

- En comparación con Qwen-VL o Qwen2.5-VL, ¿qué mejoras introduce Qwen3-VL?
- Guía completa de los modelos Qwen3-VL: 24 pesos de código abierto
- ¿Qué rendimiento tiene Qwen3-VL en tareas visuales?
- ¿Qué tipo de hardware se necesita para ejecutar Qwen3-VL de forma local?
- Para desarrolladores, ¿cuáles son las ideas prácticas para construir agentes multimodales con Qwen3-VL?
- ¿Cómo acceder a la serie Qwen3-VL?
En el campo en rápida evolución de la inteligencia artificial multimodal, los desarrolladores se enfrentan a desafíos persistentes: los modelos de lenguaje tradicionales tienen dificultades para comprender información visual, razonar espacialmente, interactuar con interfaces del mundo real o manejar contextos largos y complejos. Estas limitaciones restringen su capacidad para actuar como verdaderos agentes inteligentes capaces de percepción y toma de decisiones entre modalidades.
Este artículo presenta Qwen3-VL, el modelo de lenguaje y visión (VLM, por sus siglas en inglés) más avanzado de Alibaba Cloud, diseñado para superar estas barreras. Al integrar una comprensión mejorada del texto, razonamiento visual, cognición espacial e interacción multimodal, Qwen3-VL permite que los sistemas de IA vean, comprendan, razonen y actúen.
En comparación con Qwen-VL o Qwen2.5-VL, ¿qué mejoras introduce Qwen3-VL?
Qwen3-VL representa el modelo de lenguaje y visión (VLM) más avanzado de Alibaba Cloud. Mejora las capacidades de comprensión de texto, percepción visual, razonamiento espacial e inteligencia interactiva, permitiendo que la IA vea, comprenda, razone y actúe entre modalidades: imágenes, vídeos, texto e interfaces.
| Problema | Limitación en los LLM tradicionales | Cómo resuelve esto Qwen3-VL |
|---|---|---|
| 1. Falta de comprensión visual | Los modelos solo de texto no pueden interpretar imágenes o vídeos. | Añade un codificador Vision Transformer y capas de fusión para comprender escenas y detalles visuales. |
| 2. Sin razonamiento espacial | Los LLM no pueden razonar sobre posiciones de objetos, oclusiones o relaciones 3D. | Integra anclaje espacial 2D/3D y módulos de razonamiento espacial para inteligencia encarnada. |
| 3. Sin interacción con el mundo real | Los modelos no pueden operar software o interfaces GUI. | Introduce un Agente Visual que puede reconocer botones, comprender funciones y realizar operaciones con herramientas. |
| 4. Límite de contexto corto | Los modelos estándar no pueden procesar documentos o vídeos largos. | Soporta contexto de 256K a 1M tokens, permitiendo la recuperación completa de textos largos y vídeos de varias horas de duración. |
| 5. Razonamiento multimodal débil | Los modelos tienen dificultades para conectar datos de texto, matemáticas y visuales. | Mejora el razonamiento lógico y causal entre modalidades (STEM, matemáticas, preguntas y respuestas). |
| 6. Cobertura visual limitada | El reconocimiento se limita a objetos comunes. | Amplía el reconocimiento a personas, productos, puntos de referencia, flora, fauna, anime, etc. |
| 7. Rendimiento de OCR frágil | Falla en casos de borrosidad, inclinación o multilingüismo. | Extiende el OCR a 32 idiomas; es robusto ante ruido, scripts poco comunes y diseños complejos. |
| 8. Pérdida de calidad del texto en la fusión multimodal | Añadir visión suele debilitar la capacidad de comprensión de texto. | Logra una fusión sin pérdidas: la comprensión del texto es igual a la de los LLM puros. |
¡Puedes usar directamente Novita AI en la interfaz web de Hugging Face para iniciar una prueba gratuita y rápida!
Guía completa de los modelos Qwen3-VL: 24 pesos de código abierto
Qwen3-VL está disponible en dos arquitecturas base: Dense y MoE (Mixtura de Expertos), lo que permite un despliegue flexible desde dispositivos perimetrales hasta entornos en la nube.
- Variantes de modelo:
- Edición Instruct: Optimizada para el seguimiento de instrucciones, preguntas y respuestas, resumen y generación de contenido.
- Edición Thinking: Mejorada para el razonamiento de varios pasos y tareas analíticas o de toma de decisiones complejas.
- Componentes principales:
- Columna vertebral de texto: El modelo de lenguaje Qwen3 Transformer.
- Codificador de visión: Un ViT (Vision Transformer) mejorado integrado con una capa de fusión entre modalidades para una comprensión unificada de texto y visión.
| Fecha de lanzamiento | Modelo | Tamaño / variante | Modo(s) |
|---|---|---|---|
| 2025-09-23 | Qwen3-VL-235B-A22B-Instruct / Thinking | 235B parámetros (22B activos) | MoE |
| 2025-10-04 | Qwen3-VL-30B-A3B-Instruct / Thinking | 30B (3B activos) | MoE |
| 2025-10-15 | Qwen3-VL-4B(Instruct/Thinking) Qwen3-VL-8B (Instruct/Thinking) |
4B y 8B | Dense |
| 2025-10-21 | Qwen3-VL-2B (Instruct/Thinking) Qwen3-VL-32B (Instruct/Thinking) |
2B y 32B | Dense |
¿Qué rendimiento tiene Qwen3-VL en tareas visuales?
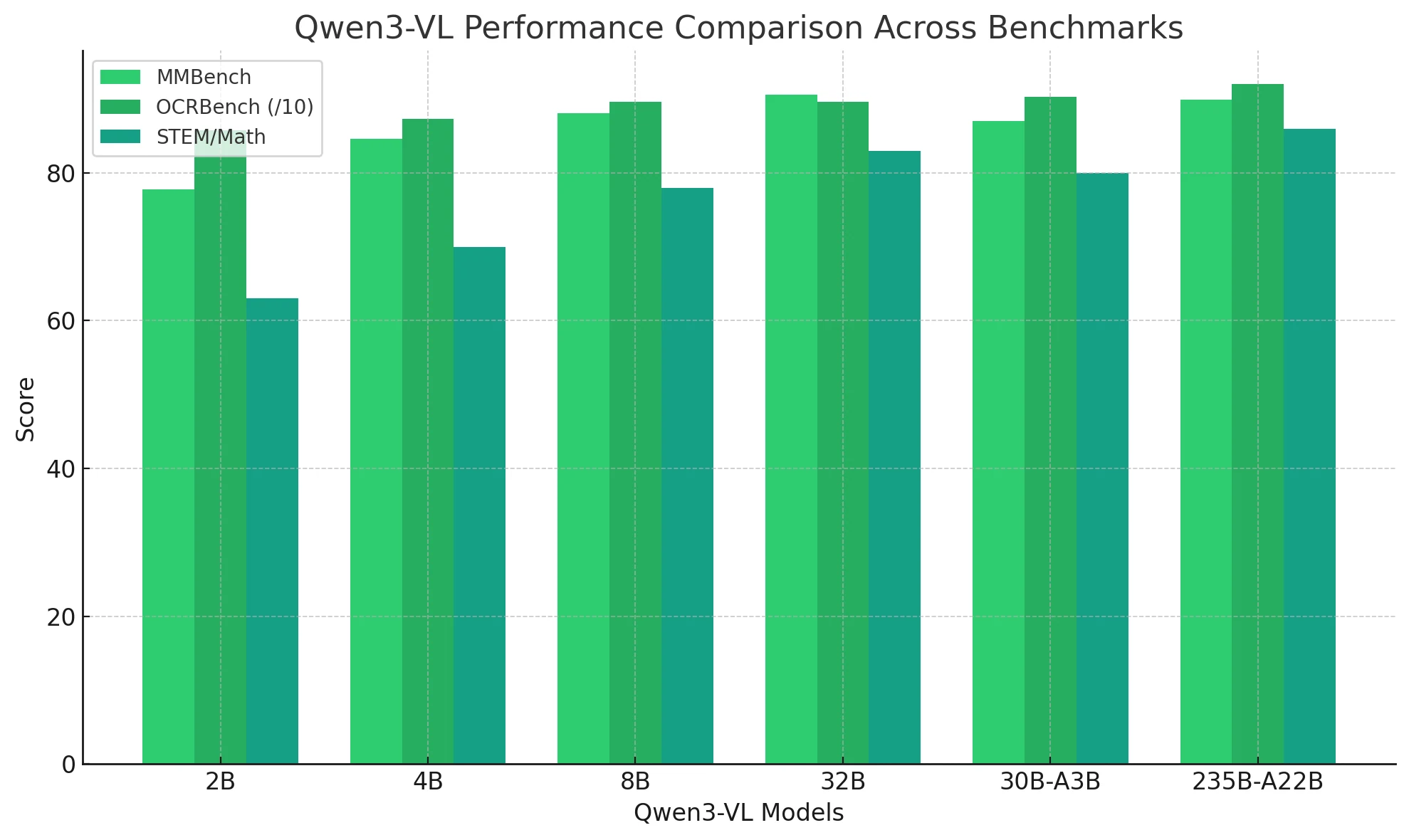
| Dimensión de la tarea | Referencia representativa | Rendimiento de Qwen3-VL |
|---|---|---|
| Reconocimiento de texto / OCR | OCRBench 850–920 | Lidera entre todos los modelos; robusto ante borrosidad y texto multilingüe. |
| Razonamiento STEM / matemático | AIME, MathVerse | Mejora significativa a partir de 8B; el modelo de 235B promedia más de 80. |
| Respuesta a preguntas visuales (VQA) | MMBench, RealWorldQA | Los modelos de 32B y MoE superan a GPT-5 Mini. |
| Razonamiento espacial y 3D | EmbSpatialBench > 80 | Fuerte percepción espacial 2D/3D; soporta comprensión de RA/RV. |
| Comprensión de vídeo | VideoMME, LVBench ≈ 80 | Gestiona contextos de 256K a 1M tokens para análisis de vídeos de varias horas de duración. |
| Capacidad de agente | ScreenSpot ≈ 95 | Demuestra habilidades de operación de GUI y llamada a herramientas. |
| Programación / programación visual | Design2Code ≈ 90+ | Convierte imágenes en código HTML/CSS/JS ejecutable. |
| Comprensión multilingüe | MMLU-ProX ≈ 80 | Está a la par de los LLM puros; logra una fusión perfecta entre texto y visión. |
Qwen3-VL establece un sistema de inteligencia multimodal de espectro completo: destaca en OCR, razonamiento, vídeo, comprensión espacial e interacción autónoma.
Desde 2B hasta 235B, el rendimiento escala de forma lineal, mientras que los modelos 8B y 30B-A3B ofrecen la mejor relación costo-rendimiento.
En última instancia, Qwen3-VL transforma los LLM de modelos de lenguaje a sistemas unificados de visión-lenguaje-acción capaces de percepción, razonamiento y ejecución entre modalidades.
¿Qué tipo de hardware se necesita para ejecutar Qwen3-VL de forma local?
| Tipo de modelo | Requisito de hardware | Notas / Recomendaciones |
|---|---|---|
| Variantes pequeñas (4B / 8B) | Se ejecutan de forma local en una única GPU (se recomiendan 24 a 40 GB de VRAM). Se recomienda encarecidamente una cuantización pesada (INT4 / FP16) para GPUs de consumo como RTX 4090 / 3090 / A6000. | Ideal para desarrollo local, investigación y despliegue perimetral. |
| Modelos de gama media (32B) | Requieren ≥ 80 GB de VRAM o una configuración de doble GPU. La cuantización puede reducir las necesidades de memoria a 40 GB por GPU. | Adecuado para servidores locales o inferencia en la nube. |
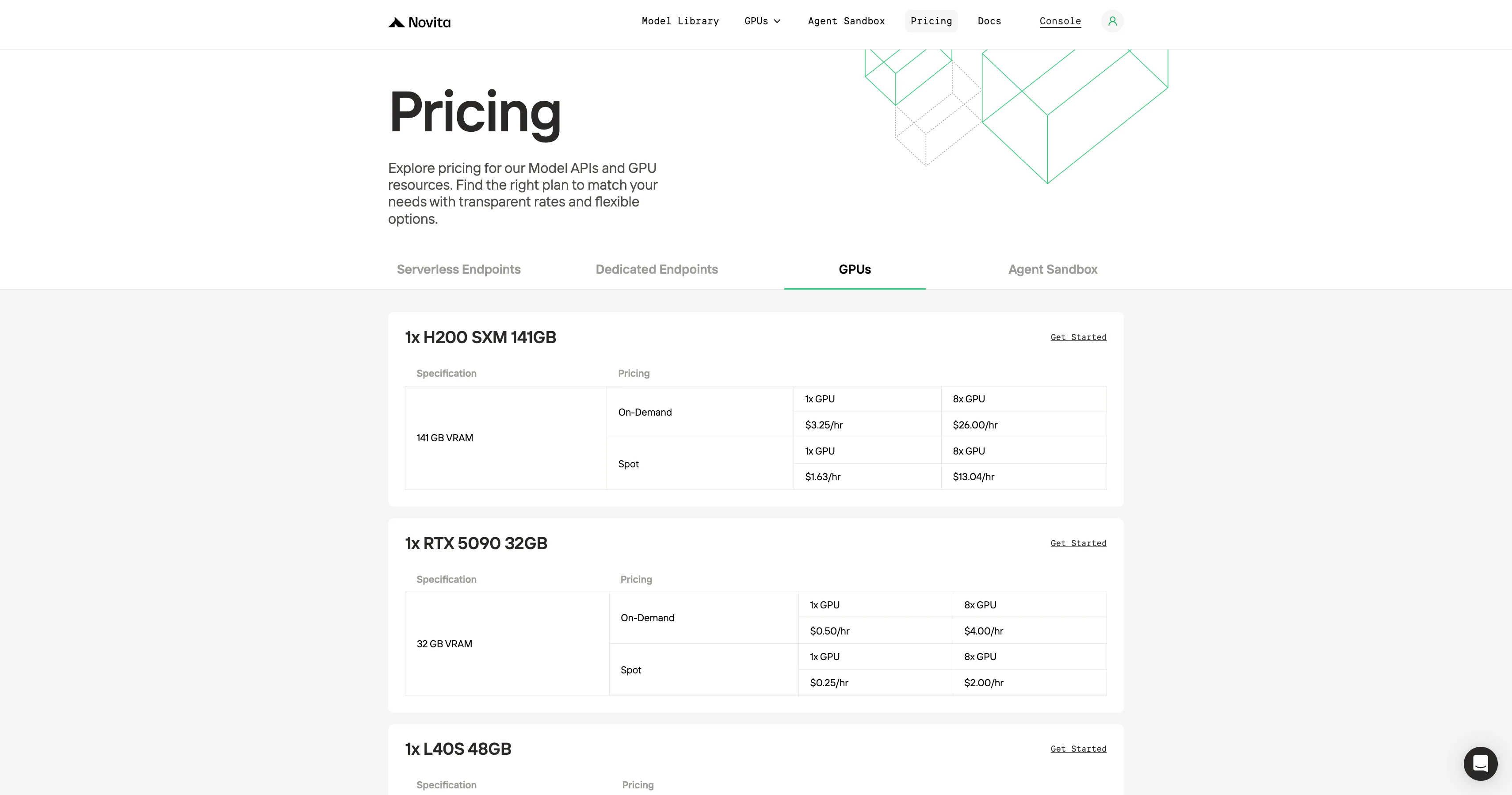
| MoE insignia (Qwen3-VL-30B-A3B / 235B-A22B) | Necesita al menos 8 GPUs, cada una con ≥ 80 GB de VRAM (por ejemplo, A100, H100, H200). | La configuración predeterminada puede fallar en GPUs más pequeñas; sigue la guía de ajuste de precisión y memoria a continuación. |
Novita destaca por su asequibilidad, ofreciendo GPUs equivalentes a aproximadamente la mitad del precio de RunPod y plataformas similares.
¿Puedes comprobar si este es el precio más bajo?
Para desarrolladores, ¿cuáles son las ideas prácticas para construir agentes multimodales con Qwen3-VL?
1. Elige la variante adecuada
- Usa la variante Instruct cuando la tarea implique flujos de trabajo, automatización de interfaces de usuario o generación de contenido.
- Usa la variante Thinking cuando necesites razonamiento profundo, lógica de varios pasos, procesamiento de STEM/matemáticas o comprensión espacial/de vídeo.
- Adapta el tamaño del modelo a la tarea y al hardware: variantes más pequeñas para agentes locales responsivos, variantes más grandes para razonamiento de alta fidelidad o tareas de contexto largo.
2. Estructura tus entradas y flujo de trabajo multimodales
- Combina diferentes modalidades en una sola llamada: por ejemplo, imagen (
"type":"image") + instrucciones de texto. El repositorio muestra este patrón. - Para tareas de vídeo o contexto largo, proporciona imágenes/fotogramas + indicaciones de texto con alineación de marcas de tiempo para aprovechar la memoria de largo alcance del modelo.
- Al construir agentes que operan GUIs o herramientas: primero captura una captura de pantalla o el estado de la interfaz, luego pide al modelo que interprete y decida una acción. El código de ejemplo en GitHub incluye demostraciones de “Agente Móvil” y “Agente de Uso de Ordenador”.
3. Optimiza para eficiencia y despliegue
- Habilita funciones de aceleración (por ejemplo, Flash Attention v2) y usa backends optimizados para cargas multimodales pesadas.
- Para el despliegue en hardware con recursos limitados: cuantiza el modelo o restringe el modo (por ejemplo, entrada solo de imagen, fotogramas limitados) para reducir el uso de memoria y computación. Las guías de la comunidad muestran esto para modelos grandes.
- Usa procesamiento por lotes, muestreo temporal para vídeos y marcos de inferencia eficientes en memoria (como las recetas de vLLM) para soportar tareas de contexto largo y múltiples fotogramas.
4. Diseña una lógica de agente robusta y mecanismos de respaldo
-
Al automatizar tareas de interfaz de usuario: incluye pasos de verificación (¿Tuvo éxito la tarea? Si no, describe el estado) para manejar diseños dinámicos o fallos.
-
Para tareas de visión + razonamiento: diseña indicaciones que especifiquen “qué mirar”, “qué hacer” y “cómo informar el resultado”. Ejemplo: captura de pantalla + “Encuentra el botón ‘Enviar’, haz clic en él, luego resume el mensaje de confirmación.”
-
Para tareas de vídeos largos o documentos grandes: construye lógica de recuperación o indexación (por ejemplo, extracción de fotogramas clave o división de subcontextos) para mantener la latencia controlada y evitar explosiones de memoria. El artículo de la comunidad menciona el uso de extracción de fotogramas clave para manejar entradas de una hora de duración.
-
¿Qwen3-VL está limitado a modalidades de imagen + texto, o soportará entradas de vídeo, audio y otras modalidades más amplias en el futuro?
¿Cómo acceder a la serie Qwen3-VL?
Novita AI ofrece APIs de Qwen3-VL 235B Thinking con una ventana de contexto de 131K a $0,98 por entrada y $3,95 por salida. También proporciona APIs de Qwen3-VL 235BInstruct con una ventana de contexto de 131K a $0,30 por entrada y $1,50 por salida, con soporte para salidas estructuradas y llamadas a funciones.*
1. Interfaz web (la más fácil para principiantes)
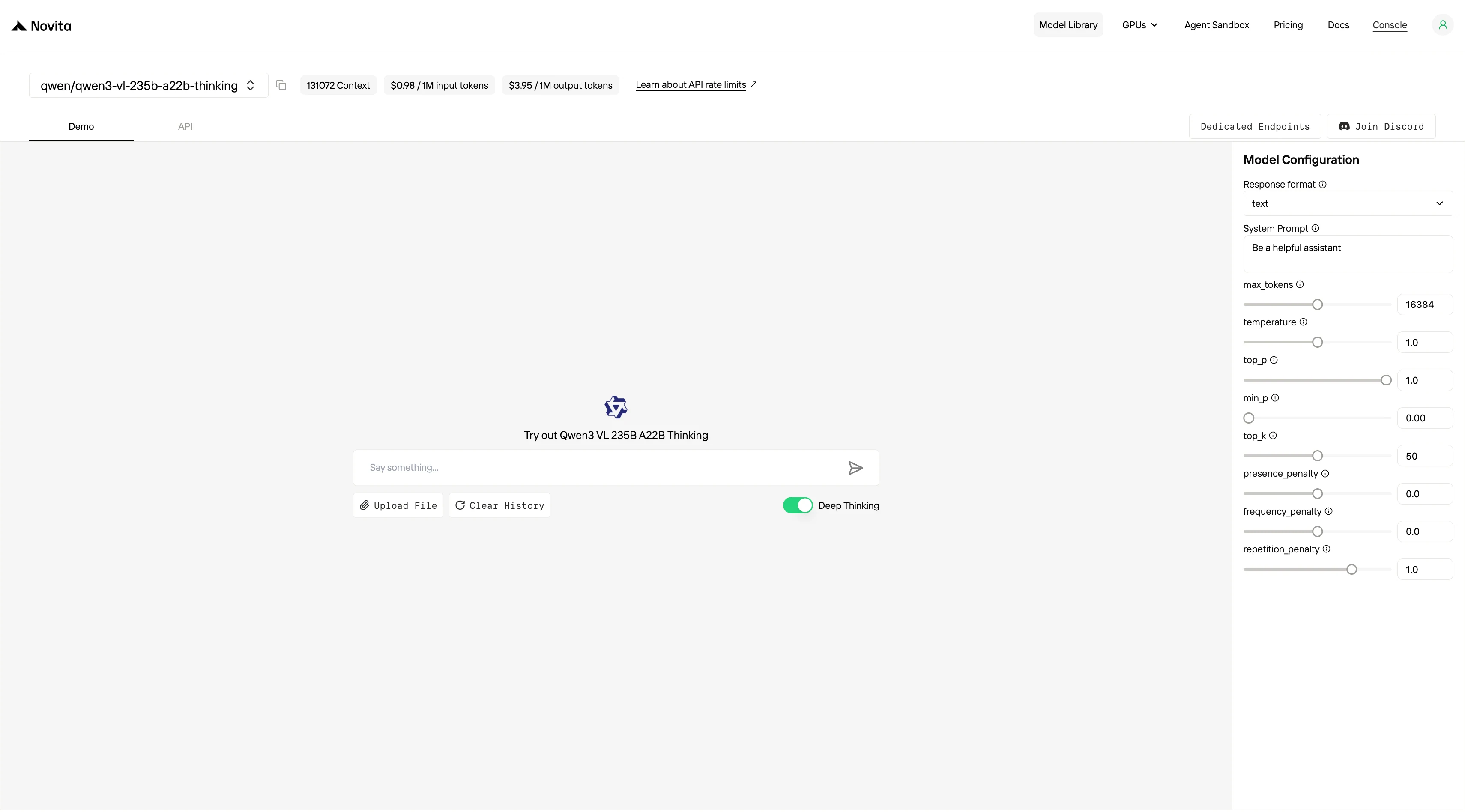
¡Prueba Qwen 3 VL 235B A22B ahora!
2. Acceso a API (para desarrolladores)
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Al entrar en la página de “Configuración”, puedes copiar la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con el LLM de Novita AI. Este es un ejemplo de uso de la API de finalización de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_UxQ9B4FllYcK6ZwMw6OFh5Q15fFCM4gMHoTbNh4vB3ZF_Dc5yN4RzVXxOHjarOF-AhMO61lRJN8plthUCfFvZA==",
)
model = "qwen/qwen3-vl-235b-a22b-thinking"
stream = True # or False
max_tokens = 16384
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
3. Despliegue local (usuarios avanzados)
Requisitos:
- Qwen3-VL-235B-A22B: 8 GPUs NVIDIA H200.
Pasos de instalación:
- Descarga los pesos del modelo desde HuggingFace o ModelScope
- Elige el framework de inferencia: se soporta vLLM o SGLang
- Sigue la guía de despliegue en el repositorio oficial de GitHub
4. Integración
Uso de CLI como Trae, Claude Code, Qwen Code
Si quieres usar los modelos principales de Novita AI (como Qwen3-Coder, Kimi K2, DeepSeek R1) para asistencia de codificación con IA en tu entorno local o IDE, el proceso es sencillo: obtén tu clave de API, instala la herramienta, configura las variables de entorno y empieza a programar.
Para obtener comandos de configuración detallados y ejemplos, consulta los tutoriales oficiales:
- Trae: Guía paso a paso para acceder a modelos de IA en tu IDE
- Claude Code: Cómo usar Kimi-K2 en Claude Code en Windows, Mac y Linux
- Qwen Code: Cómo usar la API compatible con OpenAI en Qwen Code (¡configuración en 60 segundos!)
Flujos de trabajo multiagente con el SDK de OpenAI Agents
Construye sistemas multiagente avanzados integrando Novita AI con el SDK de OpenAI Agents:
- Plug and play: Usa los LLM de Novita AI en cualquier flujo de trabajo de OpenAI Agents.
- Soporta transferencias, enrutamiento y uso de herramientas: Diseña agentes que puedan delegar, clasificar o ejecutar funciones, todo impulsado por los modelos de Novita AI.
- Integración con Python: Simplemente establece el endpoint del SDK en
https://api.novita.ai/v3/openaiy usa tu clave de API.
Conecta la API en plataformas de terceros
API compatible con OpenAI: Disfruta de una migración e integración sin complicaciones con herramientas como Cline y Cursor, diseñadas para el estándar de API de OpenAI.
Hugging Face: Usa los modelos en Spaces, pipelines o con la librería Transformers a través de los endpoints de Novita AI.
Frameworks de agentes y orquestación: Conecta fácilmente Novita AI con plataformas asociadas como Continue, AnythingLLM,LangChain, Dify y Langflow a través de conectores oficiales y guías de integración paso a paso.
Con arquitecturas flexibles Dense y MoE, escalando desde 2B hasta 235B parámetros, Qwen3-VL soporta tanto experimentación local como despliegue a nivel empresarial. Las variantes 8B y 30B-A3B equilibran costo y rendimiento, mientras que el modelo 235B-A22B alcanza el razonamiento multimodal de última generación. En última instancia, Qwen3-VL supone un paso decisivo hacia la inteligencia encarnada: permite a los desarrolladores construir sistemas que no solo analizan información, sino que actúan de forma inteligente en entornos digitales y físicos.
Preguntas frecuentes
En comparación con Qwen-VL o Qwen2.5-VL, ¿qué mejoras introduce Qwen3-VL?
Qwen3-VL introduce una comprensión visual mejorada, razonamiento espacial 2D/3D, comprensión de contexto largo de hasta 1M de tokens y un “Agente Visual” que puede interactuar con interfaces de software. También amplía la cobertura de OCR a 32 idiomas y logra una fusión sin pérdidas entre texto y visión.
¿Qué hardware se necesita para ejecutar Qwen3-VL de forma local?
Los modelos más pequeños como Qwen3-VL-4B o Qwen3-VL-8B se pueden ejecutar en una única GPU (24 a 40 GB de VRAM) con cuantización. Qwen3-VL-30B-A3B y Qwen3-VL-235B-A22B requieren al menos ocho GPUs, cada una con 80 GB de VRAM (por ejemplo, H100 / A100 / H200). Se recomienda el modo FP8 para H100 para maximizar la eficiencia.
¿Qué rendimiento tiene Qwen3-VL en tareas visuales?
En referencias como MMBench, OCRBench y MathVerse, Qwen3-VL supera a las generaciones anteriores, logrando puntuaciones de OCRBench entre 850 y 920 y superando a GPT-5 Mini en VQA. Destaca en razonamiento espacial, de vídeo y STEM.
Novita AI es una plataforma de IA en la nube que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA mediante nuestra API simple, además de proporcionar una nube de GPUs asequible y fiable para construir y escalar.



