

- ميزات GLM 4.5V غير الموجودة في GLM 4.1V
- مقارنة البنية بين GLM 4.5V و GLM 4.1V
- مقارنة الأداء القياسي بين GLM 4.5V و GLM 4.1V
- مقارنة الأجهزة بين GLM 4.5V و GLM 4.1V
- مقارنة التطبيقات بين GLM 4.5V و GLM 4.1V
- مزايا التكلفة لـ GLM 4.5V
- Novita AI: مزود API لـ GLM 4.5V أكثر فعالية من حيث التكلفة واستقراراً
- بناء أداة بسيطة للتعرف على الصور باستخدام MCP و GLM
GLM-4.5V يمثل قفزة كبيرة إلى الأمام مقارنة بـ GLM-4.1V، حيث يقدم قابلية توسع محسنة، وقدرات متعددة الوسائط، وكفاءة في التكلفة. من خلال دمج خبراء متخصصين في المجالات، ووحدات رؤية متقدمة، وهيكل الخبراء المختلطين (MoE)، يتفوق GLM-4.5V في مهام مثل فهم المستندات، والتعرف الضوئي على الحروف في الفيديو في الوقت الفعلي، وتوليد المحتوى متعدد الوسائط، مما يجعله حلاً متعدد الاستخدامات وملائماً للمطورين.
ميزات GLM 4.5V غير الموجودة في GLM 4.1V
يظهر GLM-4.5V مرونة وتكامل مع الأدوات أعلى بكثير مقارنة بـ GLM-4.1V. فهو يبسط المهام التي كانت تتطلب سابقاً نماذج متخصصة متعددة، حيث يتعامل مع كل شيء من التعرف الأساسي على الصور إلى تحليل الفيديو المعقد ومعالجة المستندات ضمن نظام واحد. على سبيل المثال، يمكن لـ GLM-4.5V توليد كود الواجهة الأمامية من لقطة شاشة لصفحة ويب أو تحليل صورة خريطة للعثور على أدلة الموقع الجغرافي. إن قدرته على دمج الاستدلال مع الأدوات الخارجية وإنتاج مخرجات منظمة تميزه عن GLM-4.1V، مما يجعل الإصدار 4.5V منصة ذكاء اصطناعي متعددة الوسائط أكثر ملاءمة للمطورين وقابلية للتوسع.

مقارنة البنية بين GLM 4.5V و GLM 4.1V
| الجانب | GLM-4.1V | GLM-4.5V |
|---|---|---|
| الحجم | 9 مليار معامل، محول كثيف. | 106 مليار إجمالي، 12 مليار نشط عبر هيكل الخبراء المختلطين (MoE). |
| التخصص | نموذج عام. | خبراء متخصصون في المجالات عبر MoE لأداء أفضل في المهام. |
| وحدات الرؤية | معالجة صور ثنائية الأبعاد فقط. | تضيف طيًا ثلاثي الأبعاد للتعرف على الفيديو وواجهة المستخدم الرسومية. |
| ترميز السياق | RoPE ثنائي الأبعاد لـ ~64 ألف رمز. | RoPE ثلاثي الأبعاد لـ 64 ألف رمز + مدخلات متعددة الأبعاد |
| النموذج الأساسي | مبني على GLM-4 (9 مليار). | مبني على GLM-4.5-Air، مع قدرات لغة ومتعددة الوسائط محسنة. |
مقارنة الأداء القياسي بين GLM 4.5V و GLM 4.1V
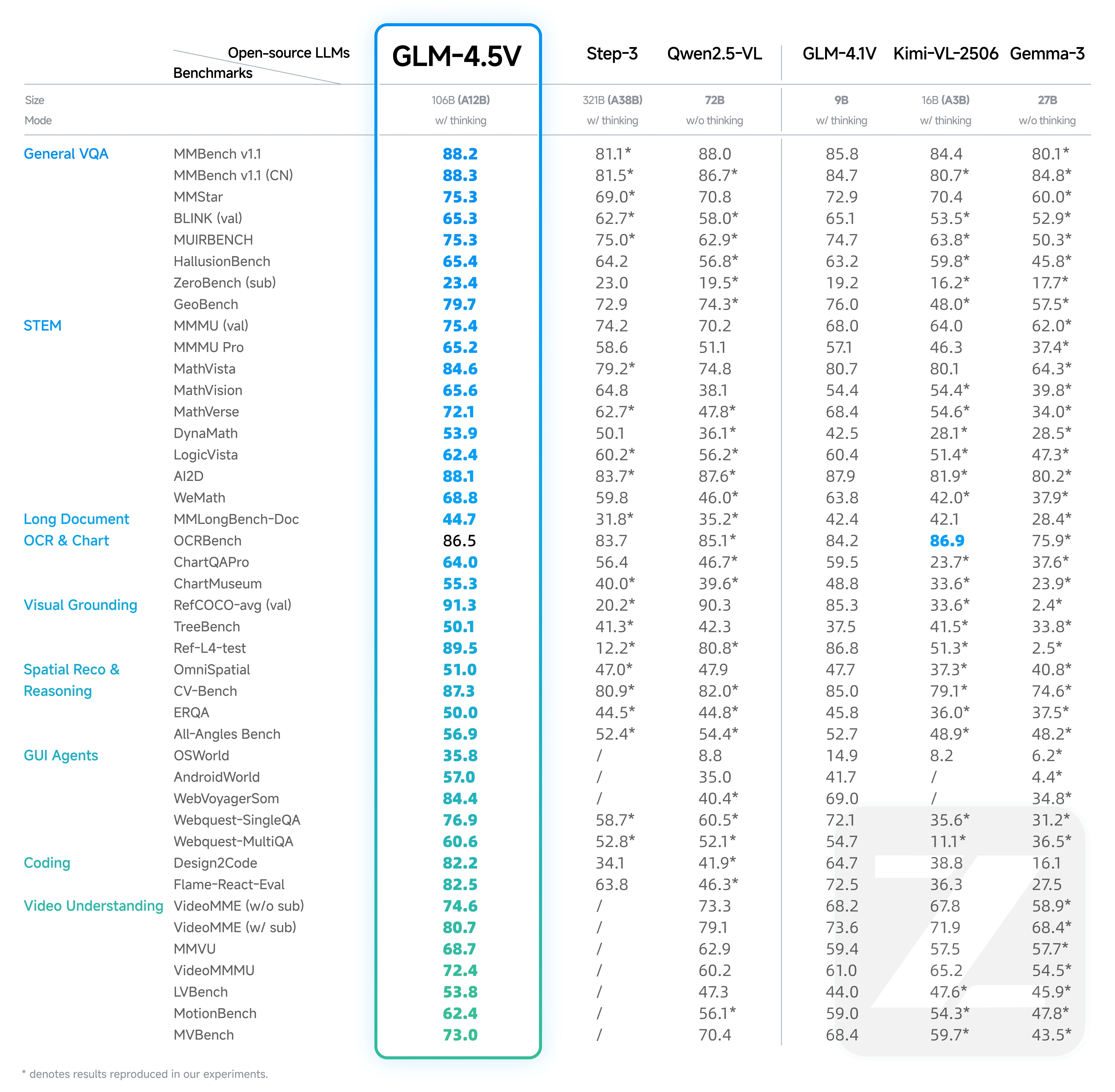
من Hugging Face
إنجازات GLM-4.1V:
- تفوق على نماذج أكبر مثل Qwen-2.5-VL (7B) ومنافس Qwen-72B على الرغم من حجمه الأصغر.
- وضع المعيار للأنظمة المتقدمة للنماذج صغيرة الحجم قبل عام 2025.
تطورات GLM-4.5V:
- تفوق على النماذج المفتوحة في نطاق المعاملات الخاص به وتفوق على بعض النماذج الأكبر.
- تفوق على Step-3 (321 مليار معامل) في معايير رئيسية متعددة، مما يبرز كفاءته ودقته.
نقاط القوة الرئيسية لـ GLM-4.5V:
- يتفوق في الإجابة على الأسئلة البصرية العامة، والاستدلال في مجالات STEM، والتعرف الضوئي على الحروف (OCR) في المستندات الطويلة.
- يستغل هيكل MoE وتحسينات تدريب متقدمة لأداء متفوق.
مقارنة الأجهزة بين GLM 4.5V و GLM 4.1V
| الجانب | GLM-4.1V | GLM-4.5V |
|---|---|---|
| متطلبات ذاكرة الفيديو (VRAM) | 24 جيجابايت (مثل NVIDIA A100 40GB، RTX 4090) | 80 جيجابايت لكل بطاقة رسومية؛ يتطلب عادة 8 بطاقات 80 جيجابايت للنشر الكامل. |
| إعداد بطاقات الرسومية | يكفي بطاقة رسومية عالية الأداء واحدة. | يتطلب إعداد بطاقات رسومية متعددة (مثل 8 بطاقات) أو مجموعات بطاقات رسومية سحابية. |
| التوافق مع المعالج المركزي (CPU) | يمكن تشغيله على المعالج المركزي (غير في الوقت الفعلي) مع تحسينات. | غير مصمم للتشغيل على المعالج المركزي؛ يتطلب أجهزة متقدمة أو حلول سحابية. |
| خيارات الضغط الكمي | يدعم الضبط الكمي 16 بت، 8 بت، وحتى 4 بت لتقليل استهلاك الذاكرة. | يقدم إصدارات محسنة للذاكرة (مثل الضبط الكمي FP8) لتخفيف متطلبات الأجهزة. |
من خلال تقديم وضع استدلال مركب وتعديلات فعالة للسرعة والدقة، يقلل GLM-4.5V من متطلبات الأجهزة، مما يجعله مناسباً لحالات الاستخدام عالية الأداء وخفيفة الوزن في الوقت الفعلي.
مقارنة التطبيقات بين GLM 4.5V و GLM 4.1V
GLM 4.5V
1. فهم المستندات
- يتعرف على النص في المستندات المعقدة ويحللها.
- يتعامل مع الكتابة اليدوية، والأختام، والعلامات المائية، والتشوهات.
- يستخرج المعلومات الرئيسية ويولد ملخصات منظمة.
2. التعرف على الجداول وإعادة بنائها
- يعالج الجداول المعقدة ذات الخلايا المدمجة والهياكل المتداخلة.
- يستنتج البيانات المفقودة ويضمن الاتساق.
- يحول الجداول المستندة إلى الصور إلى Excel و CSV وما إلى ذلك.
3. توليد المحتوى متعدد الوسائط
- يولد تقارير وملخصات بناءً على النص المعترف به، أو الرسوم البيانية، أو الصور.
- يقدم تحليلاً للاتجاهات وتوصيات قابلة للتنفيذ.
- يدعم الإنشاء من ملاحظات يدوية أو نماذج.
4. التعرف الضوئي على الحروف في الفيديو في الوقت الفعلي
- يستخرج الترجمات والنص الظاهر على الشاشة من تدفقات الفيديو.
- يتتبع النص المتحرك بشكل ديناميكي ويتكيف مع تغيرات المشهد.
- يتعرف على لغات متعددة في الوقت الفعلي.
GLM 4.1V
- أدوات تعليمية
- مثالي لتعليم استدلال الذكاء الاصطناعي خطوة بخطوة مع تحليل الصور.
- ينتج كل من الإجابات والاستدلال، مما يساعد على فهم عملية اتخاذ القرار في الذكاء الاصطناعي.
- تطبيقات حساسة
- مفيد في مجالات مثل تحليل الصور الطبية حيث تكون الشفافية وشرح سلسلة التفكير أمراً بالغ الأهمية.
- أنظمة خفيفة الوزن
- يمكن نشره على تطبيقات ويب بسيطة أو أجهزة ذات موارد خلفية محدودة.
- التجربة والبحث
- حجم النموذج المدمج يجعله متاحاً للباحثين والمطورين ذوي القدرة الحاسوبية المحدودة.
- أنظمة التعليم الخاص
- يتيح قدرات الرؤية واللغة لبيئات تعلم تفاعلية.
مزايا التكلفة لـ GLM 4.5V
أداء عالي من اختبار LLMOCR
- الدقة الإجمالية: 98.7% عبر 1000 مستند من أنواع مختلطة.
- نقاط القوة المحددة:
- التعرف على الصينية: 99.3%.
- التعرف على الإنجليزية: 98.9%.
- استعادة الجداول: 97.5%.
- التعرف على الكتابة اليدوية: 96.8%.
- الكفاءة: يعالج المستندات في 0.42 ثانية/صفحة بمعدل نجاح مكالمات API يبلغ 99.95%.
الكفاءة في التكلفة
- متوسط التكلفة: ¥0.015/صفحة.
- التوفير:
- تخفيض 73% في التكلفة مقارنة بـ GPT-4V.
- تخفيض 65% في التكلفة مقارنة بـ Claude-3.
Novita AI: مزود API لـ GLM 4.5V أكثر فعالية من حيث التكلفة واستقراراً
يقدم API Novita AI لـ GLM-4.5V سياقاً يبلغ 65.5 ألف رمز، مع تسعير المدخلات بـ 0.60 دولار/1 ألف رمز، والمخرجات بـ 1.80 دولار/1 ألف رمز، ويدعم استدعاء الدوال والمخرجات المنظمة.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.

الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع نماذج اللغات الكبيرة من Novita AI. هذا مثال على استخدام API لإكمال المحادثات لمستخدمي بايثون.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
بناء أداة بسيطة للتعرف على الصور باستخدام MCP و GLM
إذا كنت ترغب في الاستفادة من قدرات GLM—مثل بناء أداة بسيطة للتعرف على الصور لإظهار تكامله للتعرف البصري والاستدلال—يمكنك استخدام وظائف MCP المدعومة من Novita AI. أدناه نموذج للكود:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
إذا كنت ترغب في الحصول على التفاصيل، يمكنك الاطلاع على هذا المقال: كيفية بناء خادم MCP الأول الخاص بك مع Novita AI!
يتفوق GLM-4.5V على سابقه GLM-4.1V في كل جانب: من قدرته على معالجة المحتويات البصرية المعقدة والمستندات الطويلة إلى التوفير في التكاليف وتحسين متطلبات الأجهزة بشكل متفوق. مع بنيته المحسنة ونطاق تطبيقاته الواسع، يعد هذا نموذجاً يغير قواعد اللعبة للمطورين والشركات التي تبحث عن حل ذكاء اصطناعي متكامل.
ما هي التحسينات المعمارية الرئيسية في GLM-4.5V؟
يقدم GLM-4.5V هيكل الخبراء المختلطين (MoE) بمعاملات تبلغ 106 مليار (12 مليار نشط)، وترميز RoPE ثلاثي الأبعاد، وطيًا ثلاثي الأبعاد للتعرف على الفيديو وواجهة المستخدم الرسومية، متجاوزاً تصميم المحول الكثيف لـ GLM-4.1V. إنه لا يقدم إجابات فقط، بل يتبع خطوات استدلال واضحة.
كيف يتعامل GLM-4.5V مع المهام متعددة الوسائط؟
يدمج GLM-4.5V وحدات رؤية متقدمة للتعرف على الفيديو ثلاثي الأبعاد وواجهة المستخدم الرسومية، مما يتيح مهام مثل التعرف الضوئي على الحروف في الفيديو في الوقت الفعلي، وتحليل الموقع الجغرافي، وتوليد المحتوى متعدد الوسائط.
ما هي المهام التي يكون GLM-4.5V أكثر ملاءمة لها مقارنة بـ GLM-4.1V؟
يتفوق GLM-4.5V في فهم المستندات (بما في ذلك الكتابة اليدوية والعلامات المائية)، وإعادة بناء الجداول، والتعرف الضوئي على الحروف في الفيديو في الوقت الفعلي، وتوليد المحتوى متعدد الوسائط، وهي مجالات كان GLM-4.1V محدوداً فيها.
Novita AI هي منصة سحابية متكاملة تمكّنك من تحقيق طموحاتك في الذكاء الاصطناعي. واجهات برمجة التطبيقات المدمجة، بدون خوادم، مثيلات بطاقات رسومية — الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجاناً، وحقق رؤيتك في الذكاء الاصطناعي.



