

Para apoiar a comunidade de desenvolvedores, o Qwen2.5-7B está atualmente disponível gratuitamente na Novita AI.
Qwen 2.5 VL 72B vs Qwen 2.5 72B: Requisitos de VRAM
No Hugging Face, podemos ver que o Qwen 2.5VL 72B precisa de pelo menos 384 GB de VRAM, enquanto o Qwen 2.5 72B precisa apenas de 146,77 GB!
Experimente a Demonstração do Qwen 2.5 7B Agora!
GPUs Recomendadas para Implantação do Qwen 2.5 VL 72B
| Configuração | VRAM Total | Observações |
|---|---|---|
| 8× A100 80GB | 640 GB | Configuração padrão para inferência de modelos grandes |
| 8× H100 80GB | 640 GB | Melhor desempenho que A100s. |
| 8× L40S 48GB | 384 GB | GPU empresarial mais nova da NVIDIA. Econômica, mas pode precisar de pipeline otimizado ou quantização de 8 bits para caber totalmente no modelo. |
8× L40S = 384 GB de VRAM total, que está exatamente no limite do mínimo documentado do Qwen2.5-VL-72B.
Você pode precisar de paralelismo de modelo e otimizações como vLLM, DeepSpeed ou Hugging Face
acceleratepara garantir estabilidade.Considere quantização de 8 bits ou 4 bits se o FP16 não couber na memória.
O Custo de Implantar o Qwen 2.5 VL 72B
1. Custo de Implantação Muito Maior
- Você precisará de mais GPUs (por exemplo, 8×A100 80GB ou vários H100s), ou nós de GPU de alto desempenho.
- A implantação em nuvem se torna significativamente mais cara em comparação com a versão apenas de texto.
2. Barreira de Hardware Mais Alta
- Muitos desenvolvedores simplesmente não conseguem executar o VL-72B localmente. Ele requer configurações multi-GPU e paralelismo de modelo eficiente.
- Também exige alta largura de banda de memória e infraestrutura otimizada para inferência estável.
3. Inferência Mais Cara
- Os provedores de API cobrarão mais devido ao aumento do consumo de recursos.
- O custo de inferência pode ser 2 a 3 vezes maior (ou mais) do que um modelo de texto puro do mesmo tamanho de parâmetros.
4. Velocidade de Inferência Mais Lenta
- Codificadores visuais e camadas de fusão multimodal adicionam complexidade.
- O processamento de imagens adiciona sobrecarga à taxa de transferência de tokens, aumentando a latência.
Por que o Qwen 2.5 VL 72B Exige Mais VRAM do que um LLM do Mesmo Tamanho
Qwen2.5-VL-72B é um modelo de linguagem multimodal de última geração desenvolvido pela Alibaba Cloud, projetado para entender e gerar conteúdo a partir de entradas visuais (imagens e vídeos) e textuais.
Com 72 bilhões de parâmetros, ele se destaca em tarefas como análise de documentos, análise de gráficos, resposta a perguntas visuais e compreensão de vídeos longos, tornando-o adequado para aplicações complexas como agentes de IA e automação empresarial.
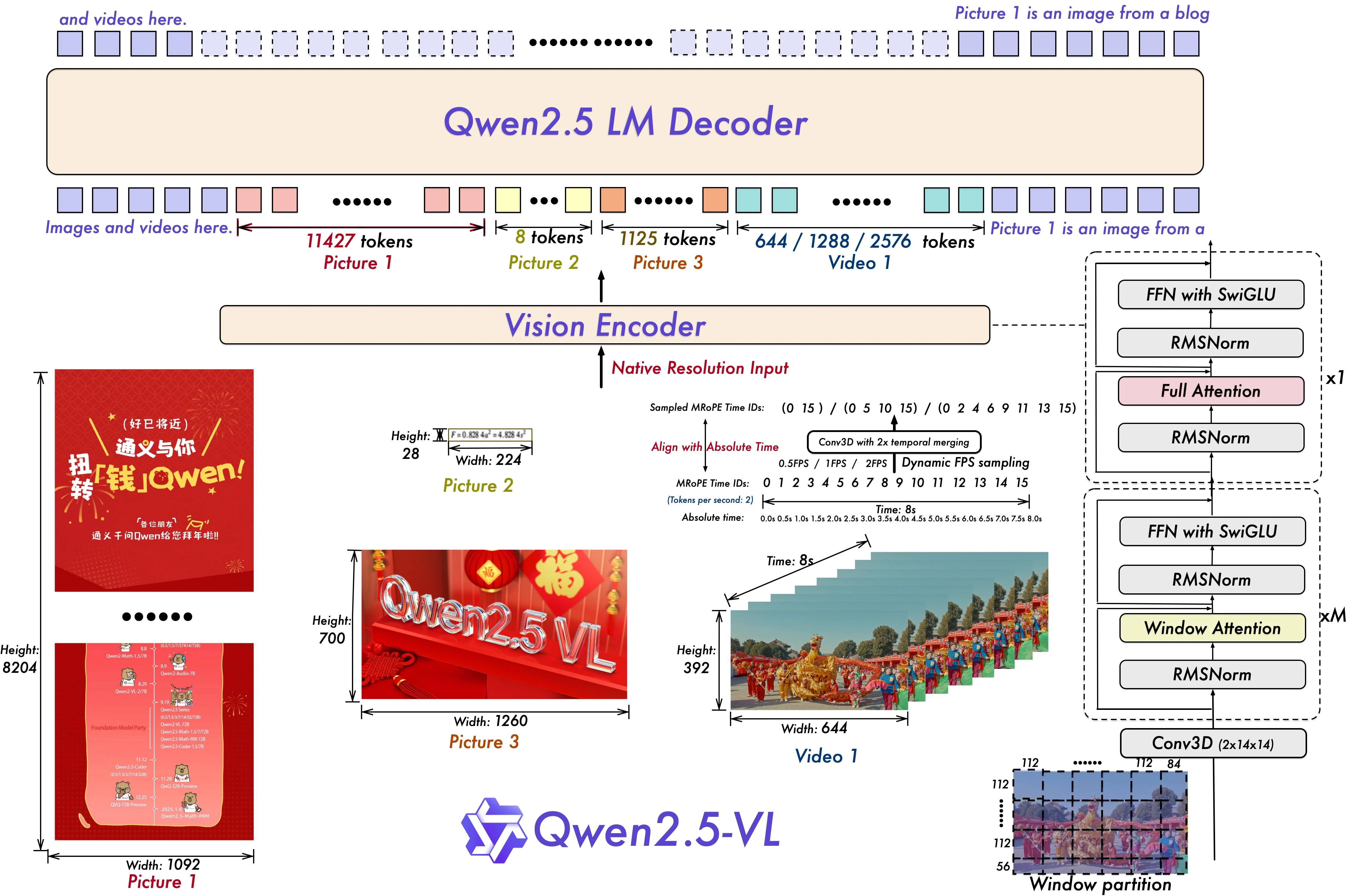
1. Resolução Dinâmica e Amostragem de Quadros
O que faz:
O Qwen2.5-VL-72B introduz resolução dinâmica e amostragem temporal de quadros, permitindo processar vídeos em várias taxas de quadros. Isso significa que o modelo pode se adaptar a diferentes velocidades de movimento, identificar eventos-chave e raciocinar sobre o tempo — como “quando algo aconteceu” em uma cena. Para suportar isso, o modelo atualiza suas incorporações de posição rotativa multimodal (mRoPE) com informações absolutas de tempo e ID de quadro.
Como afeta a VRAM:
Embora a amostragem dinâmica pareça eficiente, suportar resoluções e taxas de quadros variáveis significa que o modelo deve reservar capacidade para múltiplos padrões temporais. Isso aumenta as necessidades de memória, especialmente ao lidar com vídeos de alta resolução ou longa duração. Além disso, estender o mRoPE para a dimensão temporal significa mais tokens, mais embeddings e mais camadas de atenção — tudo isso aumenta o uso de VRAM.
2. Vision Transformer Simplificado (ViT)
O que faz:
O codificador visual do modelo é baseado em um Vision Transformer com atenção em janela, que processa imagens em patches localizados em vez de todos de uma vez. Isso ajuda a reduzir a computação. O Qwen2.5-VL também usa SwiGLU e RMSNorm — técnicas modernas que melhoram a velocidade de convergência e a estabilidade numérica, mantendo a compatibilidade com o modelo de linguagem principal Qwen2.5.
Como afeta a VRAM:
A atenção em janela ajuda a economizar memória em comparação com a atenção total, especialmente para imagens de alta resolução. No entanto, o próprio codificador visual — especialmente em um modelo de 72B — ainda adiciona uma sobrecarga significativa. SwiGLU e RMSNorm não são grandes consumidores de VRAM por si só, mas contribuem com camadas e operações adicionais. O resultado é uma pilha visual mais eficiente que alguns modelos, mas que ainda requer dezenas de gigabytes extras de VRAM para funcionar sem problemas, especialmente quando combinada com grandes tamanhos de lote ou contexto longo.
Qwen2.5-VL-72B é otimizado para desempenho, mas sua arquitetura é inerentemente multimodal e intensiva em memória. Foi construído para entender não apenas palavras, mas também padrões visuais e temporais complexos.
Essas capacidades vêm com trade-offs significativos de VRAM, tornando-o muito mais exigente do que um modelo padrão de 72B apenas de texto — mesmo quando a eficiência arquitetural é uma prioridade máxima.
Implantação Local Não é Fácil para o Qwen2.5 VL 72B
Implantar o Qwen2.5-VL-72B localmente pode ser desafiador devido às suas enormes necessidades de memória — até 384 GB de VRAM. Embora existam várias maneiras de reduzir a carga, cada uma tem sua própria complexidade:
- Quantização comprime o modelo para precisão de 8 bits ou até 4 bits, reduzindo o uso de memória em até 75%. No entanto, requer ferramentas como GPTQ ou AWQ, e pode afetar a precisão ou compatibilidade.
- Paralelismo de modelo divide o modelo em várias GPUs, permitindo que seja executado mesmo que nenhuma GPU individual tenha memória suficiente. Mas isso requer interconexões de alta velocidade (como NVLink) e configuração cuidadosa — não é para iniciantes.
- Mecanismos de inferência eficientes como o vLLM podem otimizar o reuso de memória e a taxa de transferência, mas ainda exigem infraestrutura sólida e algum trabalho de engenharia para integrar em produção.
- Implantação baseada em nuvem remove o obstáculo do hardware, mas você precisará gerenciar escalonamento, disponibilidade e custo — e muitas vezes ainda requer configuração personalizada de contêineres.
Em resumo: todas essas soluções funcionam, mas custam tempo, dinheiro ou ambos. É por isso que para muitos desenvolvedores, pesquisadores e equipes que buscam acesso rápido ao poder multimodal do Qwen2.5-VL-72B, a melhor opção é muitas vezes a mais simples — usar um serviço de API bem otimizado.
Use a API
Usar uma API permite que você evite o incômodo de configurar hardware, gerenciar memória ou se preocupar com compatibilidade. Você obtém acesso instantâneo a todas as capacidades do Qwen2.5-VL-72B — visão, linguagem e compreensão de vídeo — sem a carga da infraestrutura. Basta enviar uma solicitação, receber uma resposta e focar em construir.
Etapa 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Etapa 2: Escolha seu modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Etapa 3: Inicie seu teste gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Experimente a Demonstração do Qwen 2.5 VL 72B Agora!
Etapa 4: Obtenha sua chave de API
Para autenticar com a API, forneceremos a você uma nova chave de API. Entre na página “Configurações” e copie a chave de API conforme indicado na imagem.

Etapa 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com a Novita AI LLM. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
O Qwen2.5-VL-72B é de ponta, mas seus requisitos de recursos são altos. Em vez de lidar com configurações multi-GPU ou ajustar a quantização, a maioria dos usuários se beneficiará ao usar uma API de alto desempenho. É mais rápido, mais simples e permite que você se concentre no que importa — construir aplicações inteligentes.
Posso executar o Qwen2.5-VL-72B em uma única GPU?
Não, a menos que você quantize fortemente (por exemplo, 4 bits) e use uma GPU de altíssimo desempenho como a H100 120GB — mesmo assim, o desempenho pode ser prejudicado.
Existe uma versão leve do Qwen-VL?
Sim, Qwen2.5-VL-7B e Qwen2.5-VL-3B oferecem capacidades multimodais semelhantes a um custo de hardware menor.
Posso usar a API para prompts de imagem + texto?
Com certeza. A API da Novita AI Qwen 2.5 VL 72B suporta entrada multimodal completa — incluindo quadros de vídeo longos, diagramas e perguntas e respostas baseadas em imagens.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



