

- Verglichen mit Qwen-VL oder Qwen2.5-VL: Welche Verbesserungen bietet Qwen3-VL?
- Vollständiger Leitfaden zu Qwen3-VL-Modellen: 24 Open-Source-Gewichte
- Wie schneidet Qwen3-VL bei visuellen Aufgaben ab?
- Welche Hardware wird benötigt, um Qwen3-VL lokal auszuführen?
- Für Entwickler: Welche praktischen Erkenntnisse gibt es beim Erstellen multimodaler Agenten mit Qwen3-VL?
- Wie greifen Sie auf die Qwen3-VL-Serie zu?
Im sich schnell entwickelnden Bereich der multimodalen künstlichen Intelligenz stehen Entwickler vor anhaltenden Herausforderungen: Traditionelle Sprachmodelle haben Schwierigkeiten, visuelle Informationen zu verstehen, räumlich zu schlussfolgern, mit realen Schnittstellen zu interagieren oder lange und komplexe Kontexte zu verarbeiten. Diese Einschränkungen schränken ihre Fähigkeit ein, als echte intelligente Agenten zu fungieren, die in der Lage sind, über Modalitäten hinweg wahrzunehmen und Entscheidungen zu treffen.
Dieser Artikel stellt Qwen3-VL vor, Alibaba Clouds fortschrittlichstes Vision-Language-Modell (VLM), das entwickelt wurde, um diese Hürden zu überwinden. Durch die Integration von verbessertem Textverständnis, visueller Schlussfolgerung, räumlicher Kognition und multimodaler Interaktion ermöglicht Qwen3-VL KI-Systemen zu sehen, zu verstehen, zu schlussfolgern und zu handeln.
Verglichen mit Qwen-VL oder Qwen2.5-VL: Welche Verbesserungen bietet Qwen3-VL?
Qwen3-VL stellt Alibaba Clouds fortschrittlichstes Vision-Language-Modell (VLM) dar. Es erweitert die Fähigkeiten in den Bereichen Textverständnis, visuelle Wahrnehmung, räumliche Schlussfolgerung und interaktive Intelligenz, sodass KI über Modalitäten hinweg – Bilder, Videos, Texte und Schnittstellen – sehen, verstehen, schlussfolgern und handeln kann.
| Problem | Einschränkung bei traditionellen LLMs | Wie Qwen3-VL das Problem löst |
|---|---|---|
| 1. Fehlendes visuelles Verständnis | Text-only-Modelle können Bilder oder Videos nicht interpretieren. | Integriert einen Vision-Transformer-Encoder und Fusionsschichten, um visuelle Szenen und Details zu verstehen. |
| 2. Keine räumliche Schlussfolgerung | LLMs können keine Schlussfolgerungen über Objektpositionen, Verdeckungen oder 3D-Beziehungen ziehen. | Integriert 2D/3D-räumliche Verankerung und räumliche Schlussfolgerungsmodule für verkörperte Intelligenz. |
| 3. Keine Interaktion mit der realen Welt | Modelle können keine Software oder GUI-Schnittstellen bedienen. | Führt einen Visuellen Agenten ein, der Schaltflächen erkennen, Funktionen verstehen und Tool-Operationen durchführen kann. |
| 4. Kurze Kontextgrenze | Standardmodelle können keine langen Dokumente oder Videos verarbeiten. | Unterstützt 256K–1M-Token-Kontext, sodass lange Texte und stundenlange Videos vollständig abgerufen werden können. |
| 5. Schwache multimodale Schlussfolgerung | Modelle haben Schwierigkeiten, Text, Mathematik und visuelle Daten zu verknüpfen. | Verbessert die logische und kausale Schlussfolgerung über Modalitäten hinweg (STEM, Mathematik, Q&A). |
| 6. Eingeschränkte visuelle Abdeckung | Erkennung beschränkt auf gängige Objekte. | Erweitert die Erkennung auf Menschen, Produkte, Wahrzeichen, Flora, Fauna, Anime usw. |
| 7. Fragile OCR-Leistung | Versagt bei Unschärfe, Neigung oder mehrsprachigen Fällen. | Erweitert OCR auf 32 Sprachen; robust gegenüber Rauschen, seltenen Schriften und komplexen Layouts. |
| 8. Verlust der Textqualität bei multimodaler Fusion | Das Hinzufügen von visuellen Inhalten schwächt oft die Textfähigkeit. | Erreicht verlustfreie Fusion – das Textverständnis ist mit dem von reinen LLMs vergleichbar. |
Sie können Novita AI direkt auf Hugging Face in der Website-Oberfläche verwenden, um eine kostenlose und schnelle Testversion zu starten!
Vollständiger Leitfaden zu Qwen3-VL-Modellen: 24 Open-Source-Gewichte
Qwen3-VL ist in zwei Basisarchitekturen verfügbar – Dense und MoE (Mixture of Experts) – und ermöglicht so eine flexible Bereitstellung von Edge-Geräten bis zu Cloud-Umgebungen.
- Modellvarianten:
- Instruct-Edition: Optimiert für die Befolgung von Anweisungen, Q&A, Zusammenfassung und Inhaltsgenerierung.
- Thinking-Edition: Erweitert für mehrstufige Schlussfolgerung und komplexe analytische oder Entscheidungsaufgaben.
- Kernkomponenten:
- Text-Backbone: Das Sprachmodell Qwen3 Transformer.
- Vision-Encoder: Ein verbesserter ViT (Vision Transformer), integriert mit einer cross-modalen Fusionsschicht für ein einheitliches Text-Vision-Verständnis.
| Veröffentlichungsdatum | Modell | Größe / Variante | Modus(e) |
|---|---|---|---|
| 2025-09-23 | Qwen3-VL-235B-A22B-Instruct / Thinking | 235B Parameter (22B aktiv) | MoE |
| 2025-10-04 | Qwen3-VL-30B-A3B-Instruct / Thinking | 30B (3B aktiv) | MoE |
| 2025-10-15 | Qwen3-VL-4B (Instruct/Thinking) Qwen3-VL-8B (Instruct/Thinking) |
4B & 8B | Dense |
| 2025-10-21 | Qwen3-VL-2B (Instruct/Thinking) Qwen3-VL-32B (Instruct/Thinking) |
2B & 32B | Dense |
Wie schneidet Qwen3-VL bei visuellen Aufgaben ab?
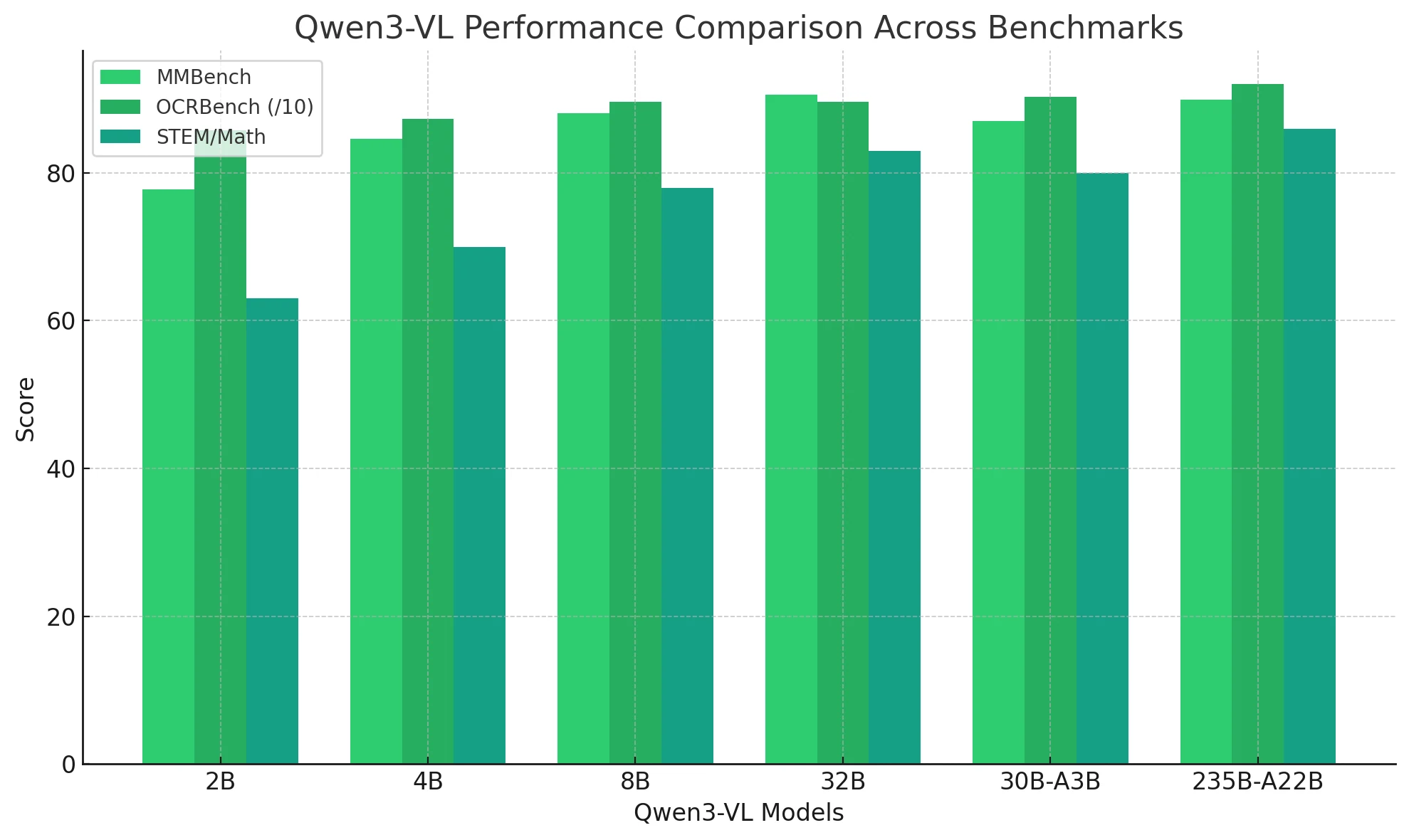
| Aufgabendimension | Repräsentativer Benchmark | Qwen3-VL-Leistung |
|---|---|---|
| Texterkennung / OCR | OCRBench 850–920 | Führend bei allen Modellen; robust gegenüber Unschärfe und mehrsprachigem Text. |
| STEM / Mathematische Schlussfolgerung | AIME, MathVerse | Deutliche Verbesserung ab 8B; 235B erreicht im Durchschnitt über 80. |
| Visuelle Fragebeantwortung (VQA) | MMBench, RealWorldQA | 32B- und MoE-Modelle übertreffen GPT-5 Mini. |
| Räumliche und 3D-Schlussfolgerung | EmbSpatialBench > 80 | Starke 2D/3D-räumliche Wahrnehmung; unterstützt AR/VR-Verständnis. |
| Video-Verständnis | VideoMME, LVBench ≈ 80 | Verarbeitet 256K–1M-Kontext für stundenlange Videoanalyse. |
| Agenten-Fähigkeit | ScreenSpot ≈ 95 | Demonstriert GUI-Bedienung und Tool-Aufruf-Fähigkeiten. |
| Codierung / Visuelle Programmierung | Design2Code ≈ 90+ | Wandelt Bilder in ausführbaren HTML/CSS/JS-Code um. |
| Mehrsprachiges Verständnis | MMLU-ProX ≈ 80 | Auf dem Niveau von reinen LLMs; erreicht nahtlose Text-Vision-Fusion. |
Qwen3-VL schafft ein vollspektrumiges multimodales Intelligenzsystem – es zeichnet sich in OCR, Schlussfolgerung, Video, räumlichem Verständnis und autonomer Interaktion aus.
Von 2B bis 235B skaliert die Leistung linear, während die 8B- und 30B-A3B-Modelle das beste Preis-Leistungs-Verhältnis bieten.
Letztendlich verwandelt Qwen3-VL LLMs von Sprachmodellen in einheitliche Vision-Language-Action-Systeme, die in der Lage sind, über Modalitäten hinweg zu wahrnehmen, zu schlussfolgern und auszuführen.
Welche Hardware wird benötigt, um Qwen3-VL lokal auszuführen?
| Modelltyp | Hardwareanforderung | Hinweise / Empfehlungen |
|---|---|---|
| Kleinere Varianten (4B / 8B) | Laufen lokal auf einer einzigen GPU (24 – 40 GB VRAM empfohlen). Starke Quantisierung (INT4 / FP16) wird dringend für Consumer-GPUs wie RTX 4090 / 3090 / A6000 empfohlen. | Am besten für lokale Entwicklung, Forschung und Edge-Bereitstellung. |
| Mittelklasse-Modelle (32B) | Erfordern ≥ 80 GB VRAM oder Dual-GPU-Setup. Quantisierung kann den Speicherbedarf auf 40 GB pro GPU senken. | Geeignet für On-Premise-Server oder Cloud-Inferenz. |
| Flaggschiff-MoE (Qwen3-VL-30B-A3B / 235B-A22B) | Benötigt mindestens 8 GPUs, jede mit ≥ 80 GB VRAM (z. B. A100, H100, H200). | Standardeinstellungen können auf kleineren GPUs fehlschlagen; befolgen Sie die untenstehenden Präzisions- und Speicheroptimierungshinweise. |
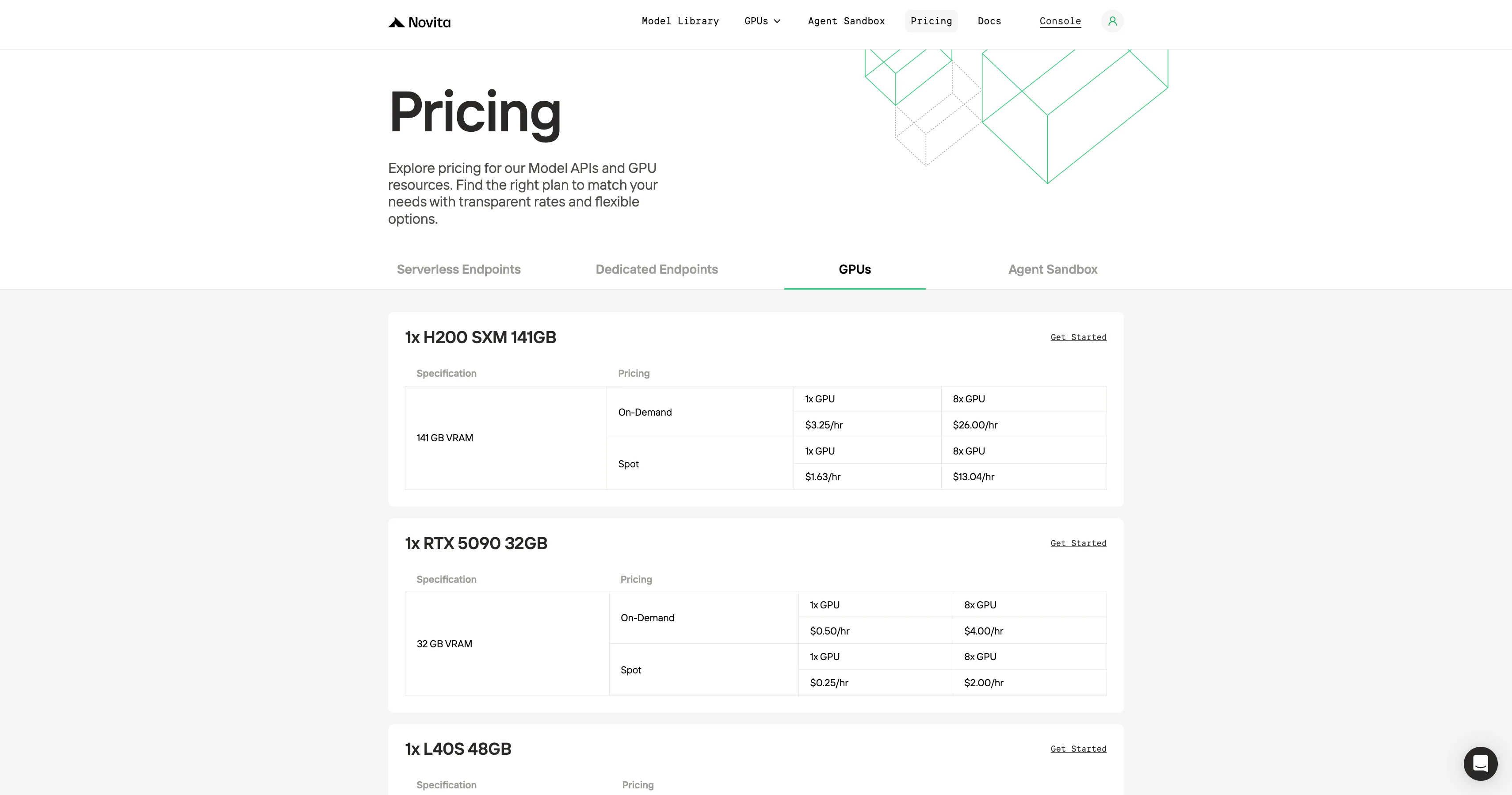
Novita zeichnet sich durch seine Erschwinglichkeit aus und bietet äquivalente GPUs zu etwa der Hälfte des Preises von RunPod und ähnlichen Plattformen…
Sie können prüfen, ob dies der niedrigste Preis ist?
Für Entwickler: Welche praktischen Erkenntnisse gibt es beim Erstellen multimodaler Agenten mit Qwen3-VL?
1. Wählen Sie die passende Variante
- Verwenden Sie die Instruct-Variante, wenn die Aufgabe Workflows, UI-Automatisierung oder Inhaltsgenerierung umfasst.
- Verwenden Sie die Thinking-Variante, wenn Sie tiefe Schlussfolgerung, mehrstufige Logik, STEM/Mathematik-Verarbeitung oder räumliches/Video-Verständnis benötigen.
- Passen Sie die Modellgröße an Aufgabe und Hardware an: Kleinere Varianten für reaktionsschnelle lokale Agenten, größere für hochwertige Schlussfolgerung oder Langkontext-Aufgaben.
2. Strukturieren Sie Ihre multimodalen Eingaben und Workflows
- Kombinieren Sie verschiedene Modalitäten in einem Aufruf: z. B. Bild (
"type":"image") + Textanweisungen. Das Repository zeigt dieses Muster. - Für Video- oder Langkontext-Aufgaben: Liefern Sie Bilder/Frames + Text-Hinweise mit Zeitstempel-Ausrichtung, um das Langzeitgedächtnis des Modells zu nutzen.
- Beim Erstellen von Agenten, die GUIs oder Tools bedienen: Erfassen Sie zuerst einen Screenshot oder den UI-Zustand, fordern Sie dann das Modell auf, diesen zu interpretieren und eine Aktion zu entscheiden. Der Beispielcode auf GitHub enthält Demos für “Mobile Agent” und “Computer-Use Agent”.
3. Optimieren Sie für Effizienz und Bereitstellung
- Aktivieren Sie Beschleunigungsfunktionen (z. B. Flash Attention v2) und verwenden Sie optimierte Backends für schwere multimodale Lasten.
- Für die Bereitstellung auf eingeschränkter Hardware: Quantisieren Sie das Modell oder schränken Sie den Modus ein (z. B. nur Bildeingabe, begrenzte Frames), um Speicher und Rechenleistung zu reduzieren. Community-Anleitungen zeigen dies für große Modelle.
- Verwenden Sie Stapelverarbeitung, Zeitabtastung für Videos und speichereffiziente Inferenz-Frameworks (wie vLLM-Rezepte), um Langkontext- und Multi-Frame-Aufgaben zu unterstützen.
4. Entwerfen Sie robuste Agentenlogik und Fallbacks
-
Bei der Automatisierung von UI-Aufgaben: Fügen Sie Verifizierungsschritte hinzu (War die Aufgabe erfolgreich? Wenn nicht, beschreiben Sie den Zustand), um mit dynamischen Layouts oder Fehlern umzugehen.
-
Für Vision- + Schlussfolgerungsaufgaben: Entwerfen Sie Prompts, die angeben “worauf zu achten ist”, “was zu tun ist” und “wie das Ergebnis zu melden ist”. Beispiel: Screenshot + “Finden Sie die Schaltfläche ‘Senden’, klicken Sie darauf, fassen Sie dann die Bestätigungsmeldung zusammen.”
-
Für Langvideo- oder Großdokument-Aufgaben: Bauen Sie Retrieval- oder Indexierungslogik ein (z. B. Keyframe-Extraktion oder Unterkontext-Aufteilung), um die Latenz überschaubar zu halten und Speicherüberlastung zu vermeiden. Ein Community-Artikel erwähnt die Verwendung von Keyframe-Extraktion, um stundenlange Eingaben zu verarbeiten.
-
Ist Qwen3-VL auf die Modalitäten Bild + Text beschränkt, oder wird es in Zukunft Video, Audio und breitere multimodale Eingaben unterstützen?
Wie greifen Sie auf die Qwen3-VL-Serie zu?
Novita AI bietet Qwen3-VL 235B Thinking-APIs mit einem 131K-Kontextfenster für 0,98 $ pro Eingabe und 3,95 $ pro Ausgabe. Es bietet außerdem Qwen3-VL 235BInstruct-APIs mit einem 131K-Kontextfenster für 0,30 $ pro Eingabe und 1,50 $ pro Ausgabe, die strukturierte Ausgaben und Funktionsaufrufe unterstützen.*
1. Weboberfläche (Am einfachsten für Einsteiger)
Qwen 3 VL 235B A22B jetzt testen!
2. API-Zugriff (Für Entwickler)
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Um sich gegenüber der API zu authentifizieren, stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite “Einstellungen” können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_UxQ9B4FllYcK6ZwMw6OFh5Q15fFCM4gMHoTbNh4vB3ZF_Dc5yN4RzVXxOHjarOF-AhMO61lRJN8plthUCfFvZA==",
)
model = "qwen/qwen3-vl-235b-a22b-thinking"
stream = True # or False
max_tokens = 16384
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
3. Lokale Bereitstellung (Für fortgeschrittene Benutzer)
Anforderungen:
- Qwen3-VL-235B-A22B: 8 NVIDIA H200 GPUs.
Installationsschritte:
- Laden Sie die Modellgewichte von HuggingFace oder ModelScope herunter
- Wählen Sie das Inferenz-Framework: vLLM oder SGLang werden unterstützt
- Befolgen Sie die Bereitstellungsanleitung im offiziellen GitHub-Repository
4. Integration
Verwendung von CLIs wie Trae, Claude Code, Qwen Code
Wenn Sie Novita AIs Top-Modelle (wie Qwen3-Coder, Kimi K2, DeepSeek R1) für KI-Codeunterstützung in Ihrer lokalen Umgebung oder IDE verwenden möchten, ist der Vorgang einfach: Holen Sie sich Ihren API-Schlüssel, installieren Sie das Tool, konfigurieren Sie Umgebungsvariablen und beginnen Sie mit dem Codieren.
Für detaillierte Einrichtungbefehle und Beispiele lesen Sie die offiziellen Tutorials:
- Trae : Schritt-für-Schritt-Anleitung zum Zugriff auf KI-Modelle in Ihrer IDE
- Claude Code:So verwenden Sie Kimi-K2 in Claude Code unter Windows, Mac und Linux
- Qwen Code:So verwenden Sie die OpenAI-kompatible API in Qwen Code (60s Setup!)
**Multi-Agent-Workflows mit dem OpenAI Agents SDK
Erstellen Sie fortschrittliche Multi-Agent-Systeme, indem Sie Novita AI mit dem OpenAI Agents SDK integrieren:
- Plug-and-Play: Verwenden Sie Novita AIs LLMs in jedem OpenAI Agents-Workflow.
- Unterstützt Übergaben, Routing und Tool-Nutzung: Entwerfen Sie Agenten, die delegieren, triagieren oder Funktionen ausführen können, alle angetrieben von Novita AIs Modellen.
- Python-Integration: Setzen Sie einfach den SDK-Endpunkt auf
https://api.novita.ai/v3/openaiund verwenden Sie Ihren API-Schlüssel.
API-Verbindung auf Drittanbieter-Plattformen
OpenAI-kompatible API: Genießen Sie problemlose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI-API-Standard entwickelt wurden.
Hugging Face: Verwenden Sie Modelle in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
Agent- und Orchestrierungs-Frameworks: Verbinden Sie Novita AI einfach mit Partnerplattformen wie Continue, AnythingLLM,LangChain, Dify und Langflow über offizielle Connectors und Schritt-für-Schritt-Integrationsanleitungen.
Mit den flexiblen Dense- und MoE-Architekturen, die von 2B bis 235B Parametern skalieren, unterstützt Qwen3-VL sowohl lokale Experimente als auch unternehmensweite Bereitstellung. Die 8B- und 30B-A3B-Varianten bieten ein ausgewogenes Verhältnis von Kosten und Leistung, während das 235B-A22B-Modell multimodale Schlussfolgerung auf dem neuesten Stand der Technik erreicht. Letztendlich markiert Qwen3-VL einen entscheidenden Schritt hin zu verkörperter Intelligenz – es ermöglicht Entwicklern, Systeme zu erstellen, die nicht nur Informationen analysieren, sondern auch intelligent in digitalen und physischen Umgebungen handeln.
Häufig gestellte Fragen
Verglichen mit Qwen-VL oder Qwen2.5-VL: Welche Verbesserungen bietet Qwen3-VL?
Qwen3-VL bietet verbessertes visuelles Verständnis, 2D/3D-räumliche Schlussfolgerung, Langkontext-Verständnis von bis zu 1 M Token und einen “Visuellen Agenten”, der mit Software-Schnittstellen interagieren kann. Es erweitert außerdem die OCR-Abdeckung auf 32 Sprachen und erreicht eine verlustfreie Text-Vision-Fusion.
Welche Hardware wird benötigt, um Qwen3-VL lokal auszuführen?
Kleinere Modelle wie Qwen3-VL-4B oder Qwen3-VL-8B können auf einer einzigen GPU (24 – 40 GB VRAM) mit Quantisierung ausgeführt werden. Qwen3-VL-30B-A3B und Qwen3-VL-235B-A22B erfordern mindestens acht GPUs, jede mit 80 GB VRAM (z. B. H100 / A100 / H200). FP8-Modus wird für H100 empfohlen, um die Effizienz zu maximieren.
Wie schneidet Qwen3-VL bei visuellen Aufgaben ab?
Bei Benchmarks wie MMBench, OCRBench und MathVerse übertrifft Qwen3-VL frühere Generationen, erreicht OCRBench-Punktzahlen zwischen 850–920 und übertrifft GPT-5 Mini bei VQA. Es zeichnet sich in räumlicher, Video- und STEM-Schlussfolgerung aus.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren von KI-Lösungen bietet.



