

為了支援開發者社群,Qwen2.5-7B 目前在 Novita AI 上免費提供。
Qwen 2.5 VL 72B vs Qwen 2.5 72B:VRAM 需求
從 Hugging Face 可以發現,Qwen 2.5VL 72B 至少需要 384 GB VRAM,而 Qwen 2.5 72B 只需要 146.77 GB!
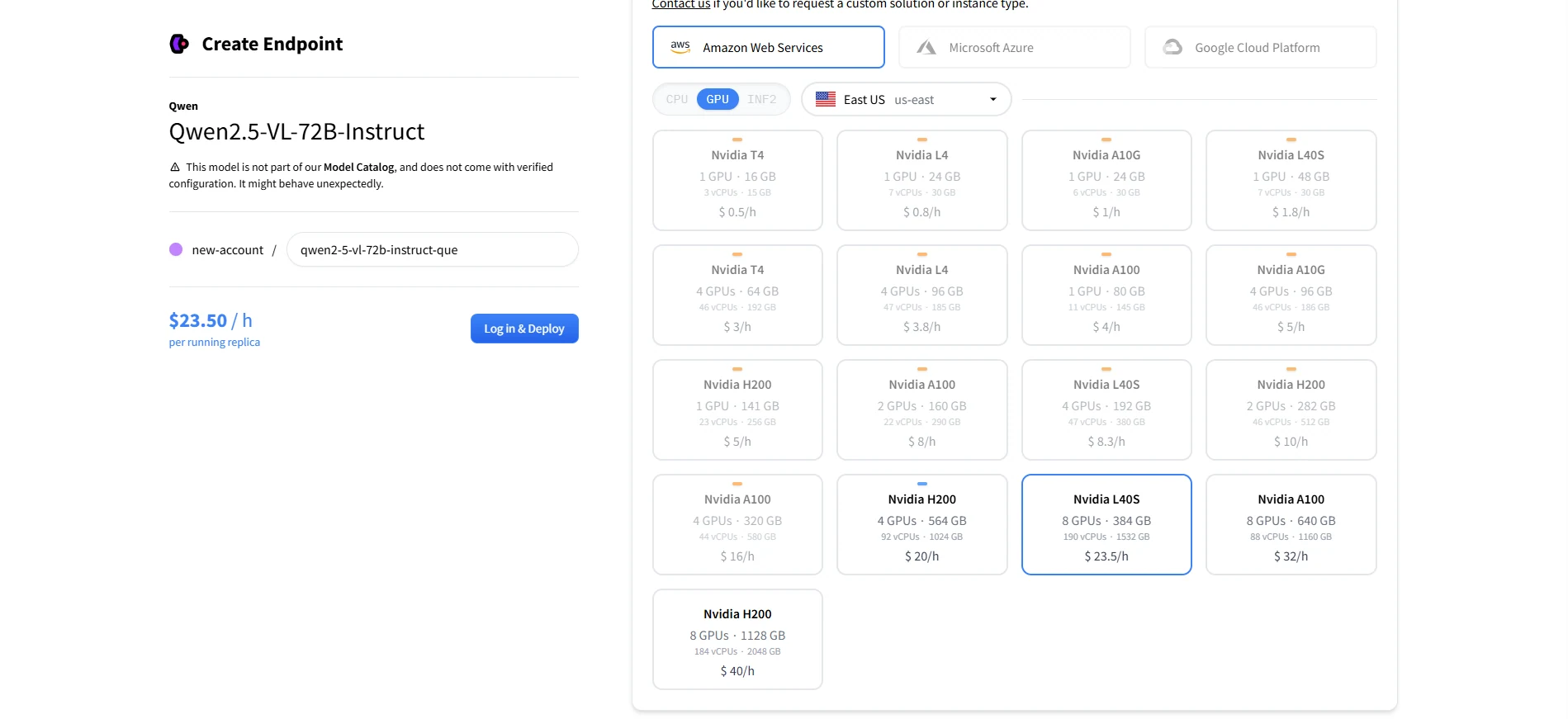
部署 Qwen 2.5 VL 72B 的推薦 GPU
| 配置 | 總 VRAM | 備註 |
|---|---|---|
| 8× A100 80GB | 640 GB | 大型模型推論的標準配置 |
| 8× H100 80GB | 640 GB | 效能優於 A100 |
| 8× L40S 48GB | 384 GB | NVIDIA 較新的企業級 GPU。成本效益高,但可能需要優化管線或 8-bit 量化才能完整容納模型。 |
8× L40S = 384 GB 總 VRAM,正好處於 Qwen2.5-VL-72B ** 文件標示的最小需求**邊緣。
您可能需要模型並行與 vLLM、DeepSpeed 或 Hugging Face
accelerate最佳化才能確保穩定性。如果 FP16 無法裝入記憶體,請考慮 8-bit 或 4-bit 量化。
部署 Qwen 2.5 VL 72B 的成本
1. 更高的部署成本
- 您需要 更多 GPU(例如 8×A100 80GB 或多個 H100),或高階 GPU 節點。
- 雲端部署成本遠高於純文字版本。
2. 更高的硬體門檻
- 許多開發者 無法在本機運行 VL-72B。它需要多 GPU 設置與高效的模型並行。
- 同時需要高記憶體頻寬與最佳化基礎設施,以穩定進行推論。
3. 更昂貴的推論費用
- API 供應商會因為更高的資源消耗而收取更多費用。
- 推論成本可能是 同參數規模純文字模型的 2–3 倍(或更多)。
4. 更慢的推論速度
- 視覺編碼器與多模態融合層增加了複雜度。
- 處理影像會增加 token 吞吐量的負擔,進而提高延遲。
為什麼 Qwen 2.5 VL 72B 需要比同規模 LLM 更多的 VRAM
Qwen2.5-VL-72B 是阿里雲開發的最新多模態大型語言模型,能夠理解並生成來自視覺(圖片與影片)及文字輸入的內容。
擁有 720 億個參數,它在文件解析、圖表分析、視覺問答以及長影片理解等任務上表現出色,適合用於 AI 代理與企業自動化等複雜應用。
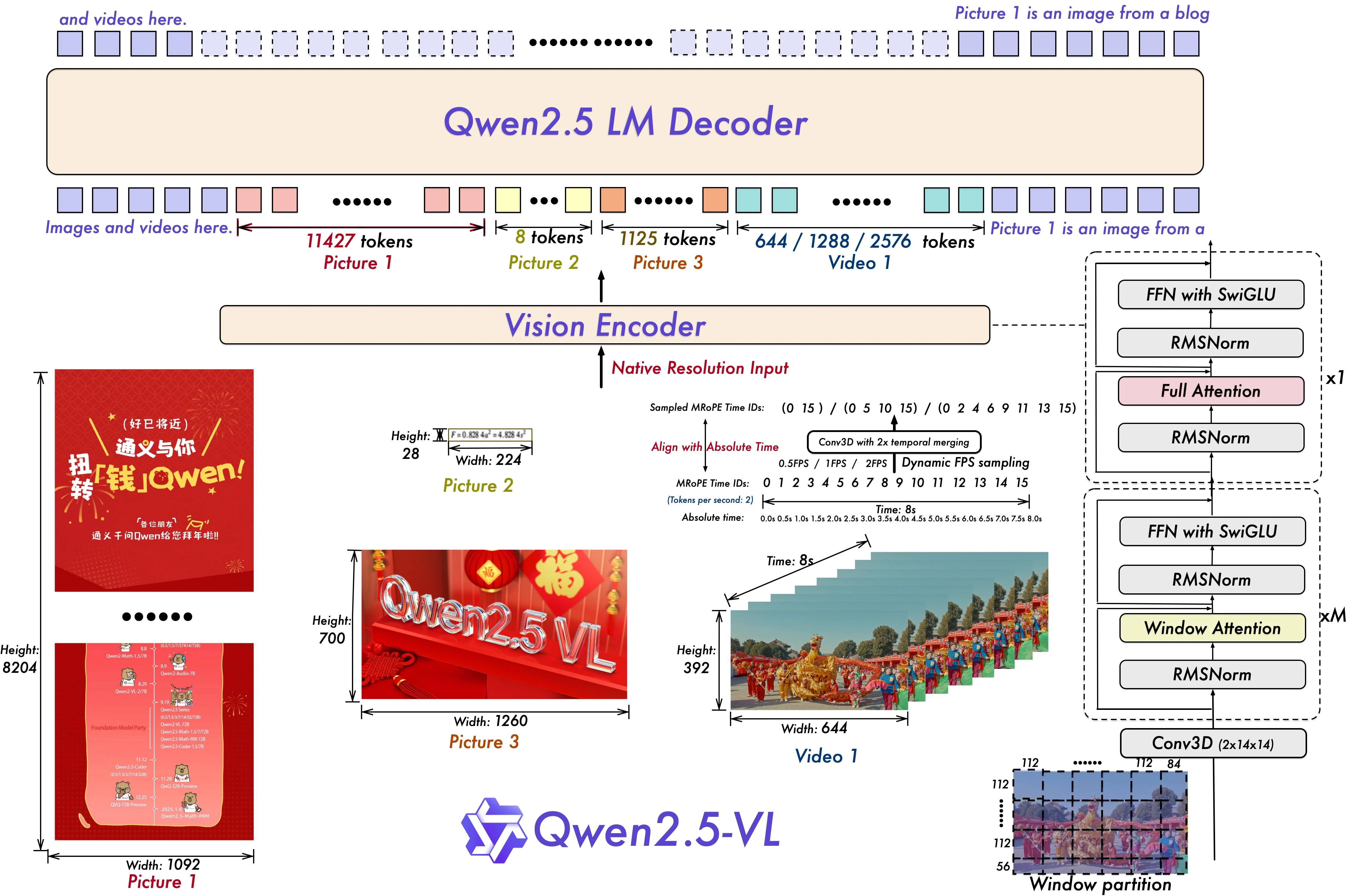
1. 動態解析度與幀率取樣
作用說明:
Qwen2.5-VL-72B 引入了動態解析度與 時間幀取樣 ,使模型能處理不同幀率的影片。這意味著模型可以適應不同的移動速度、辨識關鍵事件,並對時間進行推理——例如場景中「某件事何時發生」。為支援此功能,模型更新了其 多模態旋轉位置嵌入 (mRoPE),加入絕對時間與幀 ID 資訊。
對 VRAM 的影響:
雖然動態取樣聽起來有效率,但支援可變解析度與幀率意味著模型必須保留容量以應對多種時間模式。這會增加記憶體需求,尤其在處理高解析度或長時間影片時。此外,將 mRoPE 擴展到時間維度意味著更多 token、更多嵌入與更多注意力層——所有這些都會推高 VRAM 用量。
2. 精簡的視覺 Transformer (ViT)
作用說明:
模型的視覺編碼器基於 帶有窗口注意力的 Vision Transformer,以局部區塊而非一次全部處理影像。這有助於減少計算量。Qwen2.5-VL 還使用了 SwiGLU 與 RMSNorm——這些現代技術能改善收斂速度與數值穩定性,同時保持與主要 Qwen2.5 語言模型的相容性。
對 VRAM 的影響:
與完整注意力相比,窗口注意力確實有助於節省記憶體,尤其是對於高解析度影像。然而,視覺編碼器本身——特別是在 72B 模型中——仍然會產生顯著的額外負擔。SwiGLU 與 RMSNorm 本身並非 VRAM 大戶,但它們增加了額外的層與運算。結果是,視覺堆疊雖然比某些模型更有效率,但要流暢運行仍需 數十 GB 的額外 VRAM,尤其當搭配大批量或長上下文時。
Qwen2.5-VL-72B 針對效能進行了最佳化,但其架構本質上是 多模態且記憶體密集 的。它不僅要理解文字,還要理解複雜的視覺與時間模式。
這些能力伴隨著顯著的 VRAM 權衡,使其比標準的 72B 純文字模型耗費更多資源——即使架構效率已是首要考量。
Qwen2.5 VL 72B 的本機部署並不容易
在本機部署 Qwen2.5-VL-72B 可能會因其龐大的記憶體需求(高達 384 GB VRAM)而令人卻步。雖然有多種方法可以減輕負擔,但每種方法都有其複雜性:
- 量化 將模型壓縮至 8-bit 甚至 4-bit 精度,可將記憶體使用量減少 75%。但需要 GPTQ 或 AWQ 等工具,且可能影響準確性或相容性。
- 模型並行 將模型拆分到多個 GPU 上,即使單個 GPU 記憶體不足也能運作。但這需要高速互連(如 NVLink)與仔細設定——對初學者並不友善。
- 高效推論引擎 如 vLLM 可最佳化記憶體重用與吞吐量,但仍需要穩固的基礎設施與一些工程工作才能整合到生產環境。
- 雲端部署 消除了硬體門檻,但您需要管理擴展、正常運行時間與成本——而且通常仍需要自訂容器設定。
簡而言之:所有這些解決方案都有效,但它們需要花費時間、金錢,或兩者兼具。這就是為什麼對於許多想要快速使用 Qwen2.5-VL-72B 多模態能力的開發者、研究人員與團隊來說,最佳選擇往往是最簡單的——使用經過良好最佳化的 API 服務。
改用 API
使用 API 可以讓您免去設定硬體、管理記憶體或擔心相容性的麻煩。您可以立即獲得 Qwen2.5-VL-72B 的完整能力——視覺、語言與影片理解——而無需承擔基礎設施負擔。只需發送請求、獲得回應,然後專注於建置。
步驟 1:登入並進入模型庫
登入您的帳戶,然後點擊 Model Library(模型庫) 按鈕。

步驟 2:選擇您的模型
瀏覽可用的選項,選擇適合您需求的模型。

步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
步驟 4:取得您的 API 金鑰
為了對 API 進行驗證,我們會提供您一個新的 API 金鑰。進入「Settings(設定)」頁面,您可以按照圖片所示複製 API 金鑰。

步驟 5:安裝 API
使用您程式語言專用的套件管理器安裝 API。
安裝完成後,將必要的函式庫匯入您的開發環境。使用您的 API 金鑰初始化 API,開始與 Novita AI LLM 互動。以下是 Python 使用者使用聊天補全 API 的範例。
from openai import OpenAI
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen2.5-VL-72B 是一項尖端技術,但其資源需求很高。與其摸索多 GPU 設定或調整量化,大多數使用者會從使用高效能 API 中受益。它更快、更簡單,讓您專注於最重要的事情——建置智慧應用程式。
我可以在單個 GPU 上運行 Qwen2.5-VL-72B 嗎?
不行,除非您進行大量量化(例如 4-bit)並使用非常高階的 GPU 如 H100 120GB——即便如此,效能可能也無法令人滿意。
有輕量版的 Qwen-VL 嗎?
有,Qwen2.5-VL-7B 與 Qwen2.5-VL-3B 以較低的硬體成本提供類似的多模態能力。
我可以使用 API 處理圖片 + 文字提示嗎?
當然可以。Novita AI Qwen 2.5 VL 72B API 支援完整的多模態輸入——包括長影片幀、圖表與基於圖片的問答。
Novita AI 是一個 AI 雲端平台,為開發者提供透過簡單 API 部署 AI 模型的簡易方式,同時也提供價格實惠、可靠的 GPU 雲端,用於建置與擴展。



