

推薦您的朋友使用 Novita AI,你們雙方都將獲得 $10 的 LLM API 額度——最高可累積 $500 的總獎勵。
為了支援開發者社群,Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B 目前在 Novita AI 上可免費使用。

Qwen 3 是由阿里巴巴建構的通用且強大的開源語言模型系列。憑藉先進的架構與雙模式推理能力,它旨在同時滿足邊緣裝置與大規模企業需求。本文將探討其能力、模型類型以及如何使用——無論是透過本機部署或 API。
什麼是 Qwen 3?
Qwen 3 是阿里巴巴於 2025 年推出的開源大型語言模型系列,具備可切換的「思考」與「非思考」模式,能增強推理能力與多語言表現,涵蓋 119 種以上語言。Qwen 3 模型陣容 包含:
- 密集模型(Dense models):
- 混合專家(Mixture-of-Experts, MoE)模型:
開源且商用友善
採用 Apache 2.0 授權,權重可自由用於研究與商業用途。 ### 高效 Transformer 核心
純解碼器架構,搭配分組查詢注意力(Grouped-Query-Attention),可為長上下文 KV 快取節省記憶體,最高支援 128K token。 ### 雙重「思考 / 非思考」模式
需要時提供詳細的思維鏈,重視速度時則給出簡潔的直接答案。 ### 龐大 36T token 語料庫
119 種語言,並擴充 STEM 與程式碼資料,以強化推理與程式設計能力。 ### 三階段預訓練
基礎技能 → STEM 強化 → 32K token 長上下文適應。 ### 四階段後訓練
長思維鏈 SFT → 推理強化學習 → 模式融合 → 通用 RLHF 對齊。 ### 多語言指令遵循
在英文與中文上表現優異,並在超過 100 種語言中表現穩健,適合全球應用。 ### 工具 / 代理就緒
內建函式呼叫架構,可決定外部工具呼叫的格式與時機。 ### 文字輸入 / 文字輸出形式
目前針對語言任務最佳化;未來版本預計推出視覺變體。
Qwen 3 系列架構
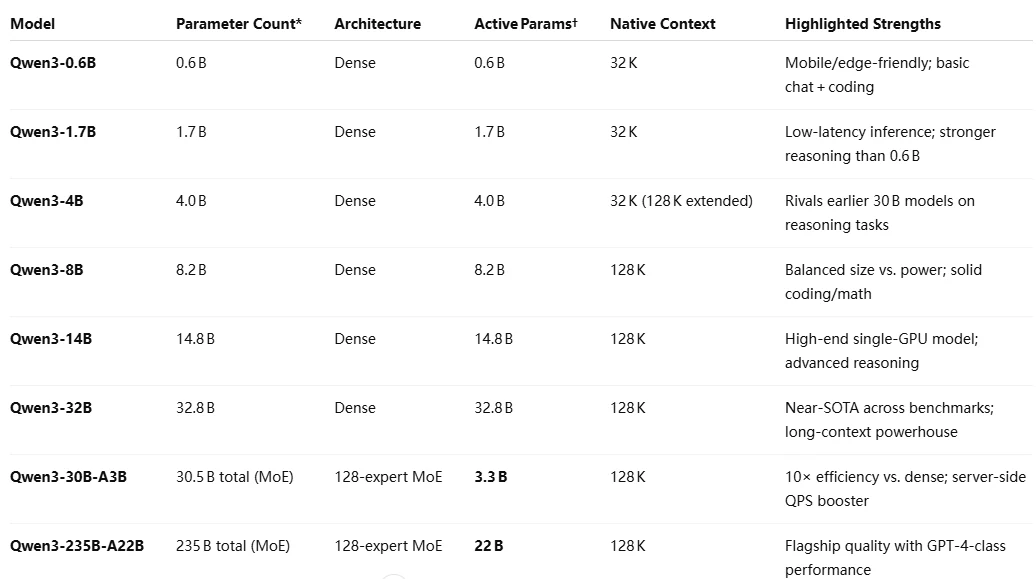
Qwen 3 系列基準測試
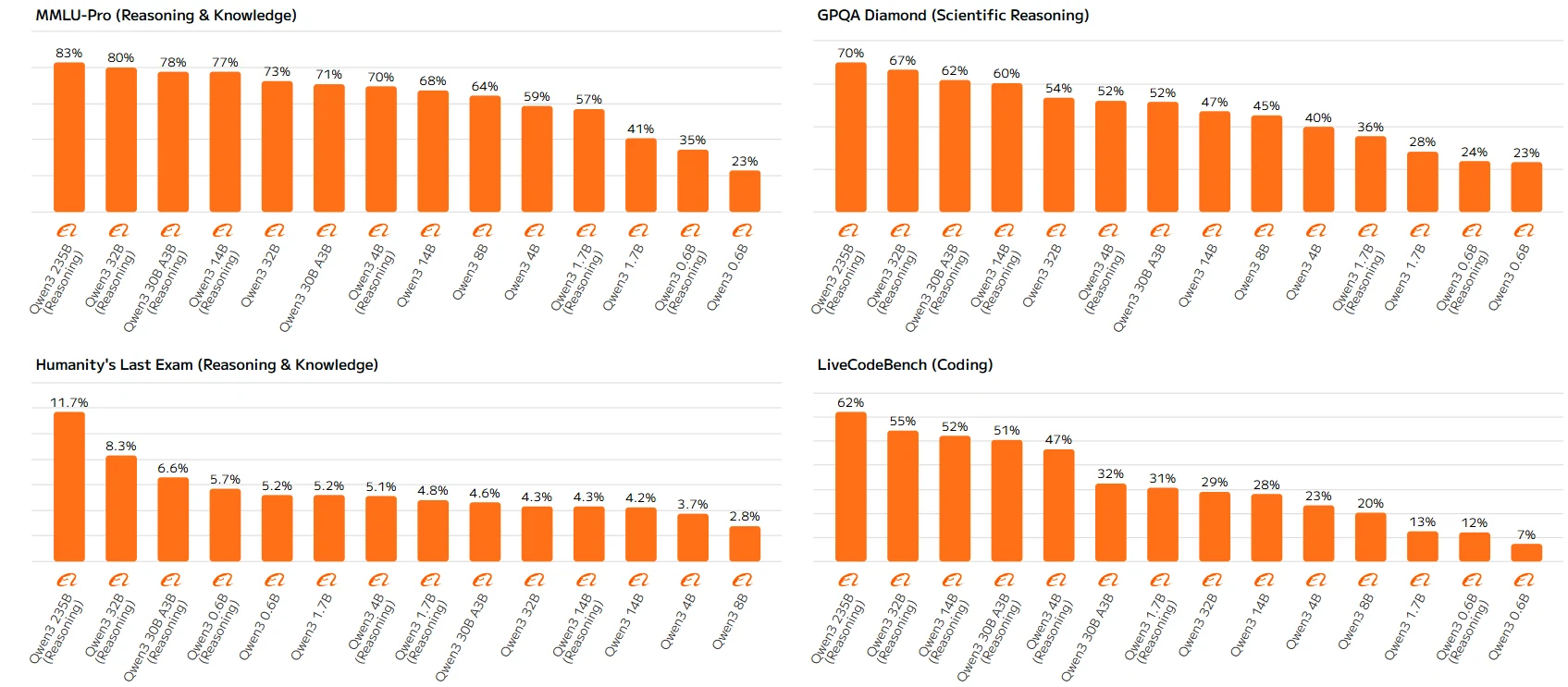
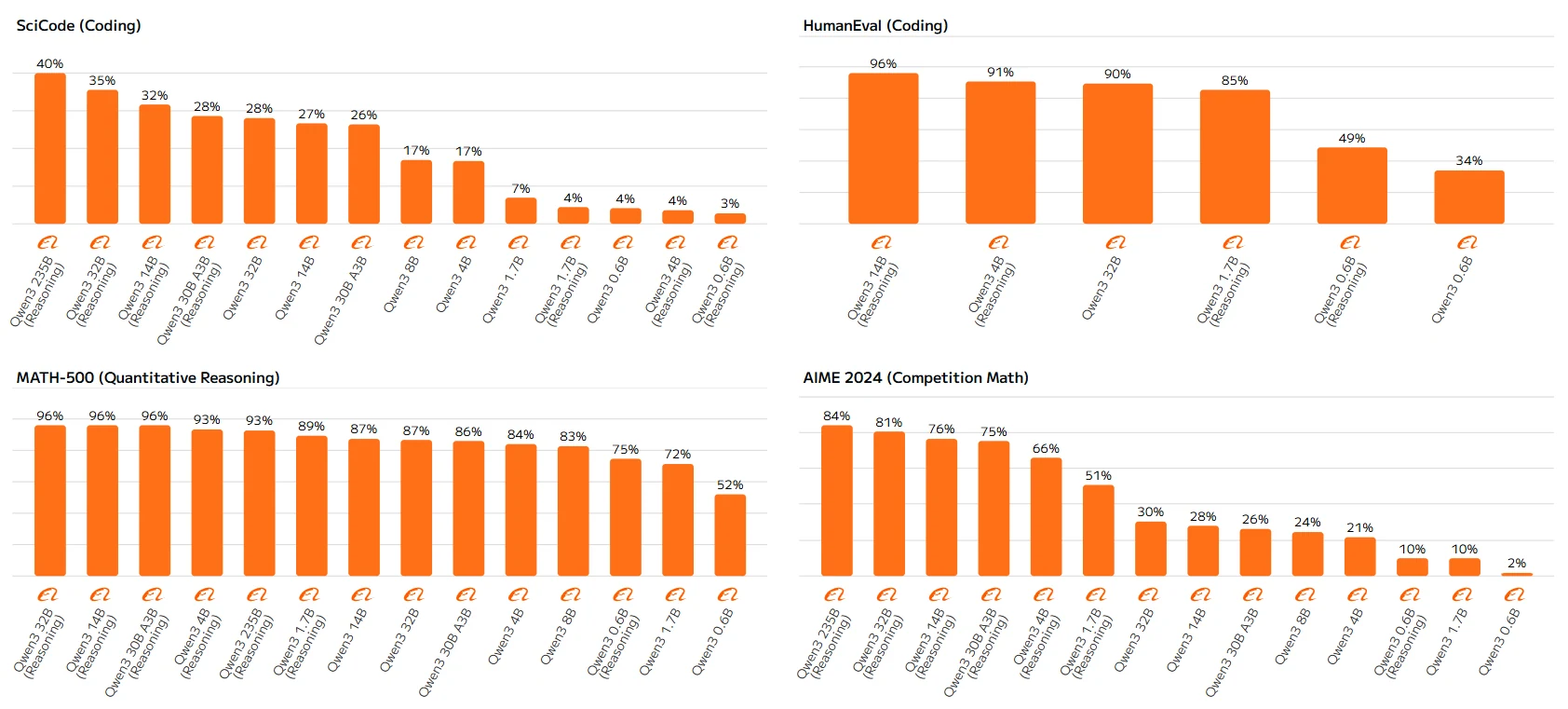
高參數模型(如 Qwen-23B 與 Qwen-14B)能始終遵循規則,較大的模型與啟用推理的版本得分更高。低參數模型中的這些差異可能源於其推理能力的限制,因為它們缺乏充分利用推理機制的容量,導致表現次佳。
如何在本機存取 Qwen 3?
硬體需求
| **模型 ** | ** 建議 GPU** | VRAM | vCPU | RAM | ** 儲存空間** |
|---|---|---|---|---|---|
| Qwen3-0.6B | RTX 3060 / T4 | 8 GB | 4 | 8 GB | 20 GB |
| Qwen3-1.7B | RTX 3060 / A5000 | 12–24 GB | 6–8 | 16 GB | 30 GB |
| Qwen3-4B | A100 40GB / RTX 3090 | 24–40 GB | 12+ | 24 GB | 40 GB |
| Qwen3-8B | A100 80GB / H100 | 40–80 GB | 16+ | 48 GB | 60 GB |
| Qwen3-14B | 2× A100 80GB / 1× H100 | 80 GB+ | 24+ | 64 GB | 80 GB |
| Qwen3-30B (MoE) | 2× H100 / 4× A100 | 160 GB | 48+ | 128 GB | 160 GB |
| Qwen3-32B | 2× H100 / 4× A100 | 160 GB | 64 | 160 GB | 200 GB |
| Qwen3-235B (MoE) | 8× H100 / 8× A100 | 640 GB | 128+ | 512 GB | 500+ GB |
逐步安裝指南
# 步驟 1:安裝 Python 並建立虛擬環境
# 確保已安裝 Python(>=3.8)。然後建立並啟用虛擬環境。
python3 -m venv llama_env
source llama_env/bin/activate # 在 Windows 上使用 `llama_env\Scripts\activate`
# 步驟 2:安裝所需函式庫
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # 為 GPU 最佳化
pip install bitsandbytes # 高效 GPU 記憶體使用
# 步驟 3:安裝 Hugging Face CLI 並登入
pip install huggingface-cli
huggingface-cli login # 依照提示進行驗證
# 步驟 4:請求存取 Llama-3.3 70B
# 前往 Llama-3.3 70B 的 Hugging Face 模型頁面並請求存取。
# URL: https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct
# 步驟 5:下載模型檔案
huggingface-cli download meta-llama/Llama-3.3-70B-Instruct --include "original/*" --local-dir Llama-3.3-70B-Instruct
# 步驟 6:在本機載入模型
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 模型 ID 與本機目錄路徑
model_id = "meta-llama/Llama-3.3-70B-Instruct"
local_model_dir = "./Llama-3.3-70B-Instruct"
# 以 GPU 最佳化載入模型
model = AutoModelForCausalLM.from_pretrained(
local_model_dir,
device_map="auto", # 自動將模型層對應到 GPU
torch_dtype=torch.bfloat16 # 使用 bfloat16 以節省記憶體
)
# 載入分詞器
tokenizer = AutoTokenizer.from_pretrained(local_model_dir)
# 步驟 7:執行推論
# 定義輸入文字
input_text = "Explain the theory of relativity in simple terms."
# 對輸入進行分詞
inputs = tokenizer(input_text, return_tensors="pt").to("cuda") # 將輸入送到 GPU
# 生成回應
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=100, # 設定回應最大長度
temperature=0.7, # 調整創意程度(越低越保守,越高越有創意)
top_k=50, # Top-k 取樣以增加多樣性
)
# 解碼輸出 token
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
如何透過 API 存取 Qwen 3
Novita AI 提供實惠、可靠且簡單的推論平台,搭配可擴展的 Llama 3.3 70b API,賦能開發者建構 AI 應用。立即試用 Novita AI Llama 3.3 70b API Demo!
選項 1:直接 API 整合(Python 範例)
主要特色:
- 統一端點:
/v3/openai支援 OpenAI 的聊天完成 API 格式。 - 彈性控制: 可調整 temperature、top-p、懲罰等參數,以獲得客製化結果。
- 串流與批次: 選擇您偏好的回應模式。
選項 2:搭配 OpenAI Agents SDK 的多代理工作流程
透過將 Novita AI 與 OpenAI Agents SDK 整合,建構進階的多代理系統:
- 即插即用: 在任何 OpenAI Agents 工作流程中使用 Novita AI 的 LLM。
- 支援移交、路由與工具使用: 設計能夠委派、分類或執行功能的代理,全部由 Novita AI 的模型驅動。
- Python 整合: 只需將 SDK 指向 Novita 的端點 (
https://api.novita.ai/v3/openai) 並使用您的 API 金鑰即可。
在第三方平台上連接 Qwen 3 API
- Hugging Face:透過 Novita AI 端點,在 Spaces、pipeline 或 Transformers 函式庫中使用 Qwen 3。
- 代理與編排框架: 透過官方連接器與逐步整合指南,輕鬆將 Novita AI 與合作夥伴平台如 Continue、AnythingLLM、LangChain、Dify 和 Langflow 連接。
- 相容 OpenAI 的 API: 透過專為 OpenAI API 標準設計的工具(如 Cline 與 Cursor),享受無痛遷移與整合。
哪種方法適合您?
本機與 API 存取比較
| 面向 | 本機存取 | API 存取 |
| 可擴展性 | 有限;需要手動升級。 | 自動且高效擴展。 |
| 彈性 | 高彈性;完全掌控設定。 | 較不彈性;依賴提供者的配置。 |
| 易用性 | 需要技術專業知識。 | 較易使用,無需複雜設定。 |
| 成本效益 | 初期成本高,後續成本低。最適合長期使用。 | 按用量付費,適合小規模或偶爾使用。 |
不同使用者群組的建議
- 研究人員 ** → 偏好 本機存取**以獲得完整控制與實驗彈性。
- 開發者 ** → 使用 API 進行快速測試與建構應用程式;需要自訂訓練時則選擇 ** 本機。
- 企業 ** → API 適合輕鬆整合; 本機**適合需求穩定的團隊。
- **小型團隊與個人 ** → API 更符合預算且易於入門。
- **非技術使用者 ** → 絕對選擇 API——無需複雜設定。
無論您是研究人員、開發者還是企業團隊,Qwen 3 都能滿足您的需求。本機存取提供控制與客製化,而 API 則提供即時可擴展性與低進入門檻。Qwen 3 的設計確保其具備強大的多語言、推理與工具增強能力,適用於真實世界的任務。
常見問題
Qwen 3 與其他 LLM 有何不同?
它支援雙重思考模式、強大的多語言指令遵循與長上下文(128k token),同時具備開源權重與商用友善授權。
我可以在個人電腦上執行 Qwen 3 嗎?
只有最小的模型(例如 0.6B)適合消費級 GPU。較大的模型需要 A100/H100 配置。
API 存取比較簡單嗎?
是的!Novita AI 與 Hugging Face 提供低成本、即插即用的 Qwen 3 API——非常適合快速整合與低延遲使用。
Novita AI 是一站式雲端平台,助您實現 AI 願景。整合 API、無伺服器、GPU 實例——您所需的經濟高效工具。免除基礎設施煩惱,免費開始,讓您的 AI 願景成真。



