

- Qwen3-Next-80B-A3B vs Qwen3-235B: Diferencias clave en las arquitecturas
- Qwen3-Next-80B-A3B vs Qwen3-235B: Por qué el modelo más pequeño puede competir de igual a igual
- Qwen3-Next-80B vs Qwen3-Next-80B-A3B: Comparativa de rendimiento
- Qwen3-Next-80B vs Qwen3-235B: Comparativa de velocidad de inferencia
- Qwen3-Next-80B vs Qwen3-235B: ¿Cuál es mejor para la generación de texto?
- Qwen3-Next-80B vs Qwen3-235B: ¿Cuál es mejor para aplicaciones de chatbot?
- ¿Cómo acceder a Qwen3-Next-80B y Qwen3-235B?
En varios puntos de referencia, Qwen3-Next-80B-A3B Instruct obtiene un rendimiento casi igual al de Qwen3-235B-A22B Instruct, a pesar de tener muchos menos parámetros. Este equilibrio sorprendente plantea naturalmente la pregunta: ¿cómo puede un modelo más pequeño competir contra uno gigante? La respuesta está en sus innovaciones arquitectónicas, y este artículo te explicará exactamente por qué.
Qwen3-Next-80B-A3B vs Qwen3-235B: Diferencias clave en las arquitecturas
En varios puntos de referencia clave, el modelo Qwen3-Next-80B-A3B Instruct obtiene un rendimiento igual al del Qwen3-235B-A22B Instruct, mostrando resultados casi idénticos en AIME25, LiveBench y LiveCodeBench. Este rendimiento lleva naturalmente a centrarse en sus diferencias arquitectónicas
From Hugging Face
| Modelo | Parámetros totales | Parámetros activos | Capas | Expertos | Expertos activados | Tipo de atención | Longitud de contexto | Modo | Enfoque clave |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-Next-80B-A3B-Instruct | 80B | 3B | 48 | 64 | 2 | Híbrido (DeltaNet + compuerta) | Estándar (hasta 256K) | Instruct | Razonamiento ligero, preguntas y respuestas cotidianas |
| Qwen3-Next-80B-A3B-Thinking | 80B | 3B | 48 | 64 | 2 | Híbrido (DeltaNet + compuerta) | Estándar (hasta 256K) | Thinking | Razonamiento potente, resolución de problemas de varios pasos |
| Qwen3-235B-A22B-Instruct-2507 | 235B | 22B | 94 | 128 | 8 | Híbrido (DeltaNet + compuerta) | 262K nativo, hasta 1M | Instruct | Capacidad a gran escala, manejo más potente de contexto largo |
| Qwen3-235B-A22B-Thinking-2507 | 235B | 22B | 94 | 128 | 8 | Híbrido (DeltaNet + compuerta) | 262K nativo, hasta 1M | Thinking | Escala masiva con capacidad de razonamiento mejorada |
Qwen3-Next-80B-A3B vs Qwen3-235B: Por qué el modelo más pequeño puede competir de igual a igual
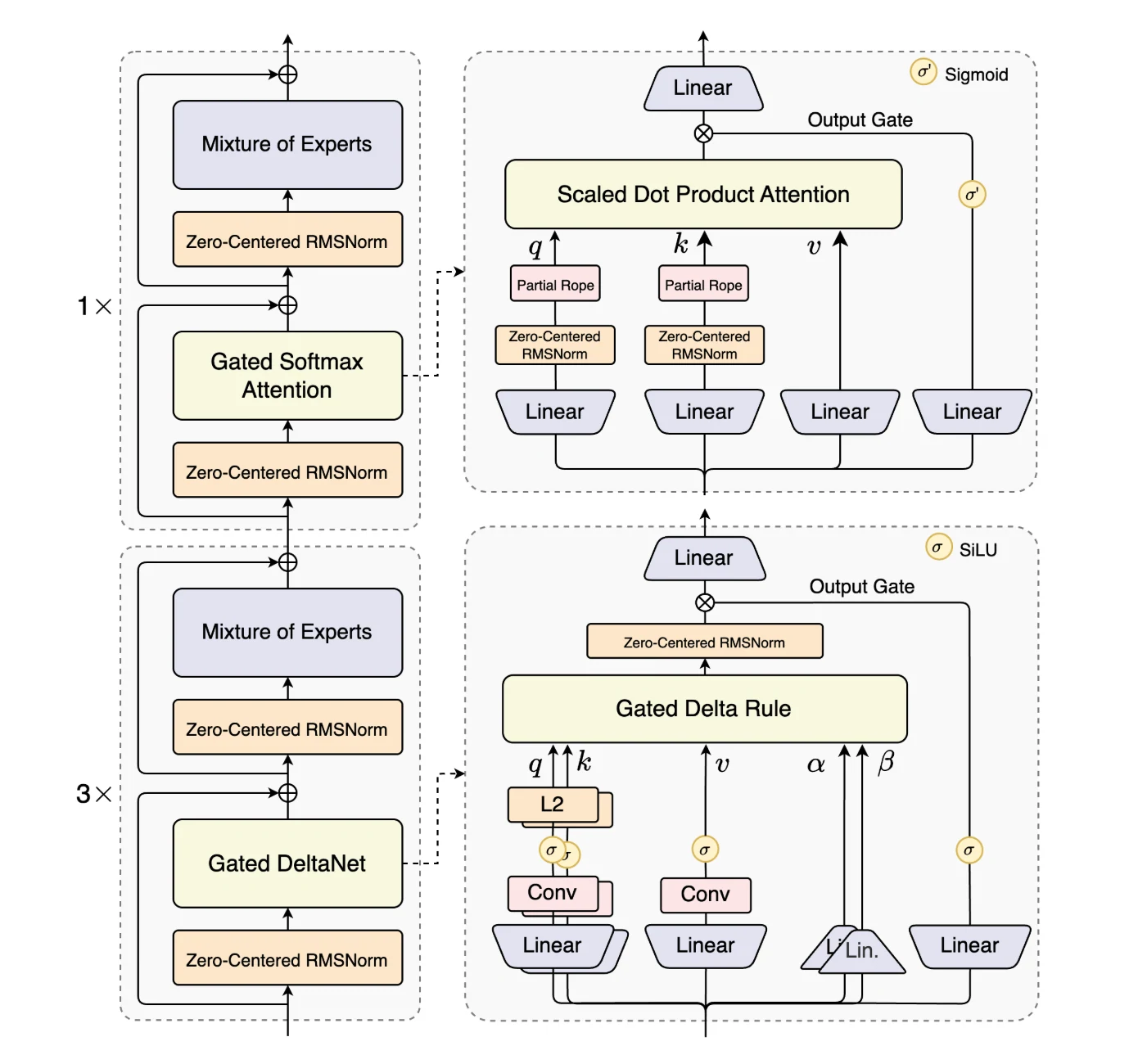
Qwen3-Next-80B-A3B es el primer modelo de la serie Qwen3-Next y destaca por sus innovaciones arquitectónicas que maximizan la eficiencia y el rendimiento en contextos largos.
Introduce Atención híbrida, que combina DeltaNet con compuerta y Atención con compuerta para reemplazar la atención estándar, permitiendo un modelado de contexto eficiente en longitudes de secuencia ultra largas.
Un diseño de Mezcla de Expertos (MoE) de alta dispersión reduce drásticamente la proporción de activación, disminuyendo los FLOPs por token sin perder capacidad del modelo.
Para garantizar la robustez, el modelo integra Optimizaciones de estabilidad como la normalización de capas centrada en cero y con decaimiento de peso.
Finalmente, la Predicción de múltiples tokens (MTP) mejora la eficiencia del preentrenamiento y acelera la inferencia. Juntas, estas mejoras hacen que Qwen3-Next-80B-A3B sea especialmente adecuado para manejar cargas de trabajo a gran escala y de contexto largo, con eficiencia y estabilidad.
From Hugging Face
La capacidad de procesar y mantener más contexto fortalece directamente varias capacidades clave del modelo:
- Comprensión de documentos largos
Puede procesar libros completos, artículos de investigación o transcripciones largas en una sola pasada, evitando la pérdida de información por división en fragmentos. - Razonamiento entre secciones distantes
Las ventanas de contexto más largas permiten establecer conexiones entre partes distantes de un texto, mejorando la coherencia lógica. - Manejo de tareas complejas
Aplicaciones como el análisis legal, la investigación científica o las conversaciones multipropósito se benefician de retener detalles a lo largo de muchos tokens para un razonamiento preciso. - Reducción de alucinaciones / desviación
Mantener toda la entrada accesible reduce el riesgo de olvidar restricciones anteriores o inventar detalles faltantes. - Escalabilidad a aplicaciones reales
Escenarios empresariales: chatbots con historiales largos, generación aumentada por recuperación con miles de tokens de contexto o canalizaciones multimodales se benefician directamente de un manejo estable de secuencias ultra largas.
Qwen3-Next-80B vs Qwen3-Next-80B-A3B: Comparativa de rendimiento
| Categoría | Punto de referencia | 80B-A3B-Instruct | 80B-A3B-Thinking | 235B-A22B-Thinking | Modelo con mayor puntuación |
|---|---|---|---|---|---|
| Conocimiento | MMLU-Pro | 80.6 | 82.7 | 84.4 | 235B-Thinking |
| MMLU-Redux | 90.9 | 92.5 | 93.8 | 235B-Thinking | |
| GPQA | 72.9 | 77.2 | 81.1 | 235B-Thinking | |
| SuperGPQA | 58.8 | 60.8 | 64.9 | 235B-Thinking | |
| Razonamiento | AIME25 | 69.5 | 87.8 | 92.3 | 235B-Thinking |
| HMMT25 | 54.1 | 73.9 | 83.9 | 235B-Thinking | |
| LiveBench (Nov 2024) | 75.8 | 76.6 | 78.4 | 235B-Thinking | |
| Programación | LiveCodeBench v6 | 56.6 | 68.7 | 74.1 | 235B-Thinking |
| MultiPL-E / CFEval* | 87.8 | 2071 (CFEval) | 2134 (CFEval) | 235B-Thinking | |
| OJBench / Aider-Polyglot* | 49.8 (Aider) | 29.7 (OJBench) | 32.5 (OJBench) | 235B-Thinking | |
| Alineación | IFEval | 87.6 | 88.9 | 88.9 (empate) | 80B-Thinking / 235B-Thinking |
| Arena-Hard v2 | 82.7 | 62.3 | 79.7 | 80B-Instruct | |
| WritingBench | 87.3 | 84.6 | 88.3 | 235B-Thinking | |
| Agente | BFCL-v3 | 70.3 | 72.0 | 72.4 | 235B-Thinking |
| TAU1-Retail | 60.9 | 69.6 | 67.8 | 80B-Thinking | |
| TAU1-Airline | 44.0 | 49.0 | 46.0 | 80B-Instruct | |
| TAU2-Retail | 57.3 | 67.8 | 71.9 | 235B-Thinking | |
| TAU2-Airline | 45.5 | 60.5 | 58.0 | 80B-Thinking | |
| TAU2-Telecom | 13.2 | 43.9 | 45.6 | 235B-Thinking | |
| Multilingüe | MultiIF | 75.8 | 77.8 | 80.6 | 235B-Thinking |
| MMLU-ProX | 76.7 | 78.7 | 81.0 | 235B-Thinking | |
| INCLUDE | 78.9 | 78.9 | 81.0 | 235B-Thinking | |
| PolyMATH | 45.9 | 56.3 | 60.1 | 235B-Thinking |
Los modelos de 235B — Qwen3-235B-A22B-Instruct-2507 y Qwen3-235B-A22B-Thinking-2507 — ofrecen el rendimiento absoluto más alto, especialmente en conocimiento profesional, programación y razonamiento avanzado.
Los modelos de 80B obtienen un rendimiento muy superior a lo que cabría esperar por su tamaño:
- Qwen3-Next-80B-A3B-Thinking ofrece una capacidad de razonamiento muy cercana a la del Qwen3-235B-A22B-Thinking-2507, por lo que es una opción ideal cuando la eficiencia y el coste son factores clave.
- Qwen3-Next-80B-A3B-Instruct compite de muy cerca con el Qwen3-235B-A22B-Instruct-2507 en conocimiento y programación, mientras que lo supera en puntos de referencia de alineación como Arena-Hard v2.
Conclusión: Qwen3-Next-80B-A3B está diseñado para la eficiencia sin sacrificar casi rendimiento. Sus innovaciones arquitectónicas — Atención híbrida, MoE disperso y optimizaciones de estabilidad — permiten que un modelo más pequeño compita de igual a igual con sus contrapartes de 235B en muchas tareas del mundo real.
Qwen3-Next-80B vs Qwen3-235B: Comparativa de velocidad de inferencia
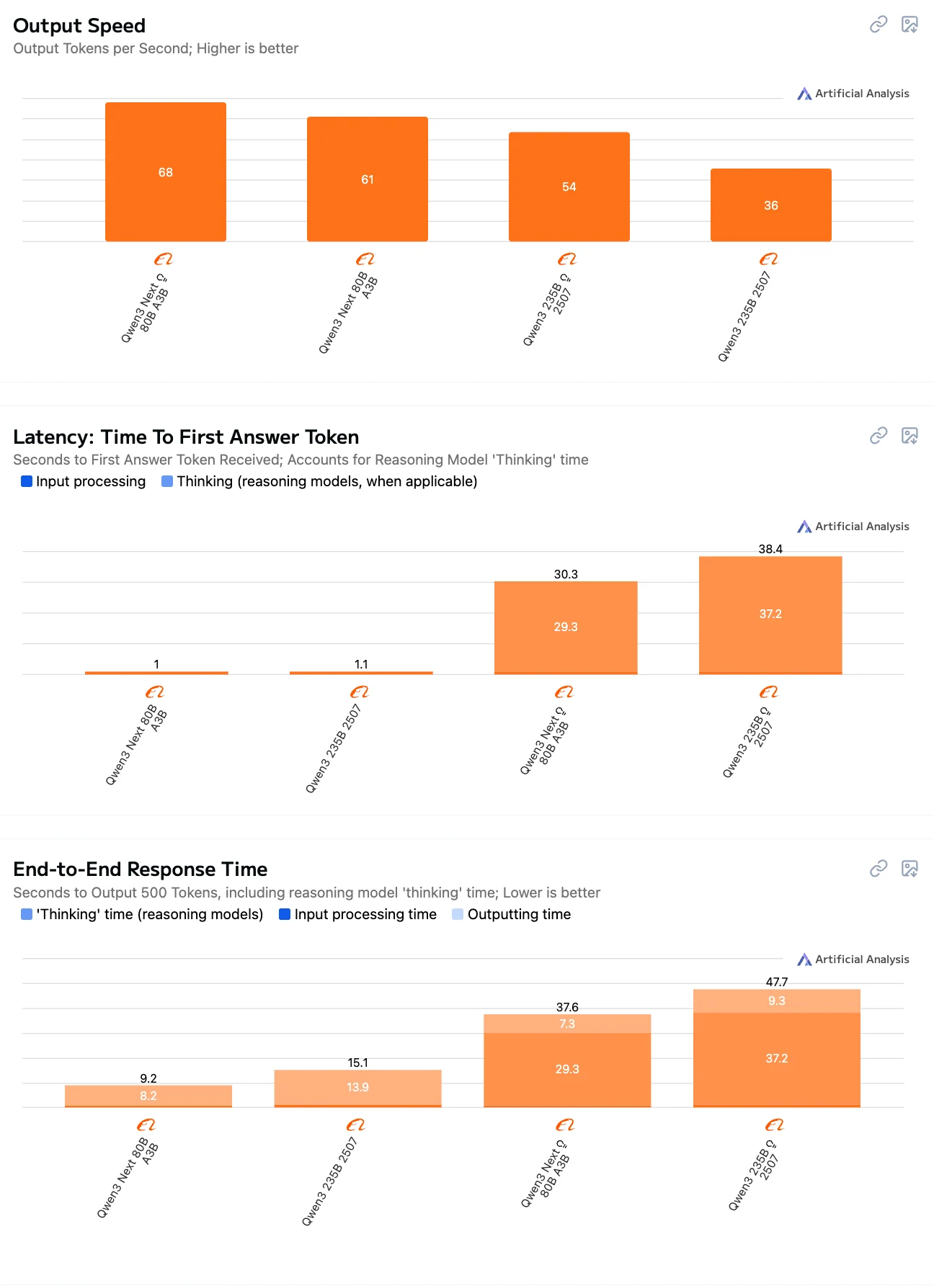
From Artificial Analysis
80B-Instruct = el mejor equilibrio entre velocidad + baja latencia.
Los modelos de 235B son más lentos, especialmente en modo Thinking, debido a su mayor escala y el razonamiento más pesado.
Los modelos de tipo Thinking (tanto 80B como 235B) tienen una latencia y un tiempo de extremo a extremo significativamente mayores que los de tipo Instruct, debido a los pasos de razonamiento explícitos.
Qwen3-Next-80B vs Qwen3-235B: ¿Cuál es mejor para la generación de texto?
Novelas / Ficción
- Requisitos: Detalle rico de personajes, arcos largos, estilo inmersivo, coherencia.
- 235B: Mayor detalle creativo, voz más consistente, mejor en metáforas y complejidad.
- 80B: Las ventanas de contexto largo mantienen las tramas a menor coste; iteración más rápida; la coherencia es suficiente para muchos lectores.
Artículos científicos / Escritura técnica
- Requisitos: Precisión, estructura, citas, jerga, flujo lógico.
- 235B: Conocimiento más profundo del dominio, mayor precisión en los detalles, razonamiento más potente.
- 80B: Suele ser suficiente para revisiones y experimentos estándar, pero con mayor riesgo de pequeños errores en áreas muy específicas.
Diálogos / Historias de chat
- Requisitos: Coherencia entre turnos, memoria, seguimiento de personajes, velocidad.
- 235B: Ligeramente mejor para recordar detalles y seguir instrucciones estrictas de personajes.
- 80B: Respuestas más rápidas con menor latencia; el manejo de contexto largo lo hace muy fuerte para chats interactivos.
No ficción creativa / Ensayos / Blogs
- Requisitos: Equilibrio entre hecho y estilo, estructura clara, capacidad de persuasión.
- 235B: Mejor en argumentos ricos en datos y complejos.
- 80B: Suficiente cuando el estilo y la legibilidad importan más que la precisión experta; más rápido para revisar borradores.
Poesía / Escritura estilizada
- Requisitos: Lenguaje imaginativo, ritmo, matices sutiles.
- 235B: Más fuerte en vocabulario poco común, creatividad y expresión sutil.
- 80B: Puede imitar el estilo bien, pero a veces tiene menos profundidad en metáforas poco comunes.
Conclusión
- Para obtener la máxima precisión y profundidad (escritura científica, trabajo técnico crítico, proyectos creativos de alta gama), el modelo 235B es la mejor opción.
- Para eficiencia, velocidad y menor coste con una calidad sólida —especialmente para entradas largas como historias o historiales de chat— el modelo 80B suele ser la opción más inteligente.
Qwen3-Next-80B vs Qwen3-235B: ¿Cuál es mejor para aplicaciones de chatbot?
Necesidades de los chatbots
Respuestas rápidas, coherencia en historiales largos, seguimiento de instrucciones, cierto razonamiento, eficiencia de costes.
235B
- Destaca en conversaciones muy extensas, conocimientos especializados y razonamiento complejo.
- Inconveniente: mayor latencia y coste de computación, menos ideal si la capacidad de respuesta es importante.
80B
- Menor latencia, respuestas más rápidas.
- Mantiene un buen seguimiento de instrucciones y manejo de contexto gracias a las innovaciones arquitectónicas.
- Opción muy fuerte para chatbots interactivos orientados al usuario.
Conclusión clave
- Para una experiencia de usuario fluida y respuestas rápidas, el modelo 80B suele ser mejor.
- Para dominios especializados o muy exigentes, el modelo 235B puede seguir siendo la opción preferida.
¿Cómo acceder a Qwen3-Next-80B y Qwen3-235B?
1. Interfaz web (la más fácil para principiantes)
Prueba Qwen3-Next-80B-A3B Instruct ahora!
2. Acceso por API (para desarrolladores)
Novita AI es una plataforma de computación en la nube de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA mediante nuestra API sencilla.
Qwen3-Next-80B-A3B Instruct cuesta $0.15 por cada millón de tokens de entrada y $1.5 por cada millón de tokens de salida, con un contexto de 65 536 tokens.
Qwen3-Next-80B-A3B Thinking también cuesta $0.15 por cada millón de tokens de entrada y $1.5 por cada millón de tokens de salida, con el mismo contexto de 65 536 tokens.
Qwen3-235B-A22B Thinking-2507 es más caro, con un precio de $0.3 por cada millón de tokens de entrada y $3 por cada millón de tokens de salida, ofreciendo un contexto de 131 072 tokens.
Qwen3-235B-A22B Instruct-2507 tiene un precio de $0.15 por cada millón de tokens de entrada y $0.8 por cada millón de tokens de salida, con un contexto de 131 072 tokens.
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Entrando en la página de “Ajustes”, puedes copiar la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API mediante el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de finalización de chat para usuarios de Python.
#Chat API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
#Completion API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
prompt="The following is a conversation with an AI assistant.",
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].text)
3. Integración
Uso de CLI como Trae, Claude Code, Qwen Code
Si quieres usar los modelos principales de Novita AI (como Qwen3-Coder, Kimi K2, DeepSeek R1) para asistencia de programación con IA en tu entorno local o IDE, el proceso es sencillo: obtén tu clave de API, instala la herramienta, configura las variables de entorno y empieza a programar.
Para obtener comandos de configuración detallados y ejemplos, consulta los tutoriales oficiales:
- Trae : Guía paso a paso para acceder a modelos de IA en tu IDE
- Claude Code:Cómo usar Kimi-K2 en Claude Code en Windows, Mac y Linux
- Qwen Code:Cómo usar la API compatible con OpenAI en Qwen Code (¡configuración en 60 segundos!)
Flujos de trabajo multiagente con el SDK de Agentes de OpenAI
Crea sistemas multiagente avanzados integrando Novita AI con el SDK de Agentes de OpenAI:
- Listo para usar: Utiliza los LLM de Novita AI en cualquier flujo de trabajo de Agentes de OpenAI.
- Admite transferencias, enrutamiento y uso de herramientas: Diseña agentes que puedan delegar, clasificar o ejecutar funciones, todo impulsado por los modelos de Novita AI.
- Integración con Python: Simplemente configura el endpoint del SDK en
https://api.novita.ai/v3/openaiy usa tu clave de API.
Conecta la API en plataformas de terceros
API compatible con OpenAI: Disfruta de una migración e integración sin complicaciones con herramientas como Cline y Cursor, diseñadas para el estándar de API de OpenAI.
Hugging Face: Usa los modelos en Spaces, canalizaciones o con la librería Transformers a través de los endpoints de Novita AI.
Frameworks de agentes y orquestación: Conecta fácilmente Novita AI con plataformas asociadas como Continue, AnythingLLM,LangChain, Dify y Langflow mediante conectores oficiales y guías de integración paso a paso.
Qwen3-Next-80B-A3B demuestra que la arquitectura es tan importante como el tamaño bruto. Con innovaciones como la Atención híbrida y el MoE disperso, ofrece un rendimiento que rivaliza con el de su contraparte de 235B en muchos puntos de referencia, al mismo tiempo que proporciona inferencia más rápida, menor latencia y mejor eficiencia. Para organizaciones que buscan equilibrar coste, velocidad y calidad, el modelo de 80B es una alternativa muy sólida que demuestra que los modelos más pequeños, cuando están bien diseñados, pueden competir de igual a igual con los gigantes.
Preguntas frecuentes
¿Cómo puede competir el modelo de 80B con el de 235B en puntos de referencia difíciles?
El modelo de 80B utiliza Atención híbrida y MoE disperso para reducir el coste de computación sin perder capacidad del modelo, lo que le permite igualar o superar al de 235B en tareas como AIME25, LiveBench y LiveCodeBench.
¿Qué modelo es mejor para documentos largos o historiales de chat?
El modelo de 235B admite un contexto nativo de 262K a 1M de tokens, pero el de 80B también maneja hasta 256K tokens de forma eficiente. Para la mayoría de las aplicaciones del mundo real, el modelo de 80B ofrece capacidad suficiente con mayor velocidad y menor coste.
¿El modelo de 80B está mejor alineado con las preferencias humanas?
Sí, en Arena-Hard v2, el Qwen3-Next-80B-A3B Instruct supera al de 235B, mostrando una alineación más fuerte a pesar de su escala más pequeña.
Novita AI es una plataforma de computación en la nube de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA mediante nuestra API sencilla, además de proporcionar una nube de GPU asequible y fiable para construir y escalar.



