

- Qwen3-Next-80B vs Qwen3-235B:Key Differences in Architectures
- Qwen3-Next-80B-A3B vs Qwen3-235B: Why the Smaller Model Holds Its Ground
- Qwen3-Next-80B vs Qwen3-Next-80B-A3B:Performance Comparison
- Qwen3-Next-80B vs Qwen3-235B:Inference Speed Comparison
- Qwen3-Next-80B vs Qwen3-235B:Which Is Better For Text Generation
- Qwen3-Next-80B vs Qwen3-235B:Which Is Better For Chatbot Applications
- How to Access Qwen3-Next-80B and Qwen3-235B?
On several benchmarks, Qwen3-Next-80B-A3B Instruct performs nearly on par with Qwen3-235B-A22B Instruct, despite having far fewer parameters. This surprising balance naturally raises the question: how can a smaller model hold its ground against a giant? The answer lies in their architectural innovations—and this article will walk you through exactly why.
Qwen3-Next-80B vs Qwen3-235B:Key Differences in Architectures
On several key benchmarks, Qwen3-Next-80B-A3B Instruct performs on par with Qwen3-235B-A22B Instruct, showing nearly identical results on AIME25, LiveBench, and LiveCodeBench. This performance naturally leads to a focus on their architectural differences
From Hugging Face
| Model | Total Parameters | Active Parameters | Layers | Experts | Activated Experts | Attention Type | Context Length | Mode | Key Focus |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-Next-80B-A3B-Instruct | 80B | 3B | 48 | 64 | 2 | Hybrid (DeltaNet + Gated) | Standard (up to 256K) | Instruct | Lightweight reasoning, everyday Q&A |
| Qwen3-Next-80B-A3B-Thinking | 80B | 3B | 48 | 64 | 2 | Hybrid (DeltaNet + Gated) | Standard (up to 256K) | Thinking | Strong reasoning, multi-step problem solving |
| Qwen3-235B-A22B-Instruct-2507 | 235B | 22B | 94 | 128 | 8 | Hybrid (DeltaNet + Gated) | 262K native, up to 1M | Instruct | Large-scale capacity, stronger long-context handling |
| Qwen3-235B-A22B-Thinking-2507 | 235B | 22B | 94 | 128 | 8 | Hybrid (DeltaNet + Gated) | 262K native, up to 1M | Thinking | Massive scale with enhanced reasoning ability |
Qwen3-Next-80B-A3B vs Qwen3-235B: Why the Smaller Model Holds Its Ground
Qwen3-Next-80B-A3B is the first model in the Qwen3-Next series and stands out for its architectural innovations that maximize long-context efficiency and throughput.
It introduces Hybrid Attention, combining Gated DeltaNet and Gated Attention to replace standard attention, enabling efficient context modeling at ultra-long sequence lengths.
A High-Sparsity Mixture-of-Experts (MoE) design lowers the activation ratio drastically, reducing FLOPs per token while preserving model capacity.
To ensure robustness, the model integrates Stability Optimizations such as zero-centered and weight-decayed layer normalization.
Finally, Multi-Token Prediction (MTP) improves pretraining efficiency and accelerates inference. Together, these enhancements make Qwen3-Next-80B-A3B uniquely suited for handling large-scale, long-context workloads with both efficiency and stability.
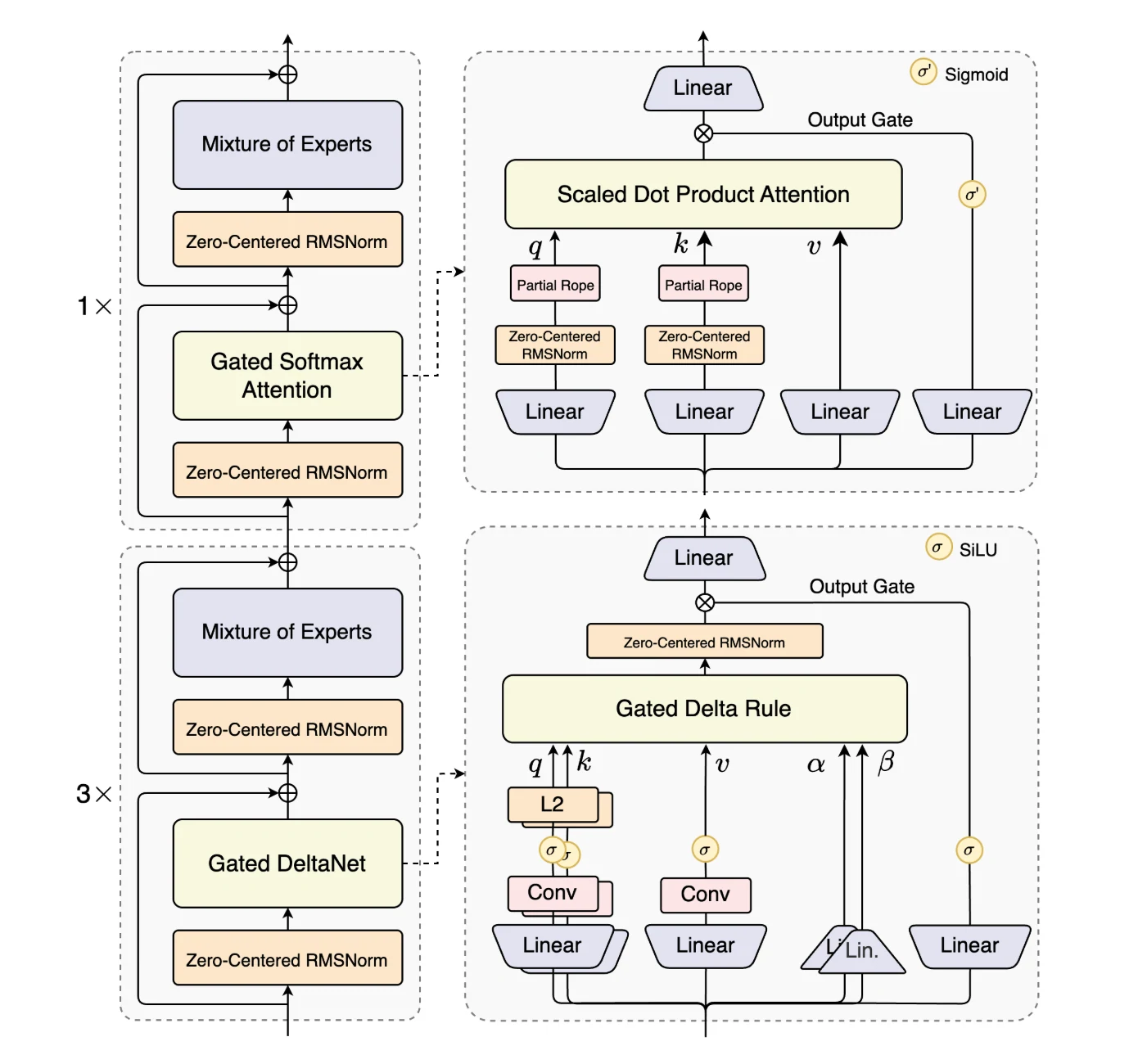
From Hugging Face
The ability to process and sustain more context directly strengthens several core capabilities of the model:
- Long-Document Understanding
It can process entire books, research papers, or long transcripts in a single pass, avoiding information loss from chunking. - Cross-Section Reasoning
Longer context windows allow connections across distant parts of a text, improving logical coherence. - Complex Task Handling
Applications like legal analysis, scientific research, or multi-turn conversations benefit from retaining details across many tokens for accurate reasoning. - Reduced Hallucination / Drift
Keeping the full input accessible lowers the risk of forgetting earlier constraints or fabricating missing details. - Scalability to Real Applications
Enterprise scenarios—chatbots with long histories, retrieval-augmented generation with thousands of context tokens, or multimodal pipelines—gain directly from stable ultra-long-sequence handling.
Qwen3-Next-80B vs Qwen3-Next-80B-A3B:Performance Comparison
| Category | Benchmark | 80B-A3B-Instruct | 80B-A3B-Thinking | 235B-A22B-Thinking | Highest Model |
|---|---|---|---|---|---|
| Knowledge | MMLU-Pro | 80.6 | 82.7 | 84.4 | 235B-Thinking |
| MMLU-Redux | 90.9 | 92.5 | 93.8 | 235B-Thinking | |
| GPQA | 72.9 | 77.2 | 81.1 | 235B-Thinking | |
| SuperGPQA | 58.8 | 60.8 | 64.9 | 235B-Thinking | |
| Reasoning | AIME25 | 69.5 | 87.8 | 92.3 | 235B-Thinking |
| HMMT25 | 54.1 | 73.9 | 83.9 | 235B-Thinking | |
| LiveBench (Nov 2024) | 75.8 | 76.6 | 78.4 | 235B-Thinking | |
| Coding | LiveCodeBench v6 | 56.6 | 68.7 | 74.1 | 235B-Thinking |
| MultiPL-E / CFEval* | 87.8 | 2071 (CFEval) | 2134 (CFEval) | 235B-Thinking | |
| OJBench / Aider-Polyglot* | 49.8 (Aider) | 29.7 (OJBench) | 32.5 (OJBench) | 235B-Thinking | |
| Alignment | IFEval | 87.6 | 88.9 | 88.9 (tie) | 80B-Thinking / 235B-Thinking |
| Arena-Hard v2 | 82.7 | 62.3 | 79.7 | 80B-Instruct | |
| WritingBench | 87.3 | 84.6 | 88.3 | 235B-Thinking | |
| Agent | BFCL-v3 | 70.3 | 72.0 | 72.4 | 235B-Thinking |
| TAU1-Retail | 60.9 | 69.6 | 67.8 | 80B-Thinking | |
| TAU1-Airline | 44.0 | 49.0 | 46.0 | 80B-Instruct | |
| TAU2-Retail | 57.3 | 67.8 | 71.9 | 235B-Thinking | |
| TAU2-Airline | 45.5 | 60.5 | 58.0 | 80B-Thinking | |
| TAU2-Telecom | 13.2 | 43.9 | 45.6 | 235B-Thinking | |
| Multilingual | MultiIF | 75.8 | 77.8 | 80.6 | 235B-Thinking |
| MMLU-ProX | 76.7 | 78.7 | 81.0 | 235B-Thinking | |
| INCLUDE | 78.9 | 78.9 | 81.0 | 235B-Thinking | |
| PolyMATH | 45.9 | 56.3 | 60.1 | 235B-Thinking |
235B models — Qwen3-235B-A22B-Instruct-2507 and Qwen3-235B-A22B-Thinking-2507 — deliver the highest absolute performance, particularly in professional knowledge, coding, and advanced reasoning.
80B models punch far above their weight:
- Qwen3-Next-80B-A3B-Thinking provides reasoning ability close to Qwen3-235B-A22B-Thinking-2507, making it an ideal choice when efficiency and cost are key.
- Qwen3-Next-80B-A3B-Instruct competes closely with Qwen3-235B-A22B-Instruct-2507 in knowledge and coding, while actually surpassing it on alignment benchmarks such as Arena-Hard v2.
Takeaway: Qwen3-Next-80B-A3B is designed for efficiency without sacrificing much performance. Its architectural innovations — Hybrid Attention, sparse MoE, and stability optimizations — enable a smaller model to stand toe-to-toe with its 235B counterparts in many real-world tasks.
Qwen3-Next-80B vs Qwen3-235B:Inference Speed Comparison
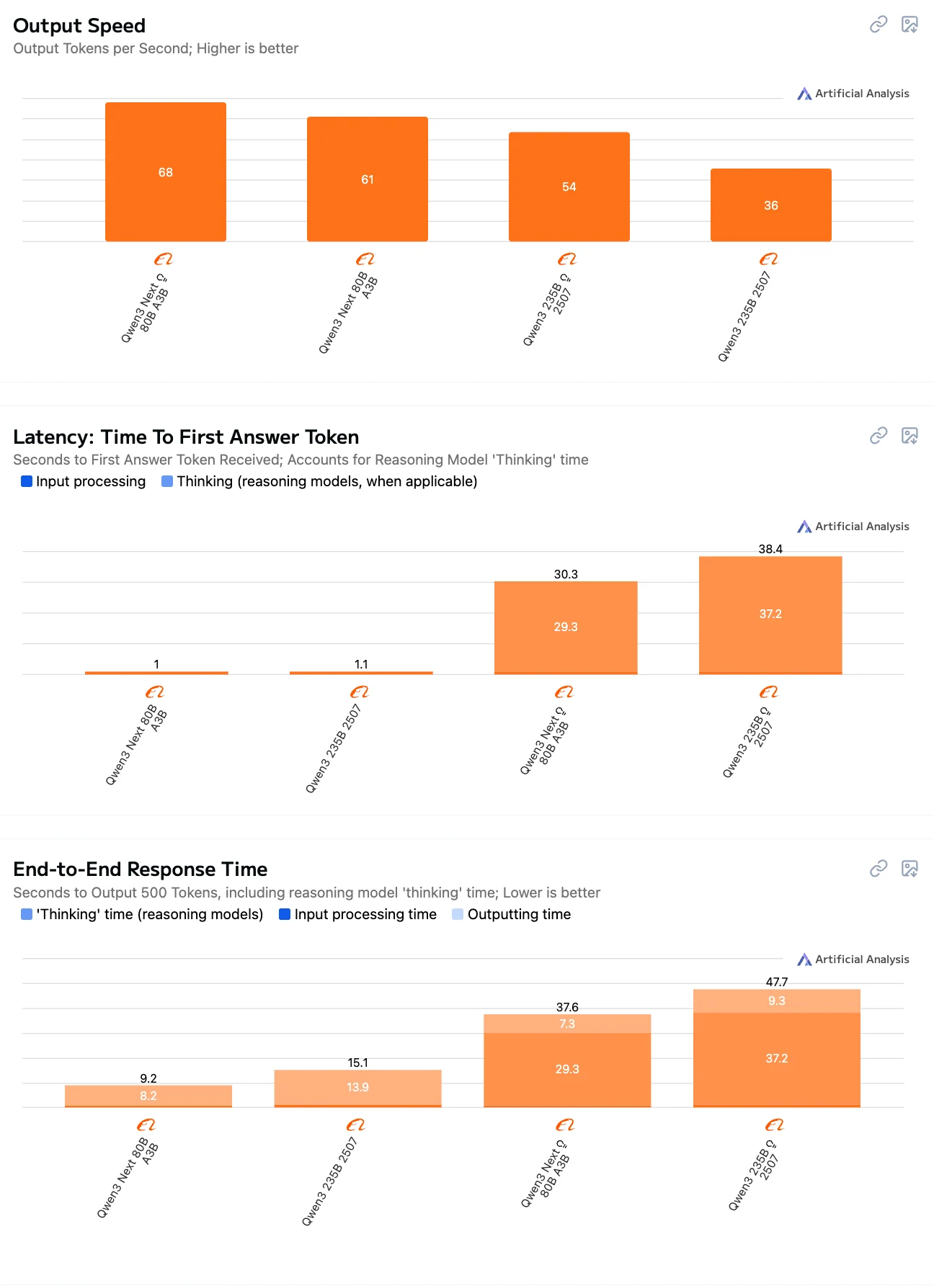
From Artificial Analysis
80B-Instruct = best balance of speed + low latency.
235B models are slower, especially in Thinking mode, due to larger scale and heavier reasoning.
Thinking models (both 80B & 235B) have significantly higher latency and end-to-end time compared to Instruct, because of explicit reasoning steps.
Qwen3-Next-80B vs Qwen3-235B:Which Is Better For Text Generation
Novel Writing / Fiction
- Requirements: Rich character detail, long arcs, immersive style, coherence.
- 235B: Stronger creative detail, more consistent voice, better at metaphor and complexity.
- 80B: Long context windows sustain storylines at lower cost; faster iteration; coherence good enough for many readers.
Scientific Papers / Technical Writing
- Requirements: Precision, structure, citations, jargon, logical flow.
- 235B: Deeper domain knowledge, higher accuracy in details, stronger reasoning.
- 80B: Often sufficient for reviews and standard experiments, but higher risk of small errors in niche areas.
Dialogue / Chat Stories
- Requirements: Coherence across turns, memory, persona following, speed.
- 235B: Slightly better at remembering details and following strict persona instructions.
- 80B: Faster replies with lower latency; long-context handling makes it strong for interactive chat.
Creative Nonfiction / Essays / Blogs
- Requirements: Balance fact and style, clear structure, persuasiveness.
- 235B: Better at fact-rich and complex arguments.
- 80B: Good enough when style and readability matter more than expert precision; faster to revise drafts.
Poetry / Stylized Writing
- Requirements: Imaginative language, rhythm, subtle nuance.
- 235B: Stronger at rare vocabulary, creativity, and subtle expression.
- 80B: Can imitate style well, but sometimes less depth in rare metaphors.
Conclusion
- For top-tier precision and depth (scientific writing, critical technical work, high-end creative projects), 235B is the better choice.
- For efficiency, speed, and lower cost with solid quality—especially for long inputs like stories or chat histories—80B is often the smarter option.
Qwen3-Next-80B vs Qwen3-235B:Which Is Better For Chatbot Applications
Chatbot Needs
Fast replies, coherence across long histories, instruction following, some reasoning, cost efficiency.
235B
- Excels in very large conversations, specialized knowledge, and hard reasoning.
- Drawback: higher latency and compute cost, less ideal if responsiveness matters.
80B
- Lower latency, faster responses.
- Still maintains good instruction following and context handling thanks to architectural innovations.
- Strong choice for interactive, user-facing chatbots.
Key Takeaway
- For smooth user experience and quick replies, 80B is usually better.
- For specialized or highly demanding domains, 235B may still be preferred.
How to Access Qwen3-Next-80B and Qwen3-235B?
1. Web Interface (Easiest for Beginners)
Try Qwen3-Next-80B-A3B Instruct Now!
2. API Access (For Developers)
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API.
Qwen3-Next-80B-A3B Instruct costs $0.15/M input and $1.5/M output, with a 65,536-token context.
Qwen3-Next-80B-A3B Thinking also costs $0.15/M input and $1.5/M output, with the same 65,536-token context.
Qwen3-235B-A22B Thinking-2507 is more expensive at $0.3/M input and $3/M output, offering a 131,072-token context.
Qwen3-235B-A22B Instruct-2507 is priced at $0.15/M input and $0.8/M output, with a 131,072-token context.
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
#Chat API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)#Completion API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
prompt="The following is a conversation with an AI assistant.",
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].text)3. Integration
Using CLI like Trae,Claude Code, Qwen Code
If you want to use Novita AI’s top models (like Qwen3-Coder, Kimi K2, DeepSeek R1) for AI coding assistance in your local environment or IDE, the process is simple: get your API Key, install the tool, configure environment variables, and start coding.
For detailed setup commands and examples, check the official tutorials:
- Trae : Step-by-Step Guide to Access AI Models in Your IDE
- Claude Code:How to Use Kimi-K2 in Claude Code on Windows, Mac, and Linux
- Qwen Code:How to Use OpenAI Compatible API in Qwen Code (60s Setup!)
Multi-Agent Workflows with OpenAI Agents SDK
Build advanced multi-agent systems by integrating Novita AI with the OpenAI Agents SDK:
- Plug-and-play: Use Novita AI’s LLMs in any OpenAI Agents workflow.
- Supports handoffs, routing, and tool use: Design agents that can delegate, triage, or run functions, all powered by Novita AI’s models.
- Python integration: Simply set the SDK endpoint to
https://api.novita.ai/v3/openaiand use your API key.
Connect API on Third-Party Platforms
OpenAI-Compatible API: Enjoy hassle-free migration and integration with tools such as Cline and Cursor, designed for the OpenAI API standard.
Hugging Face: Use Modeis in Spaces, pipelines, or with the Transformers library via Novita AI endpoints.
Agent & Orchestration Frameworks: Easily connect Novita AI with partner platforms like Continue, AnythingLLM,LangChain, Dify and Langflow through official connectors and step-by-step integration guides.
Qwen3-Next-80B-A3B proves that architecture matters as much as raw size. With innovations like Hybrid Attention and sparse MoE, it delivers performance that rivals its 235B counterpart on many benchmarks while offering faster inference, lower latency, and better efficiency. For organizations balancing cost, speed, and quality, 80B stands as a strong alternative that shows smaller models, when well-designed, can hold their ground against giants.
Frequently Asked Questions
How can 80B compete with 235B on difficult benchmarks?
The 80B model uses Hybrid Attention and sparse MoE to reduce compute cost while preserving model capacity, allowing it to match or exceed 235B on tasks like AIME25, LiveBench, and LiveCodeBench.
Which model is better for long documents or chat history?
235B supports a native 262K–1M token context, but 80B also handles up to 256K tokens efficiently. For most real-world applications, 80B offers enough capacity with faster speed and lower cost.
Is 80B better aligned with human preferences?
Yes, in Arena-Hard v2, Qwen3-Next-80B-A3B Instruct actually surpasses 235B, showing stronger alignment despite its smaller scale.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing an affordable and reliable GPU cloud for building and scaling.



