

急速に進化するマルチモーダル人工知能の分野において、開発者は常に課題に直面しています。従来の言語モデルは、視覚情報の理解、空間推論、実際のインターフェースとの対話、あるいは長く複雑なコンテキストの処理が困難です。これらの制限により、モデルが複数のモダリティにわたって認識と意思決定を行える真のインテリジェントエージェントとして機能する能力が制限されています。
本記事では、Alibaba Cloudの最先端ビジョン言語モデル(VLM)であるQwen3-VLを紹介します。このモデルは、これらの障壁を克服するために設計されています。テキスト理解、視覚推論、空間認識、マルチモーダル対話の改善を統合することで、Qwen3-VLはAIシステムが見て、理解し、推論し、行動することを可能にします。
Qwen-VLやQwen2.5-VLと比較して、Qwen3-VLはどのような改良をもたらすのか?
Qwen3-VLは、Alibaba Cloudの最も先進的なビジョン言語モデル(VLM)です。テキスト理解、視覚認識、空間推論、インタラクティブインテリジェンスの機能を向上させ、画像、動画、テキスト、インターフェースといったモダリティを横断して、AIが見て、理解し、推論し、行動することを可能にします。
| 問題 | 従来のLLMの限界 | Qwen3-VLによる解決方法 |
|---|---|---|
| 1. 視覚理解の欠如 | テキストのみのモデルは画像や動画を解釈できない。 | Vision Transformerエンコーダーと融合レイヤーを追加し、視覚シーンや詳細を理解する。 |
| 2. 空間推論の欠如 | LLMは物体の位置、遮蔽、3D関係を推論できない。 | エンボディッドインテリジェンスのための2D/3D空間グラウンディングと空間推論モジュールを統合。 |
| 3. 実世界との対話の欠如 | モデルはソフトウェアやGUIインターフェースを操作できない。 | ボタンを認識し、機能を理解し、ツール操作を実行できるVisual Agentを導入。 |
| 4. コンテキスト長の制限 | 標準モデルは長いドキュメントや動画を処理できない。 | 256K~1Mトークンのコンテキストをサポートし、長文テキストや数時間の動画を完全に記憶。 |
| 5. マルチモーダル推論の弱さ | モデルはテキスト、数学、視覚データを結びつけるのに苦労する。 | モダリティ横断での論理的・因果的推論(STEM、数学、Q&A)を強化。 |
| 6. 狭い視覚カバレッジ | 認識が一般的な物体に限定される。 | 人物、製品、ランドマーク、動植物、アニメなどに認識範囲を拡大。 |
| 7. 脆弱なOCR性能 | ぼやけ、傾き、多言語での認識に失敗する。 | OCRを32言語に拡張。ノイズ、珍しいスクリプト、複雑なレイアウトに対して堅牢。 |
| 8. マルチモーダル融合におけるテキスト品質の低下 | 視覚を追加するとテキスト能力が弱まることが多い。 | ロスレス融合を実現。テキスト理解は純粋なLLMと同等。 |
Hugging FaceのWeb UIでNovita AIを直接使い、無料で迅速なトライアルを開始できます!
Qwen3-VLモデルの完全ガイド:24のオープンソースウェイト
Qwen3-VLは、Denseと**MoE(Mixture of Experts)**という2つの基本アーキテクチャで利用可能であり、エッジデバイスからクラウド環境まで柔軟なデプロイが可能です。
-
モデルバリアント:
- Instruct版: 指示追従、Q&A、要約、コンテンツ生成に最適化。
- Thinking版: 多段階推論や複雑な分析・意思決定タスク向けに強化。
-
コアコンポーネント:
- テキストバックボーン: Qwen3 Transformer言語モデル。
- ビジョンエンコーダー: 改善されたViT(Vision Transformer)をクロスモーダル融合レイヤーと統合し、テキストとビジョンの統合理解を実現。
| リリース日 | モデル | サイズ / バリアント | モード |
|---|---|---|---|
| 2025-09-23 | Qwen3-VL-235B-A22B-Instruct / Thinking | 235Bパラメータ(22Bアクティブ) | MOE |
| 2025-10-04 | Qwen3-VL-30B-A3B-Instruct / Thinking | 30B(3Bアクティブ) | MOE |
| 2025-10-15 | Qwen3-VL-4B(Instruct/Thinking) Qwen3-VL-8B (Instruct/Thinking) |
4B & 8B | Dense |
| 2025-10-21 | Qwen3-VL-2B (Instruct/Thinking) Qwen3-VL-32B (Instruct/Thinking) |
2B & 32B | Dense |
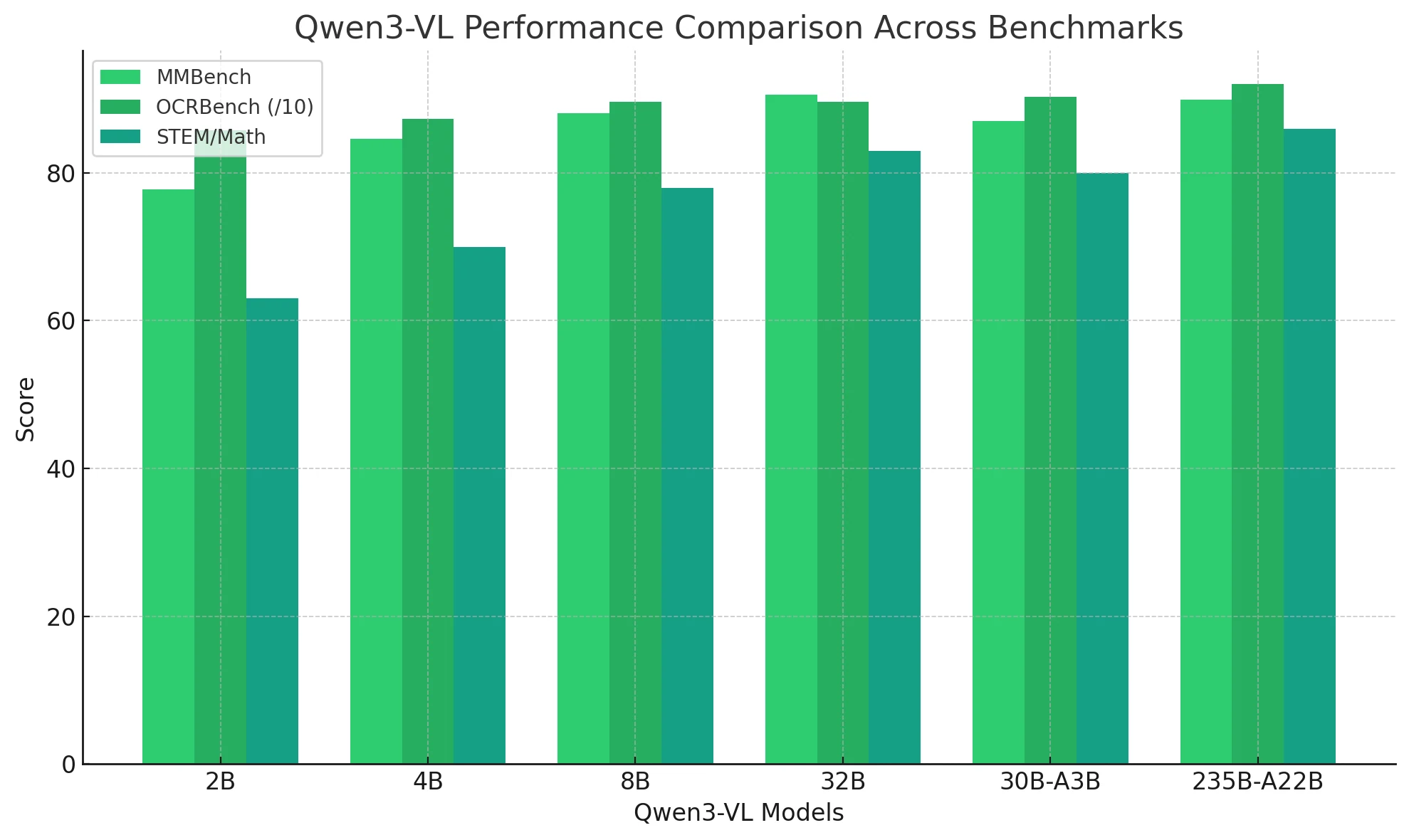
Qwen3-VLは視覚タスクでどのような性能を発揮するか?
| タスク次元 | 代表的なベンチマーク | Qwen3-VLの性能 |
|---|---|---|
| テキスト認識 / OCR | OCRBench 850–920 | 全モデルでトップ。ぼやけや多言語テキストに堅牢。 |
| STEM / 数学的推論 | AIME, MathVerse | 8B以上で大幅改善。235Bは平均80+。 |
| 視覚質問応答(VQA) | MMBench, RealWorldQA | 32BとMoEモデルがGPT-5 Miniを上回る。 |
| 空間および3D推論 | EmbSpatialBench > 80 | 強力な2D/3D空間認識。AR/VR理解をサポート。 |
| 動画理解 | VideoMME, LVBench ≈ 80 | 256K~1Mコンテキストで1時間の動画分析を処理。 |
| エージェント能力 | ScreenSpot ≈ 95 | GUI操作とツール呼び出しスキルを実証。 |
| コーディング / ビジュアルプログラミング | Design2Code ≈ 90+ | 画像を実行可能なHTML/CSS/JSコードに変換。 |
| 多言語理解 | MMLU-ProX ≈ 80 | 純粋なLLMと同等。シームレスなテキスト-ビジョン融合を実現。 |
Qwen3-VLは全スペクトルのマルチモーダルインテリジェンスシステムを確立 — OCR、推論、動画、空間理解、自律的対話において優れています。
2Bから235Bまで、性能は線形にスケーリングし、8Bと30B-A3Bモデルが最良のコスト効率を提供します。
最終的に、Qwen3-VLはLLMを言語モデルから、モダリティを横断して認識、推論、実行できる統合ビジョン言語行動システムへと変革します。
Qwen3-VLをローカルで実行するにはどのようなハードウェアが必要か?
| モデルタイプ | ハードウェア要件 | 注釈 / 推奨事項 |
|---|---|---|
| 小規模バリアント(4B / 8B) | 単一GPU(推奨VRAM 24~40 GB)でローカル実行可能。コンシューマー向けGPU(RTX 4090 / 3090 / A6000など)では、強力な量子化(INT4 / FP16)を強く推奨。 | ローカル開発、研究、エッジデプロイに最適。 |
| 中規模モデル(32B) | ≥ 80 GB VRAMまたはデュアルGPU構成が必要。量子化により、GPUあたり40 GBにメモリ要件を削減可能。 | オンプレミスサーバーまたはクラウド推論に適している。 |
| フラッグシップMoE(Qwen3-VL-30B-A3B / 235B-A22B) | それぞれ**≥ 80 GB VRAMのGPUを少なくとも8台**(例:A100, H100, H200)が必要。 | デフォルト設定では小規模GPUで失敗する可能性あり。以下の精度およびメモリチューニングガイドに従うこと。 |
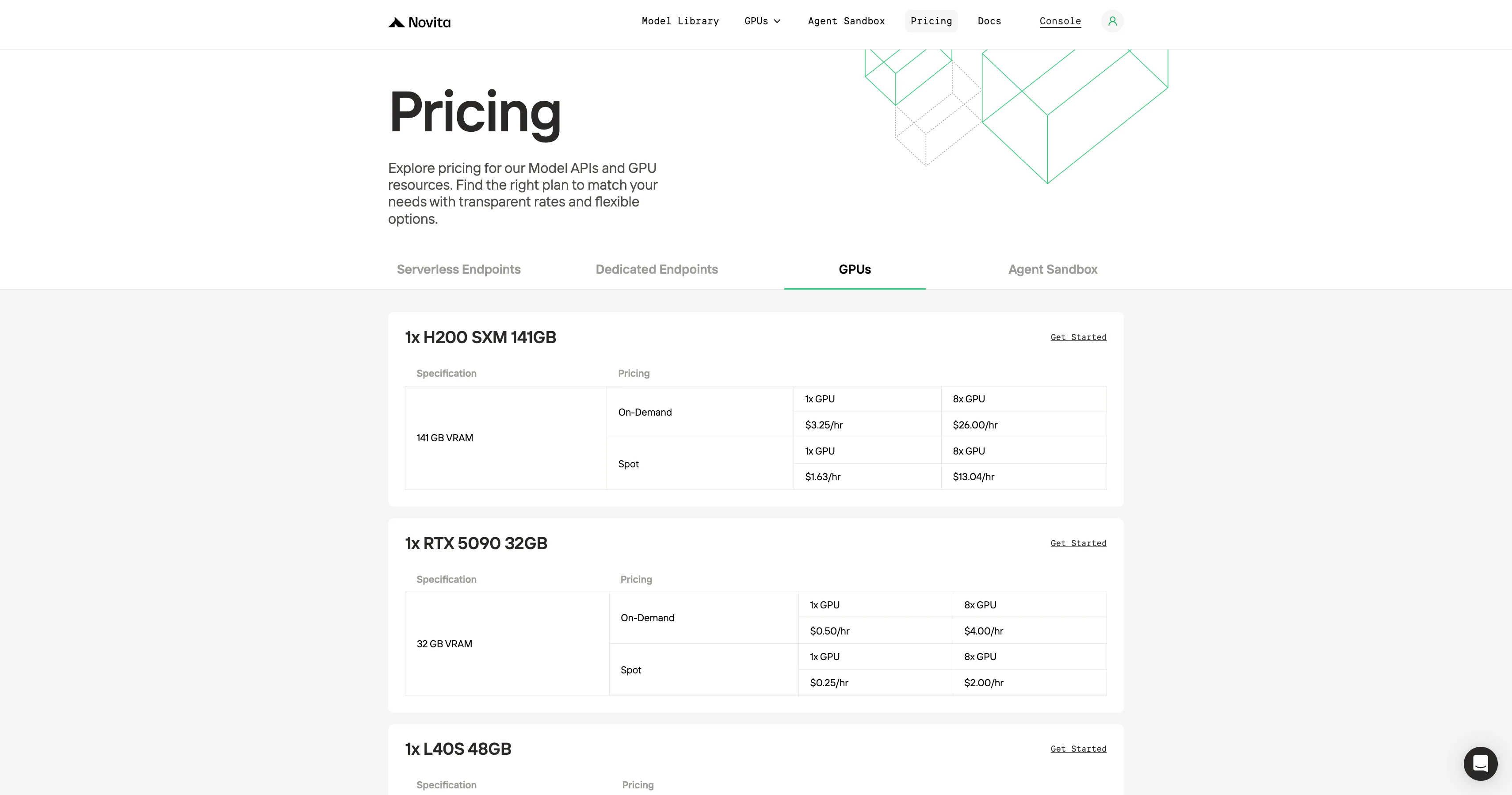
Novita AIは、同等のGPUをRunPodおよび類似プラットフォームの約半分の価格で提供し、手頃な価格で際立っています。
開発者にとって、Qwen3-VLでマルチモーダルエージェントを構築する際の実践的な洞察は?
1. 適切なバリアントの選択
- ワークフロー、UI自動化、コンテンツ生成が中心のタスクでは、Instructバリアントを使用。
- 深い推論、多段階ロジック、STEM/数学処理、空間/動画理解が必要な場合は、Thinkingバリアントを使用。
- タスクとハードウェアに合わせてモデルサイズを選択:応答性の高いローカルエージェントには小規模バリアント、高忠実度の推論や長文コンテキストタスクには大規模バリアント。
2. マルチモーダル入力とワークフローの構造化
- 1回の呼び出しで異なるモダリティを組み合わせる(例:画像(
"type":"image")+テキスト指示)。リポジトリではこのパターンを示している。 - 動画や長文コンテキストタスクの場合、タイムスタンプを合わせた画像/フレーム+テキストキューを提供し、モデルの長期的記憶を活用。
- GUIやツールを操作するエージェントを構築する場合:最初にスクリーンショットまたはUI状態をキャプチャし、モデルに解釈と行動決定を促す。GitHubのサンプルコードには「Mobile Agent」と「Computer-Use Agent」のデモが含まれている。
3. 効率性とデプロイの最適化
- 高速化機能(例:Flash Attention v2)を有効にし、重いマルチモーダル負荷には最適化されたバックエンドを使用。
- 制約のあるハードウェアへのデプロイの場合:モデルを量子化するか、モードを制限(例:画像のみ入力、フレーム数制限)してメモリと計算量を削減。コミュニティガイドで大規模モデル向けの手法が示されている。
- バッチ処理、動画の時間サンプリング、メモリ効率の高い推論フレームワーク(例:vLLMレシピ)を使用して、長文コンテキストや複数フレームのタスクをサポート。
4. 堅牢なエージェントロジックとフォールバックの設計
-
UIタスクを自動化する場合:検証ステップ(タスクは成功したか?そうでなければ状態を説明)を含めて、動的なレイアウトや障害に対処。
-
視覚+推論タスクの場合:「何を見るか」「何をするか」「結果をどのように報告するか」を指定するプロンプトを設計。例:スクリーンショット+「‘送信’ボタンを見つけてクリックし、確認メッセージを要約してください。」
-
長い動画や大規模ドキュメントタスクの場合:レイテンシーを管理しメモリ爆発を避けるために、検索やインデックス作成ロジック(例:キーフレーム抽出やサブコンテキスト分割)を構築。コミュニティ記事では、1時間の入力を処理するためのキーフレーム抽出の使用について言及。
-
Qwen3-VLは画像とテキストのモダリティに限定されているのか、それとも将来的に動画、音声、より広範なマルチモーダル入力をサポートする予定はあるのか?
Qwen3-VLシリーズにアクセスする方法は?
Novita AIは、Qwen3-VL 235B Thinking APIを131Kコンテキストウィンドウで、入力$0.98、出力$3.95で提供しています。また、Qwen3-VL 235BInstruct APIも131Kコンテキストウィンドウで、入力$0.30、出力$1.50で提供し、構造化出力と関数呼び出しをサポートしています。
1. Webインターフェース(初心者に最も簡単)
2. APIアクセス(開発者向け)
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Libraryボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションからニーズに合ったモデルを選択します。

ステップ3:無料トライアルを開始
選択したモデルの機能を試すために無料トライアルを開始します。
ステップ4:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」ページに入り、画像のようにAPIキーをコピーできます。

ステップ5:APIをインストール
ご使用のプログラミング言語に固有のパッケージマネージャーを使用してAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。これは、Pythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_UxQ9B4FllYcK6ZwMw6OFh5Q15fFCM4gMHoTbNh4vB3ZF_Dc5yN4RzVXxOHjarOF-AhMO61lRJN8plthUCfFvZA==",
)
model = "qwen/qwen3-vl-235b-a22b-thinking"
stream = True # or False
max_tokens = 16384
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
3. ローカルデプロイ(上級者向け)
必要条件:
- Qwen3-VL-235B-A22B:NVIDIA H200 GPUを8台。
インストール手順:
- HuggingFaceまたはModelScopeからモデルウェイトをダウンロード
- 推論フレームワークを選択:vLLMまたはSGLangをサポート
- 公式GitHubリポジトリのデプロイガイドに従う
4. 統合
CLI(Trae、Claude Code、Qwen Code)の使用
ローカル環境やIDEでAIコーディング支援のためにNovita AIのトップモデル(Qwen3-Coder、Kimi K2、DeepSeek R1など)を使用したい場合、プロセスは簡単です。APIキーを取得し、ツールをインストールし、環境変数を設定し、コーディングを開始するだけです。
詳細な設定コマンドと例については、公式チュートリアルをご確認ください:
- Trae : IDEでAIモデルにアクセスするためのステップバイステップガイド
- Claude Code:Windows、Mac、LinuxでClaude CodeでKimi-K2を使用する方法
- Qwen Code:Qwen CodeでOpenAI互換APIを使用する方法(60秒セットアップ!)
OpenAI Agents SDKを使用したマルチエージェントワークフロー
Novita AIをOpenAI Agents SDKと統合して、高度なマルチエージェントシステムを構築:
- プラグアンドプレイ: 任意のOpenAI AgentsワークフローでNovita AIのLLMを使用。
- ハンドオフ、ルーティング、ツール使用をサポート: エージェントが委任、トリアージ、関数実行を実行するように設計、すべてNovita AIのモデルを搭載。
- Python統合: SDKエンドポイントを
https://api.novita.ai/v3/openaiに設定し、APIキーを使用するだけ。
サードパーティプラットフォームでのAPI接続
OpenAI互換API: ClineやCursorなどのOpenAI API標準向けに設計されたツールとのシームレスな移行と統合。
Hugging Face: Novita AIエンドポイント経由でSpaces、パイプライン、またはTransformersライブラリでモデルを使用。
エージェント&オーケストレーションフレームワーク: Continue、AnythingLLM,LangChain、Dify、Langflowなどのパートナープラットフォームと、公式コネクタおよびステップバイステップの統合ガイドを通じて簡単に接続。
柔軟なDenseおよびMoEアーキテクチャにより、2Bから235Bパラメータまでスケーリング可能なQwen3-VLは、ローカルでの実験とエンタープライズレベルのデプロイの両方をサポートします。8Bと30B-A3Bバリアントはコストとパフォーマンスのバランスが取れており、235B-A22Bモデルは最先端のマルチモーダル推論を達成します。最終的に、Qwen3-VLはエンボディッドインテリジェンスへの決定的な一歩を示し、開発者が情報を分析するだけでなく、デジタル環境および物理環境内でインテリジェントに行動するシステムを構築できるようにします。
よくある質問
Qwen-VLやQwen2.5-VLと比較して、Qwen3-VLの改良点は何ですか?
Qwen3-VLは、強化された視覚理解、2D/3D空間推論、最大1Mトークンの長文コンテキスト理解、ソフトウェアインターフェースと対話できる「Visual Agent」を導入しています。また、OCRカバレッジを32言語に拡大し、ロスレスのテキスト-ビジョン融合を実現しています。
Qwen3-VLをローカルで実行するにはどのようなハードウェアが必要ですか?
Qwen3-VL-4BやQwen3-VL-8Bなどの小規模モデルは、量子化により単一GPU(VRAM 24~40 GB)で実行できます。Qwen3-VL-30B-A3BとQwen3-VL-235B-A22Bは、それぞれ80 GB VRAMのGPUを少なくとも8台(例:H100 / A100 / H200)必要とします。H100では効率を最大化するためにFP8モードが推奨されます。
Qwen3-VLは視覚タスクでどのような性能を発揮しますか?
MMBench、OCRBench、MathVerseなどのベンチマークで、Qwen3-VLは前世代を上回り、OCRBenchスコア850~920を達成し、VQAでGPT-5 Miniを上回っています。空間、動画、STEM推論に優れています。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、スケーリングのための手頃で信頼性の高いGPUクラウドも提供しています。



