昨日はオープンソースウィークの3日目であり、DeepSeekはDeepGEMMオープンソースライブラリを正式にリリースしました。
これは、DenseモデルおよびMoEモデル向けに特別に設計されたFP8 GEMM計算ライブラリであり、DeepSeek V3/R1などのMoE FP8量子化モデルのトレーニングと推論を強力にサポートします。
DeepGEMM は、NVIDIA HopperアーキテクチャのGPU(H100、H200、H800など)向けに深く最適化されています。
主な特徴は、簡潔なコード(コア部分は約300行のみ)でありながら優れたパフォーマンスを発揮し、さまざまな行列形状において専門家がチューニングしたライブラリと同等かそれ以上を実現します。
高性能AIコンピューティングサービスを提供するクラウドプラットフォームとして、Novita AIは多数のMoE FP8量子化モデル(DeepSeek FP8バージョンなど)をデプロイしています。
DeepGEMMテクノロジーをより活用し、これらのモデルの推論効率を向上させるため、Novita AIは入手後すぐにDeepGEMMの包括的なパフォーマンステストを実施しました。
具体的なテストデータに入る前に、関連する基本的な概念をいくつか確認しましょう。
What is GEMM?
GEMM(General Matrix Multiplication)は、ディープラーニングにおいて最も基本的で重要な計算演算子であり、GEMMの最適化は高性能AIコンピューティングの中核です。
DeepGEMMは、ディープラーニングにおける主要なGEMM演算を高速化するために特別に設計されたオープンソースライブラリであり、GEMM計算効率を向上させることでAIシステム全体のパフォーマンスを強化します。
Unique Advantages of DeepGEMM
CUTLASSやCuTeなどの成熟したテンプレートライブラリと比較して、DeepGEMMは軽量な設計アプローチを採用しています。すべてのGPUや計算シナリオとの幅広い互換性を目指すのではなく、HopperアーキテクチャのFP8計算能力を最大限に活用することに焦点を当て、DeepSeek R1やV3のような大規模モデルで一般的に使用される行列形状に対して緻密な最適化を行っています。
Technological Innovations of DeepGEMM
DeepGEMMは、以下の4つのコア技術革新によりパフォーマンスの飛躍的向上を実現しています:
- Just-In-Time Compilation (JIT)
従来の方法では、CUDAコードを呼び出す前に事前にコンパイルする必要がありましたが、DeepGEMMのJIT技術はコンパイルプロセスを実行時に隠蔽し、手動でのコンパイルを不要にします。
開発者は複雑なPythonインターフェースを作成する必要がなく、開発プロセスが簡素化され、わずか数行のコードで機能を実現できます。
- Computation and Transfer Overlap Optimization
DeepGEMMは、データ転送と計算操作を同時に実行し、HopperアーキテクチャのTensor Memory Accelerator(TMA)機能を完全に活用してデータ転送効率をさらに最適化します。さらに、DeepGEMMは低レベルのPTX命令を使用して極限のパフォーマンスを実現します。
- Support for Arbitrary Matrix Sizes
従来のGEMM実装では、行列サイズが2のべき乗(128、256など)である必要がありましたが、DeepGEMMは行列の非整列ブロックサイズをサポートします。この機能によりメモリの無駄を回避し、全体的な計算効率が向上します。
- FFMA SASS Instruction-Level Optimization
FFMA命令のyieldビットとreuseビットを変更することで、MMA命令とプロモーションFFMA命令をオーバーラップさせる機会が増え、基礎となるアーキテクチャの理解が限られている場合でも、特定のシナリオで10%以上のパフォーマンス向上が実現されます。
Novita AI First-Hand Evaluation: DeepGEMM Universality
MoEモデルの推論シナリオにおいて、Novita AIはH100およびH200 GPUでDeepGEMMの詳細なパフォーマンステストを実施し、その結果を公式のH800ベンチマークデータと比較しました。
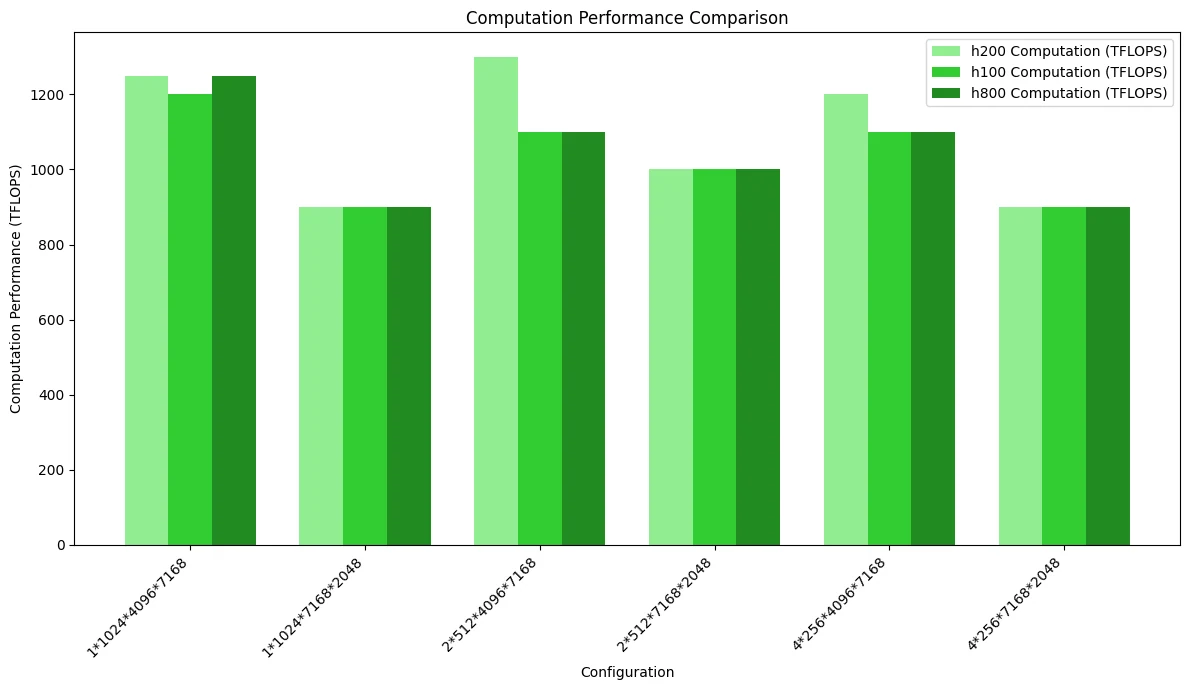
まず、DeepGEMMのパフォーマンスに影響を与えるH100、H200、H800 GPUの主要なハードウェアパラメータをまとめました:
| **指標 ** | H100 SXM | H200 SXM | H800 SXM |
|---|---|---|---|
| FP8計算能力 | 3958 TFLOPS | 3958 TFLOPS | 3958 TFLOPS |
| メモリ帯域幅 | 3.35 TB/s | 4.8 TB/s | 3.35 TB/s |
MoE Model: Grouped GEMM with Continuous Storage Layout (Training Forward Pass, Inference Prefill)
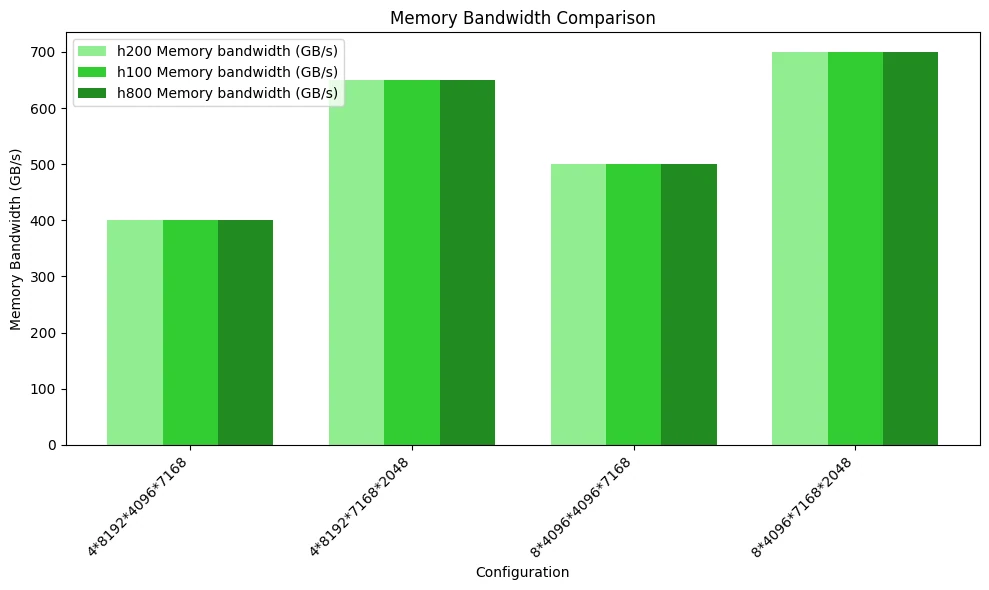
連続ストレージレイアウトを使用するMoEネットワークでは、H100、H200、H800(公式)のパフォーマンス差はわずかです。
下図はメモリ帯域幅使用率の比較テストを示しています。計算ボトルネックと3つのGPUのFP8計算能力が類似しているため、性能に有意な差は見られません。
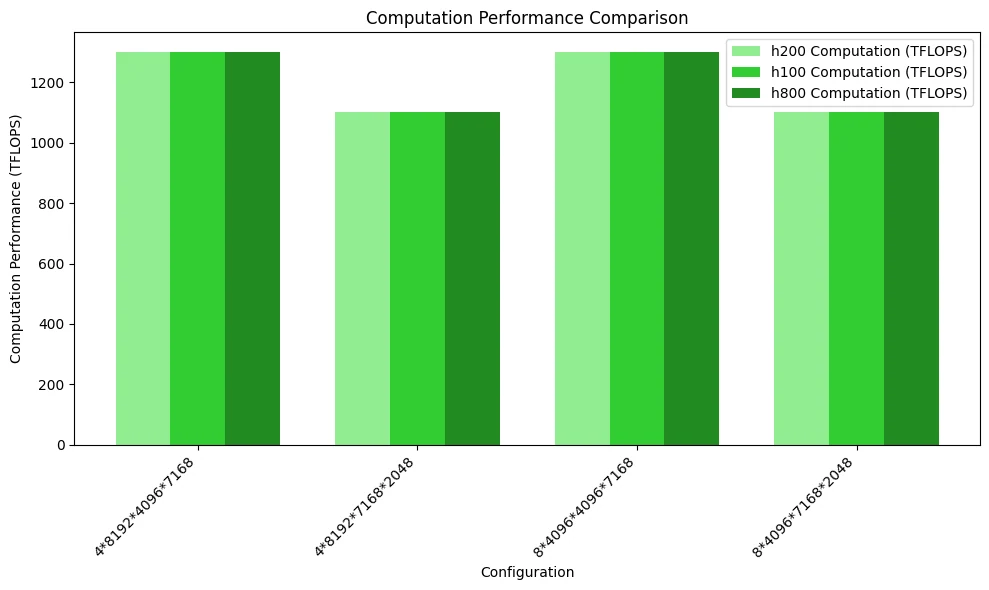
下図は計算パフォーマンスの比較を示しています。メモリアクセスのボトルネックに達していないため、3つのGPUの性能に顕著な差はありません。
MoE Model: Grouped GEMM with Masked Storage Layout (Inference Decoding)
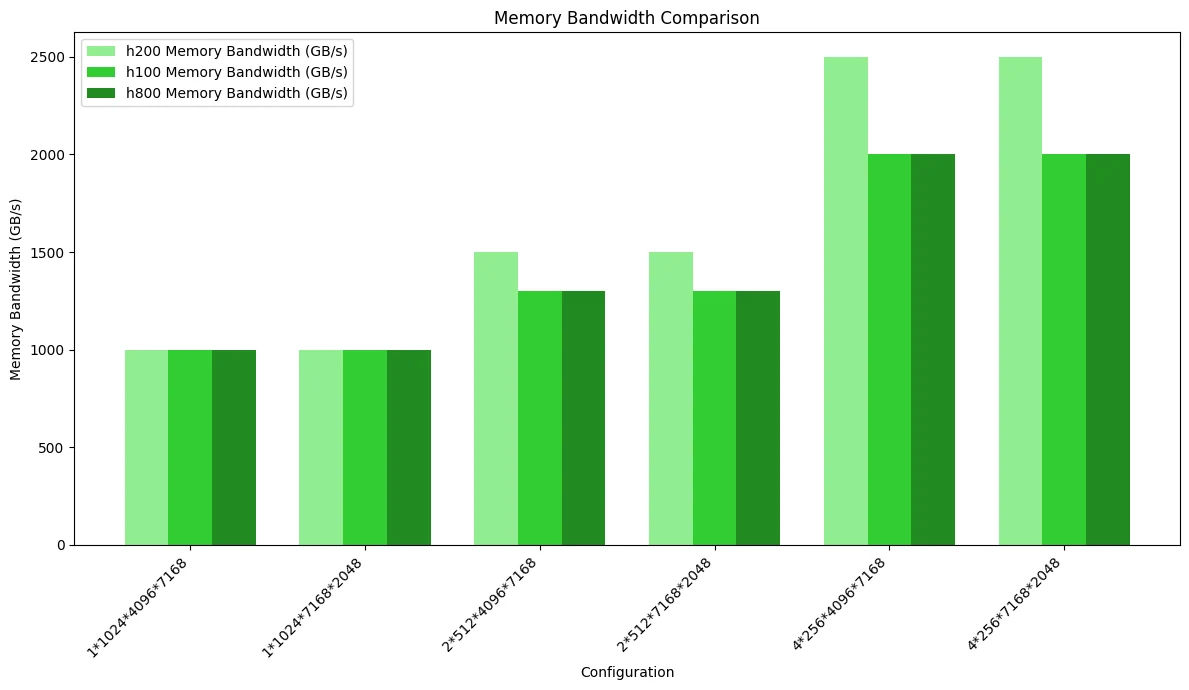
マスクストレージレイアウトを使用するMoEネットワークでは、H200が最高のパフォーマンスを示し、H100とH800の差は非常に小さいです。
下図はメモリ帯域幅使用率の比較テストを示しています。マスクストレージレイアウトは連続ストレージレイアウトよりも多くのメモリ帯域幅を消費するため、一部のシナリオでメモリアクセスのボトルネックに達し、3つのGPU間でパフォーマンスの差が生じています:
下図は計算パフォーマンスの比較テストであり、帯域幅による差を示しています:
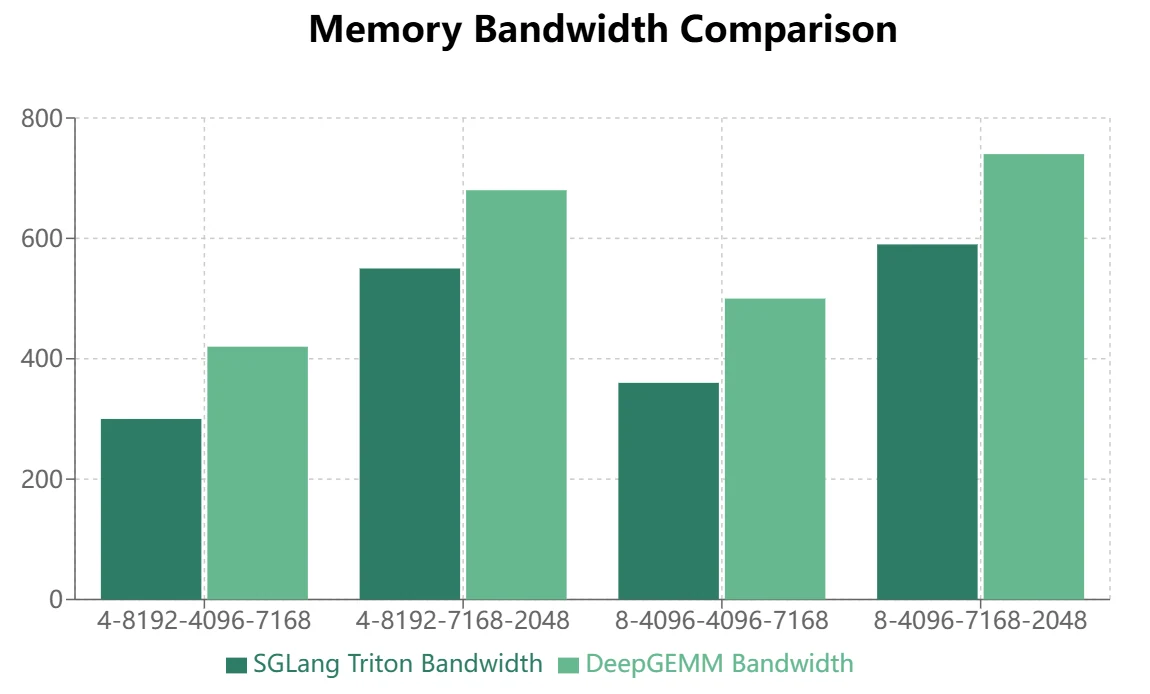
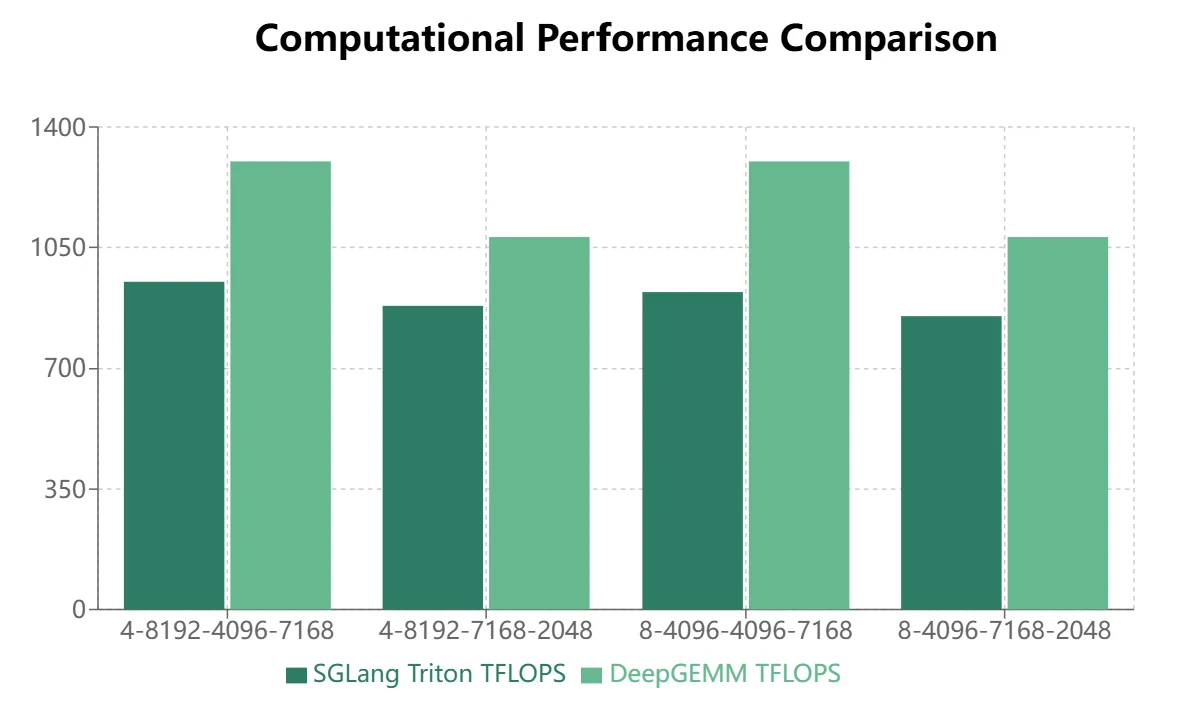
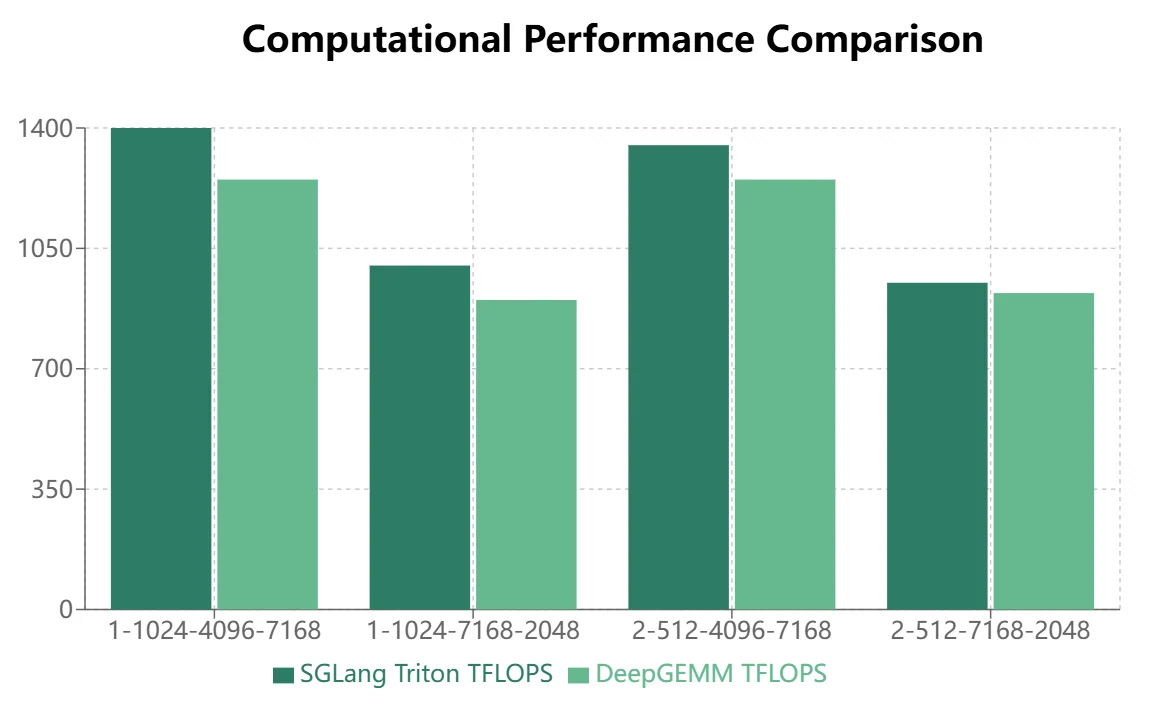
DeepGEMM vs. SGLang Triton Performance Comparison
現在、主流の推論フレームワークは、MoEモジュールにSGLang Tritonベースで開発されたグループ化GEMM演算子を使用しています。当社はH200ハードウェア条件下でDeepGEMMとSGLang Tritonのパフォーマンス比較テストを実施しました:
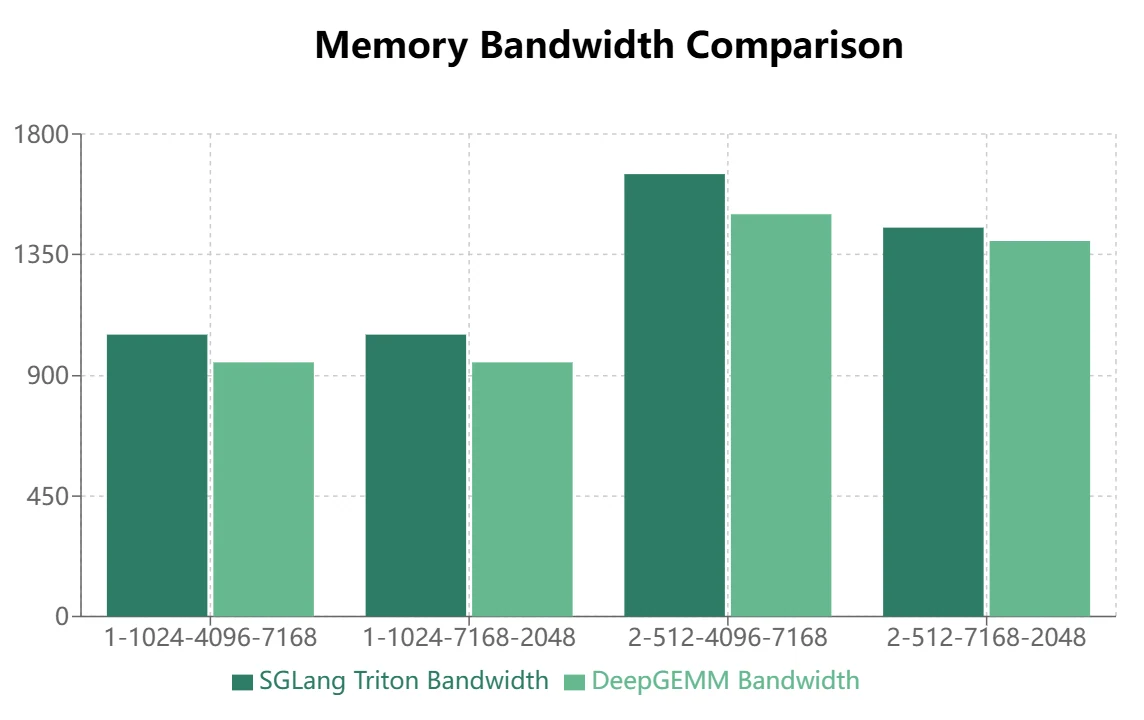
DeepGEMMは連続ストレージレイアウトにおいて一定の利点を示しますが、SGLang Tritonはマスクストレージレイアウトで優れたパフォーマンスを発揮します。現在、SGLang Tritonの一部の演算子は主にマスクストレージシナリオに適用されています。したがって、DeepGEMMが推論フレームワークでSGLang Tritonを置き換えるには、さらなる最適化が必要です。
- 連続ストレージレイアウトを使用するMoEモデル(トレーニングフォワードパス、推論プリフィル)では、DeepGEMMの方がより顕著な利点を示します。
- マスクストレージレイアウトを使用するMoEモデル(推論デコーディング)では、Tritonの方が優れたパフォーマンスを発揮します:
Conclusion
評価結果は、DeepGEMMがH100、H200、H800を含む複数のGPUで顕著なパフォーマンス最適化能力を示し、その強力な汎用性を強調しています。
Hopperアーキテクチャで実行されるMoEシリーズモデル(DeepSeek V3やR1など)の場合、元のCUTLASSバージョンのグループ化GEMMを置き換えてDeepGEMMを推論フレームワークに統合することにより、モデル推論で約1.2倍の高速化が期待され、全体的なパフォーマンスが向上します。
現在のところ、DeepGEMMはSGLang Tritonを完全に置き換えることはできず、その適用範囲を拡大するためにさらなる最適化が必要です。推論デコーディングではSGLang Tritonの方が効率的ですが、DeepGEMMはトレーニングフォワードパスと推論プリフィル段階でより大きな利点を示しています。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、同時に手頃で信頼性の高いGPUクラウドを提供して、構築とスケーリングを支援します。