

لدعم مجتمع المطورين، يتوفر Qwen2.5-7B حاليًا مجانًا على Novita AI.
Qwen 2.5 VL 72B مقابل Qwen 2.5 72B: متطلبات VRAM
من Hugging Face، نجد أن Qwen 2.5VL 72B يحتاج إلى 384 VRAM على الأقل، بينما Qwen 2.5 72B يحتاج فقط إلى 146.77 جيجابايت!
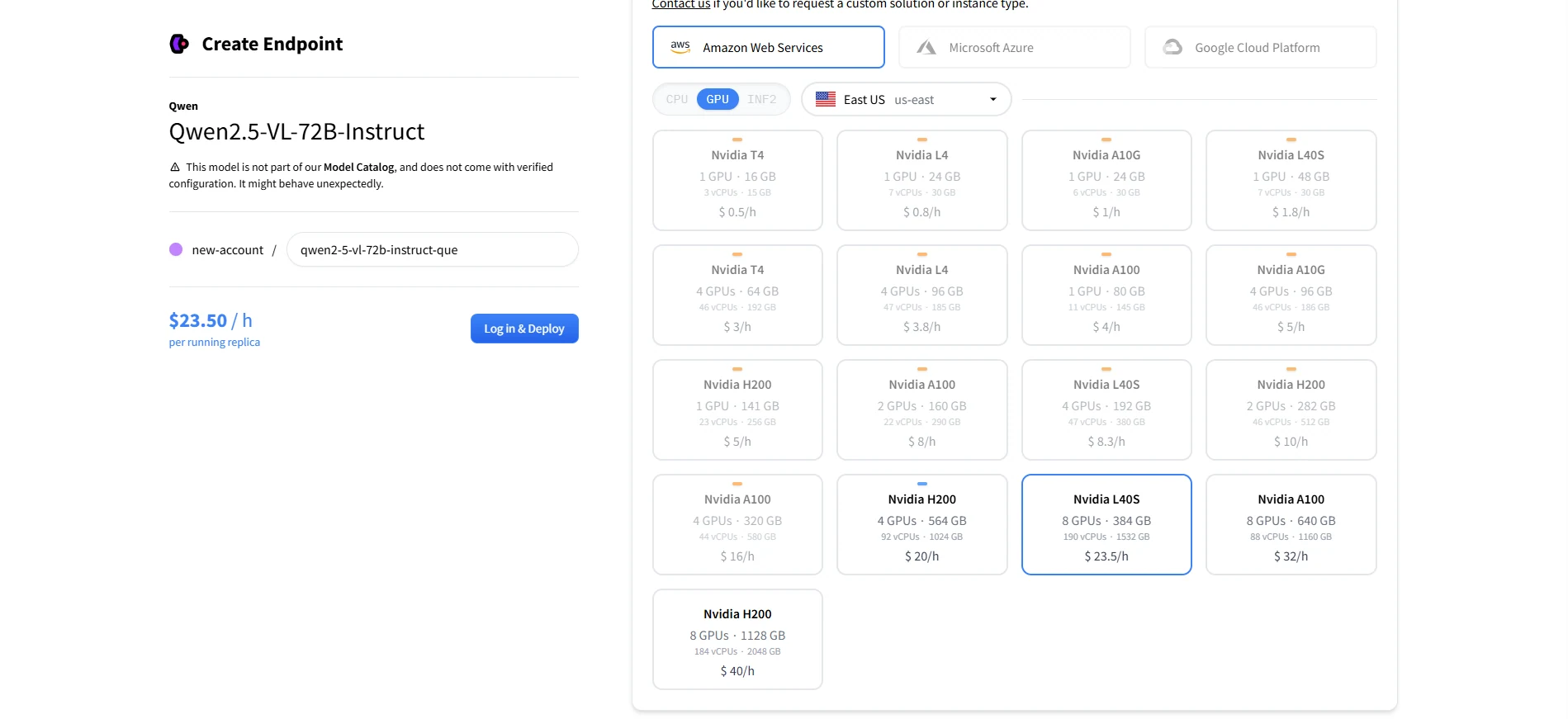
بطاقات GPU الموصى بها لنشر Qwen 2.5 VL 72B
| التكوين | إجمالي VRAM | ملاحظات |
|---|---|---|
| 8× A100 80GB | 640 جيجابايت | إعداد قياسي لاستدلال النماذج الكبيرة |
| 8× H100 80GB | 640 جيجابايت | أداء أفضل من A100s. |
| 8× L40S 48GB | 384 جيجابايت | بطاقة GPU مؤسسية أحدث من NVIDIA. فعالة من حيث التكلفة، ولكن قد تحتاج إلى خط أنابيب محسّن أو تكميم 8 بت لتناسب النموذج بالكامل. |
8× L40S = 384 جيجابايت إجمالي VRAM، وهو على حافة الحد الأدنى الموثق لـ Qwen2.5-VL-72B.
قد تحتاج إلى توازي النماذج وتحسينات من vLLM أو DeepSpeed أو Hugging Face
accelerateلضمان الاستقرار.فكر في تكميم 8 بت أو 4 بت إذا لم تكن FP16 مناسبة للذاكرة.
تكلفة نشر Qwen 2.5 VL 72B
1. تكلفة نشر أعلى بكثير
- ستحتاج إلى المزيد من بطاقات GPU (مثل 8×A100 80GB أو عدة H100s)، أو عقد GPU عالية الأداء.
- يصبح النشر السحابي أكثر تكلفة بكثير مقارنة بالإصدار النصي فقط.
2. حاجز أجهزة أعلى
- العديد من المطورين ببساطة لا يستطيعون تشغيل VL-72B محليًا. يتطلب إعدادات متعددة GPU وتوازي نماذج فعال.
- يتطلب أيضًا عرض نطاق ترددي عالي للذاكرة وبنية تحتية محسّنة لاستدلال مستقر.
3. استدلال أكثر تكلفة
- سيتقاضى مزودو API رسومًا أعلى بسبب استهلاك الموارد المتزايد.
- يمكن أن تكون تكلفة الاستدلال 2–3× أعلى (أو أكثر) من نموذج نصي صاف بنفس حجم المعلمات.
4. سرعة استدلال أبطأ
- تضيف مشفرات الرؤية وطبقات الدمج متعددة الوسائط تعقيدًا.
- معالجة الصور تضيف عبئًا إضافيًا على إنتاجية الرموز، مما يزيد من زمن الوصول.
لماذا يتطلب Qwen 2.5 VL 72B ذاكرة VRAM أكبر من LLM بنفس الحجم
Qwen2.5-VL-72B هو نموذج لغة كبير متعدد الوسائط من أحدث الإصدارات طورته Alibaba Cloud، مصمم لفهم وتوليد المحتوى من المدخلات البصرية (الصور والفيديو) والنصية.
بفضل 72 مليار معلمة، يتفوق في مهام مثل تحليل المستندات، تحليل الرسوم البيانية، الإجابة على الأسئلة البصرية، وفهم الفيديو الطويل، مما يجعله مناسبًا للتطبيقات المعقدة مثل وكلاء AI وأتمتة المؤسسات.
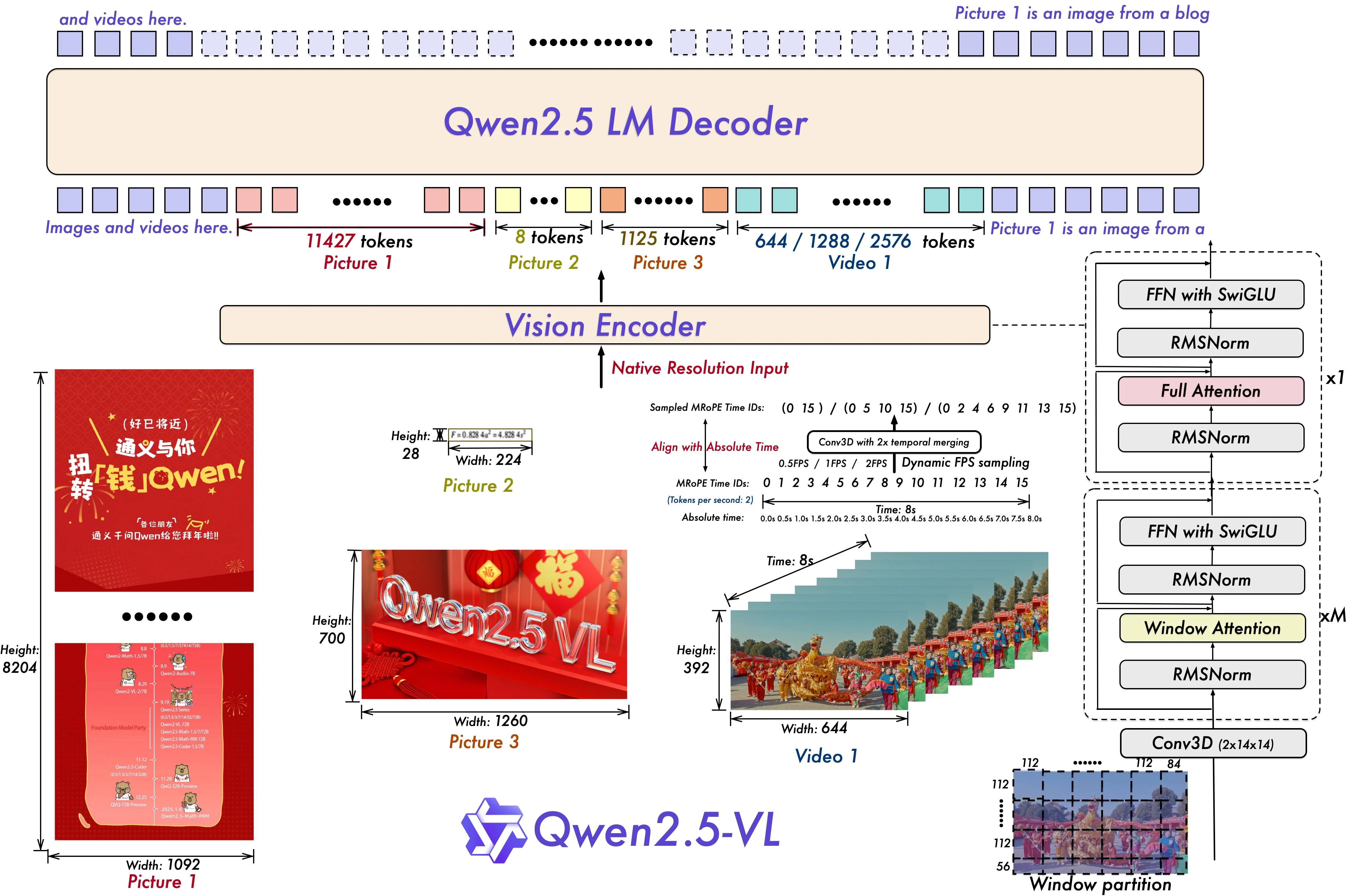
1. الدقة الديناميكية وأخذ عينات معدل الإطارات
ما يفعله:
يقدم Qwen2.5-VL-72B دقة ديناميكية وأخذ عينات إطارات زمنية، مما يسمح له بمعالجة مقاطع الفيديو بمعدلات إطارات مختلفة. هذا يعني أن النموذج يمكنه التكيف مع سرعات الحركة المختلفة، وتحديد الأحداث الرئيسية، والتفكير في الوقت — مثل “متى حدث شيء ما” في مشهد. لدعم ذلك، يحدّث النموذج تضمينات الدوران متعددة الوسائط (mRoPE) بمعلومات الوقت المطلق ومعرف الإطار.
كيف يؤثر على VRAM:
على الرغم من أن أخذ العينات الديناميكي يبدو فعالاً، إلا أن دعم الدقة المتغيرة ومعدلات الإطارات يعني أن النموذج يجب أن يحتفظ بسعة لأنماط زمنية متعددة. هذا يزيد من احتياجات الذاكرة، خاصة عند التعامل مع فيديو عالي الدقة أو طويل المدة. بالإضافة إلى ذلك، تمديد mRoPE إلى بُعد الوقت يعني المزيد من الرموز، والمزيد من التضمينات، والمزيد من طبقات الانتباه — وكلها تدفع استخدام VRAM إلى الأعلى.
2. محول الرؤية المبسط (ViT)
ما يفعله:
مشفر الرؤية في النموذج مبني على محول رؤية مع انتباه نافذة، والذي يعالج الصور في بقع محلية بدلاً من دفعة واحدة. هذا يساعد في تقليل الحساب. يستخدم Qwen2.5-VL أيضًا SwiGLU و RMSNorm — تقنيات حديثة تعمل على تحسين سرعة التقارب والاستقرار العددي، مع الحفاظ على التوافق مع نموذج اللغة الرئيسي Qwen2.5.
كيف يؤثر على VRAM:
يساعد انتباه النافذة في توفير الذاكرة مقارنة بالانتباه الكامل، خاصة للصور عالية الدقة. ومع ذلك، فإن مشفر الرؤية نفسه — خاصة في نموذج 72B — لا يزال يضيف عبئًا كبيرًا. SwiGLU و RMSNorm ليسا مستهلكين رئيسيين لـ VRAM بمفردهم، لكنهما يضيفان طبقات وعمليات إضافية. النتيجة هي كومة بصرية أكثر كفاءة من بعض النماذج ولكنها لا تزال تتطلب عشرات الجيجابايتات الإضافية من VRAM لتعمل بسلاسة، خاصة عند دمجها مع أحجام دفعات كبيرة أو سياق طويل.
Qwen2.5-VL-72B محسّن للأداء، ولكن هيكله متعدد الوسائط ويستهلك ذاكرة بشكل كبير. إنه مبني لفهم ليس فقط الكلمات ولكن أيضًا الأنماط البصرية والزمنية المعقدة.
تأتي هذه القدرات مع مقايضات كبيرة في VRAM، مما يجعله أكثر تطلبًا بكثير من نموذج 72B نصي صاف — حتى عندما تكون الكفاءة الهيكلية أولوية قصوى.
النشر المحلي ليس سهلاً لـ Qwen2.5 VL 72B
قد يكون نشر Qwen2.5-VL-72B محليًا مرهقًا بسبب احتياجاته الهائلة للذاكرة — حتى 384 جيجابايت من VRAM. بينما توجد عدة طرق لتخفيف العبء، كل منها يأتي مع تعقيده الخاص:
- التكميم يضغط النموذج إلى دقة 8 بت أو حتى 4 بت، مما يقلل استخدام الذاكرة بنسبة تصل إلى 75٪. ومع ذلك، يتطلب أدوات مثل GPTQ أو AWQ، وقد يؤثر على الدقة أو التوافق.
- توازي النماذج يقسم النموذج عبر بطاقات GPU متعددة، مما يسمح بتشغيله حتى إذا لم يكن لدى أي GPU واحدة ذاكرة كافية. لكن هذا يتطلب توصيلات عالية السرعة (مثل NVLink) وإعدادًا دقيقًا — وليس مناسبًا للمبتدئين.
- محركات الاستدلال الفعالة مثل vLLM يمكنها تحسين إعادة استخدام الذاكرة والإنتاجية، ولكنها لا تزال تتطلب بنية تحتية صلبة وبعض العمل الهندسي للتكامل في الإنتاج.
- النشر السحابي يزيل عقبة الأجهزة، لكنك ستحتاج إلى إدارة التوسع ووقت التشغيل والتكلفة — وغالبًا ما يتطلب إعداد حاوية مخصصة.
باختصار: جميع هذه الحلول تعمل، لكنها تكلف وقتًا أو مالًا أو كليهما. لهذا السبب، بالنسبة للعديد من المطورين والباحثين والفرق التي تبحث عن وصول سريع إلى قدرات Qwen2.5-VL-72B متعددة الوسائط، غالبًا ما يكون الخيار الأفضل هو الأبسط — استخدام خدمة API محسّنة جيدًا.
استخدم API بدلاً من ذلك
يتيح لك استخدام API تخطي عناء إعداد الأجهزة وإدارة الذاكرة أو القلق بشأن التوافق. تحصل على وصول فوري إلى كامل قدرات Qwen2.5-VL-72B — الرؤية واللغة وفهم الفيديو — بدون عبء البنية التحتية. فقط أرسل طلبًا، واحصل على رد، وركز على البناء.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ النسخة التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف قدرات النموذج المحدد.
جرب Qwen 2.5 VL 72B Demo الآن!
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنقدم لك مفتاح API جديد. ادخل إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام API chat completions لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen2.5-VL-72B هو أحدث ما توصلت إليه التكنولوجيا، لكن متطلباته من الموارد عالية. بدلاً من التعامل مع إعدادات متعددة GPU أو ضبط التكميم، سيستفيد معظم المستخدمين من استخدام API عالي الأداء. إنه أسرع وأبسط ويتيح لك التركيز على ما يهم — بناء تطبيقات ذكية.
هل يمكنني تشغيل Qwen2.5-VL-72B على GPU واحد؟
لا، إلا إذا قمت بتكميم كثيف (مثل 4 بت) واستخدام GPU فائق مثل H100 120GB — حتى في هذه الحالة، قد يتأثر الأداء.
هل هناك نسخة خفيفة من Qwen-VL؟
نعم، يقدم Qwen2.5-VL-7B و Qwen2.5-VL-3B قدرات متعددة الوسائط مماثلة بتكلفة أجهزة أقل.
هل يمكنني استخدام API لاستفسارات الصورة + النص؟
بالتأكيد. تدعم Novita AI API Qwen 2.5 VL 72B الإدخال متعدد الوسائط الكامل — بما في ذلك إطارات الفيديو الطويلة والرسوم البيانية والأسئلة والأجوبة القائمة على الصور.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج AI باستخدام API البسيط لدينا، مع توفير GPU سحابي ميسور التكلفة وموثوق للبناء والتوسع.



