

Novita AI 上的 Seedance 1.5 Pro 将以规模化方式,将字节跳动先进的视听 AI 能力带给开发者。 这款拥有 45 亿参数的模型,支持 8 种语言的音素级唇音同步精度、原生电影级控制以及同步空间音频——这些能力以往需要昂贵的后期制作团队才能实现。
对于构建对话驱动型视频应用的开发者而言,Novita AI 的无服务器部署提供了可配置的分辨率(480p/720p)和宽高比。下面我们将详细分析这对生产工作流的意义。
Seedance 1.5 Pro 的与众不同之处
原生联合视听生成
与先视频后音频的串行流水线不同,Seedance 1.5 Pro 采用双分支扩散 Transformer,可同时生成同步的视频帧和音频波形。其跨模态联合模块能在视觉与声音之间保持毫秒级的对齐,解决了早期模型常见的唇音不同步问题。
此架构带来了三个关键优势:音素级精准唇部动作 (将每个语音映射到正确的口型)、 空间音频定位 (脚步声根据房间声学效果正确回响)以及 情感连贯性(音乐强度与视觉节奏相匹配)。对于以对话为主的应用,这消除了手动清理音频的需求。
https://www.youtube.com/watch?v=yaB3LJElhZA
多语言方言支持
该模型支持 8 种语言,包括中国地区方言——四川话、台湾国语、粤语、上海话——以及英语、日语、韩语、西班牙语、葡萄牙语、印尼语和印地语。每种方言在保持唇音同步精度的同时,保留了地道的发音模式,这对于本地化内容活动至关重要。
电影级控制指令
开发者可以使用自然语言指定镜头运动:“在角色情感高潮处推拉变焦”、“跟随追车场景的跟拍镜头”、“说话者之间快速转场扫镜”。模型会将这些指令转换为具有正确物理效果的平滑镜头运动——无需手动设置关键帧。
Seedance 1.5 Pro 的技术规格
| 规格 | 详情 | 对开发者的影响 |
|---|---|---|
| 模型架构 | 45 亿参数双分支扩散 Transformer | 推理所需 VRAM 较低(约 16GB),生成速度快 |
| 原生分辨率 | 720p(可选 480p) | 4K 工作流需要外部超分 |
| 时长范围 | 每个片段 4-12 秒 | 最佳用于短内容,不适合长叙事 |
| 音频特性 | 空间定位、环境音效、情绪同步音乐 | 显著减少后期音频工作 |
视觉质量评估
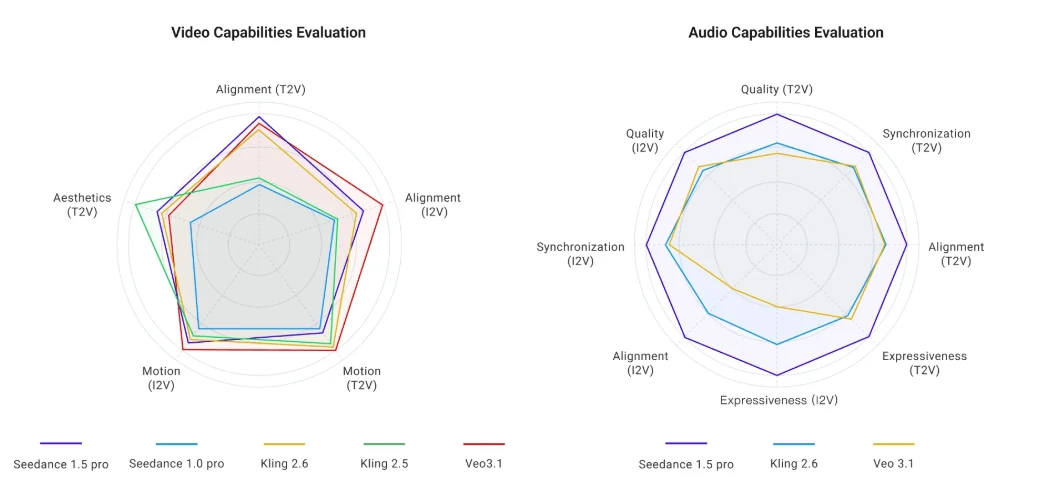
来源:字节跳动
独立评测者将 Seedance 1.5 Pro 的评分定为 7-8/10(与真人实拍相比),指出其相比 Kling 1.6 或 Runway Gen-3 在皮肤纹理和减少条带方面有所改进。然而,原生 720p 输出限制了精细细节——文字叠加层边缘可能偏软,不同镜头间存在轻微的曝光不一致。
该模型在处理复杂物理效果方面表现良好:雪粒子、高速运动模糊、水模拟渲染效果逼真。头发和树叶中偶尔会出现过度锐化的伪影,可通过添加“自然光照”提示词解决。
在 Novita AI 上使用 Seedance 1.5 Pro
API 集成设置
Novita AI 通过两个 REST 端点提供 Seedance 1.5 Pro(他们对 1.5 Pro 的命名):文本转视频 (T2V) 和图像转视频 (I2V)。两者均遵循与 OpenAI 兼容的请求/响应模式,并采用异步任务轮询。 关于何时使用 T2V 与 I2V、带音频与静默模式、在线与灵活批量处理的详细说明,请参阅 Seedance V1.5 Pro API:文本转视频 vs 图像转视频、音频与静默模式。
文本转视频示例
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-t2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"ratio": "16:9",
"prompt": "A colossal sci-fi mecha stands in the rain-soaked city nightscape, neon lights reflecting off its metallic armor. Slow motion captures every raindrop bouncing off the mecha's shoulder as it raises its arm cannon. Cinematic depth of field blurs the glowing skyscrapers behind. Anime style, dramatic lighting, 4K quality.",
"duration": 8,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'
图像转视频实现可控输出
I2V 模式接受起始和结束关键帧,有助于保持角色设计的一致性:
curl --location --request POST 'https://api.novita.ai/v3/async/seedance-v1.5-pro-i2v' \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${API_KEY}" \
--data-raw '{
"fps": 24,
"seed": 42,
"image": "https://pub-32c83cde150f4d468bd19f0a5e372c23.r2.dev/multimodal-assets/2026-02/1771500580027-43159b2510134742.jpg",
"ratio": "adaptive",
"prompt": "A young woman dances energetically on a city street with graffiti walls and neon lights. The camera follows her fluid movements as she spins and grooves to the rhythm. Shot scale changes from medium to close-up, capturing her confident natural expression. Detail enhancement on her facial features and clothing textures. Smooth stabilization throughout the dance sequence with consistent neon lighting reflections.",
"duration": 4,
"watermark": false,
"resolution": "720p",
"camera_fixed": false,
"service_tier": "default",
"generate_audio": true,
"execution_expires_after": 172800
}'
Novita AI 上 Seedance 1.5 Pro 的成本
Novita AI 按生成任务收费,而非按 token。
Seedance 1.5 Pro · 文本转视频 (T2V)
| 分辨率 | 音频 | 在线 ($/秒) | 批量 ($/秒) |
|---|---|---|---|
| 480P | 静默 | $0.012 | $0.006 |
| 480P | 带音频 | $0.024 | $0.012 |
| 720P | 静默 | $0.026 | $0.013 |
| 720P | 带音频 | $0.052 | $0.026 |
Seedance 1.5 Pro · 图像转视频 (I2V)
| 分辨率 | 音频 | 在线 ($/秒) | 批量 ($/秒) |
|---|---|---|---|
| 480P | 静默 | $0.012 | $0.006 |
| 480P | 带音频 | $0.024 | $0.012 |
| 720P | 静默 | $0.026 | $0.013 |
| 720P | 带音频 | $0.052 | $0.026 |
成本节省技巧:
- 原型阶段先从 480p 开始(生成速度最快),然后在最终版本以 720p 重新生成。
- 在可接受静态镜头的情况下,使用固定相机(
camera_fixed: true)可减少约 30% 的处理时间。- 在线任务实时处理并立即返回结果,而批量任务则以异步方式执行,适用于大规模生成,成本更低。
Seedance 1.5 Pro 的提示词工程最佳实践
为获得最佳结果的结构化提示
Seedance 1.5 Pro 在 明确、分层的提示词 下表现最佳,提示词应分离视觉动作、音频提示和相机指令:
[角色动作] + [带语言的对话] + [音频环境] + [相机运动] + [光照/风格]
示例:
"Elderly woman laughs heartily while kneading dough in rustic kitchen.
Says 'This is my grandmother's recipe!' in Sichuanese dialect with warm smile.
Background sounds: bubbling pot, wooden spoon clinking, soft folk music.
Slow dolly zoom focusing on hands, then face.
Warm afternoon sunlight through window, shallow depth of field."
方言和情感关键词
对于多语言项目,明确指定方言 以触发正确的音素模型:
- 中文方言: “使用粤语方言”、“使用台湾国语”、“带有上海口音”
- 情感强度: “愤怒地喊叫”、“紧张地低语”、“自信地说”
- 非言语音频: “在大理石上回响的脚步声”、“画外玻璃破碎声”、“远处的交通噪音”
应避免的内容
评测者指出,该模型在处理非常复杂的动作序列时存在困难——建议控制在 1-2 个角色,并限制同时发生的动作。应避免类似提示:
- “五个角色进行小组讨论”(模型能很好处理最多 2-3 个说话者)
- “角色奔跑、跳跃、然后打斗”(10 秒内包含过多连续动作)
- “带有爆炸的史诗战斗场景”(未针对动作场景优化,更适合对话/剧情类)
Seedance 1.5 Pro 的常见问题及解决方案
问题:镜头切换时曝光变化
原因: 原生 720p 生成有时会在场景转换时产生亮度不一致。
解决方案: 在提示词中添加“整个场景光照保持一致”,或使用 Lumetri Color/色轮在后期进行曝光校正。
问题:文字叠加边缘模糊
原因: 720p 原生分辨率无法保留锐利的文字边缘。
解决方案: 生成不带屏幕文字的视频,然后在后期使用 After Effects 或 Motion 以更高分辨率添加标题/图形。
问题:多说话者场景中的音频漂移
原因: 复杂的重叠对话有时会出现 100-200 毫秒的不同步。
解决方案: 每个片段最多限制 2 个说话者。对于群组对话,分别生成正拍/反拍镜头,然后剪辑在一起。
问题:相机定制有限
原因: 模型解释相机指令,但不接受精确的焦距/f 值参数。
解决方案: 使用描述性术语,如“浅景深”或“广角视角”,而不是技术规格。
Novita AI 上的 Seedance 1.5 Pro 为以对话为主的短内容提供了生产级的视听生成能力。 其音素级唇音同步精度和与 OpenAI 兼容的 REST API,为构建本地化广告、微短剧和音乐视频原型的开发者提供了一条从脚本到渲染视频的快速路径。
常见问题
Seedance 1.5 Pro 如何处理提示词中受版权保护的音乐?
该模型会生成与情感描述(“欢快的爵士乐”、“忧郁的钢琴曲”)相匹配的原创音乐。它不会再现受版权保护的歌曲——尝试提示现有曲目将产生泛化的演绎。
我可以将音频和视频轨道分开导出用于专业母带处理吗?
可以。输出的 MP4 文件包含标准音频轨道,可通过 FFmpeg 提取:ffmpeg -i output.mp4 -vn -acodec pcm_s16le audio.wav 用于无损音频导出。
Seedance 1.5 Pro 是否支持实时生成以用于直播应用?
不支持。每个片段的生成大约需要 30-60 秒。对于延迟敏感的工作流,可使用带有 webhook 回调的批量端点异步接收结果,或预先生成一个视频片段库并按需提供,而非实时生成。
Novita AI 是一个 AI 与智能体云平台,帮助开发者和初创公司以高性能、高可靠性和高成本效益构建、部署和扩展模型及智能体应用。



