

GLM-4.5V 是 GLM-4.1V 的重大升级版本,在可扩展性、多模态能力和成本效率方面都有显著提升。通过集成领域专属专家模块、先进视觉模块以及混合专家(MoE)架构,GLM-4.5V 在文档理解、实时视频OCR、多模态内容生成等任务中表现优异,是一款功能全面、对开发者友好的解决方案。
GLM 4.5V 相比 GLM 4.1V 的新特性
与 GLM-4.1V 相比,GLM-4.5V 展现了明显更高的通用性和工具集成能力。它简化了此前需要多个专用模型才能完成的任务,能够在单一系统内处理从基础图像识别到复杂视频分析、文档处理的所有需求。例如,GLM-4.5V 可以根据网页截图生成前端代码,或分析地图图像提取地理定位线索。它将推理与外部工具集成、并生成结构化输出的能力,使其与 GLM-4.1V 拉开差距,成为更对开发者友好、可扩展性更强的多模态AI平台。

GLM 4.5V 与 GLM 4.1V 架构对比
| 维度 | GLM-4.1V | GLM-4.5V |
|---|---|---|
| 规模 | 90亿参数,稠密Transformer架构 | 总参数1060亿,通过混合专家(MoE)架构仅激活120亿参数 |
| 专业化能力 | 通用型模型 | 通过MoE架构集成领域专属专家,任务表现更优 |
| 视觉模块 | 仅支持2D图像处理 | 新增3D卷积,支持视频和GUI界面识别 |
| 上下文编码 | 采用2D RoPE,支持约64k token | 采用3D RoPE,支持64k token + 多维度输入 |
| 基础模型 | 基于GLM-4(90亿参数) | 基于GLM-4.5-Air,语言和多模态能力均有增强 |
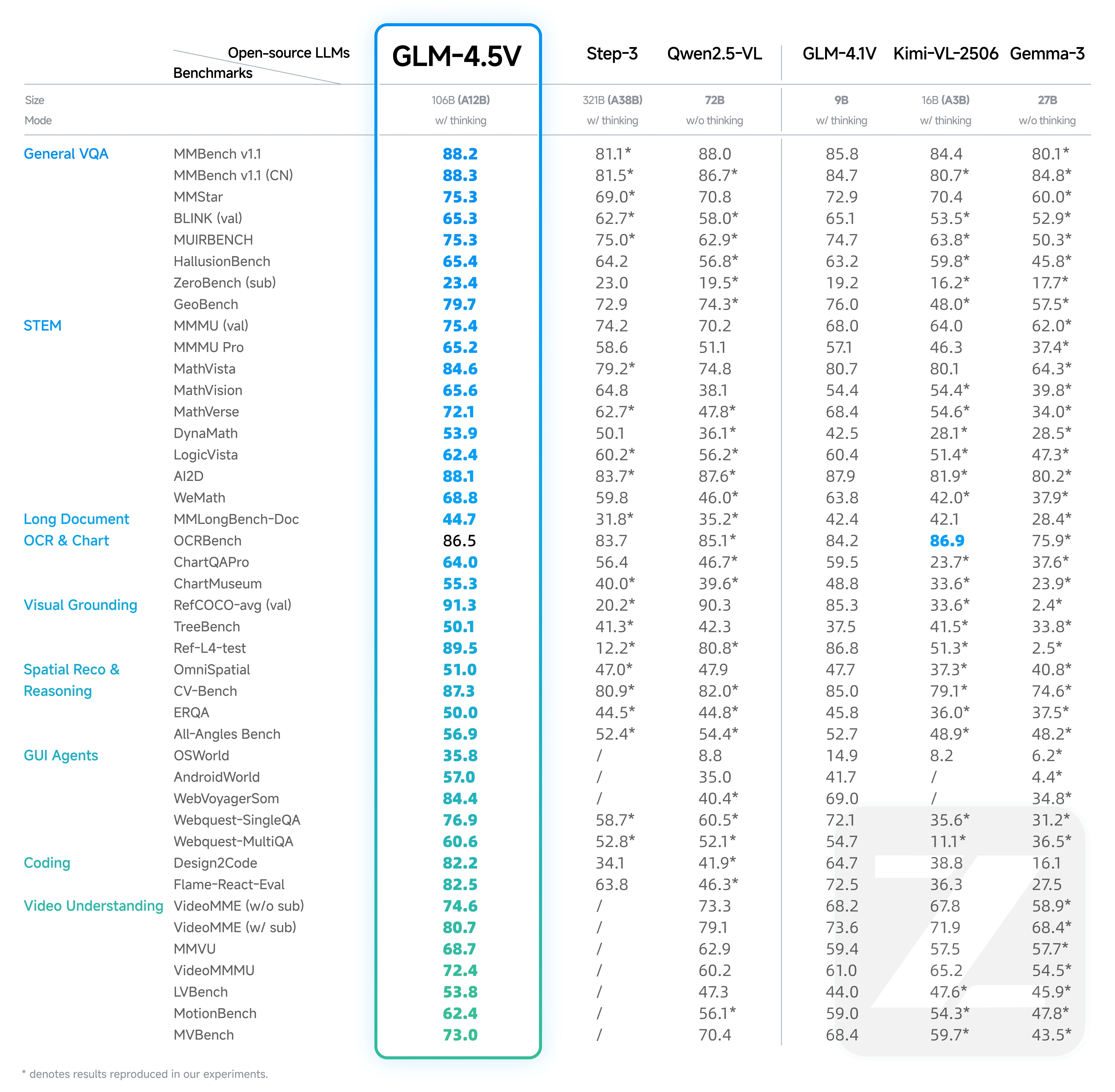
GLM 4.5V 与 GLM 4.1V 基准测试对比
数据来源:Hugging Face
GLM-4.1V 的成就:
- 性能超越Qwen-2.5-VL(7B)等更大尺寸模型,尽管参数量更小,仍可与Qwen-72B比肩。
- 在2025年前定义了小规模模型的最高性能水平。
GLM-4.5V 的升级:
- 性能超越同参数区间的所有开源模型,部分任务表现甚至超过更大尺寸的模型。
- 在多项核心基准测试中击败了Step-3(3210亿参数),展现了极高的效率和准确率。
GLM-4.5V 的核心优势:
- 在通用视觉问答、STEM推理、长文档OCR任务中表现突出。
- 依托MoE架构和先进的训练优化技术,实现更优异的性能。
GLM 4.5V 与 GLM 4.1V 硬件需求对比
| 维度 | GLM-4.1V | GLM-4.5V |
|---|---|---|
| 显存需求 | 24GB(例如NVIDIA A100 40GB、RTX 4090) | 单卡需80GB显存,完整部署通常需要8张80GB显存的GPU |
| GPU配置 | 单张高端GPU即可满足需求 | 需要多GPU配置(例如8张GPU)或云GPU集群 |
| CPU兼容性 | 经过优化后可在CPU上运行(非实时场景) | 不支持CPU运行,需要高性能硬件或云端解决方案 |
| 量化选项 | 支持16位、8位甚至4位量化以降低内存占用 | 提供内存优化版本(例如FP8量化)以降低硬件需求 |
凭借灵活的推理模式和高效的精度-速度调整能力,GLM-4.5V 最大程度降低了硬件需求,既适合高性能场景,也适合轻量级实时使用场景。
GLM 4.5V 与 GLM 4.1V 应用场景对比
GLM 4.5V
- 文档理解
- 可识别和分析复杂文档中的文本内容
- 支持手写体、印章、水印、扭曲变形等场景的处理
- 可提取关键信息并生成结构化摘要
- 表格识别与重建
- 支持处理包含合并单元格、嵌套结构的复杂表格
- 可推断缺失数据并保证数据一致性
- 可将图像类表格转换为Excel、CSV等格式
- 多模态内容生成
- 可基于识别到的文本、图表、图像生成报告和摘要
- 提供趋势分析和可落地的建议
- 支持基于手写笔记或表单创建内容
- 实时视频OCR
- 可从视频流中提取字幕和屏幕文本
- 可动态追踪移动文本,适配场景变化
- 支持实时多语言识别
GLM 4.1V
- 教育工具
- 非常适合通过图像分析逐步展示AI推理过程的教学场景
- 同时输出答案和推理过程,帮助理解AI的决策逻辑
- 敏感场景应用
- 适用于医学图像分析等对透明度和思维链解释要求较高的领域
- 轻量级系统
- 可部署在资源有限的后端支撑的简单网页应用或设备上
- 实验与研究
- 紧凑的模型尺寸让计算资源有限的研发人员也能轻松使用
- 辅导系统
- 支持视觉-语言能力,可用于互动式学习环境
GLM 4.5V 的成本优势
高性能(来自LLMOCR 测试)
- 整体准确率:在1000份混合类型文档上达到98.7%
- 核心优势:
- 中文识别准确率:99.3%
- 英文识别准确率:98.9%
- 表格还原准确率:97.5%
- 手写体识别准确率:96.8%
- 效率:处理速度为0.42秒/页,API调用成功率达99.95%
成本效益
- 平均成本:每页¥0.015
- 成本节省:
- 相比GPT-4V成本降低73%
- 相比Claude-3成本降低65%
Novita AI:更具性价比、更稳定的GLM 4.5V API服务商
Novita AI 的GLM-4.5V API支持65.5k上下文长度,输入价格为$0.60/1K tokens,输出价格为$1.80/1K tokens,支持函数调用和结构化输出。
步骤1:登录账号并进入模型库
登录你的账号,点击模型库按钮。

步骤2:选择模型
浏览可用选项,选择符合你需求的模型。

步骤3:开启免费试用
开始免费试用,探索所选模型的能力。

步骤4:获取API密钥
要完成API身份验证,我们会为你提供新的API密钥。进入「设置」页面后,即可按照下图提示复制API密钥。

步骤5:安装API
使用对应编程语言的包管理器安装API。安装完成后,将所需库导入到你的开发环境中,使用API密钥初始化API即可开始调用Novita AI LLM。以下是Python用户使用聊天补全API的示例:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
使用MCP和GLM构建简易图像识别工具
如果你想利用GLM的能力,例如构建一个简易图像识别工具来展示其视觉识别与推理的集成能力,可以使用Novita AI支持的MCP功能。以下是示例代码:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
如果你想了解详细内容,可以查看这篇文章:如何使用Novita AI构建你的第一个MCP服务器!
GLM-4.5V 在各方面都超越了前代GLM-4.1V:从处理复杂视觉内容、长文档的能力,到成本节省和硬件优化表现。凭借增强的架构和广泛的应用场景,它是开发者和企业寻求一体化AI解决方案的革命性选择。
GLM-4.5V 的核心架构升级有哪些? GLM-4.5V 引入了混合专家(MoE)架构,总参数1060亿(仅激活120亿),采用3D RoPE编码和3D卷积技术支持视频与GUI识别,超越了GLM-4.1V的稠密Transformer设计,支持逐步推理而非仅给出结果。
GLM-4.5V 如何处理多模态任务? GLM-4.5V 集成了先进的视觉模块,支持3D视频和GUI识别,能够完成实时视频OCR、地理定位分析、多模态内容生成等任务。
相比GLM-4.1V,哪些任务更适合用GLM-4.5V完成? GLM-4.5V 在文档理解(包括手写体、水印识别)、表格重建、实时视频OCR、多模态内容生成等任务中表现优异,而这些是GLM-4.1V的短板。
Novita AI 是助力你实现AI愿景的一站式云平台。集成API、无服务器、GPU实例——你需要的性价比工具应有尽有。无需操心基础设施,免费即可上手,让你的AI想法落地。



