

開発者コミュニティを支援するため、Qwen2.5-7Bは現在Novita AIで無料で利用可能です。
Qwen 2.5 VL 72B と Qwen 2.5 72B のVRAM要件比較
Hugging Faceによると、Qwen 2.5 VL 72Bは最低384 GBのVRAMを必要とするのに対し、Qwen 2.5 72Bはわずか146.77 GBで済みます。
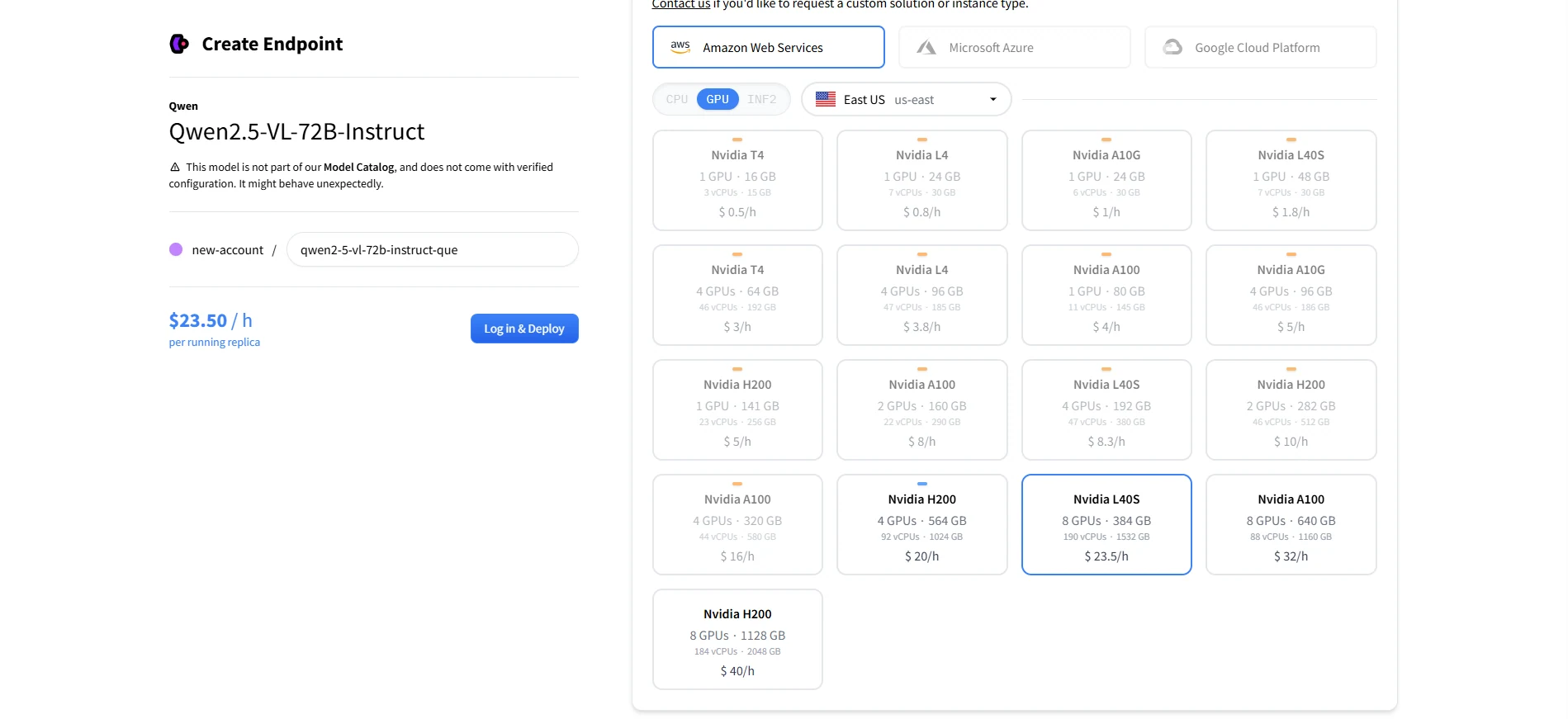
Qwen 2.5 VL 72B のデプロイに推奨されるGPU
| 構成 | 合計VRAM | 備考 |
|---|---|---|
| 8× A100 80GB | 640 GB | 大規模モデル推論の標準セットアップ |
| 8× H100 80GB | 640 GB | A100より優れたパフォーマンス。 |
| 8× L40S 48GB | 384 GB | NVIDIAの新しいエンタープライズGPU。コスト効率が良いが、モデルを完全に収めるには最適化されたパイプラインや8ビット量子化が必要な場合がある。 |
8× L40S = 合計384 GB VRAM。これはQwen2.5-VL-72Bの ** 文書化された最小要件**ぎりぎりです。
安定性を確保するには、モデル並列化と vLLM、DeepSpeed、またはHugging Faceの
accelerateによる最適化が必要になる場合があります。FP16がメモリに収まらない場合は、8ビットまたは4ビット量子化 を検討してください。
Qwen 2.5 VL 72B のデプロイにかかるコスト
1. はるかに高いデプロイコスト
- より多くのGPU(例:8×A100 80GBや複数のH100)やハイエンドGPUノードが必要になります。
- テキストのみのバージョンと比較して、クラウドデプロイのコストが大幅に高くなります。
2. 高いハードウェア障壁
- 多くの開発者は VL-72Bをローカルで実行できません。マルチGPU構成と効率的なモデル並列化が必要です。
- また、安定した推論には高いメモリ帯域幅と最適化されたインフラが求められます。
3. より高価な推論
- リソース消費が増えるため、APIプロバイダーはより高い料金を請求します。
- 推論コストは、同じパラメータサイズのテキスト専用モデルと比べて 2~3倍(またはそれ以上) になる可能性があります。
4. 推論速度の低下
- 視覚エンコーダとマルチモーダル融合レイヤーが複雑さを増します。
- 画像処理によりトークン処理にオーバーヘッドが加わり、レイテンシが増加します。
同じサイズのLLMと比較してQwen 2.5 VL 72Bがより多くのVRAMを必要とする理由
Qwen2.5-VL-72B は、Alibaba Cloudが開発した最先端のマルチモーダル大規模言語モデルであり、視覚(画像や動画)とテキストの両方の入力を理解・生成するよう設計されています。
720億のパラメータを持ち、ドキュメント解析、グラフ分析、視覚的な質問応答、長時間動画の理解などのタスクに優れており、AIエージェントやエンタープライズ自動化のような複雑なアプリケーションに適しています。
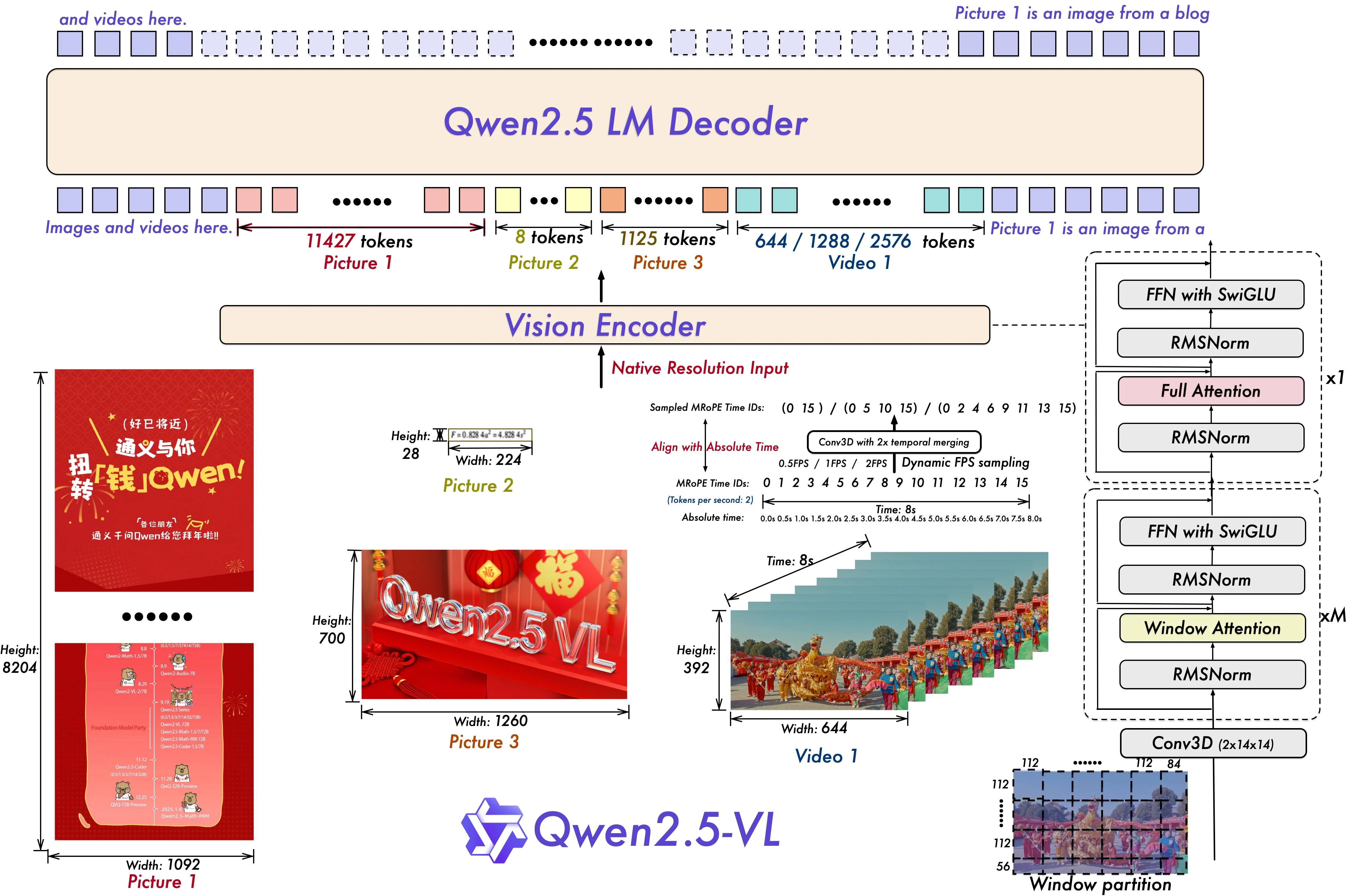
1. 動的解像度とフレームレートサンプリング
動作内容: Qwen2.5-VL-72Bは動的解像度と 時間的フレームサンプリング を導入し、さまざまなフレームレートで動画を処理できます。これにより、モデルは異なる動きの速度に適応し、重要なイベントを特定し、シーン内で「何かがいつ起こったか」のような時間的な推論が可能になります。これをサポートするため、モデルは マルチモーダル回転位置埋め込み(mRoPE) に絶対時刻とフレームID情報を追加します。
VRAMへの影響: 動的サンプリングは効率的に聞こえますが、可変解像度とフレームレートをサポートするには、モデルが複数の時間パターンに対応するための容量を確保する必要があります。これにより、特に高解像度や長時間の動画を扱う場合にメモリ需要が増加します。さらに、mRoPEを時間次元に拡張すると、より多くのトークン、埋め込み、アテンションレイヤーが必要になり、これらすべてがVRAM使用量を押し上げます。
2. 合理化されたVision Transformer(ViT)
動作内容: モデルの視覚エンコーダは ウィンドウアテンションを備えたVision Transformer 上に構築されており、画像を一度にすべて処理するのではなく、局所的なパッチで処理します。これにより計算量が削減されます。Qwen2.5-VLは SwiGLU と RMSNorm も使用しており、これらは収束速度と数値的安定性を向上させる最新の手法で、メインのQwen2.5言語モデルとの互換性を維持しています。
VRAMへの影響: ウィンドウアテンションは、特に高解像度画像において、全体アテンションと比較してメモリを節約するのに役立ちます。しかし、特に72Bモデルにおける視覚エンコーダ自体は、依然として大きなオーバーヘッドを追加します。SwiGLUとRMSNorm自体は大きなVRAMを消費しませんが、追加のレイヤーと演算をもたらします。その結果、視覚スタックは一部のモデルよりも効率的ですが、特に大きなバッチサイズや長いコンテキストと組み合わせると、スムーズに動作するために 数十ギガバイトの追加VRAM を必要とします。
Qwen2.5-VL-72Bはパフォーマンスが最適化されていますが、そのアーキテクチャは本質的に マルチモーダルでメモリ集約型 です。単語だけでなく、複雑な視覚的・時間的パターンも理解できるように作られています。
これらの機能には大きなVRAMのトレードオフが伴い、アーキテクチャの効率性が最優先されている場合でも、標準的な72Bテキスト専用モデルよりもはるかに高い要求が課されます。
Qwen2.5 VL 72Bのローカルデプロイは簡単ではない
Qwen2.5-VL-72Bをローカルにデプロイするには、最大384 GBのVRAMという膨大なメモリ需要が課題となります。負担を軽減する方法はいくつかありますが、それぞれに複雑さが伴います。
- 量子化 はモデルを8ビット、さらには4ビット精度に圧縮し、メモリ使用量を最大75%削減します。ただし、GPTQやAWQのようなツールが必要であり、精度や互換性に影響を与える可能性があります。
- モデル並列化 はモデルを複数のGPUに分割するため、単一のGPUに十分なメモリがなくても実行できます。しかし、NVLinkのような高速インターコネクトと慎重なセットアップが必要で、初心者には優しくありません。
- vLLMのような効率的な推論エンジン はメモリ再利用とスループットを最適化できますが、本番環境に統合するには堅牢なインフラとある程度のエンジニアリング作業が必要です。
- クラウドベースのデプロイ はハードウェアの障壁を取り除きますが、スケーリング、稼働時間、コストの管理が必要であり、多くの場合、カスタムコンテナのセットアップが必要です。
要するに、これらのソリューションはすべて機能しますが、時間、費用、またはその両方がかかります。そのため、Qwen2.5-VL-72Bのマルチモーダル機能に素早くアクセスしたい多くの開発者、研究者、チームにとって、最良の選択肢は多くの場合、最もシンプルな方法、つまり適切に最適化されたAPIサービスを利用することです。
代わりにAPIを使用する
APIを使用すれば、ハードウェアのセットアップ、メモリ管理、互換性の心配が不要になります。Qwen2.5-VL-72Bの視覚、言語、動画理解の全機能に、インフラの負担なしで即座にアクセスできます。リクエストを送信し、応答を受け取り、構築に集中するだけです。
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。

ステップ3:無料トライアルを開始
無料トライアルを開始して、選択したモデルの機能を試してください。
今すぐQwen 2.5 VL 72B デモをお試しください!
ステップ4:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」ページに移動し、画像に示されているようにAPIキーをコピーします。

ステップ5:APIをインストール
使用するプログラミング言語に応じたパッケージマネージャーを使用してAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。これはPythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen2.5-VL-72Bは最先端ですが、リソース要件は高くなっています。マルチGPUセットアップや量子化の調整に苦労する代わりに、ほとんどのユーザーは高性能APIを利用することで利益を得られます。より高速でシンプルであり、スマートアプリケーションの構築に集中できます。
Qwen2.5-VL-72Bを1つのGPUで実行できますか?
いいえ、大幅に量子化(例:4ビット)し、H100 120GBのような非常にハイエンドなGPUを使用しない限り不可能です。たとえ実行できても、パフォーマンスが低下する可能性があります。
Qwen-VLの軽量バージョンはありますか?
はい、Qwen2.5-VL-7BとQwen2.5-VL-3Bは、より低いハードウェアコストで同様のマルチモーダル機能を提供します。
画像+テキストのプロンプトにAPIを使用できますか?
もちろんです。Novita AI Qwen 2.5 VL 72B APIは、長尺動画フレーム、図、画像ベースのQ&Aなど、完全なマルチモーダル入力をサポートしています。
Novita AI は、シンプルなAPIを使用してAIモデルを簡単にデプロイできるクラウドプラットフォームであり、手頃で信頼性の高いGPUクラウドを構築・スケーリングのために提供します。



