

GLM-4.5V는 GLM-4.1V에 비해 상당한 도약을 이루었으며, 향상된 확장성, 멀티모달 능력, 비용 효율성을 제공합니다. 도메인별 전문가 모듈, 고급 비전 모듈, Mixture-of-Experts(MoE) 아키텍처를 통합하여 문서 이해, 실시간 비디오 OCR, 멀티모달 콘텐츠 생성과 같은 작업에서 뛰어난 성능을 발휘하여 다용도이며 개발자 친화적인 솔루션을 제공합니다.
GLM 4.1V에는 없는 GLM 4.5V의 특징
GLM-4.5V는 GLM-4.1V에 비해 훨씬 높은 다용도성과 도구 통합 기능을 보여줍니다. 이전에는 여러 전문 모델이 필요했던 작업을 간소화하여 기본 이미지 인식부터 복잡한 비디오 분석, 문서 처리까지 단일 시스템에서 모두 처리할 수 있습니다. 예를 들어 GLM-4.5V는 웹페이지 스크린샷으로부터 프론트엔드 코드를 생성하거나 지도 이미지를 분석하여 지리적 위치 단서를 찾을 수 있습니다. 추론을 외부 도구와 통합하고 구조화된 출력을 생성하는 능력은 GLM-4.1V와 차별화되며, 4.5V를 더욱 개발자 친화적이고 확장 가능한 멀티모달 AI 플랫폼으로 만듭니다.

GLM 4.5V vs GLM 4.1V: 아키텍처 비교
| 측면 | GLM-4.1V | GLM-4.5V |
|---|---|---|
| 규모 | 90억 개의 매개변수, 밀집 트랜스포머. | 106B 총 매개변수, Mixture-of-Experts(MoE)를 통해 12B 활성화. |
| 전문화 | 일반ist 모델. | MoE를 통한 도메인별 전문가 모듈로 더 나은 작업 성능 제공. |
| 비전 모듈 | 2D 이미지 처리만 지원. | 비디오 및 GUI 인식을 위한 3D 컨볼루션 추가. |
| 컨텍스트 인코딩 | 약 64k 토큰을 위한 2D RoPE. | 64k 토큰을 위한 3D RoPE + 다차원 입력 |
| 기본 모델 | GLM-4(9B) 기반. | 향상된 언어 및 멀티모달 능력을 갖춘 GLM-4.5-Air 기반. |
GLM 4.5V vs GLM 4.1V: 벤치마크 비교
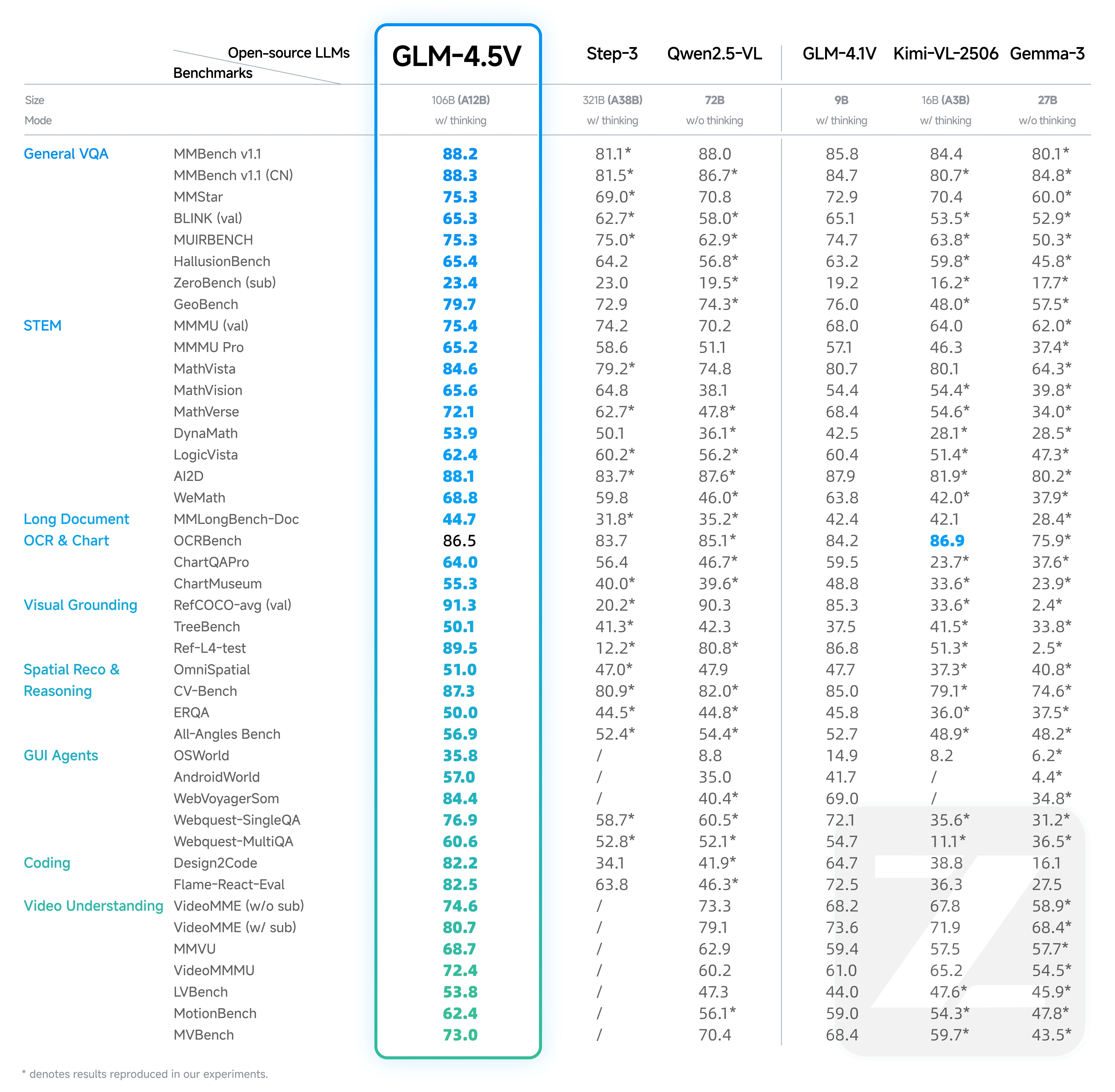
Hugging Face 출처
GLM-4.1V의 성과:
- Qwen-2.5-VL(7B)와 같은 더 큰 모델을 능가하고, 더 작은 크기임에도 불구하고 Qwen-72B와 대등한 성능을 보였습니다.
- 2025년 이전 소형 모델의 최고 수준을 정의했습니다.
GLM-4.5V의 발전:
- 동일한 매개변수 범위의 오픈 모델을 능가하고 일부 더 큰 모델보다 뛰어난 성능을 보였습니다.
- 여러 주요 벤치마크에서 Step-3(321B 매개변수)를 능가하여 효율성과 정확성을 입증했습니다.
GLM-4.5V의 주요 강점:
- 일반 비주얼 QA, STEM 추론, 장문 OCR 분야에서 뛰어납니다.
- MoE 아키텍처와 고급 훈련 최적화를 활용하여 우수한 성능을 제공합니다.
GLM 4.5V vs GLM 4.1V: 하드웨어 비교
| 측면 | GLM-4.1V | GLM-4.5V |
|---|---|---|
| VRAM 요구 사항 | 24GB (예: NVIDIA A100 40GB, RTX 4090) | GPU당 80GB; 전체 배포를 위해 일반적으로 8×80GB GPU가 필요합니다. |
| GPU 설정 | 단일 고성능 GPU로 충분합니다. | 다중 GPU 설정(예: 8개 GPU) 또는 클라우드 GPU 클러스터가 필요합니다. |
| CPU 호환성 | 최적화를 통해 CPU(비실시간)에서 실행 가능합니다. | CPU용으로 설계되지 않았음; 고급 하드웨어 또는 클라우드 기반 솔루션이 필요합니다. |
| 양자화 옵션 | 메모리 절약을 위해 16비트, 8비트, 심지어 4비트 양자화를 지원합니다. | FP8 양자화 등 메모리 최적화 버전을 제공하여 하드웨어 부담을 완화합니다. |
유연한 추론 모드와 효율적인 속도-정확도 조정을 제공하여 GLM-4.5V는 하드웨어 요구 사항을 최소화하여 고성능 및 경량 실시간 사용 사례 모두에 적합합니다.
GLM 4.5V vs GLM 4.1V: 응용 분야 비교
GLM 4.5V
- 문서 이해
- 복잡한 문서의 텍스트를 인식하고 분석합니다.
- 손글씨, 도장, 워터마크, 왜곡을 처리합니다.
- 핵심 정보를 추출하고 구조화된 요약을 생성합니다.
- 표 인식 및 재구성
- 병합 셀과 중첩 구조가 있는 복잡한 표를 처리합니다.
- 누락된 데이터를 추론하고 일관성을 보장합니다.
- 이미지 기반 표를 Excel, CSV 등으로 변환합니다.
- 멀티모달 콘텐츠 생성
- 인식된 텍스트, 차트, 이미지를 기반으로 보고서 및 요약을 생성합니다.
- 추세 분석 및 실행 가능한 권장 사항을 제공합니다.
- 손글씨 노트나 양식에서 생성하는 것을 지원합니다.
- 실시간 비디오 OCR
- 비디오 스트림에서 자막과 화면 텍스트를 추출합니다.
- 이동하는 텍스트를 동적으로 추적하고 장면 변화에 적응합니다.
- 실시간으로 여러 언어를 인식합니다.
GLM 4.1V
- 교육 도구
- 이미지 분석을 통한 AI 추론을 단계별로 가르치기에 이상적입니다.
- 답변과 추론 과정을 모두 출력하여 AI 의사 결정 이해를 돕습니다.
- 민감한 응용 분야
- 투명성과 사고의 흐름 설명이 중요한 의료 이미지 분석과 같은 분야에서 유용합니다.
- 경량 시스템
- 최소한의 백엔드 리소스로 간단한 웹 앱이나 기기에 배포할 수 있습니다.
- 실험 및 연구
- 컴팩트한 모델 크기로 제한된 컴퓨팅 파워를 가진 연구자와 개발자에게 접근 가능합니다.
- 튜터링 시스템
- 대화형 학습 환경을 위한 비전-언어 기능을 제공합니다.
지금 GLM4.5V and GLM 4.1V를 사용해 보세요!
GLM 4.5V의 비용 효율성
높은 성능 출처: LLMOCR 테스트
- 전체 정확도: 1000개의 혼합 유형 문서에서 98.7%.
- 세부 강점:
- 중국어 인식: 99.3%.
- 영어 인식: 98.9%.
- 표 복원: 97.5%.
- 손글씨 인식: 96.8%.
- 효율성: 페이지당 0.42초로 문서를 처리하며 API 호출 성공률 99.95%를 기록합니다.
비용 효율성
- 평균 비용: 페이지당 ¥0.015.
- 비용 절감 효과:
- GPT-4V 대비 73% 비용 절감.
- Claude-3 대비 65% 비용 절감.
Novita AI: 더욱 비용 효율적이고 안정적인 GLM 4.5V API 제공자
Novita AI의 GLM-4.5V API는 65.5K 컨텍스트를 제공하며, 입력은 1K 토큰당 $0.60, 출력은 1K 토큰당 $1.80의 가격으로 책정되어 있으며, 함수 호출 및 구조화된 출력을 지원합니다.
1단계: 로그인 후 모델 라이브러리 접근 계정에 로그인한 후 모델 라이브러리 버튼을 클릭하세요.

지금 GLM4.5V and GLM 4.1V를 사용해 보세요!
2단계: 모델 선택 사용 가능한 옵션을 둘러보고 필요에 맞는 모델을 선택하세요.

3단계: 무료 체험 시작 선택한 모델의 기능을 탐색하기 위해 무료 체험을 시작하세요.

4단계: API 키 발급 API 인증을 위해 새로운 API 키를 발급해 드립니다. ‘설정’ 페이지에 접속하여 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치 사용 중인 프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치하세요.
설치 후 필요한 라이브러리를 개발 환경으로 가져오세요. API 키로 API를 초기화하여 Novita AI LLM과 상호작용을 시작할 수 있습니다. 아래는 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
MCP와 GLM을 활용한 간단한 이미지 인식 도구 구축
GLM의 기능을 활용하여 시각 인식과 추론의 통합을 보여주는 간단한 이미지 인식 도구를 구축하려는 경우, Novita AI가 지원하는 MCP 기능을 사용할 수 있습니다. 아래는 샘플 코드입니다:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
자세한 내용은 다음 문서를 확인하세요: Novita AI로 첫 번째 MCP 서버 구축하기!
GLM-4.5V는 복잡한 시각 자료와 장문 처리 능력, 비용 절감, 우수한 하드웨어 최적화에 이르기까지 모든 측면에서 전작인 GLM-4.1V를 능가합니다. 향상된 아키텍처와 광범위한 응용 분야를 바탕으로 올인원 AI 솔루션을 찾는 개발자와 기업에게 게임 체인저입니다.
GLM-4.5V의 주요 아키텍처 개선 사항은 무엇인가요? GLM-4.5V는 106B 매개변수(12B 활성)의 Mixture-of-Experts(MoE) 아키텍처, 3D RoPE 인코딩, 비디오 및 GUI 인식을 위한 3D 컨볼루션을 도입하여 GLM-4.1V의 밀집 트랜스포머 설계를 능가합니다.g 단계를 제공하며, 단순히 답변만 주는 것이 아닙니다.
GLM-4.5V는 멀티모달 작업을 어떻게 처리하나요? GLM-4.5V는 3D 비디오 및 GUI 인식을 위한 고급 비전 모듈을 통합하여 실시간 비디오 OCR, 지리적 위치 분석, 멀티모달 콘텐츠 생성과 같은 작업을 가능하게 합니다.
GLM-4.1V와 비교했을 때 GLM-4.5V가 더 적합한 작업은 무엇인가요? GLM-4.5V는 문서 이해(손글씨 및 워터마크 포함), 표 재구성, 실시간 비디오 OCR, 멀티모달 콘텐츠 생성 분야에서 뛰어난 성능을 발휘하며, 이러한 분야는 GLM-4.1V가 제한적이었던 부분입니다.
Novita AI는 AI 야망을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 필요한 비용 효율적인 도구를 제공합니다. 인프라를 제거하고 무료로 시작하여 AI 비전을 현실로 만드세요.



