

В поддержку сообщества разработчиков Qwen2.5-7B сейчас доступен бесплатно на Novita AI.
Qwen 2.5 VL 72B против Qwen 2.5 72B: требования к VRAM
Из Hugging Face можно узнать, что Qwen 2.5VL 72B требует минимум 384 ГБ VRAM, тогда как Qwen 2.5 72B — всего 146,77 ГБ!
Попробуйте демо Qwen 2.5 7B сейчас!
Рекомендуемые GPU для развертывания Qwen 2.5 VL 72B
| Конфигурация | Общий VRAM | Примечания |
|---|---|---|
| 8× A100 80GB | 640 ГБ | Стандартная конфигурация для инференса больших моделей |
| 8× H100 80GB | 640 ГБ | Производительность выше, чем у A100 |
| 8× L40S 48GB | 384 ГБ | Новый корпоративный GPU от NVIDIA. Экономичен, но может потребовать оптимизированного пайплайна или 8-битного квантования для полного размещения модели. |
8× L40S = 384 ГБ общего VRAM, что находится на границе документированного минимума Qwen2.5-VL-72B.
Вам может понадобиться параллелизм модели и оптимизации vLLM, DeepSpeed или Hugging Face
accelerateдля обеспечения стабильности.Рассмотрите 8-битное или 4-битное квантование, если FP16 не помещается в память.
Стоимость развертывания Qwen 2.5 VL 72B
1. Значительно более высокая стоимость развертывания
- Вам потребуется больше GPU (например, 8×A100 80GB или несколько H100) или высокопроизводительные узлы GPU.
- Облачное развертывание становится значительно дороже по сравнению с текстовой версией.
2. Более высокий аппаратный барьер
- Многие разработчики просто не могут запустить VL-72B локально. Требуются многопроцессорные конфигурации и эффективный параллелизм модели.
- Также необходима высокая пропускная способность памяти и оптимизированная инфраструктура для стабильного инференса.
3. Более дорогой инференс
- Поставщики API будут взимать больше из-за увеличенного потребления ресурсов.
- Стоимость инференса может быть в 2–3 раза выше (или больше), чем у чисто текстовой модели того же размера.
4. Более низкая скорость инференса
- Визуальные энкодеры и мультимодальные слои слияния добавляют сложности.
- Обработка изображений добавляет накладные расходы к пропускной способности токенов, увеличивая задержку.
Почему Qwen 2.5 VL 72B требует больше VRAM, чем LLM того же размера
Qwen2.5-VL-72B — это самая современная мультимодальная большая языковая модель, разработанная Alibaba Cloud, предназначенная для понимания и генерации контента на основе как визуальных (изображения и видео), так и текстовых входов.
Имея 72 миллиарда параметров, модель отлично справляется с такими задачами, как разбор документов, анализ диаграмм, визуальный вопрос-ответ и понимание длинных видео, что делает её подходящей для сложных приложений, таких как AI-агенты и автоматизация предприятий.
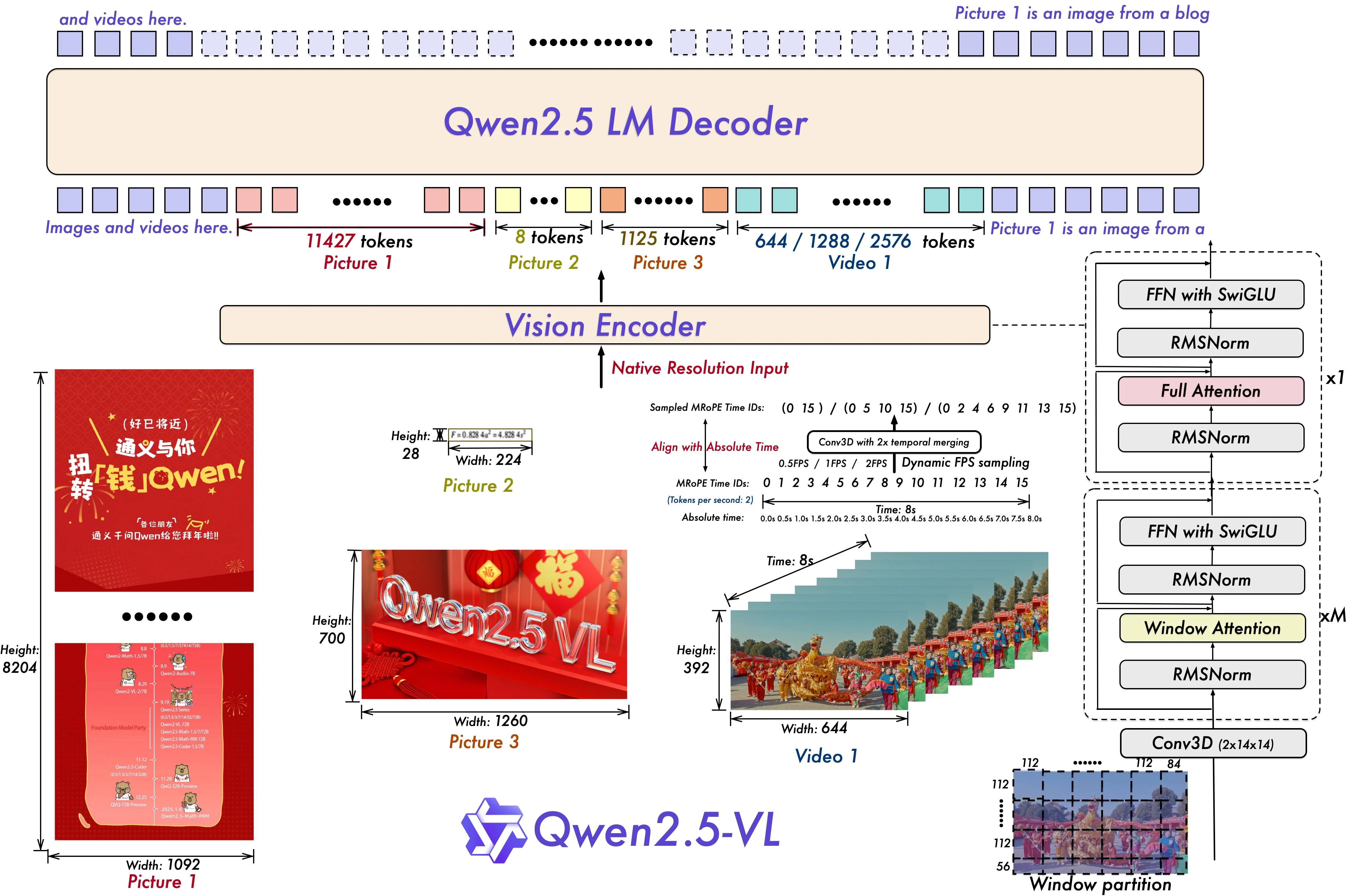
1. Динамическое разрешение и семплирование частоты кадров
Что это делает: Qwen2.5-VL-72B вводит динамическое разрешение и временное семплирование кадров, что позволяет обрабатывать видео с различной частотой кадров. Это означает, что модель может адаптироваться к разной скорости движения, определять ключевые события и рассуждать о времени — например, «когда что-то произошло» в сцене. Для поддержки этого модель обновляет свои мультимодальные вращательные позиционные вложения (mRoPE) с информацией об абсолютном времени и идентификаторе кадра.
Как это влияет на VRAM: Хотя динамическое семплирование звучит эффективно, поддержка переменного разрешения и частоты кадров означает, что модель должна резервировать ёмкость для нескольких временных паттернов. Это увеличивает потребность в памяти, особенно при обработке видео высокого разрешения или большой длительности. Кроме того, расширение mRoPE на временное измерение приводит к большему количеству токенов, вложений и слоёв внимания — всё это увеличивает использование VRAM.
2. Упрощённый Vision Transformer (ViT)
Что это делает: Визуальный энкодер модели построен на Vision Transformer с оконным вниманием, который обрабатывает изображения локальными патчами, а не целиком. Это помогает снизить вычислительные затраты. Qwen2.5-VL также использует SwiGLU и RMSNorm — современные техники, улучшающие скорость сходимости и числовую стабильность, сохраняя совместимость с основной языковой моделью Qwen2.5.
Как это влияет на VRAM: Оконное внимание действительно помогает экономить память по сравнению с полным вниманием, особенно для изображений высокого разрешения. Однако сам визуальный энкодер — особенно в модели на 72B — всё равно добавляет значительные накладные расходы. SwiGLU и RMSNorm сами по себе не являются крупными потребителями VRAM, но они добавляют дополнительные слои и операции. В результате визуальный стек оказывается более эффективным, чем у некоторых моделей, но всё равно требует десятков дополнительных гигабайт VRAM для плавной работы, особенно при больших размерах партий или длинном контексте.
Qwen2.5-VL-72B оптимизирован по производительности, но его архитектура по своей сути мультимодальна и требовательна к памяти. Он создан для понимания не только слов, но и сложных визуальных и временных паттернов.
Эти возможности сопряжены со значительными компромиссами по VRAM, что делает его гораздо более требовательным, чем стандартная 72B текстовая модель — даже если архитектурная эффективность является приоритетом.
Локальное развертывание Qwen2.5 VL 72B — непростая задача
Развертывание Qwen2.5-VL-72B локально может быть сложным из-за огромных потребностей в памяти — до 384 ГБ VRAM. Хотя существует несколько способов снизить нагрузку, каждый из них имеет свою сложность:
- Квантование сжимает модель до 8-битной или даже 4-битной точности, сокращая использование памяти до 75%. Однако для этого требуется инструментарий, такой как GPTQ или AWQ, и может повлиять на точность или совместимость.
- Параллелизм модели разделяет модель на несколько GPU, позволяя запускать её, даже если ни один отдельный GPU не имеет достаточно памяти. Но это требует высокоскоростных соединений (например, NVLink) и тщательной настройки — не для новичков.
- Эффективные движки инференса, такие как vLLM, могут оптимизировать повторное использование памяти и пропускную способность, но по-прежнему требуют надёжной инфраструктуры и определённых инженерных усилий для интеграции в продакшн.
- Облачное развертывание устраняет аппаратные преграды, но вам нужно будет управлять масштабированием, временем безотказной работы и стоимостью — и часто это всё равно требует настройки собственного контейнера.
Короче говоря: все эти решения работают, но они стоят времени, денег или того и другого. Именно поэтому для многих разработчиков, исследователей и команд, желающих быстро получить доступ к мультимодальной мощи Qwen2.5-VL-72B, лучшим вариантом часто оказывается самый простой — использование хорошо оптимизированного API-сервиса.
Используйте API вместо этого
Использование API позволяет вам пропустить хлопоты с настройкой оборудования, управлением памятью или беспокойством о совместимости. Вы получаете мгновенный доступ к полным возможностям Qwen2.5-VL-72B — зрение, язык и понимание видео — без инфраструктурного бремени. Просто отправляйте запрос, получайте ответ и сосредоточьтесь на создании.
Шаг 1: Войдите и получите доступ к библиотеке моделей
Войдите в свою учётную запись и нажмите на кнопку Model Library.

Шаг 2: Выберите модель
Просмотрите доступные опции и выберите модель, которая соответствует вашим потребностям.

Шаг 3: Начните бесплатную пробную версию
Начните бесплатную пробную версию, чтобы изучить возможности выбранной модели.
Попробуйте демо Qwen 2.5 VL 72B сейчас!
Шаг 4: Получите API-ключ
Для аутентификации в API мы предоставим вам новый API-ключ. Зайдите на страницу «Settings», чтобы скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, специфичного для вашего языка программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Вот пример использования API чат-завершений для пользователей Python.
from openai import OpenAI
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-vl-72b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen2.5-VL-72B является передовым, но его потребности в ресурсах высоки. Вместо того чтобы разбираться с многопроцессорными конфигурациями или настройкой квантования, большинству пользователей будет полезно использовать высокопроизводительный API. Это быстрее, проще и позволяет сосредоточиться на том, что действительно важно — создании умных приложений.
Можно ли запустить Qwen2.5-VL-72B на одном GPU?
Нет, если только вы не примените сильное квантование (например, 4-битное) и не используете очень мощный GPU, такой как H100 120GB — даже в этом случае производительность может пострадать.
Существует ли лёгкая версия Qwen-VL?
Да, Qwen2.5-VL-7B и Qwen2.5-VL-3B предлагают аналогичные мультимодальные возможности при меньших аппаратных затратах.
Можно ли использовать API для запросов с изображением + текстом?
Безусловно. Novita AI Qwen 2.5 VL 72B API поддерживает полный мультимодальный ввод — включая длинные видеокадры, диаграммы и вопросы-ответы на основе изображений.
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развёртывания AI-моделей с помощью нашего простого API, а также предлагает доступные и надёжные облачные GPU для создания и масштабирования.



