

- Qwen3-Next-80B-A3B vs Qwen3-235B : Principales différences architecturales
- Qwen3-Next-80B-A3B vs Qwen3-235B : Pourquoi le modèle plus petit tient tête
- Qwen3-Next-80B vs Qwen3-Next-80B-A3B : Comparaison des performances
- Qwen3-Next-80B vs Qwen3-235B : Comparaison de la vitesse d'inférence
- Qwen3-Next-80B vs Qwen3-235B : Lequel est meilleur pour la génération de texte ?
- Qwen3-Next-80B vs Qwen3-235B : Lequel est meilleur pour les applications de chatbot ?
- Comment accéder à Qwen3-Next-80B et Qwen3-235B ?
Sur plusieurs benchmarks, Qwen3-Next-80B-A3B Instruct obtient des résultats quasi équivalents à ceux de Qwen3-235B-A22B Instruct, malgré un nombre de paramètres bien inférieur. Ce résultat surprenant soulève naturellement une question : comment un modèle plus petit peut-il tenir tête à un géant ? La réponse réside dans leurs innovations architecturales — et cet article vous expliquera exactement pourquoi.
Qwen3-Next-80B-A3B vs Qwen3-235B : Principales différences architecturales
Sur plusieurs benchmarks clés, Qwen3-Next-80B-A3B Instruct obtient des résultats équivalents à ceux de Qwen3-235B-A22B Instruct, affichant des résultats quasi identiques sur AIME25, LiveBench et LiveCodeBench. Cette performance conduit naturellement à se concentrer sur leurs différences architecturales
Depuis Hugging Face
| Catégorie | Benchmark | 80B-A3B-Instruct | 80B-A3B-Thinking | 235B-A22B-Thinking | Modèle le plus performant |
|---|---|---|---|---|---|
| Connaissances | MMLU-Pro | 80.6 | 82.7 | 84.4 | 235B-Thinking |
| MMLU-Redux | 90.9 | 92.5 | 93.8 | 235B-Thinking | |
| GPQA | 72.9 | 77.2 | 81.1 | 235B-Thinking | |
| SuperGPQA | 58.8 | 60.8 | 64.9 | 235B-Thinking | |
| Raisonnement | AIME25 | 69.5 | 87.8 | 92.3 | 235B-Thinking |
| HMMT25 | 54.1 | 73.9 | 83.9 | 235B-Thinking | |
| LiveBench (Nov 2024) | 75.8 | 76.6 | 78.4 | 235B-Thinking | |
| Codage | LiveCodeBench v6 | 56.6 | 68.7 | 74.1 | 235B-Thinking |
| MultiPL-E / CFEval* | 87.8 | 2071 (CFEval) | 2134 (CFEval) | 235B-Thinking | |
| OJBench / Aider-Polyglot* | 49.8 (Aider) | 29.7 (OJBench) | 32.5 (OJBench) | 235B-Thinking | |
| Alignement | IFEval | 87.6 | 88.9 | 88.9 (égalité) | 80B-Thinking / 235B-Thinking |
| Arena-Hard v2 | 82.7 | 62.3 | 79.7 | 80B-Instruct | |
| WritingBench | 87.3 | 84.6 | 88.3 | 235B-Thinking | |
| Agent | BFCL-v3 | 70.3 | 72.0 | 72.4 | 235B-Thinking |
| TAU1-Retail | 60.9 | 69.6 | 67.8 | 80B-Thinking | |
| TAU1-Airline | 44.0 | 49.0 | 46.0 | 80B-Instruct | |
| TAU2-Retail | 57.3 | 67.8 | 71.9 | 235B-Thinking | |
| TAU2-Airline | 45.5 | 60.5 | 58.0 | 80B-Thinking | |
| TAU2-Telecom | 13.2 | 43.9 | 45.6 | 235B-Thinking | |
| Multilingue | MultiIF | 75.8 | 77.8 | 80.6 | 235B-Thinking |
| MMLU-ProX | 76.7 | 78.7 | 81.0 | 235B-Thinking | |
| INCLUDE | 78.9 | 78.9 | 81.0 | 235B-Thinking | |
| PolyMATH | 45.9 | 56.3 | 60.1 | 235B-Thinking |
| Modèle | Paramètres totaux | Paramètres actifs | Couches | Experts | Experts activés | Type d’attention | Longueur de contexte | Mode | Objectif principal |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-Next-80B-A3B-Instruct | 80B | 3B | 48 | 64 | 2 | Hybride (DeltaNet + Gated) | Standard (jusqu’à 256K) | Instruct | Raisonnement léger, questions-réponses quotidiennes |
| Qwen3-Next-80B-A3B-Thinking | 80B | 3B | 48 | 64 | 2 | Hybride (DeltaNet + Gated) | Standard (jusqu’à 256K) | Thinking | Raisonnement fort, résolution de problèmes multi-étapes |
| Qwen3-235B-A22B-Instruct-2507 | 235B | 22B | 94 | 128 | 8 | Hybride (DeltaNet + Gated) | 262K natif, jusqu’à 1M | Instruct | Capacité à grande échelle, meilleure gestion du long contexte |
| Qwen3-235B-A22B-Thinking-2507 | 235B | 22B | 94 | 128 | 8 | Hybride (DeltaNet + Gated) | 262K natif, jusqu’à 1M | Thinking | Échelle massive avec capacités de raisonnement améliorées |
Qwen3-Next-80B-A3B vs Qwen3-235B : Pourquoi le modèle plus petit tient tête
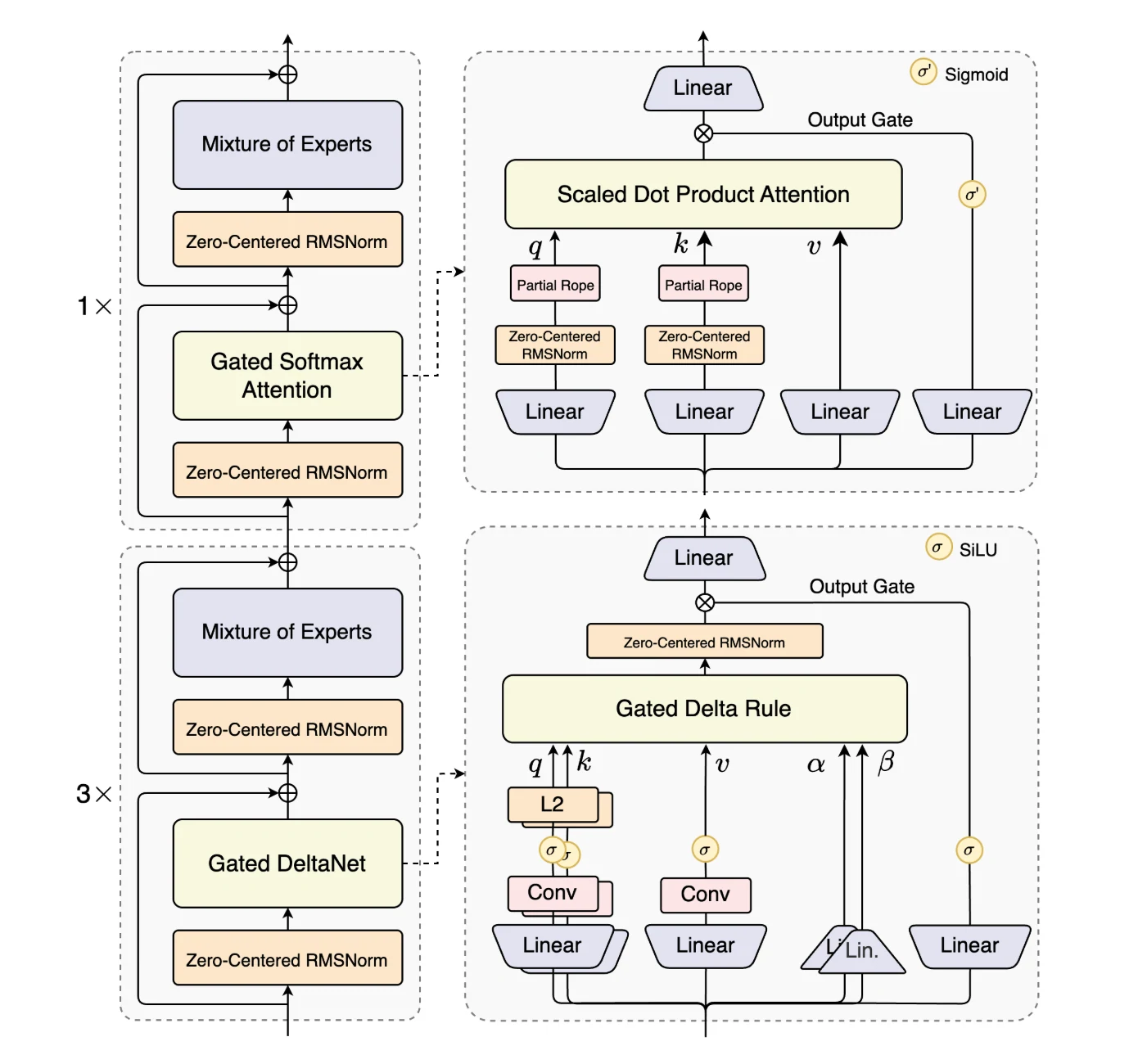
Qwen3-Next-80B-A3B est le premier modèle de la série Qwen3-Next et se distingue par ses innovations architecturales qui maximisent l’efficacité sur long contexte et le débit.
Il introduit Hybrid Attention, combinant DeltaNet gated et Attention gated pour remplacer l’attention standard, permettant une modélisation efficace du contexte sur des séquences ultra-longues.
Une conception Mixture-of-Experts (MoE) à haute sparsité réduit drastiquement le ratio d’activation, réduisant les FLOPs par token tout en préservant la capacité du modèle.
Pour garantir sa robustesse, le modèle intègre des Optimisations de stabilité telles qu’une normalisation de couche centrée sur zéro et avec decay de poids.
Enfin, la Prédiction multi-tokens (MTP) améliore l’efficacité du pré-entraînement et accélère l’inférence. Ensemble, ces améliorations font de Qwen3-Next-80B-A3B un modèle particulièrement adapté pour traiter des charges de travail à grande échelle et sur long contexte, avec à la fois efficacité et stabilité.
Depuis Hugging Face
La capacité à traiter et maintenir plus de contexte renforce directement plusieurs capacités clés du modèle :
- Compréhension de documents longs
Il peut traiter des livres entiers, des articles de recherche ou de longues transcriptions en une seule passe, évitant la perte d’information due au découpage en morceaux. - Raisonnement inter-parties
Des fenêtres de contexte plus longues permettent de faire des liens entre des parties éloignées d’un texte, améliorant la cohérence logique. - Traitement de tâches complexes
Des applications comme l’analyse juridique, la recherche scientifique ou les conversations multi-tours bénéficient de la conservation des détails sur de nombreux tokens pour un raisonnement précis. - Réduction des hallucinations / dérives
Garder l’ensemble de l’entrée accessible réduit le risque d’oublier des contraintes initiales ou d’inventer des détails manquants. - Scalabilité vers des applications réelles
Des scénarios professionnels — chatbots avec des historiques longs, génération augmentée par récupération avec des milliers de tokens de contexte, ou pipelines multimodaux — bénéficient directement d’une gestion stable des séquences ultra-longues.
Qwen3-Next-80B vs Qwen3-Next-80B-A3B : Comparaison des performances
Les modèles 235B — Qwen3-235B-A22B-Instruct-2507 et Qwen3-235B-A22B-Thinking-2507 — offrent les performances absolues les plus élevées, notamment en matière de connaissances professionnelles, de codage et de raisonnement avancé.
Les modèles 80B performent largement au-dessus de leur catégorie :
- Qwen3-Next-80B-A3B-Thinking offre des capacités de raisonnement proches de celles de Qwen3-235B-A22B-Thinking-2507, ce qui en fait un choix idéal lorsque l’efficacité et le coût sont prioritaires.
- Qwen3-Next-80B-A3B-Instruct est très proche de Qwen3-235B-A22B-Instruct-2507 sur les connaissances et le codage, et le surpasse même sur les benchmarks d’alignement comme Arena-Hard v2.
Point clé : Qwen3-Next-80B-A3B est conçu pour l’efficacité sans sacrifier beaucoup de performances. Ses innovations architecturales — Hybrid Attention, MoE sparse et optimisations de stabilité — permettent à un modèle plus petit de se mesurer à ses homologues de 235B sur de nombreuses tâches réelles.
Qwen3-Next-80B vs Qwen3-235B : Comparaison de la vitesse d’inférence
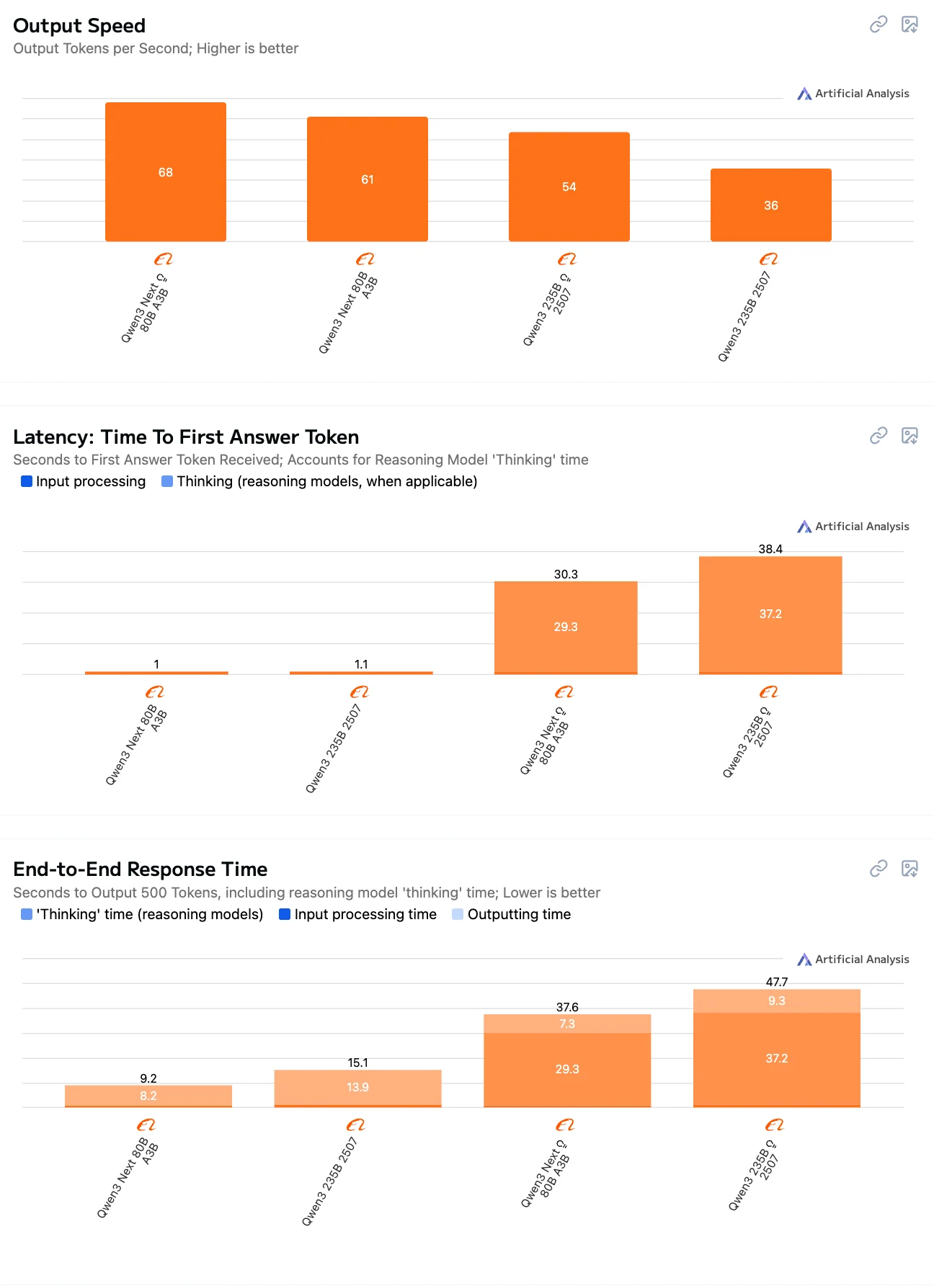
Depuis Artificial Analysis
80B-Instruct = meilleur équilibre entre vitesse + faible latence.
Les modèles 235B sont plus lents, notamment en mode Thinking, en raison de leur échelle plus importante et d’un raisonnement plus lourd.
Les modèles Thinking (80B et 235B) ont une latence et un temps de bout en bout significativement plus élevés que les modèles Instruct, en raison des étapes de raisonnement explicites.
Qwen3-Next-80B vs Qwen3-235B : Lequel est meilleur pour la génération de texte ?
Rédaction de romans / Fiction
- Exigences : Détails riches sur les personnages, arcs narratifs longs, style immersif, cohérence.
- 235B : Détails créatifs plus poussés, voix plus cohérente, meilleure pour les métaphores et la complexité.
- 80B : Les fenêtres de contexte long maintiennent les intrigues à moindre coût ; itération plus rapide ; cohérence suffisante pour de nombreux lecteurs.
Rédaction d’articles scientifiques / écrits techniques
- Exigences : Précision, structure, citations, jargon, flux logique.
- 235B : Connaissances domaines plus profondes, précision plus élevée sur les détails, raisonnement plus fort.
- 80B : Souvent suffisant pour des revues et des expériences standard, mais risque plus élevé de petites erreurs dans des domaines de niche.
Dialogue / Histoires de chat
- Exigences : Cohérence entre les tours, mémoire, respect du persona, vitesse.
- 235B : Légèrement meilleur pour se souvenir des détails et suivre des instructions de persona strictes.
- 80B : Réponses plus rapides avec une latence plus faible ; la gestion du long contexte le rend performant pour les chats interactifs.
Non-fiction créative / Essais / Blogs
- Exigences : Équilibre entre faits et style, structure claire, persuasion.
- 235B : Meilleur pour des arguments riches en faits et complexes.
- 80B : Suffisant lorsque le style et la lisibilité comptent plus que la précision experte ; plus rapide pour réviser des brouillons.
Poésie / Écriture stylisée
- Exigences : Langage imagé, rythme, nuances subtiles.
- 235B : Plus performant pour le vocabulaire rare, la créativité et l’expression subtile.
- 80B : Peut bien imiter le style, mais parfois moins de profondeur dans les métaphores rares.
Conclusion
- Pour une précision et une profondeur de haut niveau (rédaction scientifique, travaux techniques critiques, projets créatifs haut de gamme), le 235B est le meilleur choix.
- Pour l’efficacité, la vitesse et un coût plus faible avec une qualité solide — notamment pour des entrées longues comme des histoires ou des historiques de chat — le 80B est souvent l’option la plus judicieuse.
Qwen3-Next-80B vs Qwen3-235B : Lequel est meilleur pour les applications de chatbot ?
Besoins des chatbots
Réponses rapides, cohérence sur des historiques longs, respect des instructions, un peu de raisonnement, efficacité des coûts.
235B
- Excelle dans les conversations très volumineuses, les connaissances spécialisées et le raisonnement complexe.
- Inconvénient : latence et coût de calcul plus élevés, moins idéal si la réactivité est importante.
80B
- Latence plus faible, réponses plus rapides.
- Maintient un bon respect des instructions et une gestion du contexte grâce aux innovations architecturales.
- Choix fort pour les chatbots interactifs orientés utilisateur.
Point clé
- Pour une expérience utilisateur fluide et des réponses rapides, le 80B est généralement meilleur.
- Pour des domaines spécialisés ou très exigeants, le 235B peut toujours être préféré.
Comment accéder à Qwen3-Next-80B et Qwen3-235B ?
1. Interface Web (la plus simple pour les débutants)
Essayez Qwen3-Next-80B-A3B Instruct dès maintenant !
2. Accès API (pour les développeurs)
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA grâce à notre API simple.
Qwen3-Next-80B-A3B Instruct coûte 0,15 $ par million de tokens en entrée et 1,5 $ par million de tokens en sortie, avec un contexte de 65 536 tokens.
Qwen3-Next-80B-A3B Thinking coûte également 0,15 $ par million de tokens en entrée et 1,5 $ par million de tokens en sortie, avec le même contexte de 65 536 tokens.
Qwen3-235B-A22B Thinking-2507 est plus cher à 0,3 $ par million de tokens en entrée et 3 $ par million de tokens en sortie, avec un contexte de 131 072 tokens.
Qwen3-235B-A22B Instruct-2507 est tarifé à 0,15 $ par million de tokens en entrée et 0,8 $ par million de tokens en sortie, avec un contexte de 131 072 tokens.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
#Chat API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
#Completion API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
prompt="The following is a conversation with an AI assistant.",
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].text)
3. Intégration
Utilisation d’outils CLI comme Trae, Claude Code, Qwen Code
Si vous souhaitez utiliser les meilleurs modèles de Novita AI (comme Qwen3-Coder, Kimi K2, DeepSeek R1) pour l’assistance au codage IA dans votre environnement local ou votre IDE, le processus est simple : récupérez votre clé API, installez l’outil, configurez les variables d’environnement et commencez à coder.
Pour des commandes de configuration détaillées et des exemples, consultez les tutoriels officiels :
- Trae : Guide étape par étape pour accéder aux modèles IA dans votre IDE
- Claude Code:Comment utiliser Kimi-K2 dans Claude Code sur Windows, Mac et Linux
- Qwen Code:Comment utiliser l’API compatible OpenAI dans Qwen Code (configuration en 60s !)
Flux de travail multi-agents avec le SDK OpenAI Agents
Construisez des systèmes multi-agents avancés en intégrant Novita AI avec le SDK OpenAI Agents :
- Prêt à l’emploi : Utilisez les LLM de Novita AI dans tout flux de travail OpenAI Agents.
- Prend en charge les transferts, le routage et l’utilisation d’outils : Concevez des agents qui peuvent déléguer, trier ou exécuter des fonctions, le tout alimenté par les modèles de Novita AI.
- Intégration Python : Définissez simplement le point de terminaison du SDK sur
https://api.novita.ai/v3/openaiet utilisez votre clé API.
Connecter l’API sur des plateformes tierces
API compatible OpenAI : Profitez d’une migration et d’une intégration sans problème avec des outils tels que Cline et Cursor, conçus pour le standard d’API OpenAI.
Hugging Face : Utilisez les modèles dans Spaces, les pipelines ou avec la bibliothèque Transformers via les points de terminaison Novita AI.
Frameworks d’agents et d’orchestration : Connectez facilement Novita AI à des plateformes partenaires comme Continue, AnythingLLM,LangChain, Dify et Langflow via des connecteurs officiels et des guides d’intégration étape par étape.
Qwen3-Next-80B-A3B prouve que l’architecture compte autant que la taille brute. Avec des innovations comme Hybrid Attention et le MoE sparse, il offre des performances qui rivalisent avec son homologue de 235B sur de nombreux benchmarks, tout en proposant une inférence plus rapide, une latence plus faible et une meilleure efficacité. Pour les organisations cherchant à équilibrer coût, vitesse et qualité, le 80B est une alternative solide qui montre que les modèles plus petits, lorsqu’ils sont bien conçus, peuvent tenir tête aux géants.
Foire aux questions
Comment le 80B peut-il concurrencer le 235B sur des benchmarks difficiles ? Le modèle 80B utilise Hybrid Attention et le MoE sparse pour réduire le coût de calcul tout en préservant la capacité du modèle, lui permettant d’égaler ou de dépasser le 235B sur des tâches comme AIME25, LiveBench et LiveCodeBench.
Quel modèle est meilleur pour les documents longs ou les historiques de chat ? Le 235B prend en charge nativement un contexte de 262K à 1M de tokens, mais le 80B gère également jusqu’à 256K tokens efficacement. Pour la plupart des applications réelles, le 80B offre une capacité suffisante avec une vitesse plus élevée et un coût plus faible.
Le 80B est-il mieux aligné sur les préférences humaines ? Oui, sur Arena-Hard v2, Qwen3-Next-80B-A3B Instruct surpasse même le 235B, montrant un alignement plus fort malgré sa taille plus petite.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA grâce à notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle.



