

- Comparado com o Qwen-VL ou o Qwen2.5-VL, quais melhorias o Qwen3-VL traz?
- Guia Completo dos Modelos Qwen3-VL: 24 Pesos de Código Aberto
- Como o Qwen3-VL se desempenha em tarefas visuais?
- Que tipo de hardware é necessário para executar o Qwen3-VL localmente?
- Para desenvolvedores, quais são os insights práticos na construção de agentes multimodais com o Qwen3-VL?
- Como acessar a série Qwen3-VL?
No campo em rápida evolução da inteligência artificial multimodal, os desenvolvedores enfrentam desafios persistentes: os modelos de linguagem tradicionais têm dificuldade para entender informações visuais, raciocinar espacialmente, interagir com interfaces do mundo real ou lidar com contextos longos e complexos. Essas limitações restringem sua capacidade de atuar como verdadeiros agentes inteligentes capazes de percepção e tomada de decisão entre diferentes modalidades.
Este artigo apresenta o Qwen3-VL, o Modelo de Visão e Linguagem (VLM) mais avançado da Alibaba Cloud, projetado para superar essas barreiras. Ao integrar compreensão de texto aprimorada, raciocínio visual, cognição espacial e interação multimodal, o Qwen3-VL permite que sistemas de IA vejam, entendam, raciocinem e ajam.
Comparado com o Qwen-VL ou o Qwen2.5-VL, quais melhorias o Qwen3-VL traz?
O Qwen3-VL representa o Modelo de Visão e Linguagem (VLM) mais avançado da Alibaba Cloud. Ele atualiza as capacidades de compreensão de texto, percepção visual, raciocínio espacial e inteligência interativa, permitindo que a IA veja, entenda, raciocine e aja entre diferentes modalidades — imagens, vídeos, texto e interfaces.
| Problema | Limitação em LLMs Tradicionais | Como o Qwen3-VL resolve isso |
|---|---|---|
| 1. Falta de compreensão visual | Modelos apenas de texto não conseguem interpretar imagens ou vídeos. | Adiciona um codificador Vision Transformer e camadas de fusão para entender cenas e detalhes visuais. |
| 2. Sem raciocínio espacial | LLMs não conseguem raciocinar sobre posições de objetos, oclusão ou relações 3D. | Integra ancoragem espacial 2D/3D e módulos de raciocínio espacial para inteligência incorporada. |
| 3. Sem interação com o mundo real | Modelos não conseguem operar softwares ou interfaces GUI. | Introduz um Agente Visual que pode reconhecer botões, entender funções e realizar operações com ferramentas. |
| 4. Limite de contexto curto | Modelos padrão não conseguem processar documentos longos ou vídeos. | Suporta contexto de 256K a 1M tokens, permitindo a recuperação completa de textos longos e vídeos de várias horas. |
| 5. Raciocínio multimodal fraco | Modelos têm dificuldade para conectar dados de texto, matemática e visuais. | Aprimora o raciocínio lógico e causal entre modalidades (STEM, Matemática, Perguntas e Respostas). |
| 6. Cobertura visual limitada | Reconhecimento restrito a objetos comuns. | Expande o reconhecimento para pessoas, produtos, pontos turísticos, flora, fauna, anime, etc. |
| 7. Desempenho de OCR frágil | Falha em casos de desfoque, inclinação ou multilíngue. | Estende o OCR para 32 idiomas; robusto a ruídos, scripts raros e layouts complexos. |
| 8. Perda de qualidade de texto na fusão multimodal | Adicionar visão geralmente enfraquece a capacidade de texto. | Alcança fusão sem perdas — compreensão de texto igual a de LLMs puros. |
Você pode usar diretamente o Novita AI no Hugging Face na interface do site para iniciar um teste gratuito e rápido!
Guia Completo dos Modelos Qwen3-VL: 24 Pesos de Código Aberto
O Qwen3-VL está disponível em duas arquiteturas base — Densa e MoE (Mistura de Especialistas) — permitindo implantação flexível de dispositivos de borda a ambientes de nuvem.
- Variantes de modelo:
- Edição Instruct: Otimizada para seguir instruções, Perguntas e Respostas, sumarização e geração de conteúdo.
- Edição Thinking: Aprimorada para raciocínio de múltiplos passos e tarefas analíticas complexas ou de tomada de decisão.
- Componentes principais:
- Estrutura de texto: O modelo de linguagem Qwen3 Transformer.
- Codificador de visão: Um ViT (Vision Transformer) aprimorado integrado a uma camada de fusão cross-modal para compreensão unificada de texto e visão.
| Data de lançamento | Modelo | Tamanho / variante | Modo(s) |
|---|---|---|---|
| 2025-09-23 | Qwen3-VL-235B-A22B-Instruct / Thinking | 235B parâmetros (22B ativos) | MoE |
| 2025-10-04 | Qwen3-VL-30B-A3B-Instruct / Thinking | 30B (3B ativos) | MoE |
| 2025-10-15 | Qwen3-VL-4B(Instruct/Thinking) Qwen3-VL-8B (Instruct/Thinking) |
4B e 8B | Denso |
| 2025-10-21 | Qwen3-VL-2B (Instruct/Thinking) Qwen3-VL-32B (Instruct/Thinking) |
2B e 32B | Denso |
Como o Qwen3-VL se desempenha em tarefas visuais?
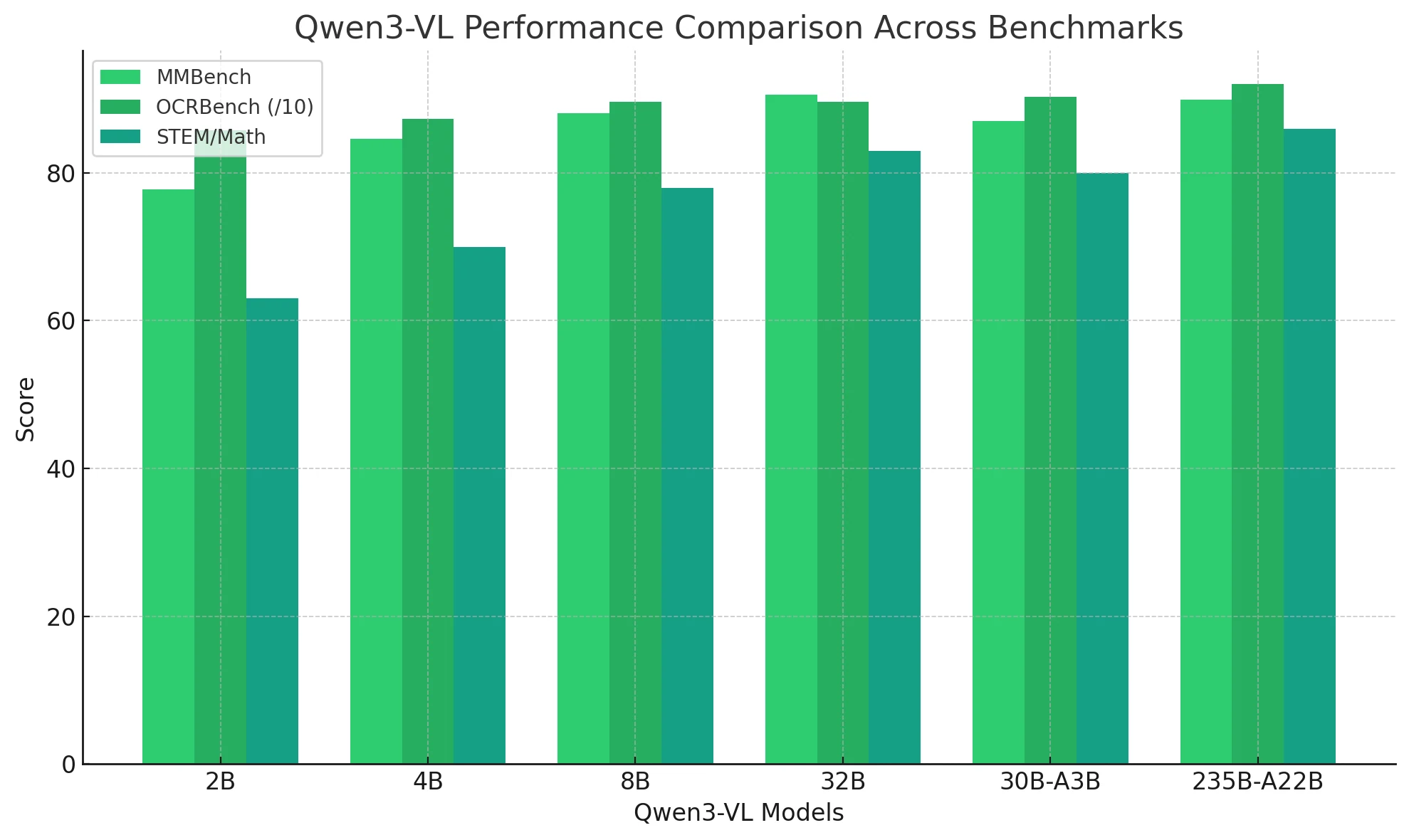
| Dimensão da tarefa | Benchmark representativo | Desempenho do Qwen3-VL |
|---|---|---|
| Reconhecimento de texto / OCR | OCRBench 850–920 | Líder entre todos os modelos; robusto a desfoque e texto multilíngue. |
| Raciocínio STEM / Matemático | AIME, MathVerse | Melhoria significativa a partir de 8B; o modelo de 235B tem média superior a 80. |
| Resposta a Perguntas Visuais (VQA) | MMBench, RealWorldQA | Os modelos de 32B e MoE superam o GPT-5 Mini. |
| Raciocínio espacial e 3D | EmbSpatialBench > 80 | Forte percepção espacial 2D/3D; suporta compreensão de AR/VR. |
| Compreensão de vídeo | VideoMME, LVBench ≈ 80 | Lida com contexto de 256K a 1M tokens para análise de vídeos de uma hora ou mais. |
| Capacidade de agente | ScreenSpot ≈ 95 | Demonstra habilidades de operação de GUI e chamada de ferramentas. |
| Programação / Programação visual | Design2Code ≈ 90+ | Converte imagens em código HTML/CSS/JS executável. |
| Compreensão multilíngue | MMLU-ProX ≈ 80 | Em pé de igualdade com LLMs puros; alcança fusão perfeita entre texto e visão. |
O Qwen3-VL estabelece um sistema de inteligência multimodal de espectro completo — se destacando em OCR, raciocínio, vídeo, compreensão espacial e interação autônoma.
De 2B a 235B, o desempenho escala linearmente, enquanto os modelos 8B e 30B-A3B oferecem a melhor relação custo-benefício.
Em última análise, o Qwen3-VL transforma LLMs de modelos de linguagem em sistemas unificados de visão-linguagem-ação capazes de percepção, raciocínio e execução entre diferentes modalidades.
Que tipo de hardware é necessário para executar o Qwen3-VL localmente?
| Tipo de modelo | Requisito de hardware | Observações / Recomendações |
|---|---|---|
| Variantes menores (4B / 8B) | Executam localmente em uma única GPU (recomenda-se 24 a 40 GB de VRAM). Quantização pesada (INT4 / FP16) é fortemente recomendada para GPUs de consumo como RTX 4090 / 3090 / A6000. | Melhor para desenvolvimento local, pesquisa e implantação em borda. |
| Modelos de faixa intermediária (32B) | Requerem ≥ 80 GB de VRAM ou configuração de duas GPUs. A quantização pode reduzir as necessidades de memória para 40 GB por GPU. | Adequados para servidores locais ou inferência em nuvem. |
| MoE principal (Qwen3-VL-30B-A3B / 235B-A22B) | Necessita de pelo menos 8 GPUs, cada uma com ≥ 80 GB de VRAM (ex: A100, H100, H200). | Configurações padrão podem falhar em GPUs menores; siga as orientações de ajuste de precisão e memória abaixo. |
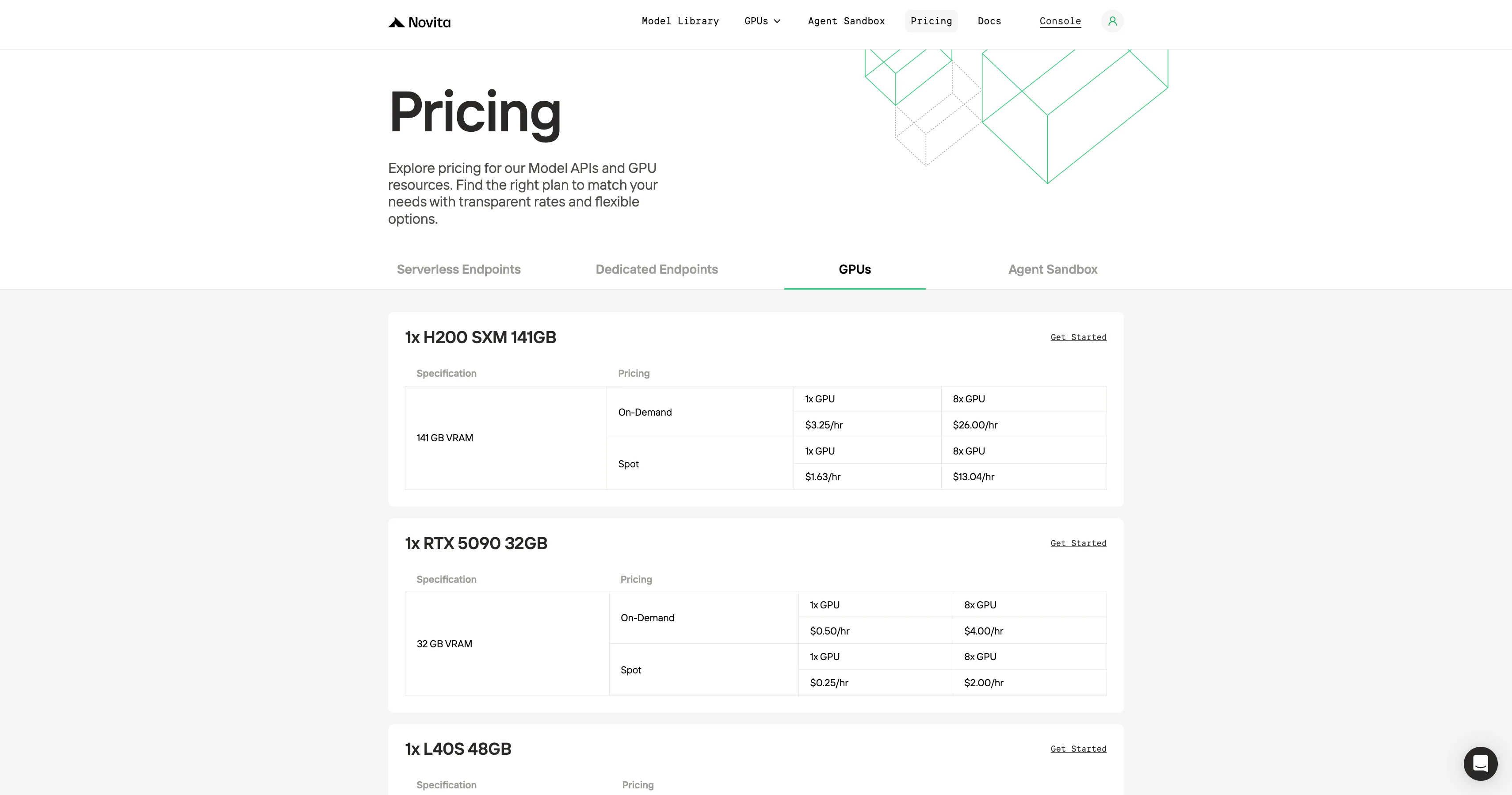
A Novita se destaca pela sua acessibilidade, oferecendo GPUs equivalentes a aproximadamente metade do preço do RunPod e plataformas similares…
Você pode verificar se este é o menor preço?
Para desenvolvedores, quais são os insights práticos na construção de agentes multimodais com o Qwen3-VL?
1. Escolha a variante apropriada
- Use a variante Instruct quando a tarefa envolve fluxos de trabalho, automação de interface de usuário ou geração de conteúdo.
- Use a variante Thinking quando precisar de raciocínio profundo, lógica de múltiplos passos, processamento de STEM/matemática ou compreensão espacial/de vídeo.
- Combine o tamanho do modelo com a tarefa e o hardware: variantes menores para agentes locais responsivos, maiores para raciocínio de alta fidelidade ou tarefas de contexto longo.
2. Estruture suas entradas multimodais e fluxo de trabalho
- Combine diferentes modalidades em uma única chamada: ex: imagem (
"type":"image") + instruções de texto. O repositório mostra esse padrão. - Para tarefas de vídeo ou contexto longo, forneça imagens/frames + dicas de texto com alinhamento de carimbo de data/hora para aproveitar a memória de longo prazo do modelo.
- Ao construir agentes que operam GUIs ou ferramentas: primeiro capture uma captura de tela ou o estado da interface de usuário, depois solicite ao modelo que interprete e decida uma ação. O código de exemplo no GitHub inclui demonstrações de “Agente Móvel” e “Agente de Uso de Computador”.
3. Otimize para eficiência e implantação
- Habilite recursos de aceleração (ex: Flash Attention v2) e use backends otimizados para cargas multimodais pesadas.
- Para implantação em hardware com restrições: quantize o modelo ou restrinja o modo (ex: entrada apenas de imagem, frames limitados) para reduzir memória e poder de computação. Os guias da comunidade mostram isso para modelos grandes.
- Use processamento em lote, amostragem temporal para vídeos e estruturas de inferência com uso eficiente de memória (como as receitas do vLLM) para suportar tarefas de contexto longo e múltiplos frames.
4. Projete lógica de agente robusta e fallbacks
-
Ao automatizar tarefas de interface de usuário: inclua etapas de verificação (A tarefa foi concluída? Se não, descreva o estado) para lidar com layouts dinâmicos ou falhas.
-
Para tarefas de visão + raciocínio: projete prompts que especifiquem “o que observar”, “o que fazer” e “como relatar o resultado”. Exemplo: captura de tela + “Encontre o botão ‘Enviar’, clique nele, depois resuma a mensagem de confirmação.”
-
Para tarefas de vídeo longo ou documentos grandes: construa lógica de recuperação ou indexação (ex: extração de frames-chave ou divisão de subcontextos) para manter a latência gerenciável e evitar explosão de memória. Um artigo da comunidade menciona o uso de extração de frames-chave para lidar com entradas de uma hora ou mais.
-
O Qwen3-VL está limitado a modalidades de imagem + texto, ou suportará vídeo, áudio e entradas multimodais mais amplas no futuro?
Como acessar a série Qwen3-VL?
A Novita AI oferece APIs do Qwen3-VL 235B Thinking com uma janela de contexto de 131K por $0,98 por entrada e $3,95 por saída. Ela também fornece APIs do Qwen3-VL 235BInstruct com janela de contexto de 131K por $0,30 por entrada e $1,50 por saída, suportando saídas estruturadas e chamadas de função.
1. Interface Web (Mais fácil para iniciantes)
Experimente o Qwen 3 VL 235B A22B agora!
2. Acesso via API (Para desenvolvedores)
Passo 1: Faça login e acesse a biblioteca de modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha seu modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie seu teste gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha sua chave de API
Para autenticar com a API, forneceremos uma nova chave de API para você. Acessando a página de “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_UxQ9B4FllYcK6ZwMw6OFh5Q15fFCM4gMHoTbNh4vB3ZF_Dc5yN4RzVXxOHjarOF-AhMO61lRJN8plthUCfFvZA==",
)
model = "qwen/qwen3-vl-235b-a22b-thinking"
stream = True # or False
max_tokens = 16384
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
3. Implantação local (Usuários avançados)
Requisitos:
- Qwen3-VL-235B-A22B: 8 NVIDIA H200 GPUs.
Etapas de instalação:
- Baixe os pesos do modelo no HuggingFace ou no ModelScope
- Escolha a estrutura de inferência: vLLM ou SGLang são suportados
- Siga o guia de implantação no repositório oficial do GitHub
4. Integração
Usando CLI como Trae, Claude Code, Qwen Code
Se você quiser usar os principais modelos da Novita AI (como Qwen3-Coder, Kimi K2, DeepSeek R1) para assistência de codificação de IA no seu ambiente local ou IDE, o processo é simples: obtenha sua chave de API, instale a ferramenta, configure as variáveis de ambiente e comece a codificar.
Para comandos de configuração detalhados e exemplos, consulte os tutoriais oficiais:
- Trae : Guia passo a passo para acessar modelos de IA na sua IDE
- Claude Code:Como usar o Kimi-K2 no Claude Code no Windows, Mac e Linux
- Qwen Code:Como usar a API compatível com OpenAI no Qwen Code (configuração em 60s!)
Fluxos de trabalho de múltiplos agentes com o SDK OpenAI Agents
Construa sistemas avançados de múltiplos agentes integrando a Novita AI com o SDK OpenAI Agents:
- Plug-and-play: Use os LLMs da Novita AI em qualquer fluxo de trabalho do OpenAI Agents.
- Suporta transferências, roteamento e uso de ferramentas: Projete agentes que possam delegar, triar ou executar funções, todos alimentados pelos modelos da Novita AI.
- Integração com Python: Basta definir o endpoint do SDK como
https://api.novita.ai/v3/openaie usar sua chave de API.
Conecte a API em plataformas de terceiros
API compatível com OpenAI: Aproveite uma migração e integração sem complicações com ferramentas como Cline e Cursor, projetadas para o padrão de API do OpenAI.
Hugging Face: Use modelos nos Spaces, pipelines ou com a biblioteca Transformers via endpoints da Novita AI.
Estruturas de agente e orquestração: Conecte facilmente a Novita AI com plataformas parceiras como Continue, AnythingLLM,LangChain, Dify e Langflow por meio de conectores oficiais e guias de integração passo a passo.
Com arquiteturas flexíveis Densa e MoE, escalando de 2B a 235B parâmetros, o Qwen3-VL suporta tanto experimentação local quanto implantação em nível empresarial. As variantes 8B e 30B-A3B equilibram custo e desempenho, enquanto o modelo 235B-A22B alcança o raciocínio multimodal de última geração. Em última análise, o Qwen3-VL marca um passo decisivo em direção à inteligência incorporada — permitindo que desenvolvedores construam sistemas que não apenas analisam informações, mas agem de forma inteligente em ambientes digitais e físicos.
Perguntas Frequentes
Comparado com o Qwen-VL ou o Qwen2.5-VL, quais melhorias o Qwen3-VL traz O Qwen3-VL introduz compreensão visual aprimorada, raciocínio espacial 2D/3D, compreensão de contexto longo de até 1M de tokens e um “Agente Visual” que pode interagir com interfaces de software. Ele também expande a cobertura de OCR para 32 idiomas e alcança fusão sem perdas entre texto e visão.
Que hardware é necessário para executar o Qwen3-VL localmente? Modelos menores como o Qwen3-VL-4B ou o Qwen3-VL-8B podem ser executados em uma única GPU (24 a 40 GB de VRAM) com quantização. Os modelos Qwen3-VL-30B-A3B e Qwen3-VL-235B-A22B requerem pelo menos oito GPUs, cada uma com 80 GB de VRAM (ex: H100 / A100 / H200). O modo FP8 é recomendado para H100 para maximizar a eficiência.
Como o Qwen3-VL se desempenha em tarefas visuais? Em benchmarks como MMBench, OCRBench e MathVerse, o Qwen3-VL supera gerações anteriores, atingindo pontuações no OCRBench entre 850 e 920 e superando o GPT-5 Mini em VQA. Ele se destaca em raciocínio espacial, de vídeo e STEM.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.



