

在多模态人工智能快速发展的领域,开发者面临着持续的挑战:传统语言模型难以理解视觉信息、进行空间推理、与真实世界界面交互,或者处理长而复杂的上下文。这些局限性限制了它们作为能够跨模态感知和决策的真正智能体的能力。
本文介绍 Qwen3-VL,阿里云最先进的 视觉语言模型(VLM),旨在克服这些障碍。通过集成改进的文本理解、视觉推理、空间认知和多模态交互,Qwen3-VL 使 AI 系统能够看、理解、推理和行动。
与 Qwen-VL 或 Qwen2.5-VL 相比,Qwen3-VL 带来了哪些改进?
Qwen3-VL 代表了阿里云最先进的视觉语言模型(VLM)。它升级了文本理解、视觉感知、空间推理和交互智能方面的能力,使 AI 能够跨模态——图像、视频、文本和界面——进行看、理解、推理和行动。
| 问题 | 传统 LLM 的局限性 | Qwen3-VL 的解决方案 |
|---|---|---|
| 1. 缺乏视觉理解 | 纯文本模型无法解读图像或视频。 | 增加 Vision Transformer 编码器和融合层,以理解视觉场景和细节。 |
| 2. 缺乏空间推理 | LLM 无法推理物体位置、遮挡或 3D 关系。 | 集成 2D/3D 空间定位和空间推理模块,支持具身智能。 |
| 3. 无法与真实世界交互 | 模型无法操作软件或 GUI 界面。 | 引入 Visual Agent,可识别按钮、理解功能并执行工具操作。 |
| 4. 上下文长度有限 | 标准模型无法处理长文档或视频。 | 支持 256K–1M token 上下文,可完整回顾长文本和数小时视频。 |
| 5. 多模态推理能力弱 | 模型难以连接文本、数学和视觉数据。 | 增强 跨模态的逻辑和因果推理(STEM、数学、问答)。 |
| 6. 视觉覆盖范围窄 | 仅限于常见物体识别。 | 扩展识别到 人物、产品、地标、动植物、动漫等。 |
| 7. OCR 性能脆弱 | 在模糊、倾斜或多语言情况下失败。 | 将 OCR 扩展到 32 种语言;对噪声、稀有字体和复杂布局鲁棒。 |
| 8. 多模态融合中文本质量下降 | 添加视觉常常削弱文本能力。 | 实现 无损融合——文本理解能力与纯 LLM 相当。 |
您可以直接在 Hugging Face 的网站 UI 上使用 Novita AI,开始免费快速试用!
Qwen3-VL 模型完整指南:24 个开源权重
Qwen3-VL 提供两种基础架构——Dense 和 MoE(专家混合)——支持从 边缘设备到云环境 的灵活部署。
-
模型变体:
- Instruct 版本: 针对指令遵循、问答、摘要和内容生成进行了优化。
- Thinking 版本: 增强用于多步推理和复杂的分析或决策任务。
-
核心组件:
- 文本主干: Qwen3 Transformer 语言模型。
- 视觉编码器: 改进的 ViT(视觉 Transformer),集成 跨模态融合层,实现统一的文本-视觉理解。
| 发布日期 | 模型 | 大小 / 变体 | 模式 |
|---|---|---|---|
| 2025-09-23 | Qwen3-VL-235B-A22B-Instruct / Thinking | 235B 参数(22B 活跃) | MOE |
| 2025-10-04 | Qwen3-VL-30B-A3B-Instruct / Thinking | 30B(3B 活跃) | MOE |
| 2025-10-15 | Qwen3-VL-4B(Instruct/Thinking) Qwen3-VL-8B (Instruct/Thinking) |
4B 和 8B | Dense |
| 2025-10-21 | Qwen3-VL-2B (Instruct/Thinking) Qwen3-VL-32B (Instruct/Thinking) |
2B 和 32B | Dense |
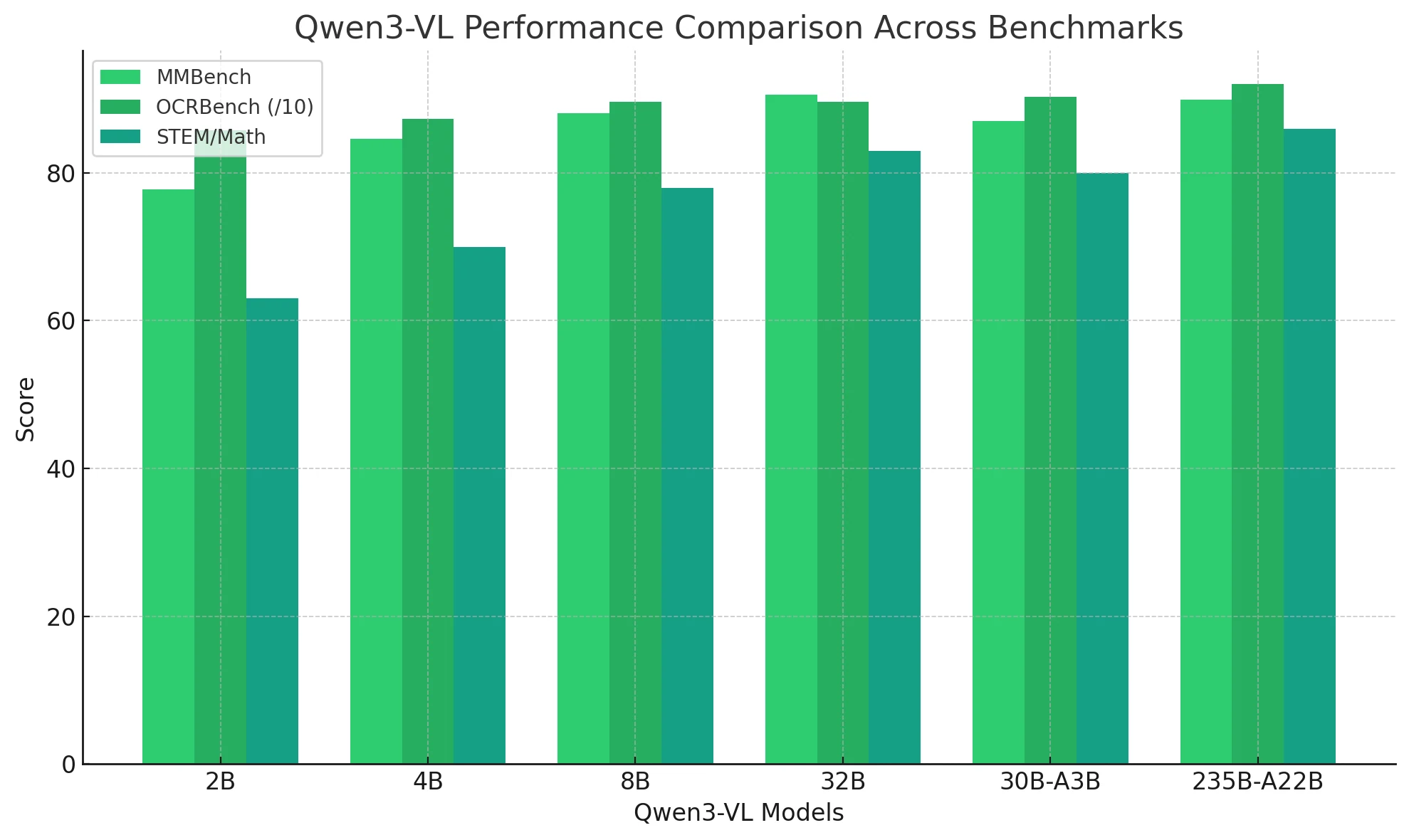
Qwen3-VL 在视觉任务上表现如何?
| 任务维度 | 代表性基准测试 | Qwen3-VL 表现 |
|---|---|---|
| 文本识别 / OCR | OCRBench 850–920 | 在所有模型中领先;对模糊和多语言文本鲁棒。 |
| STEM / 数学推理 | AIME, MathVerse | 从 8B 开始显著提升;235B 平均得分 80+。 |
| 视觉问答(VQA) | MMBench, RealWorldQA | 32B 和 MoE 模型超越 GPT-5 Mini。 |
| 空间和 3D 推理 | EmbSpatialBench > 80 | 强大的 2D/3D 空间感知能力;支持 AR/VR 理解。 |
| 视频理解 | VideoMME, LVBench ≈ 80 | 处理 256K–1M 上下文,用于长达一小时的视频分析。 |
| 智能体能力 | ScreenSpot ≈ 95 | 展示 GUI 操作和工具调用技能。 |
| 编程 / 视觉编程 | Design2Code ≈ 90+ | 将图像转换为可运行的 HTML/CSS/JS 代码。 |
| 多语言理解 | MMLU-ProX ≈ 80 | 与纯 LLM 相当;实现无缝的文本-视觉融合。 |
Qwen3-VL 建立了全频谱的多模态智能系统——在 OCR、推理、视频、空间理解和自主交互方面表现出色。
从 2B 到 235B,性能线性扩展,而 8B 和 30B-A3B 模型提供最佳成本效益。
最终,Qwen3-VL 将 LLM 从语言模型转变为统一的视觉-语言-行动系统,能够跨模态感知、推理和执行。
本地运行 Qwen3-VL 需要什么样的硬件?
| 模型类型 | 硬件要求 | 说明 / 建议 |
|---|---|---|
| 较小变体(4B / 8B) | 本地运行在 单 GPU(推荐 24 – 40 GB VRAM)上。强烈建议在消费级 GPU(如 RTX 4090 / 3090 / A6000)上使用重度量化(INT4 / FP16)。 | 最适合本地开发、研究和边缘部署。 |
| 中等模型(32B) | 需要 ≥ 80 GB VRAM 或 双 GPU 设置。量化可将每个 GPU 内存需求降至 40 GB。 | 适用于本地服务器或云推理。 |
| 旗舰 MoE(Qwen3-VL-30B-A3B / 235B-A22B) | 需要 至少 8 个 GPU,每个 ≥ 80 GB VRAM(例如 A100, H100, H200)。 | 默认设置可能在较小 GPU 上失败;请遵循下面的精度和内存调优指南。 |
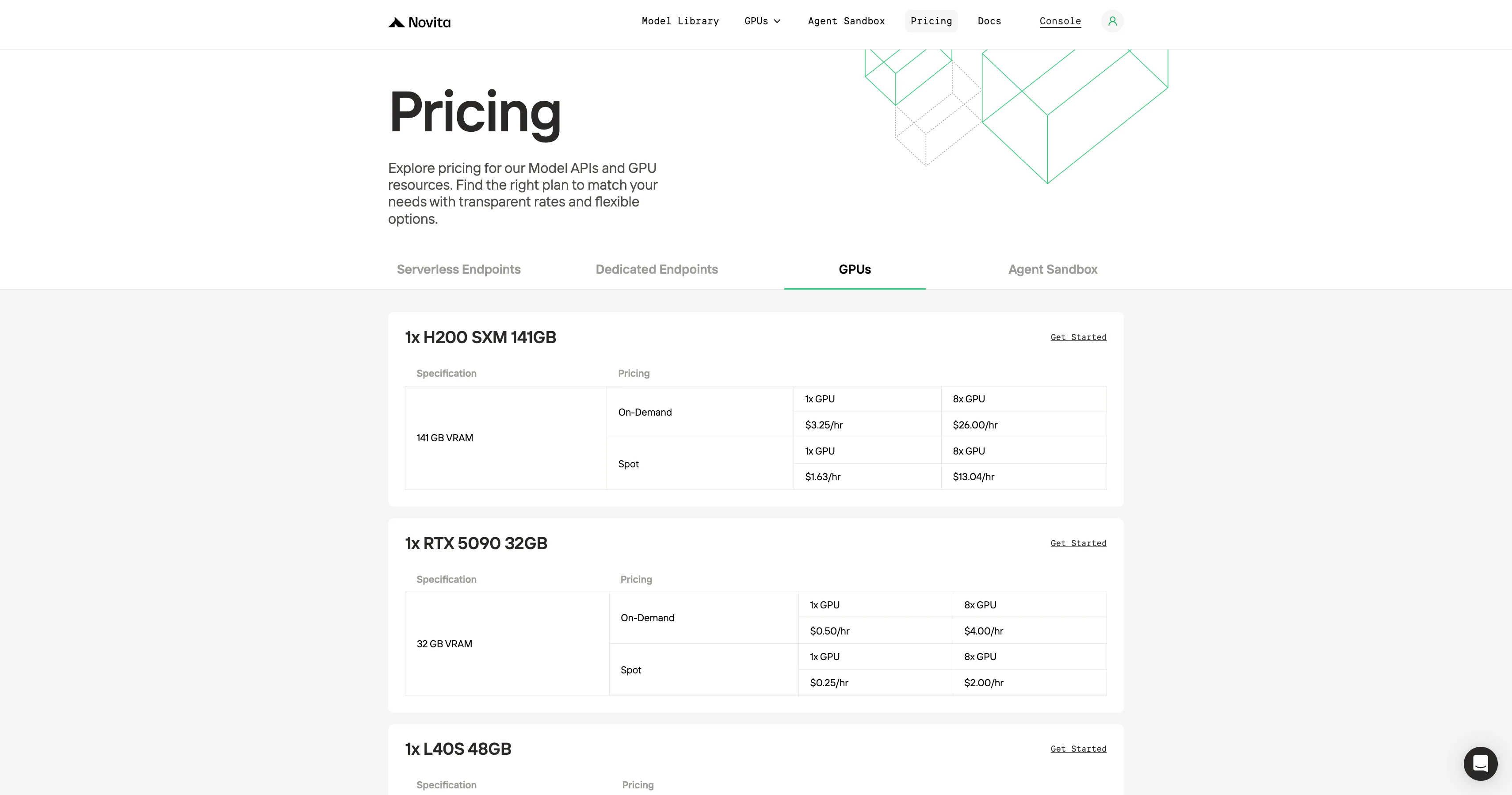
Novita 以其实惠的价格脱颖而出,提供等效的 GPU 成本大约仅为 RunPod 和类似平台的一半。
对于开发者来说,使用 Qwen3-VL 构建多模态智能体有哪些实用见解?
1. 选择适当的变体
- 当任务涉及工作流、UI 自动化或内容生成时,使用 Instruct 变体。
- 当需要深度推理、多步逻辑、STEM/数学处理或空间/视频理解时,使用 Thinking 变体。
- 将模型大小与任务和硬件匹配:较小的变体适用于响应式本地智能体,较大的变体适用于高保真推理或长上下文任务。
2. 构建您的多模态输入和工作流
- 在一次调用中结合不同模态:例如,图像(
"type":"image")+ 文本指令。代码库展示了这种模式。 - 对于视频或长上下文任务,提供图像/帧 + 文本提示,同时对齐时间戳,以利用模型的长时间记忆。
- 当构建操作 GUI 或工具的智能体时:首先捕获截图或 UI 状态,然后提示模型解释并决定操作。GitHub 上的示例代码包括“Mobile Agent”和“Computer-Use Agent”演示。
3. 优化效率和部署
- 启用加速功能(例如 Flash Attention v2),并使用针对重度多模态负载优化的后端。
- 在受限硬件上部署:量化模型或限制模式(例如仅图像输入、有限帧数)以减少内存和计算。社区指南显示了大模型的这种做法。
- 使用批处理、视频的时间采样和内存高效的推理框架(例如 vLLM 配方)来支持长上下文和多帧任务。
4. 设计鲁棒的智能体逻辑和回退
-
当自动化 UI 任务时:包含验证步骤(任务是否成功?如果没有,描述状态)以处理动态布局或失败。
-
对于视觉 + 推理任务:设计提示,明确说明“看什么”、“做什么”以及“如何报告结果”。例如:截图 +“找到‘提交’按钮,点击它,然后总结确认消息。”
-
对于长视频或大型文档任务:构建检索或索引逻辑(例如关键帧提取或子上下文拆分)以保持低延迟并避免内存爆炸。社区文章提到使用关键帧提取来处理一小时长的输入。
-
Qwen3-VL 仅限于图像 + 文本模态吗?还是将来会支持视频、音频和更广泛的多模态输入?
如何访问 Qwen3-VL 系列?
Novita AI 提供 Qwen3-VL 235B Thinking API,上下文窗口为 131K,输入价格 $0.98,输出价格 $3.95。还提供 Qwen3-VL 235BInstruct API,上下文窗口为 131K,输入价格 $0.30,输出价格 $1.50,支持结构化输出和函数调用。
1. 网页界面(初学者最简单)
2. API 访问(面向开发者)
第一步:登录并访问模型库
登录您的账户,点击 模型库 按钮。

第二步:选择您的模型
浏览可用选项,选择适合您需求的模型。

第三步:开始免费试用
开始免费试用,探索所选模型的功能。
第四步:获取您的 API 密钥
为了向 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入“设置”页面,您可以复制 API 密钥,如图所示。

第五步:安装 API
使用您编程语言对应的包管理器安装 API。
安装后,将必要的库导入到您的开发环境中。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是面向 Python 用户的聊天补全 API 示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_UxQ9B4FllYcK6ZwMw6OFh5Q15fFCM4gMHoTbNh4vB3ZF_Dc5yN4RzVXxOHjarOF-AhMO61lRJN8plthUCfFvZA==",
)
model = "qwen/qwen3-vl-235b-a22b-thinking"
stream = True # or False
max_tokens = 16384
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
3. 本地部署(高级用户)
要求:
- Qwen3-VL-235B-A22B:8 个 NVIDIA H200 GPU。
安装步骤:
- 下载模型权重 从 HuggingFace 或 ModelScope
- 选择推理框架:支持 vLLM 或 SGLang
- 遵循官方 GitHub 仓库中的部署指南
4. 集成
使用 CLI,如 Trae, Claude Code, Qwen Code
如果您想在本地环境或 IDE 中使用 Novita AI 的顶级模型(例如 Qwen3-Coder, Kimi K2, DeepSeek R1)进行 AI 编码辅助,过程很简单:获取您的 API 密钥,安装工具,配置环境变量,然后开始编码。
有关详细的设置命令和示例,请查看官方教程:
- Trae : 逐步指南:在您的 IDE 中访问 AI 模型
- Claude Code:如何在 Windows、Mac 和 Linux 上的 Claude Code 中使用 Kimi-K2
- Qwen Code:如何在 Qwen Code 中使用 OpenAI 兼容 API(60 秒设置!)
使用 OpenAI Agents SDK 构建多智能体工作流
通过将 Novita AI 与 OpenAI Agents SDK 集成,构建高级多智能体系统:
- 即插即用: 在任何 OpenAI Agents 工作流中使用 Novita AI 的 LLM。
- 支持交接、路由和工具使用: 设计能够委托、分流或运行函数的智能体,全部由 Novita AI 模型驱动。
- Python 集成: 只需将 SDK 端点设置为
https://api.novita.ai/v3/openai并使用您的 API 密钥。
在第三方平台上连接 API
OpenAI 兼容 API: 享受与 Cline 和 Cursor 等工具的无缝迁移和集成,这些工具专为 OpenAI API 标准设计。
Hugging Face: 在 Spaces、pipelines 或使用 Transformers 库中,通过 Novita AI 端点使用模型。
智能体与编排框架: 通过官方连接器和逐步集成指南,轻松将 Novita AI 与 Continue, AnythingLLM,LangChain, Dify 和 Langflow 等合作伙伴平台连接。
凭借灵活的 Dense 和 MoE 架构,参数规模从 2B 到 235B,Qwen3-VL 既支持本地实验,也支持企业级部署。8B 和 30B-A3B 变体在成本和性能之间取得平衡,而 235B-A22B 模型达到最先进的多模态推理水平。最终,Qwen3-VL 标志着向具身智能迈出了决定性的一步——使开发者能够构建不仅在数字和物理环境中分析信息,还能智能行动的系统。
常见问题
与 Qwen-VL 或 Qwen2.5-VL 相比,Qwen3-VL 有哪些改进?
Qwen3-VL 引入了增强的视觉理解、2D/3D 空间推理、长达 1M token 的长上下文理解能力,以及可以操作软件界面的“Visual Agent”。它还扩展了 OCR 覆盖范围到 32 种语言,并实现了无损的文本-视觉融合。
本地运行 Qwen3-VL 需要什么样的硬件?
较小的模型,如 Qwen3-VL-4B 或 Qwen3-VL-8B,可以在单个 GPU(24 – 40 GB VRAM)上通过量化运行。Qwen3-VL-30B-A3B 和 Qwen3-VL-235B-A22B 至少需要八个 GPU,每个配备 80 GB VRAM(例如 H100 / A100 / H200)。建议 H100 使用 FP8 模式以最大化效率。
Qwen3-VL 在视觉任务上表现如何?
在 MMBench、OCRBench 和 MathVerse 等基准测试中,Qwen3-VL 的表现优于前代产品,OCRBench 得分在 850–920 之间,在 VQA 上超越 GPT-5 Mini。它在空间、视频和 STEM 推理方面表现出色。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的简便途径,同时提供价格实惠且可靠的 GPU 云用于构建和扩展。



