

开源权重模型如今已足够强大,可以用于真实的生产环境工作负载——如智能体编程、长上下文工作流和工具型助手,且无需锁定单一供应商。在“快速且强大”的讨论中,经常被提及的两个模型是 GLM-4.7-Flash 和 GPT-OSS-20B。
本文从实用角度对两者进行比较——质量(基准测试)、速度/延迟和成本,并展示如何通过 API 在 Novita AI 上立即运行这两个模型。
基本介绍
两者都是为高效而构建的 MoE 模型,但侧重点不同:
- GLM-4.7-Flash:在能力和效率之间取得“300亿参数级”平衡(擅长长上下文工作流)。
- GPT-OSS-20B:OpenAI 开源权重模型,针对更低延迟/单 GPU 友好性和工具使用进行了优化。
| GLM-4.7-Flash | GPT-OSS-20B | |
| 开发者 | Z.ai | OpenAI |
| 发布日期 | 2026 年 1 月 20 日 | 2025 年 8 月 5 日 |
| 参数(激活) | 30B-A3B (MoE) | 总计 21B / 激活 3.6B (MoE) |
| Novita 上下文 | 200,000 | 131,072 |
| Novita 定价 | 输入 $0.07/M · 输出 $0.40/M | 输入 $0.04/M · 输出 $0.15/M |
基准测试对比
下图报告了 6 个基准测试的结果:SWE-bench Verified、τ²-Bench、BrowseComp、AIME 25、GPQA、HLE。这些数字来自 GLM-4.7-Flash 的 Hugging Face 模型页面,我们将其作为权威来源。
| 基准测试 | GLM-4.7-Flash | GPT-OSS-20B | 获胜者 |
| SWE-bench Verified | 59.2 | 34 | GLM-4.7-Flash |
| τ²-Bench | 79.5 | 47.7 | GLM-4.7-Flash |
| BrowseComp | 42.8 | 28.3 | GLM-4.7-Flash |
| AIME 25 | 91.6 | 91.7 | GPT-OSS-20B(略胜) |
| GPQA | 75.2 | 71.5 | GLM-4.7-Flash |
| HLE | 14.4 | 10.9 | GLM-4.7-Flash |
💡解读
大多数基准测试结果偏向 GLM-4.7-Flash——在五项评估中领先,而 AIME 25 几乎持平(91.6 对 91.7)。
- 智能体 + 工具密集型任务: GLM-4.7-Flash 在 SWE-bench Verified 和 τ²-Bench 上明显领先,这两项测试与实际智能体工作流(编程/终端、多步骤交互)密切相关。
- 浏览类任务: GLM-4.7-Flash 也在 BrowseComp 上领先,表明在评估设置下具有更强的长程导航/选择能力。
- 数学: AIME 25 基本持平(91.6 对 91.7)。换句话说:不要仅凭这一点来选择。
- 知识密集型问答: 在这组报告中,GLM-4.7-Flash 在 GPQA 和 HLE 上领先。
速度与延迟对比
| 指标 | GPT-OSS-20B | GLM-4.7-Flash |
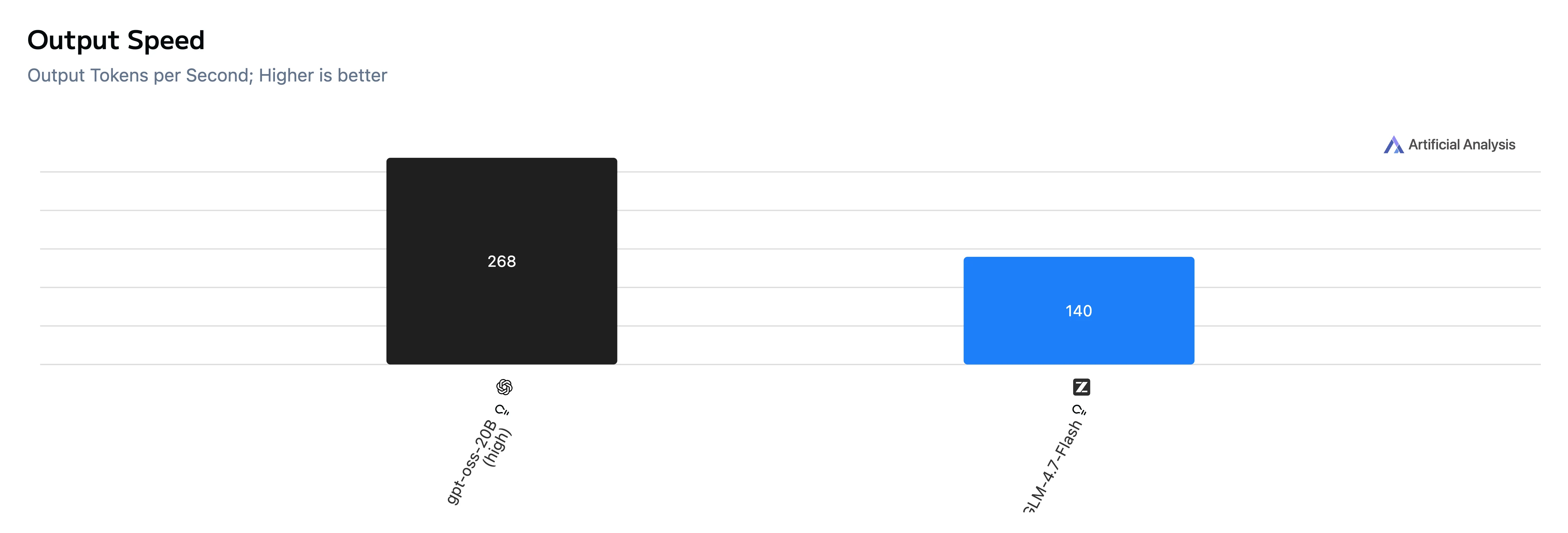
| 输出速度 | 268 tok/s | 140 tok/s |
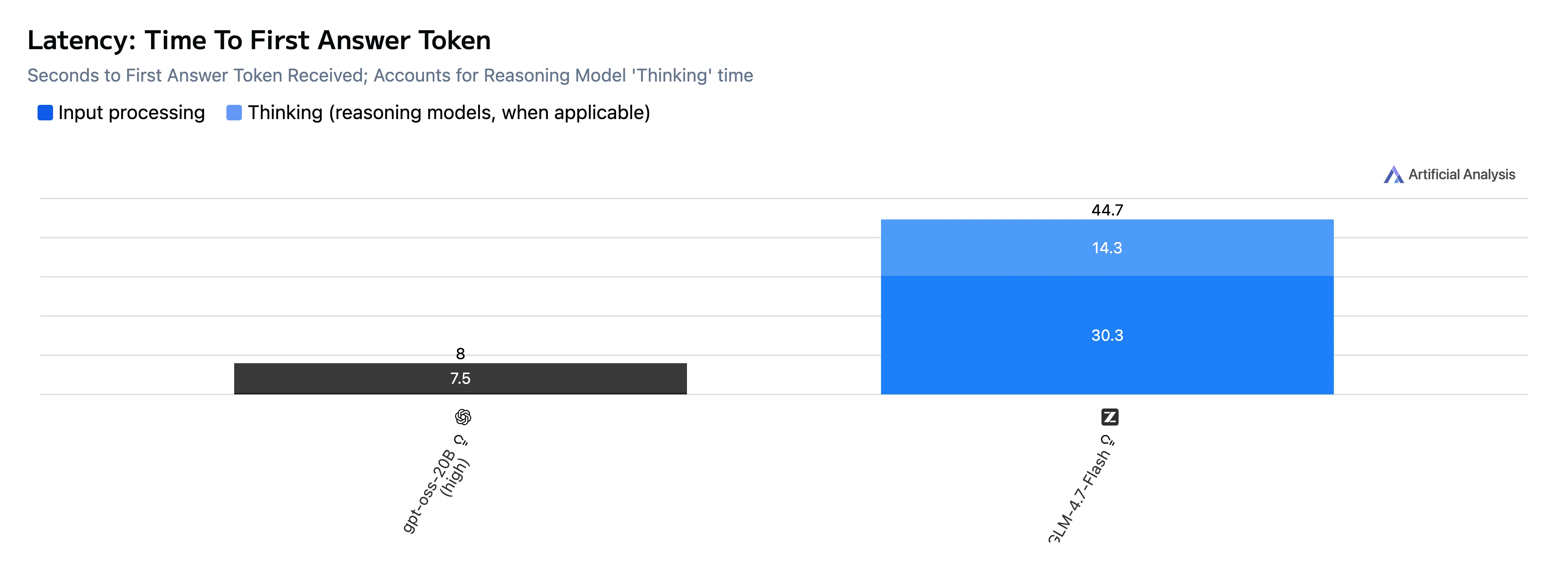
| TTFT(首个回答 Token) | 8.0 秒 | 46.5 秒 |
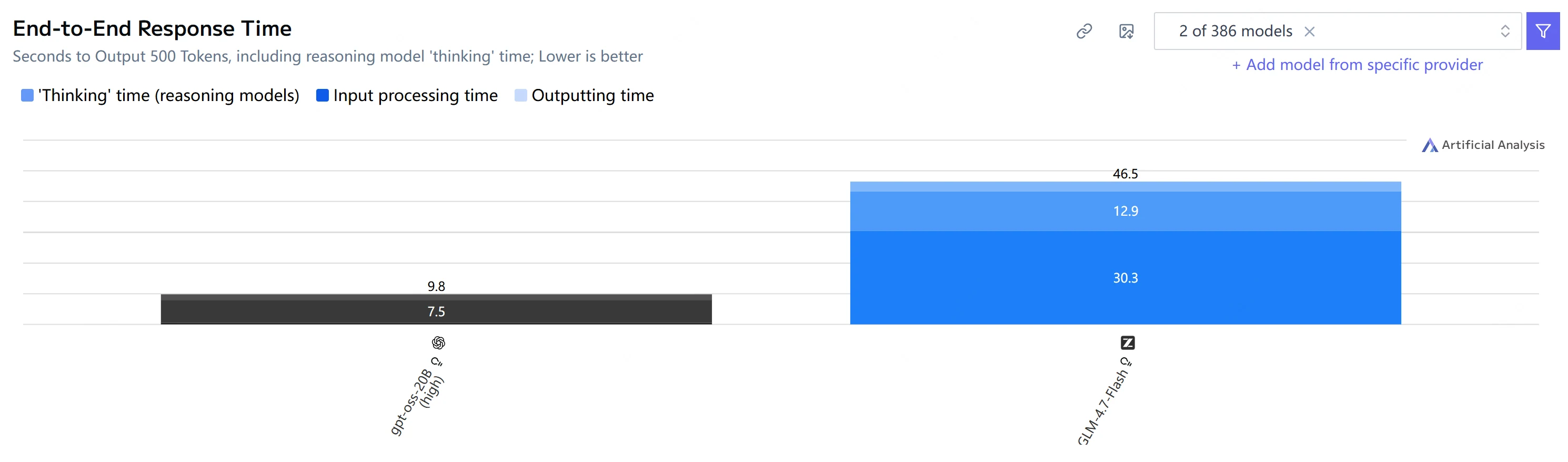
| 端到端时间 (500 个输出 Token) |
9.8 秒 | 46.5 秒 |
要点: 在此测试集中,GPT-OSS-20B 在 首 Token 时间 和 端到端生成 上都 快得多,并且 Token 输出速度也更快。
成本对比
| 模型 | 输入(美元 / 百万 Token) | 输出(美元 / 百万 Token) | 缓存读取(美元 / 百万 Token) |
| GLM-4.7-Flash (zai-org/glm-4.7-flash) | $0.07 | $0.40 | $0.01 |
| GPT-OSS-20B (openai/gpt-oss-20b) | $0.04 | $0.15 | - |
GPT-OSS-20B 按 Token 计算更具成本效益,而 GLM-4.7-Flash 成本更高,但当你需要更强的性能和长上下文能力时,它物有所值。如需更多详情,请访问 Novita AI 的 模型库 查看最新定价和模型规格。
快速上手:在 Playground 上即刻体验两个模型
如果你想立即体验 GLM-4.7-Flash 和 GPT-OSS-20B 之间的差异,最快的方法是使用 Novita AI Playground——无需代码,无需设置。
在 Playground 中,你可以:
- 即时切换模型,在 GLM-4.7-Flash 和 GPT-OSS-20B 之间切换
- 使用相同的提示来比较输出质量、推理风格和响应速度
Novita AI Playground
如何部署:API、SDK 和第三方集成
API
获取 API Key
- 步骤 1:创建或登录账户
访问 [**https://novita.ai**](https://novita.ai) 并 注册 或登录你现有的账户
- 步骤 2:进入密钥管理
登录后,找到“API Keys”

- 步骤 3:创建新密钥
点击“Add New Key”按钮。

- 步骤 4:立即保存你的密钥
生成后立即复制并存储密钥;通常只显示一次,之后无法找回。将密钥保存在安全位置,如密码管理器或加密笔记中。
OpenAI 兼容 API(Python)
from openai import OpenAI
client = OpenAI(
api_key="<你的NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "你是一个精确的工程助手。当被要求时,输出有效的 JSON。"},
{"role": "user", "content": "总结在 20 项服务中推出功能标志的主要风险。"},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
SDK
如果你在构建 智能体工作流(任务交接、路由、工具/函数调用),你可以使用 OpenAI Agents SDK 在 Novita 托管的模型上运行,只需最小改动:
- 即插即用兼容性: Novita 提供 OpenAI 兼容 API,因此你的 Agents 工作流保持不变——只需更改 base URL 和模型。
- 智能体编排就绪: 使用路由 + 工具分配任务,同时将推理保持在 Novita 上。
- 设置: 将 SDK 指向
https://api.novita.ai/openai,设置NOVITA_API_KEY,选择zai-org/glm-4.7-flash(或openai/gpt-oss-20b)。
第三方平台
你还可以通过流行的生态系统使用 Novita 托管的模型:
- 智能体框架和应用构建器: 按照 Novita 的分步集成指南,连接到 Continue、AnythingLLM、LangChain 和 Langflow 等流行工具。
- Hugging Face Hub: Novita 被列为 Hugging Face 上的 推理提供商,因此你可以通过 Hugging Face 的提供商工作流和生态系统运行支持的模型。
- OpenAI 兼容 API: Novita 的 LLM 端点与 OpenAI API 标准兼容,使得迁移现有 OpenAI 风格应用和连接许多 OpenAI 兼容工具(Cline、Cursor、Trae 和 Qwen Code)变得简单。
- Anthropic 兼容 API: Novita 还提供 Anthropic SDK 兼容 访问,因此你可以将 Novita 支持的模型集成到 Claude Code 风格的智能体编码工作流中。
- OpenCode:Novita AI 现已直接集成到 OpenCode 中,作为 支持的提供商,用户无需手动配置即可在 OpenCode 中选择 Novita。
结论
- GLM-4.7-Flash 更适合当你最关心 智能体/编码质量 和 非常长的上下文(200K) 时——在提供的图表中,它在 5/6 个基准测试上领先(AIME 基本持平)。
- GPT-OSS-20B 更适合当你最关心 速度和成本 时——在提供的延迟图表上它快得多,并且按 Novita 的无服务器定价也更便宜。
最快的路径:在 Novita AI Playground 上尝试两者,然后根据你的构建方式迁移到 API / SDK / 第三方集成。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的简便方法,同时还提供经济实惠且可靠的 GPU 云用于构建和扩展。
常见问题
什么是 GLM-4.7-Flash?
GLM-4.7-Flash 是由智谱 AI 开发的 300 亿参数级混合专家(MoE)大语言模型,旨在以高效和低延迟提供强大的推理、编码和智能体性能。
GLM-4.7-Flash 的成本是多少?
在 Novita AI(无服务器)上,GLM-4.7-Flash 的定价为 输入 $0.07/M Token、缓存读取 $0.01/M Token 和 输出 $0.40/M Token,对于大上下文和高吞吐量工作负载来说具有成本效益。
GLM-4.7-Flash 和 GPT-OSS-20B 哪个更好?
这取决于用例:GLM-4.7-Flash 通常在智能体、工具密集型以及现实世界的基准测试上表现更好,而 GPT-OSS-20B 在轻量级、低延迟或单 GPU 部署场景下可能更受青睐。



