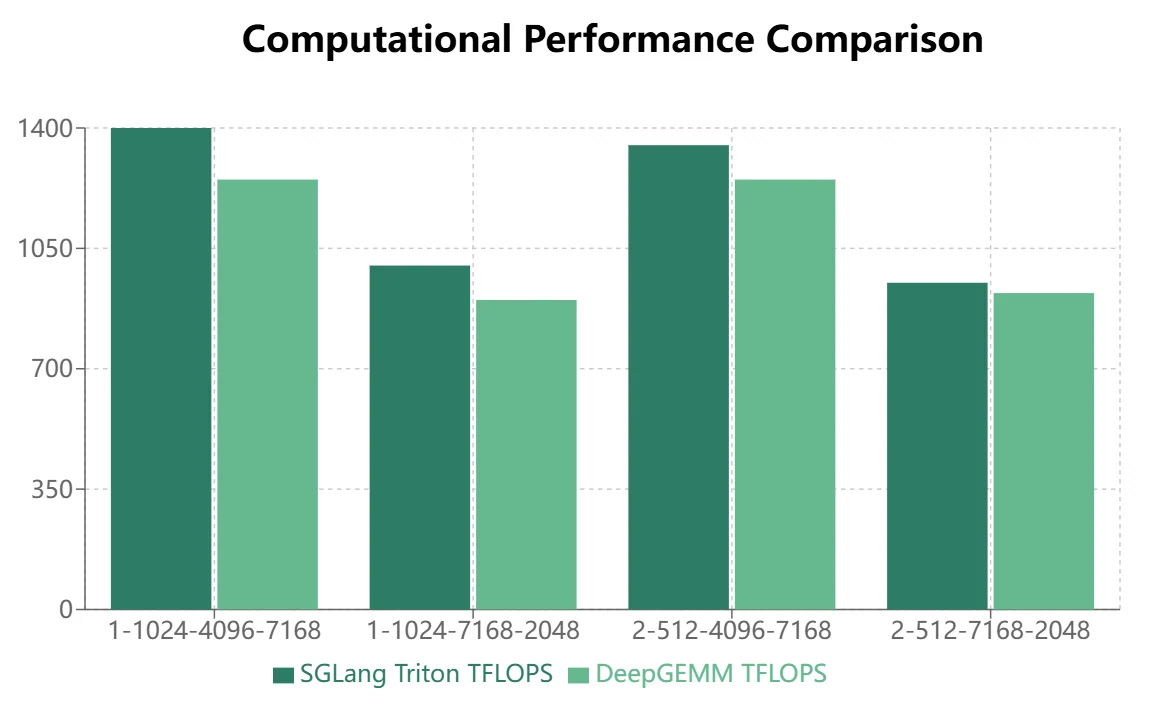
Заключение
Результаты оценки показывают, что DeepGEMM демонстрирует значительные возможности оптимизации производительности на нескольких GPU, включая H100, H200 и H800, что подчёркивает его высокую универсальность.
Для MoE-моделей (таких как DeepSeek V3 и R1), работающих на архитектуре Hopper, интеграция DeepGEMM в фреймворк инференса путём замены исходной версии grouped GEMM из CUTLASS может обеспечить примерно 1,2-кратное ускорение инференса модели, повышая общую производительность.
В настоящее время DeepGEMM не может полностью заменить SGLang Triton и требует дальнейшей оптимизации для расширения сферы применения. При декодинге инференса SGLang Triton остаётся более эффективным, в то время как DeepGEMM показывает большие преимущества на этапах прямого прохода обучения и префилла инференса.
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развёртывания AI-моделей с помощью нашего простого API, а также предлагает доступный и надёжный облачный GPU для создания и масштабирования.
Получите $20 кредитов и попробуйте DeepSeek сейчас!



