

- Características de GLM 4.5V que no están en GLM 4.1V
- Comparación de arquitectura entre GLM 4.5V y GLM 4.1V
- Comparación de benchmarks entre GLM 4.5V y GLM 4.1V
- Comparación de hardware entre GLM 4.5V y GLM 4.1V
- Comparación de aplicaciones entre GLM 4.5V y GLM 4.1V
- Ventajas de costo de GLM 4.5V
- Novita AI: Proveedor de API de GLM 4.5V más rentable y estable
- Construye una herramienta de reconocimiento de imágenes sencilla usando MCP y GLM
GLM-4.5V representa un salto significativo con respecto a GLM-4.1V, ofreciendo una escalabilidad, capacidades multimodales y eficiencia de costos mejoradas. Al integrar expertos específicos de dominio, módulos de visión avanzados y una arquitectura de Mezcla de Expertos (MoE), GLM-4.5V destaca en tareas como comprensión de documentos, OCR de video en tiempo real y generación de contenido multimodal, convirtiéndose en una solución versátil y amigable para desarrolladores.
Características de GLM 4.5V que no están en GLM 4.1V
GLM-4.5V demuestra una versatilidad y una integración de herramientas significativamente mayores en comparación con GLM-4.1V. Optimiza tareas que anteriormente requerían múltiples modelos especializados, manejando todo desde el reconocimiento básico de imágenes hasta el análisis complejo de videos y procesamiento de documentos dentro de un solo sistema. Por ejemplo, GLM-4.5V puede generar código frontend a partir de una captura de pantalla de una página web o analizar una imagen de mapa para obtener pistas de geolocalización. Su capacidad para integrar el razonamiento con herramientas externas y producir resultados estructurados lo distingue de GLM-4.1V, convirtiendo a 4.5V en una plataforma de IA multimodal más amigable para desarrolladores y escalable.

Comparación de arquitectura entre GLM 4.5V y GLM 4.1V
| Aspecto | GLM-4.1V | GLM-4.5V |
|---|---|---|
| Escala | 9B parámetros, transformador denso. | 106B en total, 12B activos mediante Mezcla de Expertos (MoE). |
| Especialización | Modelo generalista. | Expertos específicos de dominio mediante MoE para un mejor rendimiento en tareas. |
| Módulos de visión | Solo procesamiento de imágenes 2D. | Añade convolución 3D para reconocimiento de video e interfaces gráficas de usuario (GUI). |
| Codificación de contexto | RoPE 2D para ~64k tokens. | RoPE 3D para 64k tokens + entrada multidimensional |
| Modelo base | Basado en GLM-4 (9B). | Construido sobre GLM-4.5-Air, con capacidades lingüísticas y multimodales mejoradas. |
Comparación de benchmarks entre GLM 4.5V y GLM 4.1V
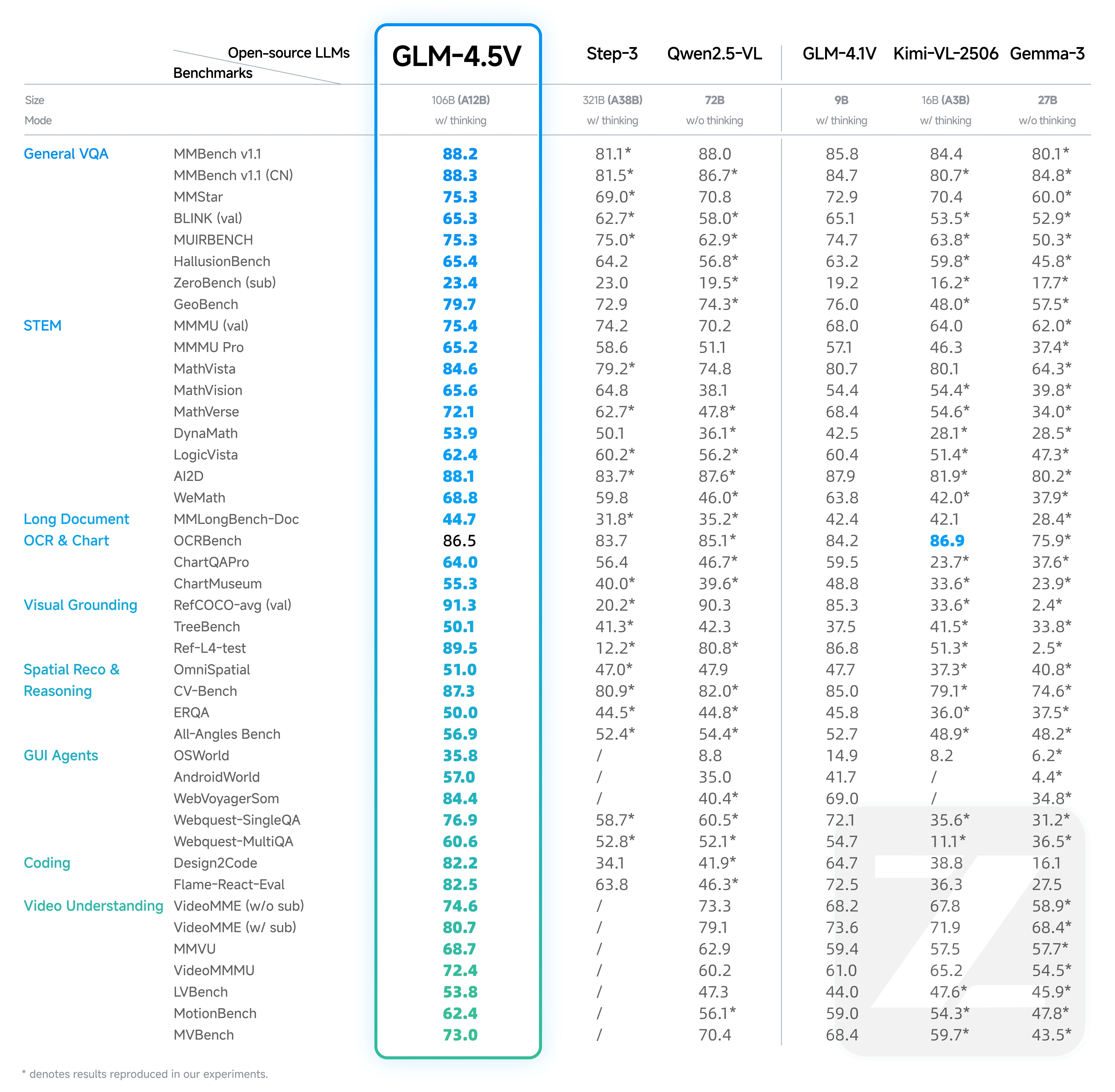
De Hugging Face
Logros de GLM-4.1V:
- Superó a modelos más grandes como Qwen-2.5-VL (7B) y rivalizó con Qwen-72B a pesar de su tamaño más reducido.
- Definió el estado del arte para modelos de pequeña escala antes de 2025.
Avances de GLM-4.5V:
- Superó a los modelos abiertos en su rango de parámetros y obtuvo mejores resultados que algunos modelos más grandes.
- Superó a Step-3 (321B parámetros) en múltiples benchmarks clave, demostrando su eficiencia y precisión.
Puntos fuertes clave de GLM-4.5V:
- Destaca en preguntas y respuestas visuales generales, razonamiento STEM y OCR de documentos largos.
- Aprovecha la arquitectura MoE y optimizaciones de entrenamiento avanzadas para obtener un rendimiento superior.
Comparación de hardware entre GLM 4.5V y GLM 4.1V
| Aspecto | GLM-4.1V | GLM-4.5V |
|---|---|---|
| Requisitos de VRAM | 24GB (por ejemplo, NVIDIA A100 40GB, RTX 4090) | 80GB por GPU; normalmente requiere 8 GPUs de 80GB para el despliegue completo. |
| Configuración de GPU | Es suficiente con una GPU de gama alta única. | Se requiere configuración multigpu (por ejemplo, 8 GPUs) o clústeres de GPU en la nube. |
| Compatibilidad con CPU | Se puede ejecutar en CPU (no en tiempo real) con optimizaciones. | No está diseñado para CPU; demanda hardware avanzado o soluciones basadas en la nube. |
| Opciones de cuantización | Soporta cuantización de 16 bits, 8 bits e incluso de 4 bits para reducir el consumo de memoria. | Ofrece versiones optimizadas en memoria (por ejemplo, cuantización FP8) para aliviar las demandas de hardware. |
Al ofrecer un modo de razonamiento flexible y ajustes eficientes de velocidad-precisión, GLM-4.5V minimiza los requisitos de hardware, lo que lo hace adecuado tanto para casos de uso de alto rendimiento como para casos de uso ligeros en tiempo real.
Comparación de aplicaciones entre GLM 4.5V y GLM 4.1V
GLM 4.5V
1. Comprensión de documentos
- Reconoce y analiza texto en documentos complejos.
- Maneja escritura a mano, sellos, marcas de agua y distorsiones.
- Extrae información clave y genera resúmenes estructurados. 2. Reconocimiento y reconstrucción de tablas
- Procesa tablas complejas con celdas combinadas y estructuras anidadas.
- Infiere datos faltantes y garantiza la coherencia.
- Convierte tablas basadas en imágenes en Excel, CSV, etc. 3. Generación de contenido multimodal
- Genera informes y resúmenes basados en texto reconocido, gráficos o imágenes.
- Proporciona análisis de tendencias y recomendaciones procesables.
- Admite la creación a partir de notas escritas a mano o formularios. 4. OCR de video en tiempo real
- Extrae subtítulos y texto en pantalla de flujos de video.
- Rastrea el texto en movimiento de forma dinámica y se adapta a cambios de escena.
- Reconoce múltiples idiomas en tiempo real.
GLM 4.1V
- Herramientas educativas
- Ideal para enseñar razonamiento de IA paso a paso con análisis de imágenes.
- Proporciona tanto respuestas como razonamientos, ayudando a comprender la toma de decisiones de la IA.
- Aplicaciones sensibles
- Útil en campos como el análisis de imágenes médicas donde la transparencia y las explicaciones de cadena de pensamiento son críticas.
- Sistemas ligeros
- Se puede desplegar en aplicaciones web sencillas o dispositivos con recursos de back-end mínimos.
- Experimentación e investigación
- El tamaño compacto del modelo lo hace accesible para investigadores y desarrolladores con potencia de computación limitada.
- Sistemas de tutoría
- Habilita capacidades de lenguaje y visión para entornos de aprendizaje interactivo.
Prueba GLM4.5V y GLM 4.1V ahora!
Ventajas de costo de GLM 4.5V
Alto rendimiento de la Prueba LLMOCR
- Precisión general: 98,7 % en 1000 documentos de tipo mixto.
- Puntos fuertes específicos:
- Reconocimiento de chino: 99,3 %.
- Reconocimiento de inglés: 98,9 %.
- Restauración de tablas: 97,5 %.
- Reconocimiento de escritura a mano: 96,8 %.
- Eficiencia: Procesa documentos en 0,42 segundos/página con una tasa de éxito de llamadas a la API del 99,95 %.
Eficiencia de costos
- Costo medio: ¥0,015/página.
- Ahorros:
- Reducción de costos del 73 % en comparación con GPT-4V.
- Reducción de costos del 65 % en comparación con Claude-3.
Novita AI: Proveedor de API de GLM 4.5V más rentable y estable
La API de GLM-4.5V de Novita AI ofrece un contexto de 65,5K, con un precio de entrada de $0,60/1K tokens, salida de $1,80/1K tokens, y soporta llamadas a funciones y resultados estructurados.
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

Prueba GLM4.5V y GLM 4.1V ahora!
Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.

Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Entrando en la página de “Ajustes”, puedes copiar la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API utilizando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de finalizaciones de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Construye una herramienta de reconocimiento de imágenes sencilla usando MCP y GLM
Si quieres aprovechar las capacidades de GLM, como construir una herramienta de reconocimiento de imágenes sencilla para demostrar su integración de reconocimiento visual y razonamiento, puedes usar la funcionalidad MCP soportada por Novita AI. A continuación tienes el código de ejemplo:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
Si quieres obtener los detalles, puedes consultar este artículo: Cómo construir tu primer servidor MCP con Novita AI!
GLM-4.5V supera a su predecesor GLM-4.1V en todos los aspectos: desde su capacidad para procesar visuales complejos y documentos largos hasta el ahorro de costos y la optimización superior de hardware. Con su arquitectura mejorada y su amplio rango de aplicaciones, es un cambio de juego para desarrolladores y empresas que buscan una solución de IA todo en uno.
¿Cuáles son las mejoras arquitectónicas clave en GLM-4.5V?
GLM-4.5V introduce una arquitectura de Mezcla de Expertos (MoE) con 106B parámetros (12B activos), codificación RoPE 3D y convolución 3D para reconocimiento de video e interfaces gráficas de usuario (GUI), superando el diseño de transformador denso de GLM-4.1V. Muestra los pasos, no solo da respuestas.
¿Cómo maneja GLM-4.5V las tareas multimodales?
GLM-4.5V integra módulos de visión avanzados para reconocimiento 3D de video e interfaces gráficas de usuario (GUI), permitiendo tareas como OCR de video en tiempo real, análisis de geolocalización y generación de contenido multimodal.
¿Qué tareas son más adecuadas para GLM-4.5V en comparación con GLM-4.1V?
GLM-4.5V destaca en comprensión de documentos (incluyendo escritura a mano y marcas de agua), reconstrucción de tablas, OCR de video en tiempo real y generación de contenido multimodal, áreas en las que GLM-4.1V tenía limitaciones.
Novita AI es la plataforma en la nube todo en uno que impulsa tus ambiciones de IA. APIs integradas, sin servidor, instancias de GPU: las herramientas rentables que necesitas. Elimina la infraestructura, empieza gratis y haz realidad tu visión de IA.



