

- Funktionen von GLM 4.5V, die GLM 4.1V nicht hat
- GLM 4.5V im Vergleich zu GLM 4.1V: Architekturvergleich
- GLM 4.5V im Vergleich zu GLM 4.1V: Benchmark-Vergleich
- GLM 4.5V im Vergleich zu GLM 4.1V: Hardware-Vergleich
- GLM 4.5V im Vergleich zu GLM 4.1V: Anwendungsvergleich
- Kostenvorteile von GLM 4.5V
- Novita AI: Kosteneffektiverer und stabiler Anbieter der GLM 4.5V API
- Erstellen Sie ein einfaches Bilderkennungstool mit MCP und GLM.
GLM-4.5V stellt einen bedeutenden Sprung gegenüber GLM-4.1V dar und bietet verbesserte Skalierbarkeit, multimodale Fähigkeiten und Kosteneffizienz. Durch die Integration domänenspezifischer Experten, fortschrittlicher Vision-Module und einer Mixture-of-Experts (MoE)-Architektur glänzt GLM-4.5V bei Aufgaben wie Dokumentenverständnis, Echtzeit-Video-OCR und multimodale Inhaltsgenerierung, was es zu einer vielseitigen und entwicklerfreundlichen Lösung macht.
Funktionen von GLM 4.5V, die GLM 4.1V nicht hat
GLM-4.5V zeigt im Vergleich zu GLM-4.1V eine deutlich höhere Vielseitigkeit und Tool-Integration. Es optimiert Aufgaben, die zuvor mehrere spezialisierte Modelle erforderten, und bewältigt alles von grundlegender Bilderkennung bis hin zu komplexer Videoanalyse und Dokumentenverarbeitung in einem einzigen System. Beispielsweise kann GLM-4.5V Frontend-Code aus einem Screenshot einer Webseite generieren oder ein Kartenbild nach Geolocation-Hinweisen analysieren. Seine Fähigkeit, Schlussfolgerungen mit externen Tools zu integrieren und strukturierte Ausgaben zu erzeugen, hebt es von GLM-4.1V ab und macht 4.5V zu einer entwicklerfreundlicheren und skalierbareren multimodalen KI-Plattform.

GLM 4.5V im Vergleich zu GLM 4.1V: Architekturvergleich
| Aspekt | GLM-4.1V | GLM-4.5V |
|---|---|---|
| Skalierung | 9B Parameter, dichter Transformer. | 106B gesamt, 12B aktiv über Mixture-of-Experts (MoE). |
| Spezialisierung | Generalistisches Modell. | Domänenspezifische Experten über MoE für bessere Aufgabenperformance. |
| Vision-Module | Nur 2D-Bildverarbeitung. | Fügt 3D-Faltung für Video- und GUI-Erkennung hinzu. |
| Kontextkodierung | 2D RoPE für ~64k Token. | 3D RoPE für 64k Token + mehrdimensionale Eingaben |
| Basis-Modell | Basiert auf GLM-4 (9B). | Basiert auf GLM-4.5-Air, mit verbesserten Sprach- und multimodalen Fähigkeiten. |
GLM 4.5V im Vergleich zu GLM 4.1V: Benchmark-Vergleich
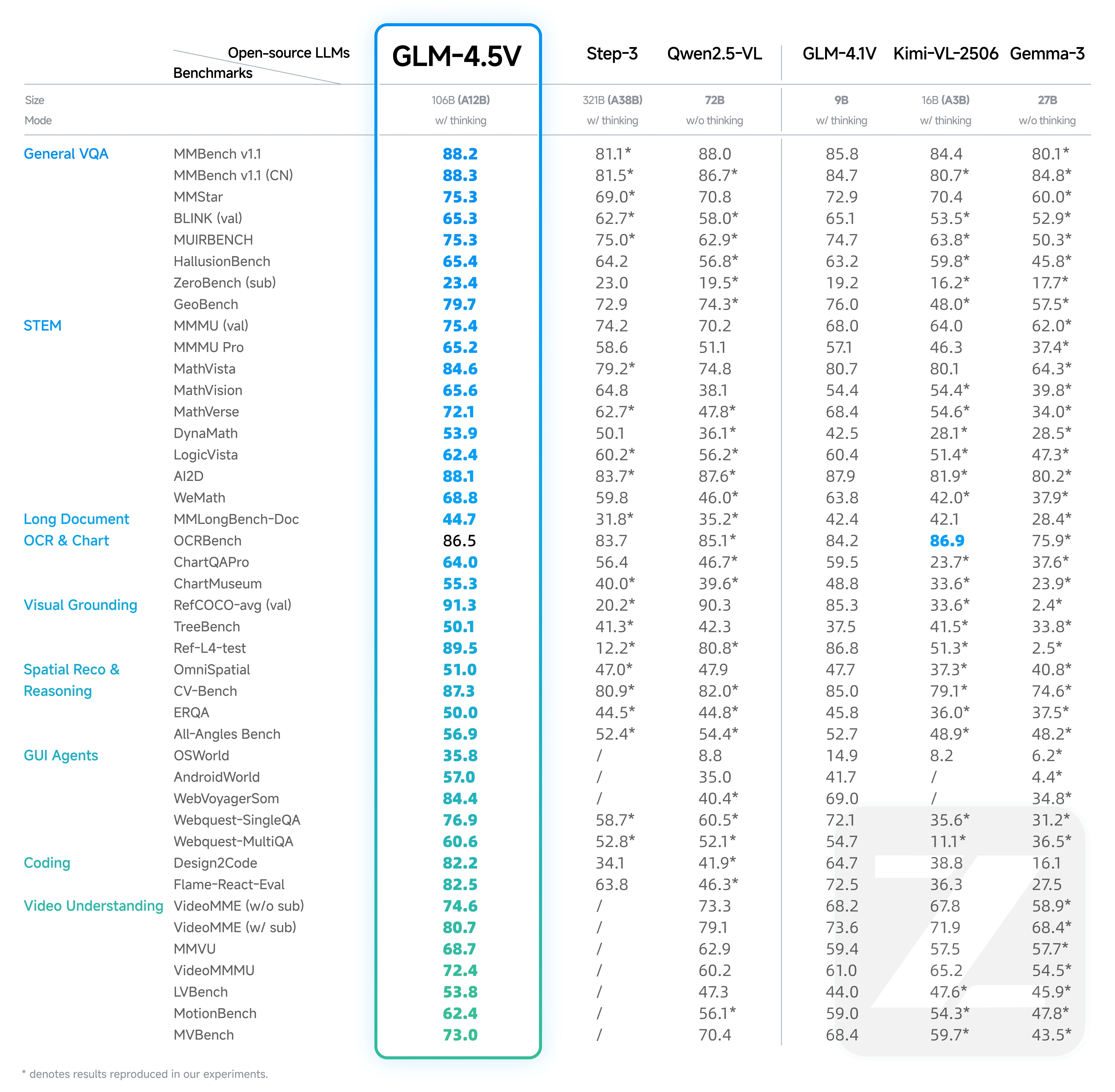
Quelle: Hugging Face
Erfolge von GLM-4.1V:
- Übertraf größere Modelle wie Qwen-2.5-VL (7B) und war trotz seiner geringeren Größe auf Augenhöhe mit Qwen-72B.
- Definierte den Stand der Technik für kleine Modelle vor 2025.
Fortschritte von GLM-4.5V:
- Übertraf Open-Source-Modelle in seinem Parameterbereich und übertraf teilweise sogar größere Modelle.
- Besiegte Step-3 (321B Parameter) bei mehreren wichtigen Benchmarks, was seine Effizienz und Genauigkeit unterstreicht.
Hauptstärken von GLM-4.5V:
- Glänzt bei allgemeiner visueller Q&A, STEM-Schlussfolgerung und OCR für lange Dokumente.
- Nutzt die MoE-Architektur und fortschrittliche Trainingsoptimierungen für überlegene Performance.
GLM 4.5V im Vergleich zu GLM 4.1V: Hardware-Vergleich
| Aspekt | GLM-4.1V | GLM-4.5V |
|---|---|---|
| VRAM-Anforderungen | 24 GB (z. B. NVIDIA A100 40GB, RTX 4090) | 80 GB pro GPU; für den vollständigen Einsatz werden typischerweise 8×80-GB-GPUs benötigt. |
| GPU-Konfiguration | Eine einzelne High-End-GPU reicht aus. | Multi-GPU-Konfiguration (z. B. 8 GPUs) oder Cloud-GPU-Cluster erforderlich. |
| CPU-Kompatibilität | Kann mit Optimierungen auf CPU (nicht in Echtzeit) laufen. | Nicht für CPU ausgelegt; erfordert fortschrittliche Hardware oder cloudbasierte Lösungen. |
| Quantisierungsoptionen | Unterstützt 16-Bit-, 8-Bit- und sogar 4-Bit-Quantisierung zur Reduzierung des Speicherbedarfs. | Bietet speicheroptimierte Versionen (z. B. FP8-Quantisierung) zur Verringerung der Hardwareanforderungen. |
Durch einen flexiblen Reasoning-Modus und effiziente Geschwindigkeits-Genauigkeits-Anpassungen minimiert GLM-4.5V die Hardwareanforderungen, sodass es sowohl für leistungsstarke als auch für leichtgewichtige Echtzeitanwendungen geeignet ist.
GLM 4.5V im Vergleich zu GLM 4.1V: Anwendungsvergleich
GLM 4.5V
1. Dokumentenverständnis
- Erkennt und analysiert Text in komplexen Dokumenten.
- Verarbeitet Handschrift, Stempel, Wasserzeichen und Verzerrungen.
- Extrahiert Schlüsselinformationen und erstellt strukturierte Zusammenfassungen.
2. Tabellenerkennung und -rekonstruktion
- Verarbeitet komplexe Tabellen mit zusammengeführten Zellen und verschachtelten Strukturen.
- Schließt fehlende Daten und gewährleistet Konsistenz.
- Konvertiert bildbasierte Tabellen in Excel, CSV usw.
3. Multimodale Inhaltsgenerierung
- Generiert Berichte und Zusammenfassungen auf Basis erkannter Texte, Diagramme oder Bilder.
- Bietet Trendanalysen und handlungsrelevante Empfehlungen.
- Unterstützt die Erstellung aus handschriftlichen Notizen oder Formularen.
4. Echtzeit-Video-OCR
- Extrahiert Untertitel und on-screen-Text aus Videostreams.
- Verfolgt sich bewegenden Text dynamisch und passt sich an Szenenwechsel an.
- Erkennt mehrere Sprachen in Echtzeit.
GLM 4.1V
- Bildungstools
- Ideal, um KI-Schlussfolgerung Schritt für Schritt mit Bildanalyse zu unterrichten.
- Gibt sowohl Antworten als auch Schlussfolgerungen aus und hilft, das KI-Entscheidungsverhalten zu verstehen.
- Sensible Anwendungen
- Nützlich in Bereichen wie der medizinischen Bildanalyse, wo Transparenz und Chain-of-Thought-Erklärungen kritisch sind.
- Leichtgewichtige Systeme
- Kann auf einfachen Web-Apps oder Geräten mit minimalen Backend-Ressourcen bereitgestellt werden.
- Experimente und Forschung
- Die kompakte Modellgröße macht es für Forscher und Entwickler mit begrenzter Rechenleistung zugänglich.
- Tutorensysteme
- Ermöglicht Vision-Sprache-Fähigkeiten für interaktive Lernumgebungen.
Probieren Sie GLM4.5V und GLM 4.1V jetzt aus!
Kostenvorteile von GLM 4.5V
Hohe Leistung aus dem LLMOCR-Test
- Gesamtgenauigkeit: 98,7 % über 1000 gemischte Dokumente.
- Spezifische Stärken:
- Chinesische Erkennung: 99,3 %.
- Englische Erkennung: 98,9 %.
- Tabellenwiederherstellung: 97,5 %.
- Handschrifterkennung: 96,8 %.
- Effizienz: Verarbeitet Dokumente in 0,42 Sekunden/Seite mit einer API-Erfolgsrate von 99,95 %.
Kosteneffizienz
- Durchschnittskosten: ¥0,015/Seite.
- Einsparungen:
- 73 % Kostensenkung im Vergleich zu GPT-4V.
- 65 % Kostensenkung im Vergleich zu Claude-3.
Novita AI: Kosteneffektiverer und stabiler Anbieter der GLM 4.5V API
Die GLM-4.5V-API von Novita AI bietet einen 65,5K-Kontext, mit Eingaben zum Preis von $0,60/1K Token, Ausgaben zum Preis von $1,80/1K Token, sowie Unterstützung für Funktionsaufrufe und strukturierte Ausgaben.
Schritt 1: Einloggen und Zugriff auf die Modellbibliothek
Loggen Sie sich in Ihrem Konto ein und klicken Sie auf die Schaltfläche Modellbibliothek.

Probieren Sie GLM4.5V und GLM 4.1V jetzt aus!
Schritt 2: Wählen Sie Ihr Modell
Durchstöbern Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.

Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Erstellen Sie ein einfaches Bilderkennungstool mit MCP und GLM.
Wenn Sie die Fähigkeiten von GLM nutzen möchten – beispielsweise um ein einfaches Bilderkennungstool zu erstellen, das die Integration von visueller Erkennung und Schlussfolgerung demonstriert – können Sie die von Novita AI unterstützte MCP-Funktionalität verwenden. Unten finden Sie den Beispielcode:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
Wenn Sie Details erfahren möchten, können Sie diesen Artikel lesen: So erstellen Sie Ihren ersten MCP-Server mit Novita AI!
GLM-4.5V übertrifft seinen Vorgänger GLM-4.1V in jeder Hinsicht: von der Fähigkeit, komplexe visuelle Inhalte und lange Dokumente zu verarbeiten, über Kosteneinsparungen bis hin zu überlegener Hardware-Optimierung. Mit seiner verbesserten Architektur und seinem umfangreichen Anwendungsbereich ist es ein Game-Changer für Entwickler und Unternehmen, die eine All-in-One-KI-Lösung suchen.
Was sind die wichtigsten architektonischen Verbesserungen in GLM-4.5V?
GLM-4.5V führt eine Mixture-of-Experts (MoE)-Architektur mit 106B Parametern (12B aktiv), 3D-RoPE-Kodierung und 3D-Faltung für Video- und GUI-Erkennung ein, die den dichten Transformer von GLM-4.1V übertrifft und Schlussfolgerungsschritte durchführt, statt nur Antworten zu geben.
Wie verarbeitet GLM-4.5V multimodale Aufgaben?
GLM-4.5V integriert fortschrittliche Vision-Module für 3D-Video- und GUI-Erkennung, die Aufgaben wie Echtzeit-Video-OCR, Geolocation-Analyse und multimodale Inhaltsgenerierung ermöglichen.
Für welche Aufgaben eignet sich GLM-4.5V im Vergleich zu GLM-4.1V besser?
GLM-4.5V glänzt bei Dokumentenverständnis (einschließlich Handschrift und Wasserzeichen), Tabellenrekonstruktion, Echtzeit-Video-OCR und multimodaler Inhaltsgenerierung – Bereiche, in denen GLM-4.1V eingeschränkt war.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen verwirklicht. Integrierte APIs, Serverless, GPU-Instanzen – die kosteneffektiven Tools, die Sie brauchen. Eliminieren Sie Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



