

在多项基准测试中,Qwen3-Next-80B-A3B Instruct 的表现几乎与 Qwen3-235B-A22B Instruct 持平,尽管前者的参数量要少得多。这种出人意料的性能平衡自然引出一个问题:小模型如何能与大模型抗衡?答案在于两者的架构创新——本文将为你详细解读其中的原因。
Qwen3-Next-80B 与 Qwen3-235B 对比:架构核心差异
在多项关键基准测试中,Qwen3-Next-80B-A3B Instruct 的表现与 Qwen3-235B-A22B Instruct 持平,在 AIME25、LiveBench 和 LiveCodeBench 上的得分几乎完全一致。这种性能表现自然让两者的架构差异成为关注焦点
来自 Hugging Face
| 模型 | 总参数量 | 激活参数量 | 层数 | 专家数量 | 激活专家数 | 注意力类型 | 上下文长度 | 模式 | 核心定位 |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-Next-80B-A3B-Instruct | 80B | 3B | 48 | 64 | 2 | 混合(DeltaNet + 门控) | 标准(最高 256K) | Instruct | 轻量推理、日常问答 |
| Qwen3-Next-80B-A3B-Thinking | 80B | 3B | 48 | 64 | 2 | 混合(DeltaNet + 门控) | 标准(最高 256K) | Thinking | 强推理能力、多步骤问题求解 |
| Qwen3-235B-A22B-Instruct-2507 | 235B | 22B | 94 | 128 | 8 | 混合(DeltaNet + 门控) | 原生 262K,最高可扩至 1M | Instruct | 大规模容量、更强的长上下文处理能力 |
| Qwen3-235B-A22B-Thinking-2507 | 235B | 22B | 94 | 128 | 8 | 混合(DeltaNet + 门控) | 原生 262K,最高可扩至 1M | Thinking | 超大参数量、强化推理能力 |
Qwen3-Next-80B-A3B 与 Qwen3-235B 对比:小模型为何能站稳脚跟
Qwen3-Next-80B-A3B 是 Qwen3-Next 系列的首款模型,凭借最大化长上下文效率和吞吐量的架构创新脱颖而出。
它引入了混合注意力机制,结合门控 DeltaNet 和门控注意力替代标准注意力,可在超长序列长度下实现高效的上下文建模。
**高稀疏度混合专家(MoE)**设计大幅降低了激活比例,在保留模型容量的同时减少了每 token 的计算量(FLOPs)。
为保障模型鲁棒性,该模型集成了稳定性优化,包括零中心化、权重衰减层归一化等技术。
最后,**多 Token 预测(MTP)**提升了预训练效率并加速推理。这些增强特性共同使 Qwen3-Next-80B-A3B 能够以高效、稳定的方式处理大规模长上下文工作负载。
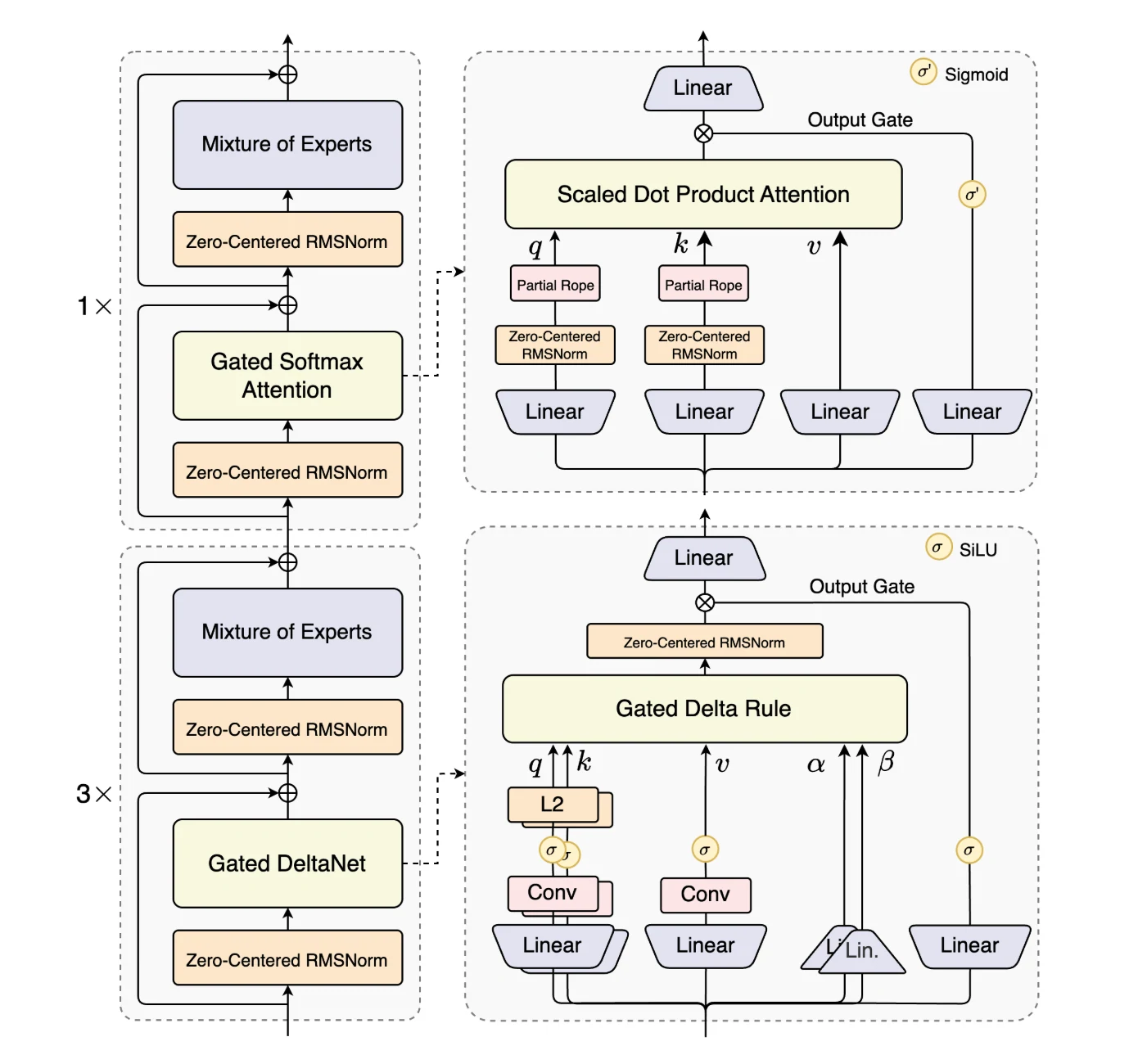
来自 Hugging Face
处理和承载更长上下文的能力直接强化了模型的几项核心能力:
- 长文档理解
可一次性处理整本书、研究论文或长转录文本,避免分块处理导致的信息丢失。 - 跨段落推理
更长的上下文窗口支持关联文本中相距较远的部分,提升逻辑连贯性。 - 复杂任务处理
法律分析、科学研究或多轮对话等应用场景,可通过保留大量 token 中的细节来实现准确推理。 - 降低幻觉/内容漂移
保留完整输入可降低遗忘早期约束、编造缺失细节的风险。 - 实际应用可扩展性
企业级场景——包含长历史记录的聊天机器人、支持数千上下文 token 的检索增强生成(RAG)、多模态流水线等,都能从稳定的超长序列处理能力中直接受益。
Qwen3-Next-80B 与 Qwen3-Next-80B-A3B 对比:性能表现
| 类别 | 基准测试 | 80B-A3B-Instruct | 80B-A3B-Thinking | 235B-A22B-Thinking | 最优模型 |
|---|---|---|---|---|---|
| 知识 | MMLU-Pro | 80.6 | 82.7 | 84.4 | 235B-Thinking |
| MMLU-Redux | 90.9 | 92.5 | 93.8 | 235B-Thinking | |
| GPQA | 72.9 | 77.2 | 81.1 | 235B-Thinking | |
| SuperGPQA | 58.8 | 60.8 | 64.9 | 235B-Thinking | |
| 推理 | AIME25 | 69.5 | 87.8 | 92.3 | 235B-Thinking |
| HMMT25 | 54.1 | 73.9 | 83.9 | 235B-Thinking | |
| LiveBench(2024年11月) | 75.8 | 76.6 | 78.4 | 235B-Thinking | |
| 代码 | LiveCodeBench v6 | 56.6 | 68.7 | 74.1 | 235B-Thinking |
| MultiPL-E / CFEval* | 87.8 | 2071(CFEval) | 2134(CFEval) | 235B-Thinking | |
| OJBench / Aider-Polyglot* | 49.8(Aider) | 29.7(OJBench) | 32.5(OJBench) | 235B-Thinking | |
| 对齐 | IFEval | 87.6 | 88.9 | 88.9(并列) | 80B-Thinking / 235B-Thinking |
| Arena-Hard v2 | 82.7 | 62.3 | 79.7 | 80B-Instruct | |
| WritingBench | 87.3 | 84.6 | 88.3 | 235B-Thinking | |
| 智能体 | BFCL-v3 | 70.3 | 72.0 | 72.4 | 235B-Thinking |
| TAU1-Retail | 60.9 | 69.6 | 67.8 | 80B-Thinking | |
| TAU1-Airline | 44.0 | 49.0 | 46.0 | 80B-Instruct | |
| TAU2-Retail | 57.3 | 67.8 | 71.9 | 235B-Thinking | |
| TAU2-Airline | 45.5 | 60.5 | 58.0 | 80B-Thinking | |
| TAU2-Telecom | 13.2 | 43.9 | 45.6 | 235B-Thinking | |
| 多语言 | MultiIF | 75.8 | 77.8 | 80.6 | 235B-Thinking |
| MMLU-ProX | 76.7 | 78.7 | 81.0 | 235B-Thinking | |
| INCLUDE | 78.9 | 78.9 | 81.0 | 235B-Thinking | |
| PolyMATH | 45.9 | 56.3 | 60.1 | 235B-Thinking |
235B 系列模型——Qwen3-235B-A22B-Instruct-2507 和 Qwen3-235B-A22B-Thinking-2507——拥有最高的绝对性能,在专业知识、代码生成和高级推理任务上表现尤为突出。
80B 系列模型的表现远超其参数量水平:
- Qwen3-Next-80B-A3B-Thinking 的推理能力接近 Qwen3-235B-A22B-Thinking-2507,是追求效率和成本场景下的理想选择。
- Qwen3-Next-80B-A3B-Instruct 在知识和代码任务上与 Qwen3-235B-A22B-Instruct-2507 表现接近,甚至在 Arena-Hard v2 等对齐基准测试中超越了后者。
核心结论: Qwen3-Next-80B-A3B 在保证效率的同时并未牺牲太多性能。其架构创新——混合注意力、稀疏 MoE 和稳定性优化——让这款小模型在众多实际任务中能够与 235B 同级别大模型比肩。
Qwen3-Next-80B 与 Qwen3-235B 对比:推理速度对比
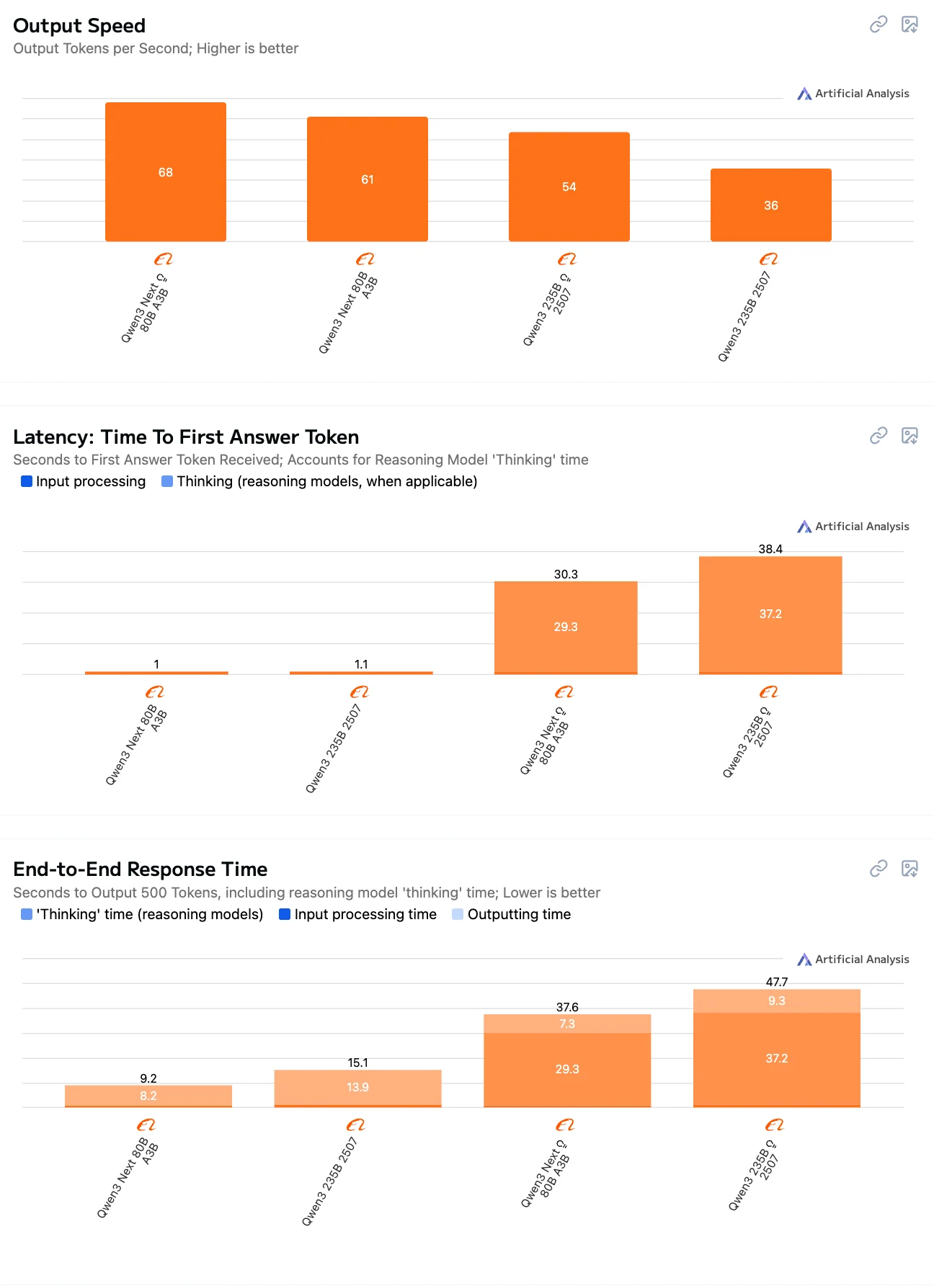
80B-Instruct 是速度与低延迟的最佳平衡。
由于规模更大、推理逻辑更复杂,235B 系列模型速度更慢,在 Thinking 模式下尤为明显。
由于需要执行显式推理步骤,**Thinking 模式模型(包括 80B 和 235B)**的延迟和端到端耗时远高于 Instruct 模式。
Qwen3-Next-80B 与 Qwen3-235B 对比:哪款更适合文本生成
小说/虚构文学创作
- 需求:丰富的人物细节、长篇剧情线、沉浸式文风、内容连贯性。
- 235B:创意细节更丰富,文风更统一,隐喻和复杂情节处理能力更强。
- 80B:长上下文窗口可低成本支撑长篇剧情线,迭代速度更快,连贯性足以满足多数读者需求。
科学论文/技术写作
- 需求:准确性、结构化、引用规范、专业术语、逻辑流畅。
- 235B:领域知识更深入,细节准确率更高,推理能力更强。
- 80B:通常足以满足文献综述、常规实验的写作需求,但在细分领域出现小错误的概率更高。
对话/聊天类故事创作
- 需求:多轮对话连贯性、记忆保持、人设遵循、响应速度。
- 235B:在记忆细节、遵循严格人设指令方面略胜一筹。
- 80B:响应速度更快、延迟更低,长上下文处理能力使其在互动聊天场景中表现优异。
非虚构创作/散文/博客
- 需求:事实与文风平衡、结构清晰、有说服力。
- 235B:更擅长处理事实密集、逻辑复杂的论证。
- 80B:当文风和可读性比专业精确性更重要时,其表现完全足够,且草稿修改速度更快。
诗歌/风格化写作
- 需求:富有想象力的语言、韵律、细腻的意蕴。
- 235B:在生僻词汇使用、创意表达、细腻情感传递方面更强。
- 80B:可很好地模仿文风,但在生僻隐喻的深度上有时稍显不足。
总结
- 若追求顶级的精确度和深度(如科学写作、关键性技术文档、高端创意项目),235B 是更优选择。
- 若追求效率、速度和低成本,同时要求稳定的输出质量——尤其是处理故事、聊天历史等长输入场景——80B 通常是更明智的选择。
Qwen3-Next-80B 与 Qwen3-235B 对比:哪款更适合聊天机器人应用
聊天机器人核心需求
响应速度快、长历史对话连贯、指令遵循能力强、具备基础推理能力、成本可控。
235B
- 在超大规模对话、专业知识问答、复杂推理任务上表现优异。
- 缺点:延迟更高、计算成本更高,若对响应速度要求高则不太适合。
80B
- 延迟更低,响应速度更快。
- 得益于架构创新,仍能保持良好的指令遵循和上下文处理能力。
- 是面向用户的交互式聊天机器人的优质选择。
核心结论
- 若追求流畅的用户体验和快速响应,80B 通常是更优选择。
- 若面向专业领域或高要求场景,235B 可能仍是更合适的选择。
如何访问 Qwen3-Next-80B 和 Qwen3-235B?
1. 网页端(最适合新手)
立即试用 Qwen3-Next-80B-A3B Instruct!
2. API 接入(适合开发者)
Novita AI 是一款 AI 云平台,为开发者提供简单的 API,方便快速部署 AI 模型。
Qwen3-Next-80B-A3B Instruct 定价为输入 $0.15/百万 token、输出 $1.5/百万 token,支持 65536 token 上下文。
Qwen3-Next-80B-A3B Thinking 定价同样为输入 $0.15/百万 token、输出 $1.5/百万 token,支持 65536 token 上下文。
Qwen3-235B-A22B Thinking-2507 价格更高,为输入 $0.3/百万 token、输出 $3/百万 token,支持 131072 token 上下文。
Qwen3-235B-A22B Instruct-2507 定价为输入 $0.15/百万 token、输出 $0.8/百万 token,支持 131072 token 上下文。
步骤1:登录并进入模型库
登录你的账号,点击模型库按钮。

步骤2:选择所需模型
浏览所有可选模型,选择符合你需求的型号。
步骤3:开启免费试用
开启免费试用,探索所选模型的能力。
步骤4:获取 API 密钥
用于 API 认证的密钥将由我们提供。进入「设置」页面,即可按照图中提示复制 API 密钥。

步骤5:安装 API SDK
使用对应编程语言的包管理器安装 API SDK。
安装完成后,将所需库导入你的开发环境,使用 API 密钥初始化 API,即可开始调用 Novita AI 的大语言模型。以下是 Python 用户调用聊天补全 API 的示例:
#Chat API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
#Completion API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
prompt="The following is a conversation with an AI assistant.",
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].text)
3. 集成指南
使用 Trae,Claude Code、Qwen Code 等 CLI 工具
如果你想在本地环境或 IDE 中使用 Novita AI 的顶级模型(如 Qwen3-Coder、Kimi K2、DeepSeek R1)获得 AI 编程辅助,流程非常简单:获取 API 密钥、安装对应工具、配置环境变量,即可开始编程。
详细的安装命令和示例可参考官方教程:
- Trae:在 IDE 中访问 AI 模型的逐步指南
- Claude Code:如何在 Windows、Mac 和 Linux 上的 Claude Code 中使用 Kimi-K2
- Qwen Code:如何在 Qwen Code 中使用 OpenAI 兼容 API(60 秒完成配置!)
使用 OpenAI Agents SDK 构建多智能体工作流
通过将 Novita AI 与 OpenAI Agents SDK 集成,构建高级多智能体系统:
- 即插即用: 可在任意 OpenAI Agents 工作流中使用 Novita AI 的大语言模型。
- 支持交接、路由和工具调用: 可设计由 Novita AI 模型驱动的智能体,实现任务委派、分流或函数执行。
- Python 集成: 只需将 SDK 端点设置为
https://api.novita.ai/v3/openai,并配置你的 API 密钥即可。
在第三方平台接入 API
OpenAI 兼容 API: 可无缝迁移并集成到符合 OpenAI API 标准的工具中,例如 Cline 和 Cursor。
Hugging Face: 可通过 Novita AI 端点,在 Hugging Face Spaces、流水线或 Transformers 库中使用模型。
智能体与编排框架: 通过官方连接器和逐步集成指南,可轻松将 Novita AI 与 Continue、AnythingLLM、LangChain、Dify 和 Langflow 等合作平台连接。
Qwen3-Next-80B-A3B 证明架构设计与参数量规模同样重要。 凭借混合注意力、稀疏 MoE 等创新技术,它在多项基准测试中的表现可与 235B 同级别大模型比肩,同时提供更快的推理速度、更低的延迟和更高的效率。对于需要平衡成本、速度和质量的企业而言,80B 是一个极具竞争力的选择,也证明了设计精良的小模型完全能够与大模型抗衡。
常见问题
80B 模型如何在困难基准测试中与 235B 模型竞争?
80B 模型采用混合注意力和稀疏 MoE 技术,在降低计算成本的同时保留了模型容量,使其在 AIME25、LiveBench、LiveCodeBench 等任务上的表现可与 235B 模型持平甚至超越。
哪款模型更适合处理长文档或聊天历史?
235B 原生支持 262K-1M token 的上下文,但 80B 也可高效处理最高 256K token 的输入。对于绝大多数实际应用场景,80B 的容量完全足够,且速度更快、成本更低。
80B 模型的人类偏好对齐效果更好吗?
是的,在 Arena-Hard v2 基准测试中,Qwen3-Next-80B-A3B Instruct 的表现甚至超越了 235B 模型,尽管参数量更小,但人类偏好对齐效果更强。
Novita AI 是一款 AI 云平台,不仅为开发者提供简单的 API 来部署 AI 模型,还提供高性价比、可靠的 GPU 云服务,支持模型构建与扩容。



