

Empfehlen Sie Novita AI an Ihre Freunde, und Sie beide erhalten $10 in LLM-API-Guthaben – bis zu $500 an Gesamtbelohnungen.
Um die Entwickler-Community zu unterstützen, stehen Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B derzeit kostenlos auf Novita AI zur Verfügung.

Qwen 3 ist eine vielseitige und leistungsstarke Open-Source-Sprachmodellfamilie von Alibaba. Mit modernster Architektur und dualem Reasoning-Modus ist sie sowohl für Edge-Geräte als auch für große Unternehmensanforderungen konzipiert. Dieser Artikel untersucht ihre Fähigkeiten, Modelltypen und wie man sie – entweder lokal oder per API – nutzt.
Was ist Qwen 3?
Qwen 3 ist Alibabas Open-Source-LLM-Familie von 2025 mit umschaltbaren „Thinking“- und „Non-Thinking“-Modi für verbesserte Reasoning-Fähigkeiten und mehrsprachige Leistung in über 119 Sprachen. Die Qwen 3-Modellreihe umfasst:
- Dichte Modelle:
- Mixture-of-Experts (MoE)-Modelle:
Open Source & kommerziell nutzbar
Apache-2.0-Lizenz, frei verfügbare Gewichte für Forschung und geschäftliche Nutzung. ### Effizienter Transformer-Kern
Decoder-only mit Grouped-Query-Attention für KV-Speicherersparnisse bei langen Kontexten bis zu 128 K Token. ### Duale „Thinking / Non-Thinking“-Modi
Detaillierte Gedankenkette bei Bedarf, schnelle direkte Antworten, wenn Geschwindigkeit zählt. ### Massives Korpus von 36 Billionen Token
119 Sprachen mit erweiterten STEM- und Code-Daten für stärkere Reasoning- und Programmierfähigkeiten. ### Drei-Stufen-Pretraining
Basiskenntnisse → STEM-Anreicherung → Langkontext-Anpassung auf 32 K Token. ### Vier-Stufen-Posttraining
Long CoT SFT → Reasoning RL → Modusfusion → allgemeines RLHF-Alignment. ### Mehrsprachige Instruktionsbefolgung
Stark in Englisch und Chinesisch, robust in über 100 Sprachen für globale Anwendungen. ### Tool‑/Agent‑Bereitschaft
Eingebaute Funktionsaufruf-Schemata zur Entscheidung und Formatierung externer Tool-Aufrufe. ### Text‑in / Text‑out‑Modalität
Optimiert für Sprachaufgaben heute; Vision-Varianten sind für zukünftige Veröffentlichungen geplant.
Qwen 3-Serien-Architektur
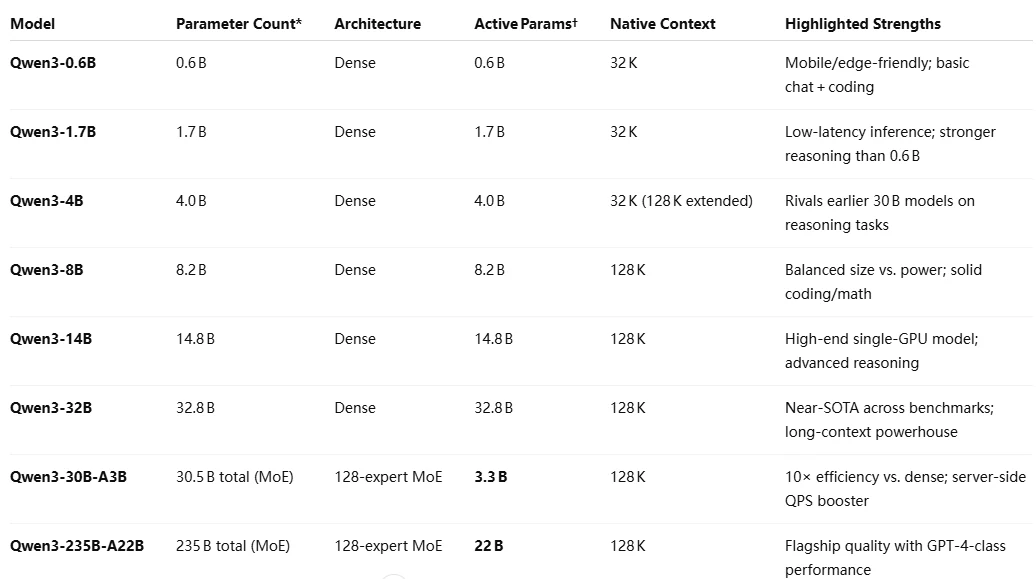
Qwen 3-Serien-Benchmark
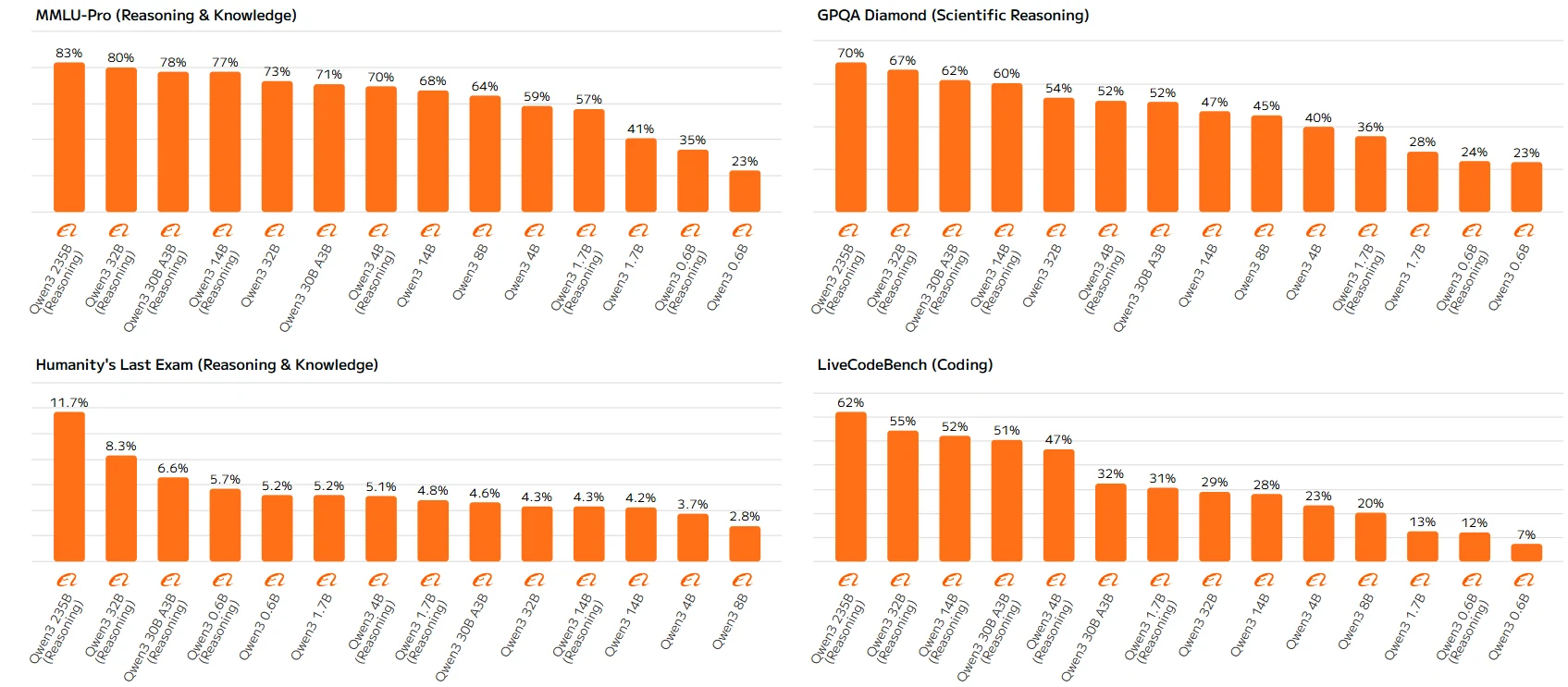
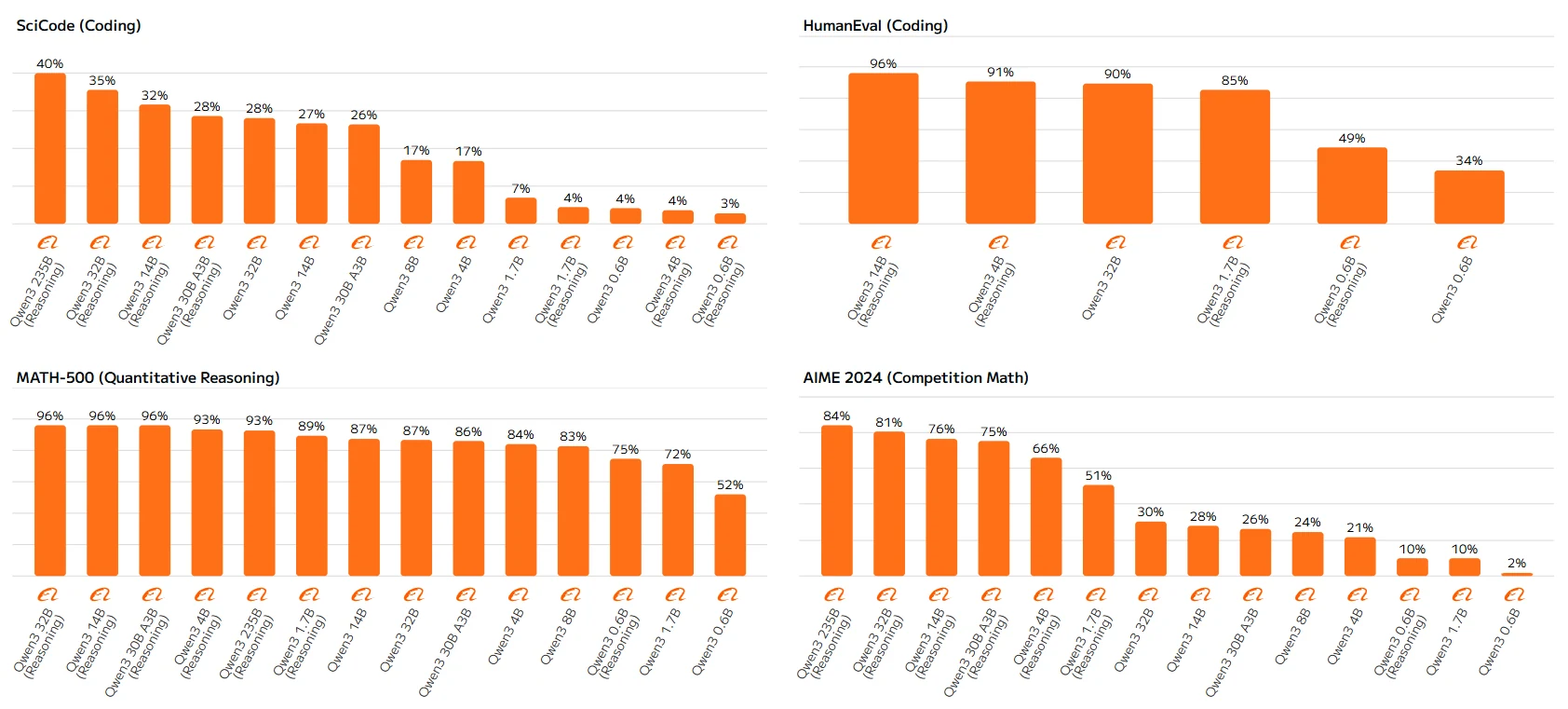
Modelle mit hohen Parameterzahlen wie Qwen-23B und Qwen-14B befolgen die Regeln durchgängig, wobei größere Modelle und Reasoning-fähige Versionen höher punkten. Diese Diskrepanzen bei Modellen mit niedrigen Parameterzahlen könnten auf Einschränkungen ihrer Reasoning-Fähigkeiten zurückzuführen sein, da ihnen die Kapazität fehlt, Reasoning-Mechanismen voll auszuschöpfen, was zu suboptimaler Leistung führt.
Wie greife ich lokal auf Qwen 3 zu?
Hardware-Anforderungen
| Modell | Empfohlene GPU | VRAM | vCPUs | RAM | Speicher |
|---|---|---|---|---|---|
| Qwen3-0.6B | RTX 3060 / T4 | 8 GB | 4 | 8 GB | 20 GB |
| Qwen3-1.7B | RTX 3060 / A5000 | 12–24 GB | 6–8 | 16 GB | 30 GB |
| Qwen3-4B | A100 40GB / RTX 3090 | 24–40 GB | 12+ | 24 GB | 40 GB |
| Qwen3-8B | A100 80GB / H100 | 40–80 GB | 16+ | 48 GB | 60 GB |
| Qwen3-14B | 2× A100 80GB / 1× H100 | 80 GB+ | 24+ | 64 GB | 80 GB |
| Qwen3-30B (MoE) | 2× H100 / 4× A100 | 160 GB | 48+ | 128 GB | 160 GB |
| Qwen3-32B | 2× H100 / 4× A100 | 160 GB | 64 | 160 GB | 200 GB |
| Qwen3-235B (MoE) | 8× H100 / 8× A100 | 640 GB | 128+ | 512 GB | 500+ GB |
Schritt-für-Schritt-Installationsanleitung
# Schritt 1: Python installieren und eine virtuelle Umgebung erstellen
# Stellen Sie sicher, dass Python (>=3.8) installiert ist. Erstellen und aktivieren Sie dann eine virtuelle Umgebung.
python3 -m venv llama_env
source llama_env/bin/activate # Unter Windows: `llama_env\Scripts\activate`
# Schritt 2: Erforderliche Bibliotheken installieren
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # Für GPU-Optimierung
pip install bitsandbytes # Effiziente GPU-Speichernutzung
# Schritt 3: Hugging Face CLI installieren und anmelden
pip install huggingface-cli
huggingface-cli login # Folgen Sie den Anweisungen zur Authentifizierung
# Schritt 4: Zugriff auf Llama-3.3 70B anfordern
# Besuchen Sie die Hugging Face-Modellseite für Llama-3.3 70B und fordern Sie Zugriff an.
# URL: https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct
# Schritt 5: Modell-Dateien herunterladen
huggingface-cli download meta-llama/Llama-3.3-70B-Instruct --include "original/*" --local-dir Llama-3.3-70B-Instruct
# Schritt 6: Modell lokal laden
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Modell-ID und lokaler Verzeichnispfad
model_id = "meta-llama/Llama-3.3-70B-Instruct"
local_model_dir = "./Llama-3.3-70B-Instruct"
# Modell mit GPU-Optimierung laden
model = AutoModelForCausalLM.from_pretrained(
local_model_dir,
device_map="auto", # Modell-Layer automatisch auf GPU(s) verteilen
torch_dtype=torch.bfloat16 # bfloat16 für effiziente Speichernutzung verwenden
)
# Tokenizer laden
tokenizer = AutoTokenizer.from_pretrained(local_model_dir)
# Schritt 7: Inferenz ausführen
# Eingabetext definieren
input_text = "Explain the theory of relativity in simple terms."
# Eingabe tokenisieren
inputs = tokenizer(input_text, return_tensors="pt").to("cuda") # Eingaben an GPU senden
# Antwort generieren
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=100, # Maximale Antwortlänge festlegen
temperature=0.7, # Kreativität anpassen (niedriger = weniger kreativ, höher = kreativer)
top_k=50, # Top-k Sampling für Vielfalt
)
# Ausgabe-Token dekodieren
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
Wie greife ich per API auf Qwen 3 zu?
Novita AI bietet eine erschwingliche, zuverlässige und einfache Inferenz-Plattform mit skalierbarer Llama 3.3 70b API, die Entwicklern hilft, KI-Anwendungen zu erstellen. Probieren Sie noch heute die Novita AI Llama 3.3 70b API Demo aus!
Option 1: Direkte API-Integration (Python-Beispiel)
Jetzt Qwen3 zu einem sehr niedrigen Preis testen!
Hauptmerkmale:
- Einheitlicher Endpunkt:
/v3/openaiunterstützt das Chat-Completions-API-Format von OpenAI. - Flexible Steuerung: Passen Sie Temperatur, Top-p, Strafen und mehr für maßgeschneiderte Ergebnisse an.
- Streaming & Batching: Wählen Sie Ihren bevorzugten Antwortmodus.
Option 2: Multi-Agent-Workflows mit dem OpenAI Agents SDK
Erstellen Sie fortschrittliche Multi-Agent-Systeme, indem Sie Novita AI mit dem OpenAI Agents SDK integrieren:
- Plug-and-Play: Verwenden Sie die LLMs von Novita AI in jedem OpenAI Agents-Workflow.
- Unterstützt Übergaben, Routing und Tool-Nutzung: Entwerfen Sie Agenten, die delegieren, priorisieren oder Funktionen ausführen können – alle angetrieben von Novita AIs Modellen.
- Python-Integration: Richten Sie das SDK einfach auf Novitas Endpunkt (
https://api.novita.ai/v3/openai) und verwenden Sie Ihren API-Schlüssel.
Qwen 3 API auf Drittanbieter-Plattformen verbinden
- Hugging Face: Verwenden Sie Qwen 3 in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
- Agenten- und Orchestrierungs-Frameworks: Verbinden Sie Novita AI einfach mit Partnerplattformen wie Continue, AnythingLLM, LangChain, Dify und Langflow über offizielle Konnektoren und schrittweise Integrationsanleitungen.
- OpenAI-kompatible API: Genießen Sie eine reibungslose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI-API-Standard entwickelt wurden.
Welche Methoden sind für Sie geeignet?
Vergleich von lokalem Zugriff vs. API-Zugriff
| Aspekt | Lokaler Zugriff | API-Zugriff |
| Skalierbarkeit | Begrenzt; erfordert manuelle Upgrades. | Skaliert automatisch und effizient. |
| Flexibilität | Hohe Flexibilität; volle Kontrolle über Einstellungen. | Weniger flexibel; abhängig von den Konfigurationen des Anbieters. |
| Benutzerfreundlichkeit | Erfordert technisches Fachwissen. | Einfacher zu bedienen, kein komplexer Setup nötig. |
| Erschwinglichkeit | Hohe Anschaffungskosten, niedrige laufende Kosten. Am besten für langfristige Nutzung. | Pay-per-Use, ideal für kleine oder gelegentliche Nutzung. |
Empfehlungen für verschiedene Benutzergruppen
- Forscher → Bevorzugen lokalen Zugriff für vollständige Kontrolle und Experimentierflexibilität.
- Entwickler → Nutzen API für schnelles Testen und Erstellen von Apps; lokal für benutzerdefiniertes Training.
- Unternehmen → API ist ideal für einfache Integration; lokal für Teams mit stabilen Anforderungen.
- Kleine Teams & Einzelpersonen → API ist budgetfreundlicher und einfacher zu starten.
- Nicht-technische Benutzer → Auf jeden Fall API – kein komplexer Setup erforderlich.
Ob Sie Forscher, Entwickler oder Unternehmensteam sind – Qwen 3 passt sich Ihren Bedürfnissen an. Der lokale Zugriff bietet Kontrolle und Anpassungsmöglichkeiten, während APIs sofortige Skalierbarkeit und niedrige Einstiegshürden bieten. Das Design von Qwen 3 gewährleistet starke mehrsprachige, Reasoning- und Tool-gestützte Fähigkeiten für reale Aufgaben.
Häufig gestellte Fragen
Was unterscheidet Qwen 3 von anderen LLMs?
Es unterstützt duale Thinking-Modi, starke mehrsprachige Instruktionen und lange Kontexte (128k Token), mit offenen Gewichten und kommerziell freundlicher Lizenzierung.
Kann ich Qwen 3 auf meinem PC ausführen?
Nur die kleinsten Modelle (z. B. 0.6B) sind für Consumer-GPUs geeignet. Größere Modelle erfordern A100/H100-Setups.
Ist der API-Zugriff einfacher?
Ja! Novita AI und Hugging Face bieten kostengünstige, Plug-and-Play Qwen 3 APIs – perfekt für schnelle Integration und geringe Latenz.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, Serverless, GPU-Instanz – die kosteneffizienten Tools, die Sie brauchen. Eliminieren Sie Infrastruktur, starten Sie kostenlos und verwirklichen Sie Ihre KI-Vision.



