

친구를 Novita AI에 추천하면 두 분 모두 $10 상당의 LLM API 크레딧을 받을 수 있습니다. 최대 $500까지 적립 가능합니다.
개발자 커뮤니티를 지원하기 위해 Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B를 현재 Novita AI에서 무료로 제공합니다.

Qwen 3는 Alibaba가 구축한 다재다능하고 강력한 오픈소스 언어 모델 제품군입니다. 최첨단 아키텍처와 이중 모드 추론을 갖추고 있어 엣지 디바이스부터 대규모 엔터프라이즈 요구 사항까지 지원하도록 설계되었습니다. 이 글에서는 Qwen 3의 기능, 모델 유형, 그리고 로컬 또는 API를 통해 사용하는 방법을 살펴봅니다.
Qwen 3란 무엇인가?
Qwen 3 는 Alibaba의 2025년 오픈소스 대규모 언어 모델 제품군으로, 전환 가능한 “생각” 모드와 “비생각” 모드를 갖추고 있어 119개 이상의 언어에 걸쳐 향상된 추론 및 다국어 성능을 제공합니다. Qwen 3 모델 라인업 은 다음과 같습니다:
- Dense 모델:
- Mixture-of-Experts (MoE) 모델:
오픈소스 및 상업적 사용 가능
Apache 2.0 라이선스로 연구 및 비즈니스 사용에 자유롭게 사용할 수 있는 가중치를 제공합니다. ### 효율적인 Transformer 코어
Grouped-Query-Attention을 사용한 Decoder‑only 아키텍처로 최대 128K 토큰의 장문 컨텍스트 KV 메모리를 절약합니다. ### 이중 “생각 / 비생각” 모드
필요할 때는 상세한 chain-of-thought, 속도가 중요할 때는 빠른 직접 응답을 제공합니다. ### 거대한 36T 토큰 코퍼스
119개 언어와 확장된 STEM 및 코드 데이터로 더 강력한 추론 및 프로그래밍 능력을 제공합니다. ### 3단계 사전 학습
기본 능력 → STEM 강화 → 32K 토큰 장문 컨텍스트 적응. ### 4단계 사후 학습
Long CoT SFT → 추론 RL → 모드 융합 → 일반 RLHF 정렬. ### 다국어 명령 수행
영어와 중국어에 강하며, 100개 이상의 언어에서 글로벌 애플리케이션을 위한 견고한 성능을 제공합니다. ### 도구 / 에이전트 준비
내장된 함수 호출 스키마로 외부 도구 호출을 결정하고 형식화합니다. ### 텍스트 입력 / 텍스트 출력 모달리티
현재 언어 작업에 최적화되어 있으며, 향후 출시될 비전 변형이 계획되어 있습니다.
Qwen 3 시리즈 아키텍처
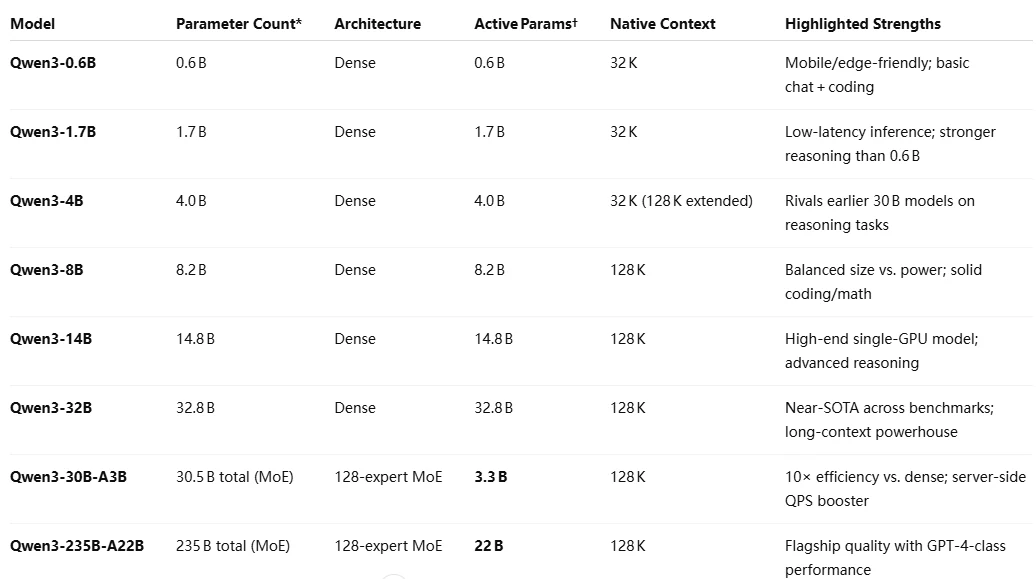
Qwen 3 시리즈 벤치마크
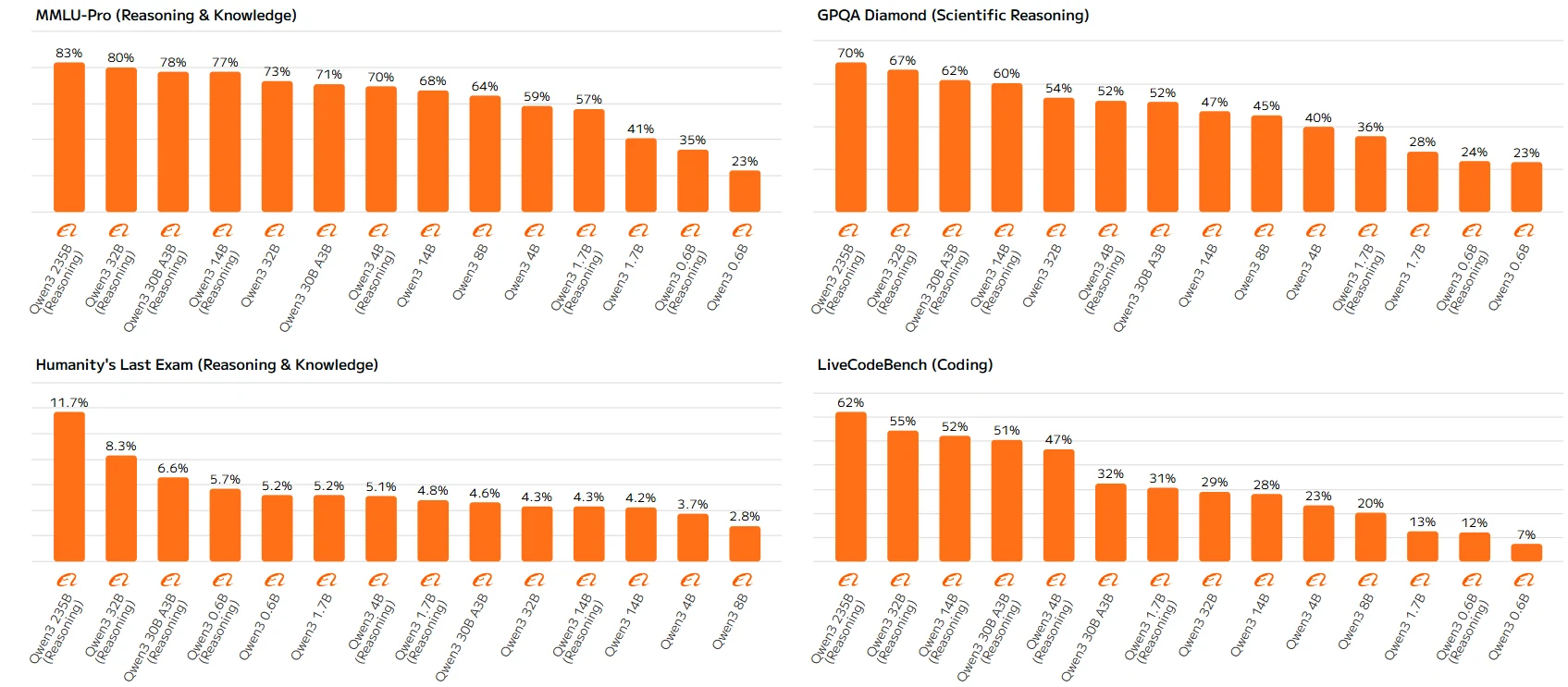
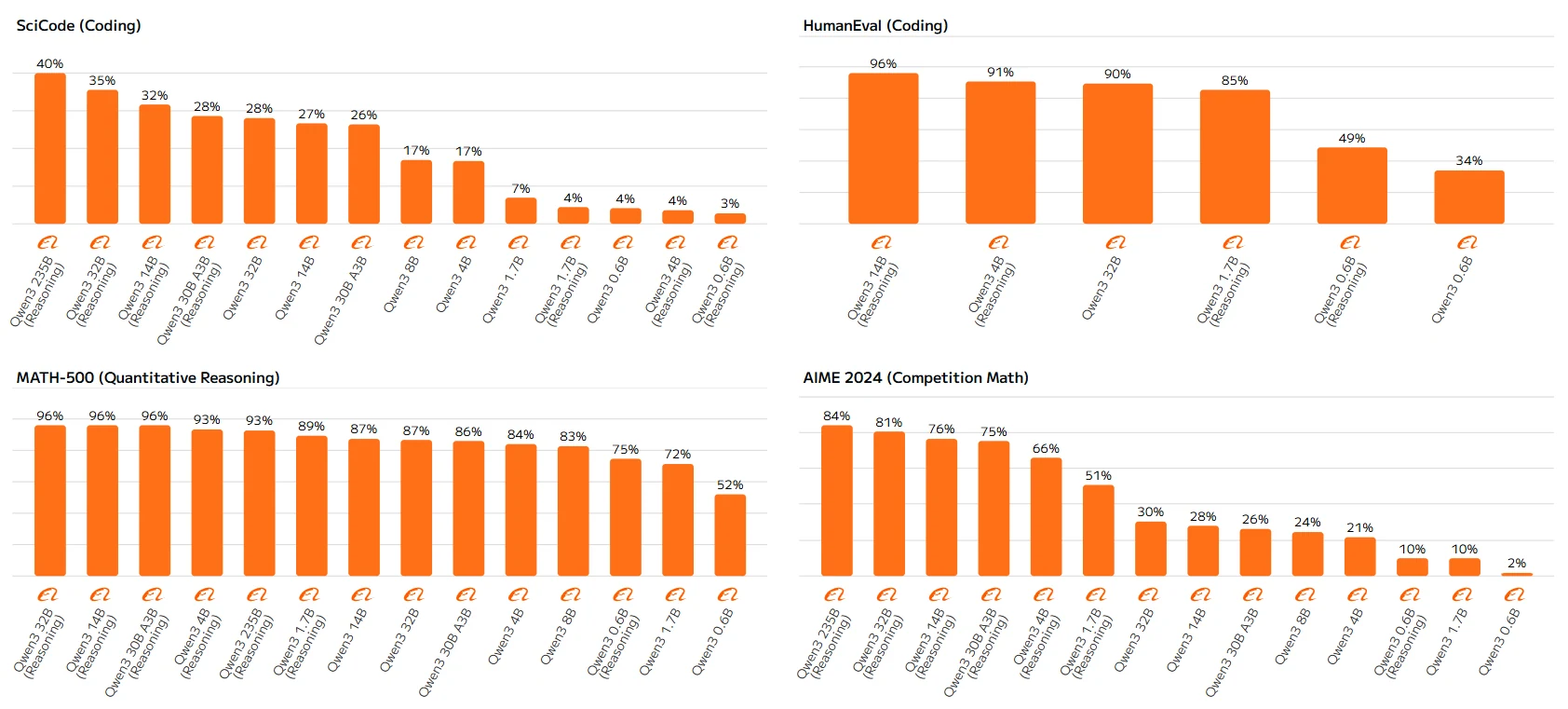
고파라미터 모델(예: Qwen-23B, Qwen-14B)은 일관되게 규칙을 따르며, 더 큰 모델과 추론 활성화 버전이 더 높은 점수를 기록합니다. 저파라미터 모델의 이러한 차이는 추론 능력의 한계에서 비롯될 수 있으며, 추론 메커니즘을 완전히 활용할 능력이 부족하여 최적 이하의 성능을 보입니다.
Qwen 3를 로컬에서 사용하는 방법
하드웨어 요구 사항
| **모델 ** | ** 권장 GPU** | VRAM | vCPUs | RAM | ** 저장 공간** |
|---|---|---|---|---|---|
| Qwen3-0.6B | RTX 3060 / T4 | 8 GB | 4 | 8 GB | 20 GB |
| Qwen3-1.7B | RTX 3060 / A5000 | 12–24 GB | 6–8 | 16 GB | 30 GB |
| Qwen3-4B | A100 40GB / RTX 3090 | 24–40 GB | 12+ | 24 GB | 40 GB |
| Qwen3-8B | A100 80GB / H100 | 40–80 GB | 16+ | 48 GB | 60 GB |
| Qwen3-14B | 2× A100 80GB / 1× H100 | 80 GB+ | 24+ | 64 GB | 80 GB |
| Qwen3-30B (MoE) | 2× H100 / 4× A100 | 160 GB | 48+ | 128 GB | 160 GB |
| Qwen3-32B | 2× H100 / 4× A100 | 160 GB | 64 | 160 GB | 200 GB |
| Qwen3-235B (MoE) | 8× H100 / 8× A100 | 640 GB | 128+ | 512 GB | 500+ GB |
단계별 설치 가이드
# Step 1: Install Python and Create a Virtual Environment
# Ensure Python (>=3.8) is installed. Then create and activate a virtual environment.
python3 -m venv llama_env
source llama_env/bin/activate # On Windows, use `llama_env\Scripts\activate`
# Step 2: Install Required Libraries
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # For GPU optimization
pip install bitsandbytes # Efficient GPU memory utilization
# Step 3: Install the Hugging Face CLI and Log In
pip install huggingface-cli
huggingface-cli login # Follow the prompts to authenticate
# Step 4: Request Access to Llama-3.3 70B
# Visit the Hugging Face model page for Llama-3.3 70B and request access.
# URL: https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct
# Step 5: Download the Model Files
huggingface-cli download meta-llama/Llama-3.3-70B-Instruct --include "original/*" --local-dir Llama-3.3-70B-Instruct
# Step 6: Load the Model Locally
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Model ID and local directory path
model_id = "meta-llama/Llama-3.3-70B-Instruct"
local_model_dir = "./Llama-3.3-70B-Instruct"
# Load the model with GPU optimization
model = AutoModelForCausalLM.from_pretrained(
local_model_dir,
device_map="auto", # Automatically map model layers to GPU(s)
torch_dtype=torch.bfloat16 # Use bfloat16 for efficient memory usage
)
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained(local_model_dir)
# Step 7: Run Inference
# Define input text
input_text = "Explain the theory of relativity in simple terms."
# Tokenize the input
inputs = tokenizer(input_text, return_tensors="pt").to("cuda") # Send inputs to GPU
# Generate a response
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=100, # Set maximum response length
temperature=0.7, # Adjust creativity (lower = less creative, higher = more creative)
top_k=50, # Top-k sampling for diversity
)
# Decode the output tokens
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
Qwen 3를 API로 사용하는 방법
Novita AI 는 확장 가능한 Llama 3.3 70b API 를 갖춘 합리적인 가격의 안정적이고 간단한 추론 플랫폼을 제공하여 개발자가 AI 애플리케이션을 구축할 수 있도록 지원합니다. 지금 Novita AI Llama 3.3 70b API 데모 를 사용해보세요!
옵션 1: 직접 API 통합 (Python 예시)
주요 기능:
- 통합 엔드포인트:
/v3/openai는 OpenAI의 Chat Completions API 형식을 지원합니다. - 유연한 제어: 온도, top-p, 패널티 등을 조정하여 맞춤형 결과를 얻을 수 있습니다.
- 스트리밍 및 배치: 원하는 응답 방식을 선택하세요.
옵션 2: OpenAI Agents SDK를 사용한 멀티 에이전트 워크플로우
Novita AI를 OpenAI Agents SDK와 통합하여 고급 멀티 에이전트 시스템을 구축하세요:
- 플러그 앤 플레이: Novita AI의 LLM을 모든 OpenAI Agents 워크플로우에서 사용할 수 있습니다.
- 핸드오프, 라우팅, 도구 사용 지원: 에이전트가 위임, 분류 또는 함수를 실행할 수 있도록 설계되었으며, 모두 Novita AI의 모델로 구동됩니다.
- Python 통합: SDK를 Novita 엔드포인트(
https://api.novita.ai/v3/openai)로 지정하고 API 키를 사용하기만 하면 됩니다.
제3자 플랫폼에서 Qwen 3 API 연결
- Hugging Face: Novita AI 엔드포인트를 통해 Spaces, 파이프라인 또는 Transformers 라이브러리에서 Qwen 3를 사용하세요.
- 에이전트 및 오케스트레이션 프레임워크: 공식 커넥터와 단계별 통합 가이드를 통해 Continue, AnythingLLM, LangChain, Dify, Langflow와 같은 파트너 플랫폼에 Novita AI를 쉽게 연결할 수 있습니다.
- OpenAI 호환 API: OpenAI API 표준에 맞춰 설계된 Cline 및 Cursor와 같은 도구와의 간편한 마이그레이션 및 통합을 누리세요.
어떤 방법이 적합한가?
로컬 vs. API 접근 비교
| 측면 | 로컬 접근 | API 접근 |
| 확장성 | 제한적이며 수동 업그레이드 필요. | 자동으로 효율적으로 확장됨. |
| 유연성 | 매우 높음, 설정을 완전히 제어 가능. | 덜 유연함, 제공자의 구성에 의존. |
| 사용 편의성 | 기술적 전문성 필요. | 사용하기 쉬우며 복잡한 설정 불필요. |
| 경제성 | 초기 비용 높지만 지속 비용 낮음. 장기 사용에 최적. | 사용량 기반 지불, 소규모 또는 간헐적 사용에 이상적. |
다양한 사용자 그룹에 대한 권장 사항
- 연구자 ** → 완전한 제어와 실험 유연성을 위해 ** 로컬 접근 선호.
- 개발자 ** → 빠른 테스트 및 앱 구축에는 API 사용, 맞춤형 학습에는 ** 로컬 사용.
- **기업 ** → API 는 쉬운 통합에 좋고, 로컬 은 안정적인 요구 사항을 가진 팀에 적합.
- **소규모 팀 및 개인 ** → API 가 예산에 더 적합하고 시작하기 쉬움.
- **비기술적 사용자 ** → 확실히 API 를 선택하세요—복잡한 설정이 필요 없습니다.
연구자, 개발자 또는 기업 팀이든 Qwen 3는 여러분의 필요에 맞게 조정됩니다. 로컬 접근은 제어와 사용자 정의를 제공하고, API는 즉각적인 확장성과 낮은 진입 장벽을 제공합니다. Qwen 3의 설계는 실제 작업을 위한 강력한 다국어, 추론 및 도구 증강 능력을 보장합니다.
자주 묻는 질문
Qwen 3가 다른 LLM과 다른 점은 무엇인가요?
이중 사고 모드, 강력한 다국어 명령 수행, 긴 컨텍스트(128k 토큰)를 지원하며, 오픈 가중치와 상업적 사용에 친화적인 라이선스를 제공합니다.
PC에서 Qwen 3를 실행할 수 있나요?
가장 작은 모델(예: 0.6B)만 소비자용 GPU에 적합합니다. 더 큰 모델은 A100/H100 설정이 필요합니다.
API 접근이 더 쉬운가요?
네! Novita AI와 Hugging Face는 저비용의 플러그 앤 플레이 Qwen 3 API를 제공합니다—빠른 통합과 저지연 사용에 완벽합니다.
Novita AI는 AI 야망을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 필요한 비용 효율적인 도구를 제공합니다. 인프라를 제거하고, 무료로 시작하여 AI 비전을 현실로 만드세요.



