

邀请好友加入 Novita AI,你们双方都将获得 $10 的 LLM API 积分——最高可获得 $500 的总奖励。
为支持开发者社区,Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B 目前在 Novita AI 上免费提供。

Qwen 3 是阿里巴巴推出的一款多功能且强大的开源语言模型系列。凭借先进的架构和双模式推理能力,它既适用于边缘设备,也能满足大规模企业需求。本文将探讨其能力、模型类型以及如何使用——无论是在本地还是通过 API。
什么是 Qwen 3?
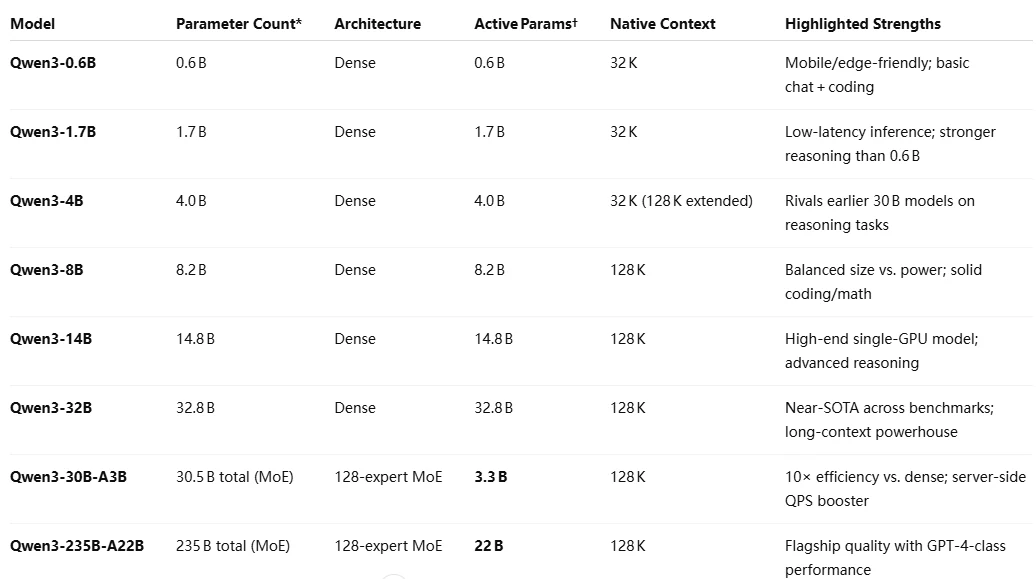
Qwen 3 是阿里巴巴 2025 年推出的开源大型语言模型系列,具有可切换的“思考”和“非思考”模式,在 119 种以上语言中提升了推理和多语言性能。Qwen 3 模型阵容 包括:
- 密集模型:
- 混合专家(MoE)模型:
开源且商用友好
采用 Apache 2.0 许可证,权重可免费用于研究和商业用途。 ### 高效 Transformer 核心
纯解码器架构,配备分组查询注意力机制,实现长上下文 KV 内存节省,最高支持 128K token。 ### 双“思考/非思考”模式
需要时提供详细的思维链,速度优先时则给出简洁的直接答案。 ### 36 T token 超大规模语料库
119 种语言,包含扩展的 STEM 与代码数据,提升推理与编程能力。 ### 三阶段预训练
基础技能 → STEM 增强 → 32 K token 长上下文适配。 ### 四阶段后训练
长 CoT SFT → 推理 RL → 模式融合 → 通用 RLHF 对齐。 ### 多语言指令遵循
在英语和中文方面表现强劲,在 100 多种语言中也能稳健运行,适用于全球应用。 ### 工具/智能体就绪
内置函数调用模式,用于判断和格式化外部工具调用。 ### 文本输入/文本输出模态
当前针对语言任务进行了优化;未来版本计划推出视觉变体。
Qwen 3 系列架构
Qwen 3 系列基准测试
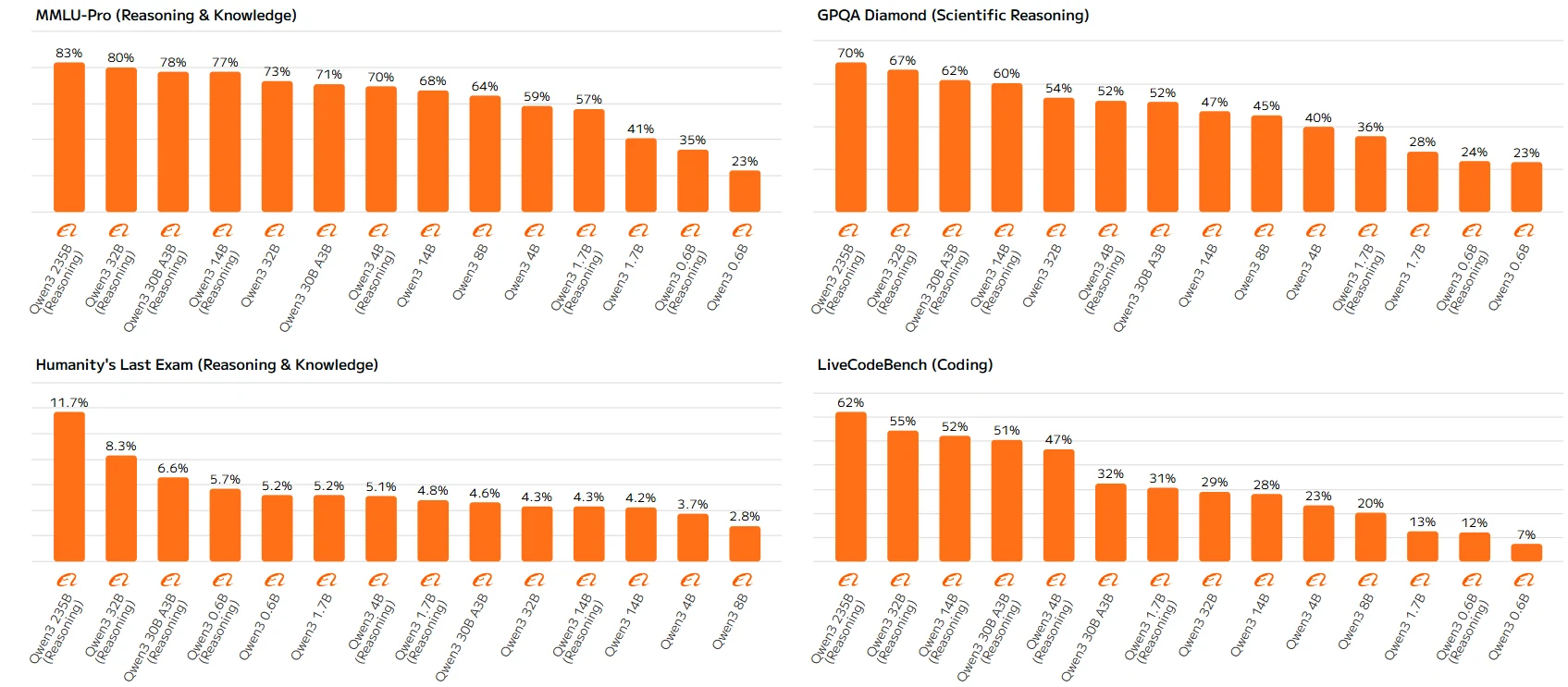
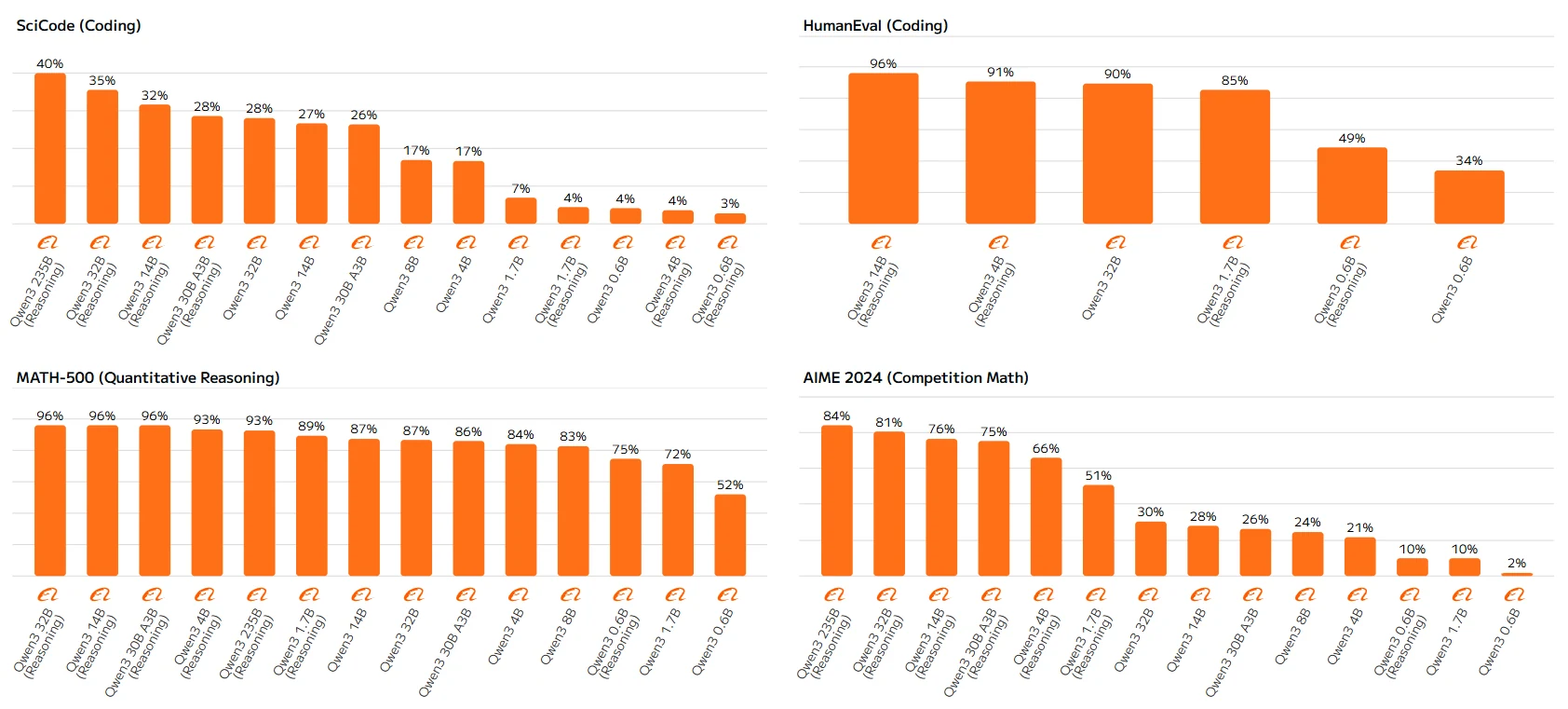
高参数模型(如 Qwen-23B 和 Qwen-14B)始终遵循规则,模型越大、启用推理的版本得分越高。低参数模型中的这些差异可能源于其推理能力的局限性,因为它们缺乏充分利用推理机制的容量,导致性能欠佳。
如何本地访问 Qwen 3?
硬件要求
| **模型 ** | ** 推荐 GPU** | ** 显存 ** | vCPUs | ** 内存 ** | ** 存储** |
|---|---|---|---|---|---|
| Qwen3-0.6B | RTX 3060 / T4 | 8 GB | 4 | 8 GB | 20 GB |
| Qwen3-1.7B | RTX 3060 / A5000 | 12–24 GB | 6–8 | 16 GB | 30 GB |
| Qwen3-4B | A100 40GB / RTX 3090 | 24–40 GB | 12+ | 24 GB | 40 GB |
| Qwen3-8B | A100 80GB / H100 | 40–80 GB | 16+ | 48 GB | 60 GB |
| Qwen3-14B | 2× A100 80GB / 1× H100 | 80 GB+ | 24+ | 64 GB | 80 GB |
| Qwen3-30B (MoE) | 2× H100 / 4× A100 | 160 GB | 48+ | 128 GB | 160 GB |
| Qwen3-32B | 2× H100 / 4× A100 | 160 GB | 64 | 160 GB | 200 GB |
| Qwen3-235B (MoE) | 8× H100 / 8× A100 | 640 GB | 128+ | 512 GB | 500+ GB |
分步安装指南
# 第1步:安装 Python 并创建虚拟环境
# 确保已安装 Python (>=3.8)。然后创建并激活虚拟环境。
python3 -m venv llama_env
source llama_env/bin/activate # 在 Windows 上,使用 `llama_env\Scripts\activate`
# 第2步:安装所需库
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # GPU 优化
pip install bitsandbytes # 高效的 GPU 内存使用
# 第3步:安装 Hugging Face CLI 并登录
pip install huggingface-cli
huggingface-cli login # 按照提示进行身份验证
# 第4步:请求访问 Llama-3.3 70B
# 访问 Llama-3.3 70B 的 Hugging Face 模型页面并请求访问。
# 网址:https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct
# 第5步:下载模型文件
huggingface-cli download meta-llama/Llama-3.3-70B-Instruct --include "original/*" --local-dir Llama-3.3-70B-Instruct
# 第6步:本地加载模型
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 模型 ID 和本地目录路径
model_id = "meta-llama/Llama-3.3-70B-Instruct"
local_model_dir = "./Llama-3.3-70B-Instruct"
# 使用 GPU 优化加载模型
model = AutoModelForCausalLM.from_pretrained(
local_model_dir,
device_map="auto", # 自动将模型层映射到 GPU(s)
torch_dtype=torch.bfloat16 # 使用 bfloat16 实现高效内存使用
)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(local_model_dir)
# 第7步:运行推理
# 定义输入文本
input_text = "用简单的话解释一下相对论。"
# 对输入进行分词
inputs = tokenizer(input_text, return_tensors="pt").to("cuda") # 将输入发送到 GPU
# 生成回复
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=100, # 设置最大回复长度
temperature=0.7, # 调整创造性(值越低越不具创造性,越高越具创造性)
top_k=50, # Top-k 采样以增加多样性
)
# 解码输出 token
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("回复:", response)
如何通过 API 访问 Qwen 3
Novita AI 提供价格实惠、可靠且简单的推理平台,具有可扩展的 Llama 3.3 70b API,助力开发者构建 AI 应用。立即试用 Novita AI Llama 3.3 70b API Demo!
选项1:直接 API 集成(Python 示例)
关键特性:
- 统一端点:
/v3/openai支持 OpenAI 的聊天补全 API 格式。 - 灵活控制: 调整 temperature、top-p、惩罚等参数,以获得定制化结果。
- 流式与批量: 选择你偏好的响应模式。
选项2:使用 OpenAI Agents SDK 构建多智能体工作流
通过将 Novita AI 与 OpenAI Agents SDK 集成,构建复杂的多智能体系统:
- 即插即用: 在任何 OpenAI Agents 工作流中使用 Novita AI 的 LLM。
- 支持交接、路由和工具使用: 设计能够委派、分类或运行函数的智能体,全部由 Novita AI 的模型驱动。
- Python 集成: 只需将 SDK 指向 Novita 的端点 (
https://api.novita.ai/v3/openai) 并使用你的 API 密钥即可。
在第三方平台上连接 Qwen 3 API
- Hugging Face:通过 Novita AI 端点在 Spaces、pipeline 或 Transformers 库中使用 Qwen 3。
- 智能体与编排框架: 通过官方连接器和分步集成指南,轻松将 Novita AI 与合作伙伴平台(如 Continue、AnythingLLM、LangChain、Dify 和 Langflow)连接起来。
- OpenAI 兼容 API: 享受与为 OpenAI API 标准设计的工具(如 Cline 和 Cursor)的无缝迁移和集成。
哪些方法适合你?
本地访问与 API 访问对比
| 方面 | 本地访问 | API 访问 |
|---|---|---|
| 可扩展性 | 有限;需要手动升级。 | 自动高效扩展。 |
| 灵活性 | 高度灵活;完全控制设置。 | 灵活性较低;依赖于提供商配置。 |
| 易用性 | 需要技术专业知识。 | 更易使用,无需复杂设置。 |
| 成本效益 | 初始成本高,持续成本低。最适合长期使用。 | 按使用付费,适合小规模或偶尔使用。 |
不同用户群体的建议
- 研究人员 ** → 更偏好 ** 本地访问,以获得完全控制和实验灵活性。
- 开发者 ** → 使用 API 进行快速测试和构建应用;如果需要自定义训练,则选择 ** 本地。
- 企业 ** → API 适合轻松集成; 本地**适合需求稳定的团队。
- **小团队与个人 ** → API 更经济实惠,上手更容易。
- **非技术用户 ** → 肯定选择 API——无需复杂设置。
无论你是研究人员、开发者还是企业团队,Qwen 3 都能根据你的需求进行调整。本地访问提供控制与定制,而 API 则提供即时可扩展性和低门槛入口。Qwen 3 的设计确保了强大的多语言、推理和工具增强能力,适用于实际任务。
常见问题
Qwen 3 与其他 LLM 有何不同?
它支持双思维模式、强大的多语言指令和长上下文(128k token),并具有开源权重和商用友好许可。
我可以在自己的 PC 上运行 Qwen 3 吗?
只有最小的模型(例如 0.6B)适合消费级 GPU。更大的模型需要 A100/H100 配置。
API 访问更容易吗?
是的!Novita AI 和 Hugging Face 提供低成本、即插即用的 Qwen 3 API——非常适合快速集成和低延迟使用。
Novita AI 是一个全能云平台,助力你的 AI 梦想。集成 API、无服务器、GPU 实例——你所需的高性价比工具。消除基础设施负担,免费开始,让 AI 愿景成真。



