

友達を Novita AI に紹介すると、あなたと友達の両方が LLM API クレジットとして $10 を獲得できます(最大 $500 まで)。
開発者コミュニティを支援するため、Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B は現在 Novita AI で無料で利用できます。

Qwen 3 は、Alibaba が開発した多用途で強力なオープンソース言語モデルファミリーです。最先端のアーキテクチャとデュアルモード推論を備えており、エッジデバイスから大規模エンタープライズニーズまで対応できるように設計されています。この記事では、その機能、モデルの種類、そしてローカルまたはAPI経由での使用方法について解説します。
Qwen 3 とは?
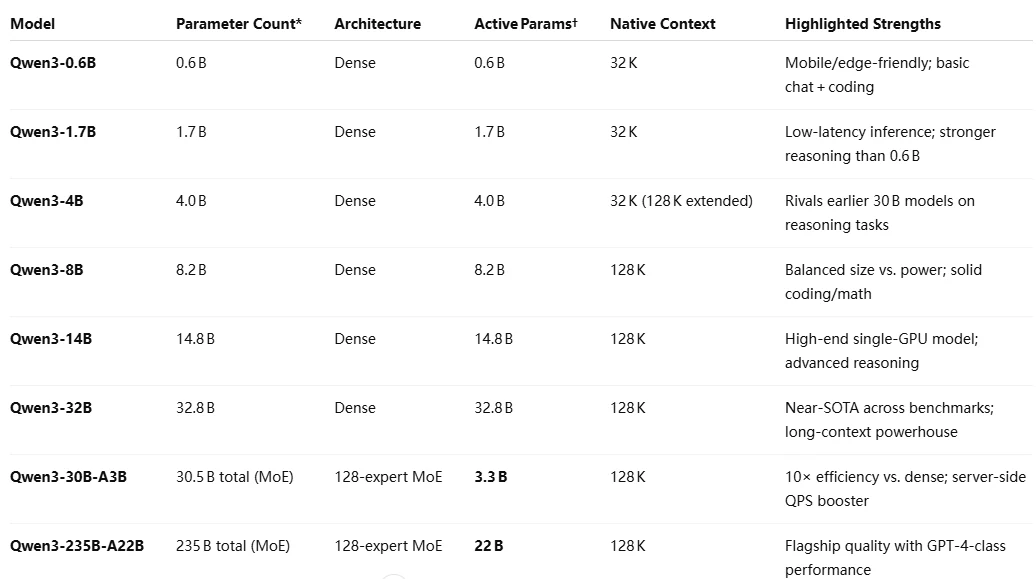
Qwen 3 は、Alibaba が 2025 年に公開したオープンソース大規模言語モデルファミリーで、切り替え可能な「思考」モードと「非思考」モードを備え、119 以上の言語での推論能力と多言語性能を強化しています。Qwen 3 モデルラインナップ は以下を含みます:
- Dense モデル:
- Mixture-of-Experts (MoE) モデル:
オープンソース&商用利用可能
Apache 2.0 ライセンスで、研究および商用利用のために重みが無料で公開されています。
効率的な Transformer コア
Grouped-Query-Attention を採用した Decoder-only アーキテクチャで、最大 128 K トークンの長期コンテキスト KV メモリを節約します。
デュアル「思考/非思考」モード
必要なときは詳細な思考連鎖を、速度が重要なときは素早い直接回答を提供します。
大規模 36 T トークンコーパス
119 言語、STEM とコードデータを拡充し、推論力とプログラミングスキルを強化。
3 段階事前学習
基礎スキル → STEM 強化 → 32 K トークン長期コンテキスト適応。
4 段階事後学習
長い CoT SFT → 推論 RL → モード融合 → 一般 RLHF アライメント。
多言語指示追従
英語と中国語で強力、100 以上の言語でロバストなグローバルアプリケーション対応。
ツール/エージェント対応
組み込みの関数呼び出しスキーマで外部ツール呼び出しの決定とフォーマットを実行。
テキスト入力/テキスト出力モダリティ
現在は言語タスクに最適化。将来のリリースでビジョンバリアントを計画中。
Qwen 3 シリーズアーキテクチャ
Qwen 3 シリーズベンチマーク
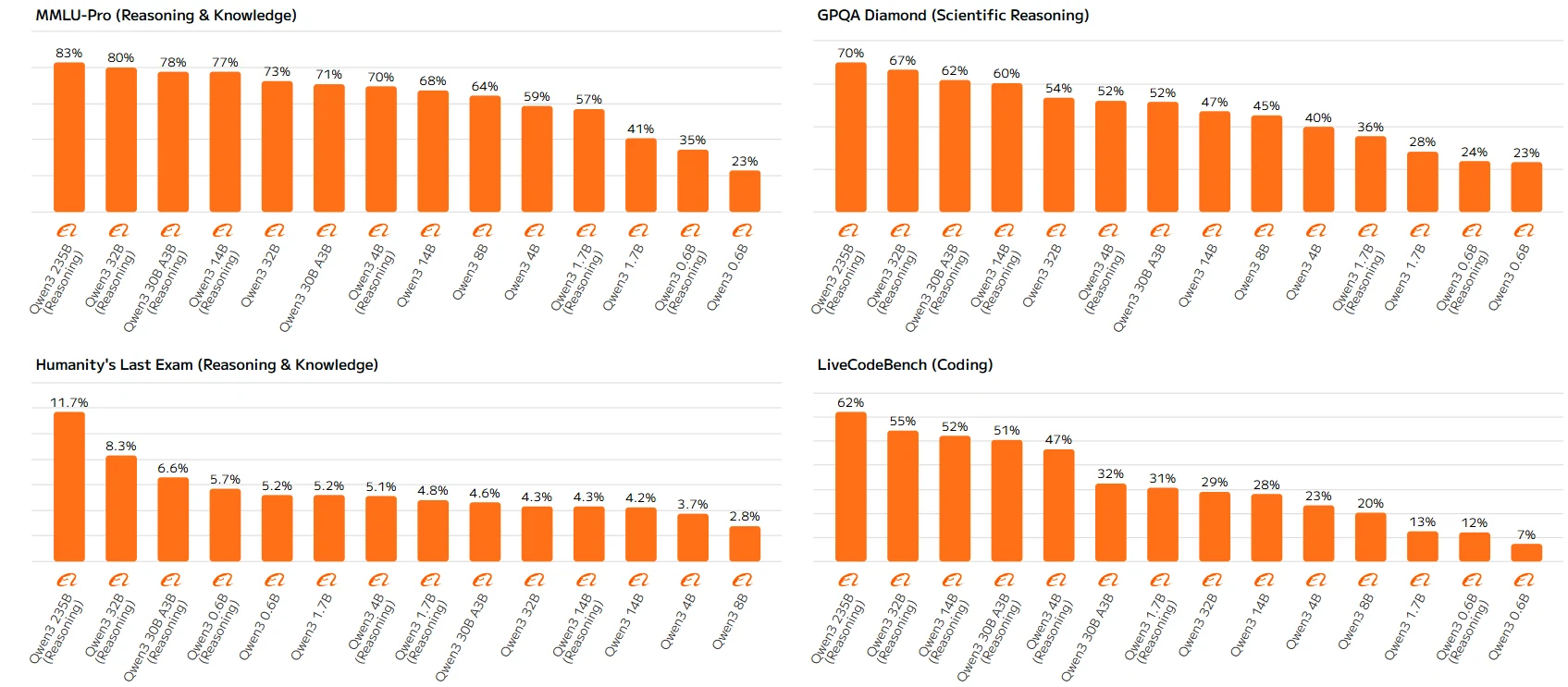
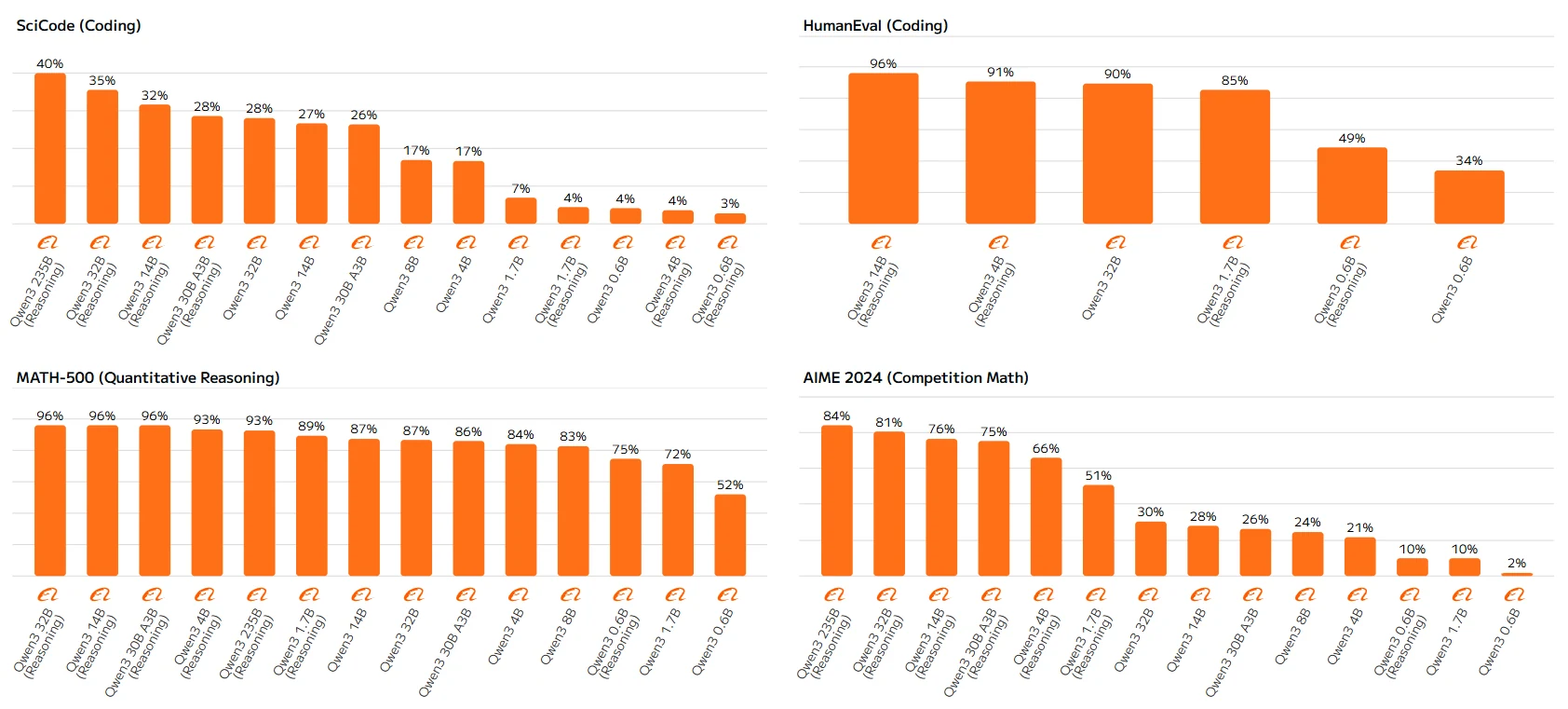
高パラメータモデル(Qwen-23B、Qwen-14B など)は一貫してルールに従い、より大きなモデルや推論機能を有効にしたバージョンほどスコアが高くなります。低パラメータモデルのこれらの不一致は、推論メカニズムを十分に活用する能力が不足していることに起因し、最適なパフォーマンスが得られない可能性があります。
Qwen 3 にローカルでアクセスする方法
ハードウェア要件
| **モデル ** | ** 推奨 GPU** | VRAM | vCPUs | RAM | ** ストレージ** |
|---|---|---|---|---|---|
| Qwen3-0.6B | RTX 3060 / T4 | 8 GB | 4 | 8 GB | 20 GB |
| Qwen3-1.7B | RTX 3060 / A5000 | 12–24 GB | 6–8 | 16 GB | 30 GB |
| Qwen3-4B | A100 40GB / RTX 3090 | 24–40 GB | 12+ | 24 GB | 40 GB |
| Qwen3-8B | A100 80GB / H100 | 40–80 GB | 16+ | 48 GB | 60 GB |
| Qwen3-14B | 2× A100 80GB / 1× H100 | 80 GB+ | 24+ | 64 GB | 80 GB |
| Qwen3-30B (MoE) | 2× H100 / 4× A100 | 160 GB | 48+ | 128 GB | 160 GB |
| Qwen3-32B | 2× H100 / 4× A100 | 160 GB | 64 | 160 GB | 200 GB |
| Qwen3-235B (MoE) | 8× H100 / 8× A100 | 640 GB | 128+ | 512 GB | 500+ GB |
インストール手順
# Step 1: Python をインストールし、仮想環境を作成する
# Python (>=3.8) がインストールされていることを確認し、仮想環境を作成して有効化します。
python3 -m venv llama_env
source llama_env/bin/activate # Windows の場合は `llama_env\Scripts\activate`
# Step 2: 必要なライブラリをインストールする
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # GPU 最適化用
pip install bitsandbytes # 効率的な GPU メモリ使用
# Step 3: Hugging Face CLI をインストールし、ログインする
pip install huggingface-cli
huggingface-cli login # プロンプトに従って認証
# Step 4: Llama-3.3 70B へのアクセスをリクエストする
# Hugging Face モデルページ (Llama-3.3 70B) にアクセスし、アクセスをリクエストします。
# URL: https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct
# Step 5: モデルファイルをダウンロードする
huggingface-cli download meta-llama/Llama-3.3-70B-Instruct --include "original/*" --local-dir Llama-3.3-70B-Instruct
# Step 6: モデルをローカルで読み込む
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデル ID とローカルディレクトリのパス
model_id = "meta-llama/Llama-3.3-70B-Instruct"
local_model_dir = "./Llama-3.3-70B-Instruct"
# GPU 最適化でモデルを読み込む
model = AutoModelForCausalLM.from_pretrained(
local_model_dir,
device_map="auto", # モデルレイヤーを自動的に GPU にマッピング
torch_dtype=torch.bfloat16 # メモリ効率のために bfloat16 を使用
)
# トークナイザーを読み込む
tokenizer = AutoTokenizer.from_pretrained(local_model_dir)
# Step 7: 推論を実行する
# 入力テキストを定義
input_text = "相対性理論を簡単な言葉で説明してください。"
# 入力をトークン化
inputs = tokenizer(input_text, return_tensors="pt").to("cuda") # 入力を GPU に送信
# 応答を生成
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=100, # 最大応答長を設定
temperature=0.7, # 創造性を調整 (低いほど控えめ、高いほど創造的)
top_k=50, # 多様性のための Top-k サンプリング
)
# 出力トークンをデコード
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
Qwen 3 に API 経由でアクセスする方法
Novita AI は、手頃な価格で信頼性が高くシンプルな推論プラットフォームを提供し、スケーラブルな Llama 3.3 70b API で開発者が AI アプリケーションを構築できるようにします。今すぐ Novita AI Llama 3.3 70b API デモ をお試しください!
オプション 1: 直接 API 統合 (Python 例)
主な機能:
- 統一エンドポイント:
/v3/openaiは OpenAI の Chat Completions API 形式をサポートします。 - 柔軟な制御: 温度、top-p、ペナルティなどを調整して、ニーズに合わせた結果を得られます。
- ストリーミングとバッチ処理: 好みの応答モードを選択できます。
オプション 2: OpenAI Agents SDK によるマルチエージェントワークフロー
Novita AI を OpenAI Agents SDK と統合して、高度なマルチエージェントシステムを構築します:
- プラグアンドプレイ: 任意の OpenAI Agents ワークフローで Novita AI の LLM を使用できます。
- ハンドオフ、ルーティング、ツール使用をサポート: 委任、トリアージ、関数実行が可能なエージェントを設計でき、すべて Novita AI のモデルを搭載。
- Python 統合: SDK を Novita のエンドポイント (
https://api.novita.ai/v3/openai) にポイントし、API キーを使用するだけです。
サードパーティプラットフォームで Qwen 3 API に接続する
- Hugging Face:Novita AI エンドポイント経由で、Spaces、パイプライン、または Transformers ライブラリで Qwen 3 を使用します。
- エージェント&オーケストレーションフレームワーク: 公式コネクタとステップバイステップの統合ガイドを通じて、Continue、AnythingLLM、LangChain、Dify、Langflow などのパートナープラットフォームに Novita AI を簡単に接続できます。
- OpenAI 互換 API: Cline や Cursor など、OpenAI API 標準向けに設計されたツールとシームレスに移行・統合できます。
どの方法があなたに適していますか?
ローカル vs API アクセスの比較
| 項目 | ローカルアクセス | API アクセス |
| スケーラビリティ | 制限あり、手動アップグレードが必要 | 自動的かつ効率的にスケール |
| 柔軟性 | 高い柔軟性、設定を完全に制御可能 | 柔軟性は低く、プロバイダの構成に依存 |
| 使いやすさ | 技術的専門知識が必要 | 使いやすく、複雑な設定不要 |
| コスト | 初期費用は高いが、ランニングコストは低い。長期利用に最適 | 従量課金制。小規模または不定期利用に最適 |
ユーザーグループ別の推奨事項
- 研究者 ** → ** ローカルアクセス を推奨。実験の柔軟性と完全な制御が可能。
- 開発者 ** → 迅速なテストとアプリ構築には API、カスタムトレーニングには ** ローカル を使用。
- 企業 ** → 簡単な統合には API、安定したニーズがあるチームには ** ローカル が適切。
- **小規模チーム・個人 ** → 予算に優しく、始めやすい API がおすすめ。
- 非技術ユーザー → 間違いなく API を選択。複雑な設定は不要。
研究者、開発者、ビジネスチームを問わず、Qwen 3 はあなたのニーズに適応します。ローカルアクセスは制御とカスタマイズを提供し、API は即時のスケーラビリティと低い参入障壁を提供します。Qwen 3 の設計により、現実世界のタスクに対して強力な多言語、推論、ツール拡張機能が保証されます。
よくある質問
Qwen 3 は他の LLM と何が違うのですか?
デュアル思考モード、強力な多言語指示追従、長いコンテキスト(128k トークン)をサポートし、オープンウェイトで商用利用に適したライセンスを備えています。
Qwen 3 を自分の PC で実行できますか?
最小のモデル(例:0.6B)のみがコンシューマ GPU で動作可能です。より大きなモデルには A100/H100 のセットアップが必要です。
API アクセスの方が簡単ですか?
はい。Novita AI と Hugging Face は低コストでプラグアンドプレイの Qwen 3 API を提供しており、迅速な統合と低レイテンシの使用に最適です。
Novita AI は、AI の野心を実現するオールインワンのクラウドプラットフォームです。統合 API、サーバーレス、GPU インスタンス — 必要なコスト効率の高いツール。インフラストラクチャを排除し、無料で始めて、AI のビジョンを現実にしましょう。



