

在多項基準測試中,Qwen3-Next-80B-A3B Instruct 的表現幾乎與 Qwen3-235B-A22B Instruct 持平,儘管其參數數量少得多。這種驚人的效能平衡自然會引發疑問:小模型如何能與巨型模型抗衡?答案就在於兩者的架構創新——本文將為你詳細解析原因。
Qwen3-Next-80B 與 Qwen3-235B 對比:架構核心差異
在多項關鍵基準測試中,Qwen3-Next-80B-A3B Instruct 的表現與 Qwen3-235B-A22B Instruct 持平,在 AIME25、LiveBench 和 LiveCodeBench 上的結果幾乎一致。這樣的效能表現自然讓我們將重點放在兩者的架構差異上
來源:Hugging Face
| 模型 | 總參數量 | 活躍參數量 | 層數 | 專家數量 | 活躍專家數量 | 注意力類型 | 上下文長度 | 模式 | 核心定位 |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-Next-80B-A3B-Instruct | 80B | 3B | 48 | 64 | 2 | 混合(DeltaNet + 門控) | 標準(最高 256K) | Instruct | 輕量推理、日常問答 |
| Qwen3-Next-80B-A3B-Thinking | 80B | 3B | 48 | 64 | 2 | 混合(DeltaNet + 門控) | 標準(最高 256K) | Thinking | 強推理、多步驟問題解決 |
| Qwen3-235B-A22B-Instruct-2507 | 235B | 22B | 94 | 128 | 8 | 混合(DeltaNet + 門控) | 原生 262K,最高可擴展至 1M | Instruct | 大規模容量、更強的長上下文處理能力 |
| Qwen3-235B-A22B-Thinking-2507 | 235B | 22B | 94 | 128 | 8 | 混合(DeltaNet + 門控) | 原生 262K,最高可擴展至 1M | Thinking | 超大規模、強化推理能力 |
Qwen3-Next-80B-A3B 與 Qwen3-235B 對比:小模型為何能穩穩立足
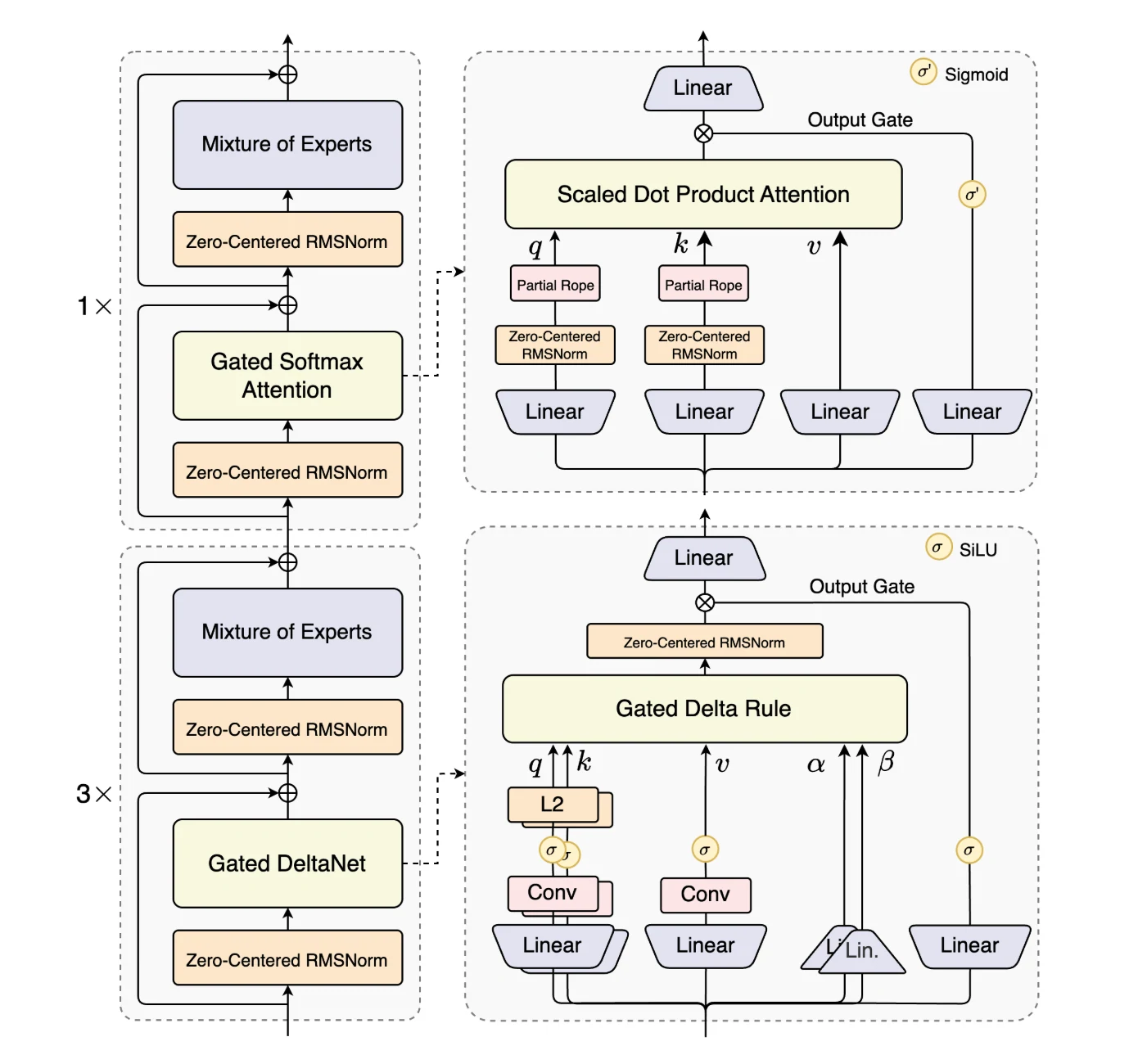
Qwen3-Next-80B-A3B 是 Qwen3-Next 系列的首款模型,憑藉最大化長上下文效率與吞吐量的架構創新脫穎而出。
它引入了混合注意力(Hybrid Attention),結合門控 DeltaNet 與門控注意力取代標準注意力,可在超長序列長度下實現高效的上下文建模。
**高稀疏度專家混合(MoE)**設計大幅降低了活化比例,在保留模型容量的同時降低了每 token 的計算量(FLOPs)。
為確保穩定性,模型整合了穩定性優化技術,例如零中心化、帶權重衰減的層歸一化。
最後,**多 Token 預測(MTP)**提升了預訓練效率並加速推理。這些優化共同作用,使 Qwen3-Next-80B-A3B 能夠以高效、穩定的方式處理大規模長上下文工作負載。
來源:Hugging Face
處理和維持更長上下文的能力直接強化了模型的幾項核心能力:
- 長文件理解
模型可單次處理完整書籍、研究論文或長篇逐字稿,避免因分段處理導致的資訊遺失。 - 跨段落推理
更長的上下文窗口可連接文本中相距較遠的內容,提升邏輯連貫性。 - 複雜任務處理
法律分析、科學研究或多輪對話等應用場景,可受益於跨越多個 token 的細節保留,實現更準確的推理。 - 降低幻覺/內容偏離
保留完整輸入可降低遺忘早期限制條件、或捏造缺失細節的風險。 - 實際應用的擴展性
企業場景——包含長歷史的聊天機器人、使用數千個上下文 token 的檢索增強生成(RAG)、或多模態流程——可直接從穩定的超長序列處理能力中受益。
Qwen3-Next-80B 與 Qwen3-Next-80B-A3B 對比:效能比較
| 類別 | 基準測試 | 80B-A3B-Instruct | 80B-A3B-Thinking | 235B-A22B-Thinking | 最佳表現模型 |
|---|---|---|---|---|---|
| 知識 | MMLU-Pro | 80.6 | 82.7 | 84.4 | 235B-Thinking |
| MMLU-Redux | 90.9 | 92.5 | 93.8 | 235B-Thinking | |
| GPQA | 72.9 | 77.2 | 81.1 | 235B-Thinking | |
| SuperGPQA | 58.8 | 60.8 | 64.9 | 235B-Thinking | |
| 推理 | AIME25 | 69.5 | 87.8 | 92.3 | 235B-Thinking |
| HMMT25 | 54.1 | 73.9 | 83.9 | 235B-Thinking | |
| LiveBench (2024年11月) | 75.8 | 76.6 | 78.4 | 235B-Thinking | |
| 程式碼 | LiveCodeBench v6 | 56.6 | 68.7 | 74.1 | 235B-Thinking |
| MultiPL-E / CFEval* | 87.8 | 2071 (CFEval) | 2134 (CFEval) | 235B-Thinking | |
| OJBench / Aider-Polyglot* | 49.8 (Aider) | 29.7 (OJBench) | 32.5 (OJBench) | 235B-Thinking | |
| 對齊 | IFEval | 87.6 | 88.9 | 88.9(平手) | 80B-Thinking / 235B-Thinking |
| Arena-Hard v2 | 82.7 | 62.3 | 79.7 | 80B-Instruct | |
| WritingBench | 87.3 | 84.6 | 88.3 | 235B-Thinking | |
| 智能體 | BFCL-v3 | 70.3 | 72.0 | 72.4 | 235B-Thinking |
| TAU1-Retail | 60.9 | 69.6 | 67.8 | 80B-Thinking | |
| TAU1-Airline | 44.0 | 49.0 | 46.0 | 80B-Instruct | |
| TAU2-Retail | 57.3 | 67.8 | 71.9 | 235B-Thinking | |
| TAU2-Airline | 45.5 | 60.5 | 58.0 | 80B-Thinking | |
| TAU2-Telecom | 13.2 | 43.9 | 45.6 | 235B-Thinking | |
| 多語言 | MultiIF | 75.8 | 77.8 | 80.6 | 235B-Thinking |
| MMLU-ProX | 76.7 | 78.7 | 81.0 | 235B-Thinking | |
| INCLUDE | 78.9 | 78.9 | 81.0 | 235B-Thinking | |
| PolyMATH | 45.9 | 56.3 | 60.1 | 235B-Thinking |
235B 模型——Qwen3-235B-A22B-Instruct-2507 與 Qwen3-235B-A22B-Thinking-2507——提供了最高的絕對效能,尤其在專業知識、程式碼編寫和高級推理任務上表現突出。
80B 模型的表現遠超其規模預期:
- Qwen3-Next-80B-A3B-Thinking 的推理能力接近 Qwen3-235B-A22B-Thinking-2507,是追求效率與成本效益場景的理想選擇。
- Qwen3-Next-80B-A3B-Instruct 在知識與程式碼任務上與 Qwen3-235B-A22B-Instruct-2507 表現接近,甚至在 Arena-Hard v2 等對齊基準測試中超越了後者。
總結: Qwen3-Next-80B-A3B 在設計上兼顧效率與效能,並未犧牲太多表現。其架構創新——混合注意力、稀疏 MoE 與穩定性優化——讓这个小模型在許多實際任務中能與 235B 同系列模型正面抗衡。
Qwen3-Next-80B 與 Qwen3-235B 對比:推理速度比較
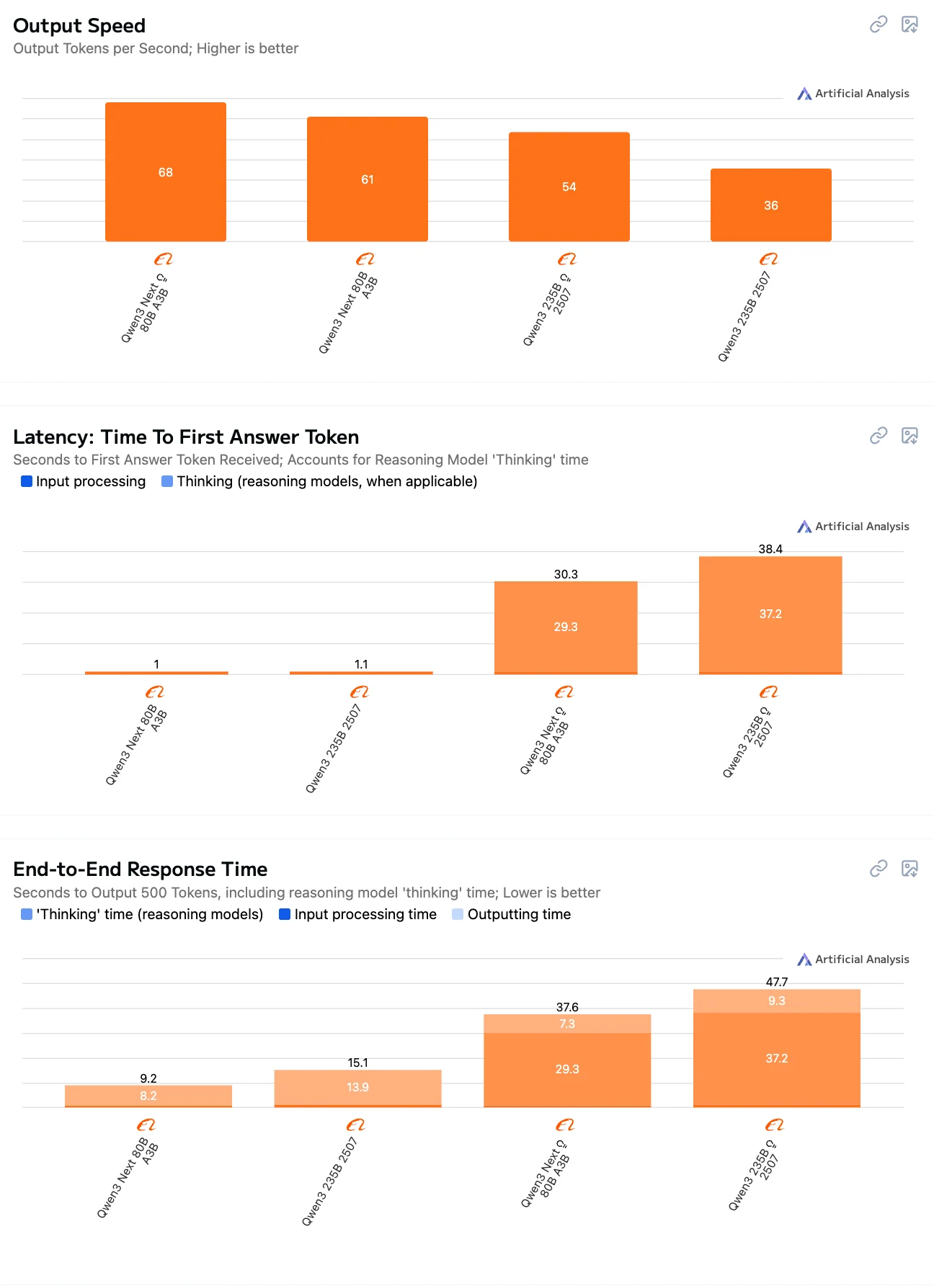
80B-Instruct = 速度 + 低延遲的最佳平衡點。
235B 模型速度更慢,尤其在 Thinking 模式下,原因在於模型規模更大、推理負擔更重。
**Thinking 模型(80B 與 235B 均適用)**相比 Instruct 模式,由於需要執行明確的推理步驟,延遲與端到端耗時都明顯更高。
Qwen3-Next-80B 與 Qwen3-235B 對比:哪個更適合文本生成
小說/虛構寫作
- 需求:豐富的角色細節、長情節線、沉浸式風格、內容連貫。
- 235B:創意細節更豐富,語調更一致,更擅長處理隱喻與複雜內容。
- 80B:長上下文窗口可低成本維持情節連貫;迭代速度更快;連貫性足以滿足多數讀者需求。
科學論文/技術寫作
- 需求:精確性、結構、引用、專業術語、邏輯流暢度。
- 235B:領域知識更紮實,細節準確度更高,推理能力更強。
- 80B:通常足以勝任文獻回顧與常規實驗撰寫,但在細分領域出現小錯誤的風險更高。
對話/聊天敘事
- 需求:多輪對話連貫、記憶能力、人設遵循、回覆速度。
- 235B:在記憶細節與嚴格遵循人設指令方面略勝一籌。
- 80B:回覆速度更快、延遲更低;長上下文處理能力使其在互動聊天場景中表現優異。
創意非虛構/散文/部落格文章
- 需求:事實與風格平衡、結構清晰、說服力。
- 235B:更擅長處理資訊密集、論證複雜的內容。
- 80B:當風格與可讀性比專業精確性更重要時,表現已足夠;草稿修改速度更快。
詩歌/風格化寫作
- 需求:想像力豐富的語言、節奏、細膩的微妙表達。
- 235B:更擅長使用罕見詞彙、創意表達與細膩的語句。
- 80B:能很好地模仿風格,但在罕見隱喻的深度上有時稍遜一籌。
結論
- 若追求頂級精確度與深度(科學寫作、關鍵技術工作、高端創意項目),235B 是更好的選擇。
- 若追求效率、速度與低成本,同時要求穩定的輸出品質——尤其是處理故事、聊天歷史等長輸入場景——80B 往往是更聰明的選擇。
Qwen3-Next-80B 與 Qwen3-235B 對比:哪個更適合聊天機器人應用場景
聊天機器人需求
快速回覆、長歷史對話連貫、指令遵循、基礎推理能力、成本效益。
235B
- 在超大規模對話、專業知識與高難度推理任務上表現優異。
- 缺點:延遲與計算成本更高,若對回覆速度要求高則不適合。
80B
- 延遲更低,回覆速度更快。
- 得益於架構創新,仍能保持良好的指令遵循與上下文處理能力。
- 是互動式、面向使用者的聊天機器人的強力選擇。
核心結論
- 若追求流暢的使用者體驗與快速回覆,80B 通常是更好的選擇。
- 若用於專業或高要求領域,235B 仍可能是首選。
如何存取 Qwen3-Next-80B 與 Qwen3-235B?
1. 網頁介面(最適合初學者)
立即試用 Qwen3-Next-80B-A3B Instruct!
2. API 存取(適合開發者)
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API,方便快速部署 AI 模型。
Qwen3-Next-80B-A3B Instruct 定價為 每百萬輸入 token 0.15 美元、每百萬輸出 token 1.5 美元,支援 65,536 token 的上下文長度。
Qwen3-Next-80B-A3B Thinking 定價同樣為 每百萬輸入 token 0.15 美元、每百萬輸出 token 1.5 美元,上下文長度同樣為 65,536 token。
Qwen3-235B-A22B Thinking-2507 價格更高,為 每百萬輸入 token 0.3 美元、每百萬輸出 token 3 美元,提供 131,072 token 的上下文長度。
Qwen3-235B-A22B Instruct-2507 定價為 每百萬輸入 token 0.15 美元、每百萬輸出 token 0.8 美元,上下文長度為 131,072 token。
步驟 1:登入並進入模型庫
登入你的帳號,點擊 模型庫 按鈕。

步驟 2:選擇你需要的模型
瀏覽所有可選模型,選擇符合你需求的版本。
步驟 3:開始免費試用
開始免費試用,體驗所選模型的能力。
步驟 4:取得 API 金鑰
若要使用 API 進行身份驗證,我們會為你提供新的 API 金鑰。進入「設定」頁面後,即可按照圖中指示複製 API 金鑰。

步驟 5:安裝 API 套件
使用對應程式語言的套件管理器安裝 API 套件。
安裝完成後,將所需庫匯入你的開發環境,使用 API 金鑰初始化 API,即可開始與 Novita AI LLM 互動。以下為 Python 使用者調用聊天補全 API 的範例:
#Chat API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
#Completion API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
prompt="The following is a conversation with an AI assistant.",
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].text)
3. 整合指南
使用 Trae、Claude Code、Qwen Code 等 CLI 工具
若你想在本地環境或 IDE 中使用 Novita AI 的頂級模型(如 Qwen3-Coder、Kimi K2、DeepSeek R1)獲取 AI 編程輔助,流程非常簡單:取得 API 金鑰、安裝對應工具、配置環境變數,即可開始編程。
詳細的設置指令與範例可參考官方教程:
- Trae:在 IDE 中存取 AI 模型的逐步指南
- Claude Code:如何在 Windows、Mac 和 Linux 的 Claude Code 中使用 Kimi-K2
- Qwen Code:如何在 Qwen Code 中使用 OpenAI 相容 API(60 秒完成設置!)
使用 OpenAI Agents SDK 構建多智能體工作流
透過將 Novita AI 與 OpenAI Agents SDK 整合,構建高級多智能體系統:
- 即插即用:可在任何 OpenAI Agents 工作流中使用 Novita AI 的 LLM。
- 支援交接、路由與工具調用:可設計能委派任務、分流處理或執行函式的智能體,所有能力均由 Novita AI 的模型提供。
- Python 整合:只需將 SDK 端點設置為
https://api.novita.ai/v3/openai,並使用你的 API 金鑰即可。
在第三方平台連接 API
OpenAI 相容 API:可無縫遷移並整合至符合 OpenAI API 標準的工具,例如 Cline 與 Cursor。
Hugging Face:可透過 Novita AI 端點,在 Hugging Face Spaces、pipeline 或 Transformers 庫中使用模型。
智能體與編排框架:透過官方連接器與逐步整合指南,可輕鬆將 Novita AI 與合作夥伴平台連接,包括 Continue、AnythingLLM、LangChain、Dify 與 Langflow。
Qwen3-Next-80B-A3B 證明了架構設計的重要性不亞於模型規模。 憑藉混合注意力、稀疏 MoE 等創新技術,它在多項基準測試中的表現可與 235B 同系列模型比肩,同時還具備更快的推理速度、更低的延遲與更高的效率。對於需要平衡成本、速度與品質的組織而言,80B 是一個強力的替代方案,證明了設計優良的小模型也能與巨型模型抗衡。
常見問題
80B 模型如何在困難的基準測試中與 235B 模型競爭?
80B 模型採用混合注意力與稀疏 MoE 技術,在保留模型容量的同時降低了計算成本,使其在 AIME25、LiveBench、LiveCodeBench 等任務上的表現能與 235B 模型持平甚至超越。
處理長文件或聊天歷史時,哪個模型更合適?
235B 原生支援 262K 至 1M token 的上下文長度,但 80B 也能高效處理最高 256K token 的輸入。對於大多數實際應用場景而言,80B 的容量已足夠,且速度更快、成本更低。
80B 模型是否更符合人類偏好?
是的,在 Arena-Hard v2 測試中,Qwen3-Next-80B-A3B Instruct 的表現甚至超越了 235B 模型,證明了儘管規模更小,但其對齊人類偏好的能力更強。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 方便快速部署 AI 模型,同時也提供平價、可靠的 GPU 雲端服務,用於構建與擴展 AI 應用。



