

DeepSeek 模型已成为大语言模型(LLM)领域的一个极具吸引力的选择,在提供出色性能的同时保持了有竞争力的成本。尽管这些模型功能强大,但要成功部署,仍需要稳健高效的基础设施解决方案。本指南将演示如何利用 Novita AI 的云平台,以兼顾高性能和成本效益的方式,优化 DeepSeek 模型的部署。
模型变体概览
蒸馏版本
- 基于开源模型(Qwen2.5 和 Llama 系列)
- 参数范围:1.5B、7B、8B、14B、32B 和 70B
- 在保持高性能的同时,针对高效推理进行了优化
- 非常适合高性价比的私有部署
- 可通过 Novita AI 的一键式解决方案轻松部署
全尺寸版本
- DeepSeek-R1-671B
- 基于 DeepSeek-V3 架构
- 拥有 671B 参数,性能最大
- 对计算资源要求较高
- 可通过我们优化的 API 服务使用
部署指南
第一步:访问 Novita AI 平台
- 访问 Novita AI 官方网站:https://novita.ai/
[立即尝试 Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Deploying DeepSeek Models on Novita AI Cloud Platform: A Comprehensive Guide)
- 创建账号或登录已有账号

第二步:访问 GPU 实例配置
- 在主导航中点击 “GPUs”
- 点击 “Get Started” 继续
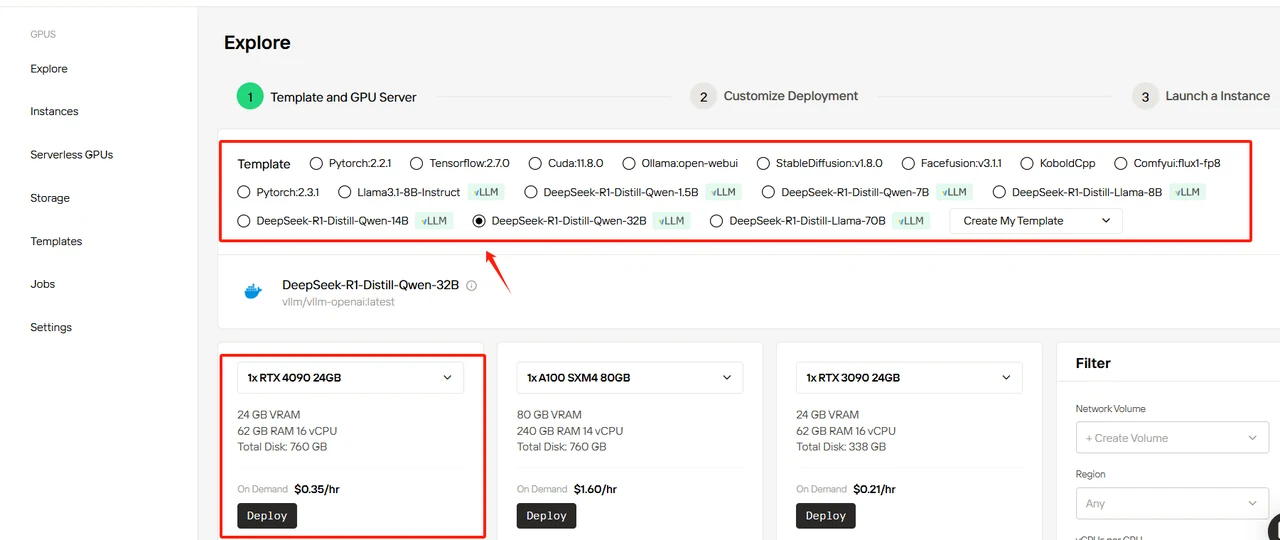
第三步:选择并配置 DeepSeek 模型
在本指南中,我们将以 DeepSeek-R1-Distill-Llama-32B 为例。您可以根据需要选择任意模板,但模板定义了模型的基础参数。您需要配置所需的 GPU 数量——对于此次部署,我们推荐使用 RTX 4090。所有模板均使用官方 DeepSeek 模型,默认精度为 BF16。以下是我们的推荐配置:
| 模型 | GPU 精度 | GPU 型号 | 数量 |
| DeepSeek-R1-Distill-Qwen-1.5B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Qwen-7B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Llama-8B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Qwen-14B | BF16 | RTX 4090 | 2 |
| DeepSeek-R1-Distill-Qwen-32B | BF16 | RTX 4090 | 4 |
| DeepSeek-R1-Distill-Llama-70B | BF16 | RTX 4090 | 8 |
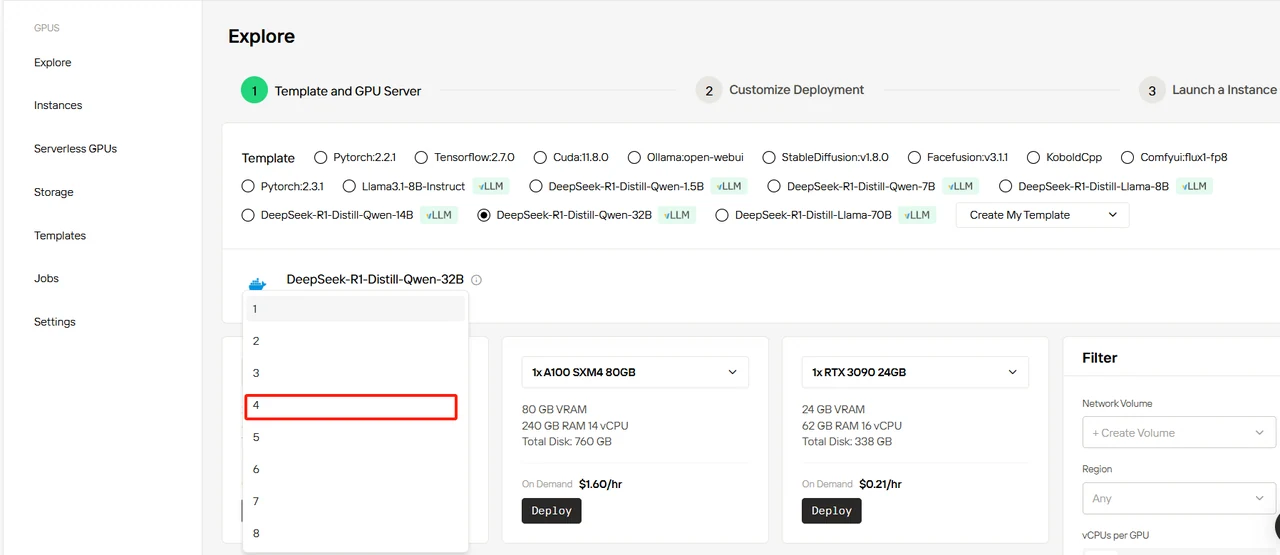
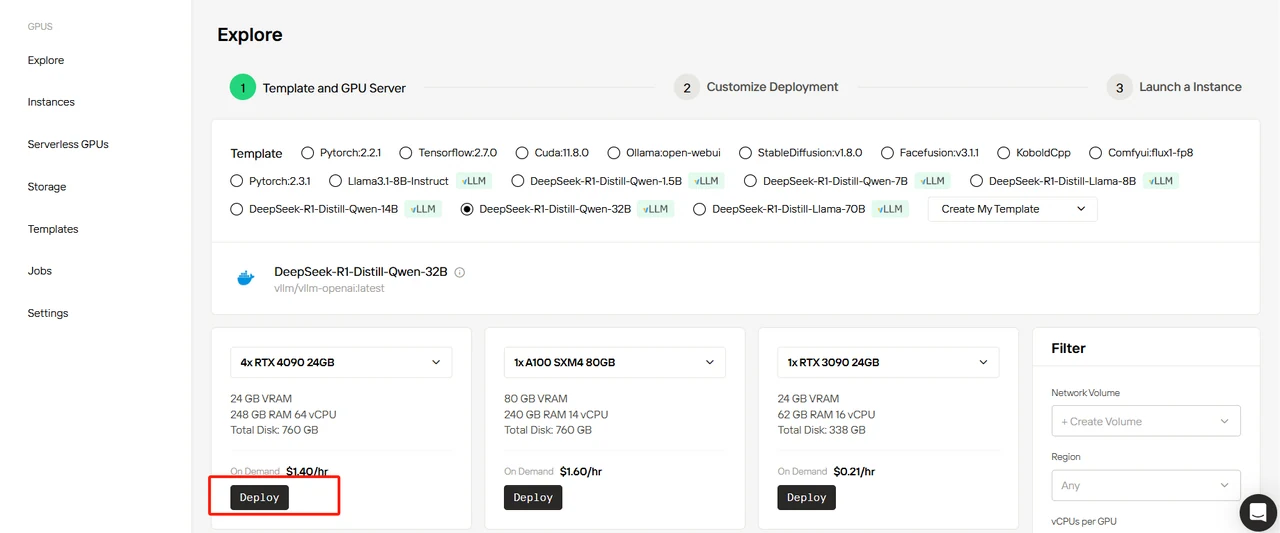
选择 DeepSeek-R1-Distill-Qwen-32B 模板,设置 4 个 GPU,然后点击 “Deploy”。
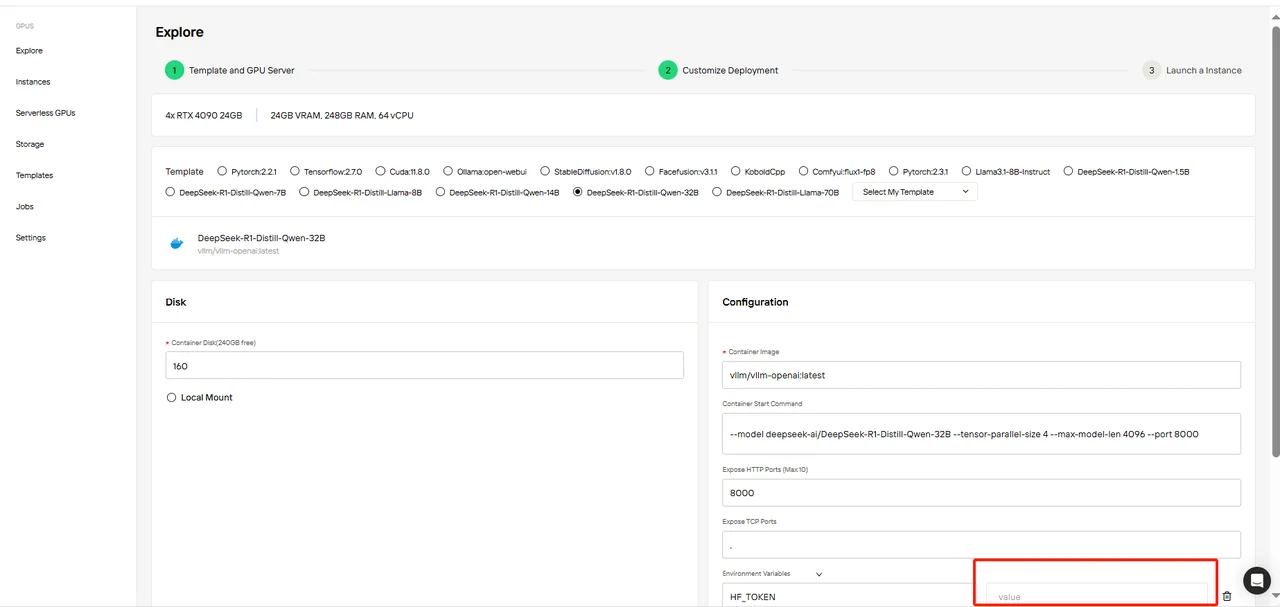
第四步:自定义部署
确认模板参数,并务必填写 HF_TOKEN 环境变量。
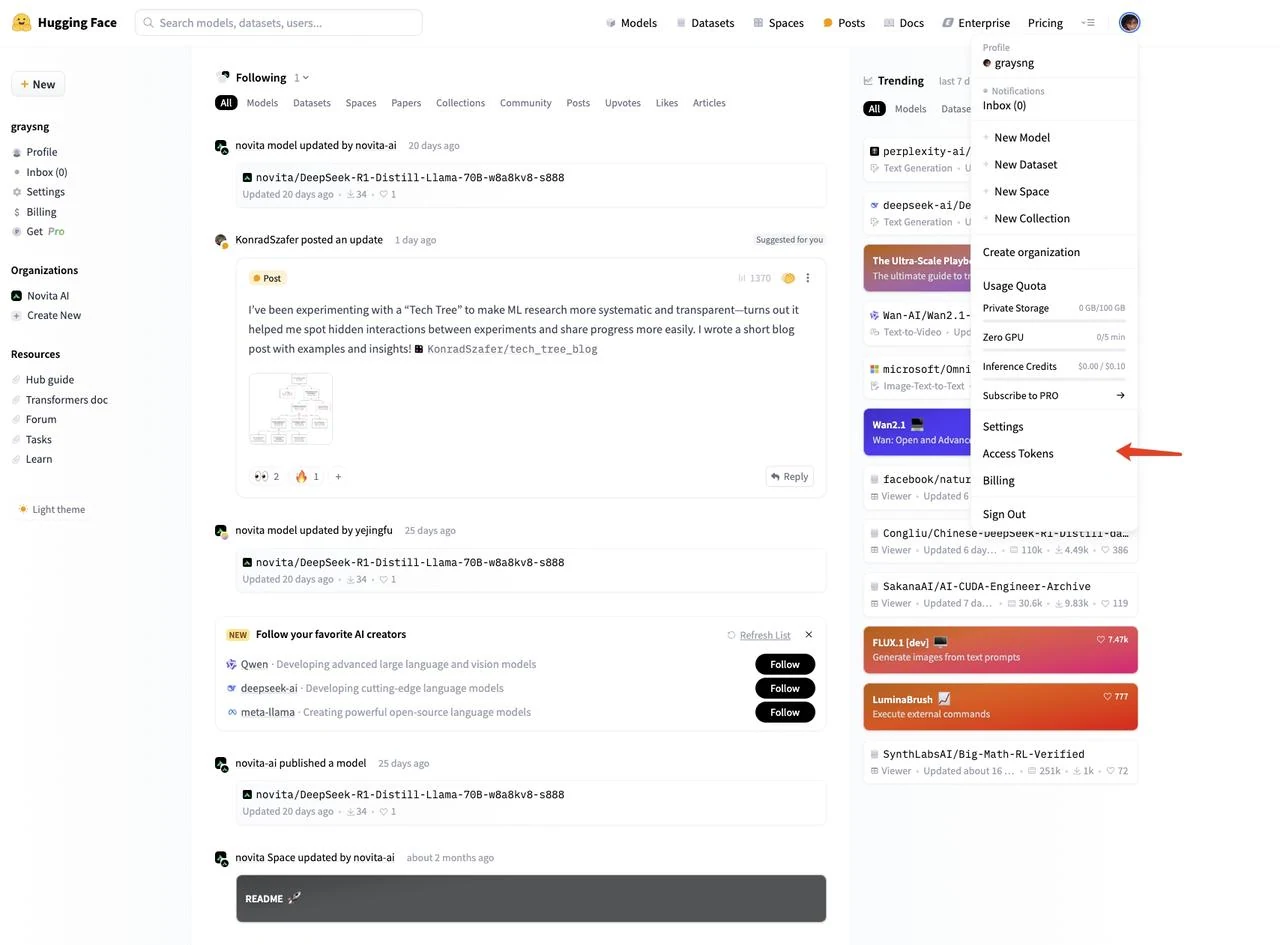
按照以下提示获取 HF_TOKEN:
-
点击右上角的 “Log In” 登录,或点击 “Sign Up” 创建新账号
-
登录后,点击右上角的个人头像,在左侧菜单中选择 “Access Tokens”
- 点击 “New token” 创建新的访问令牌
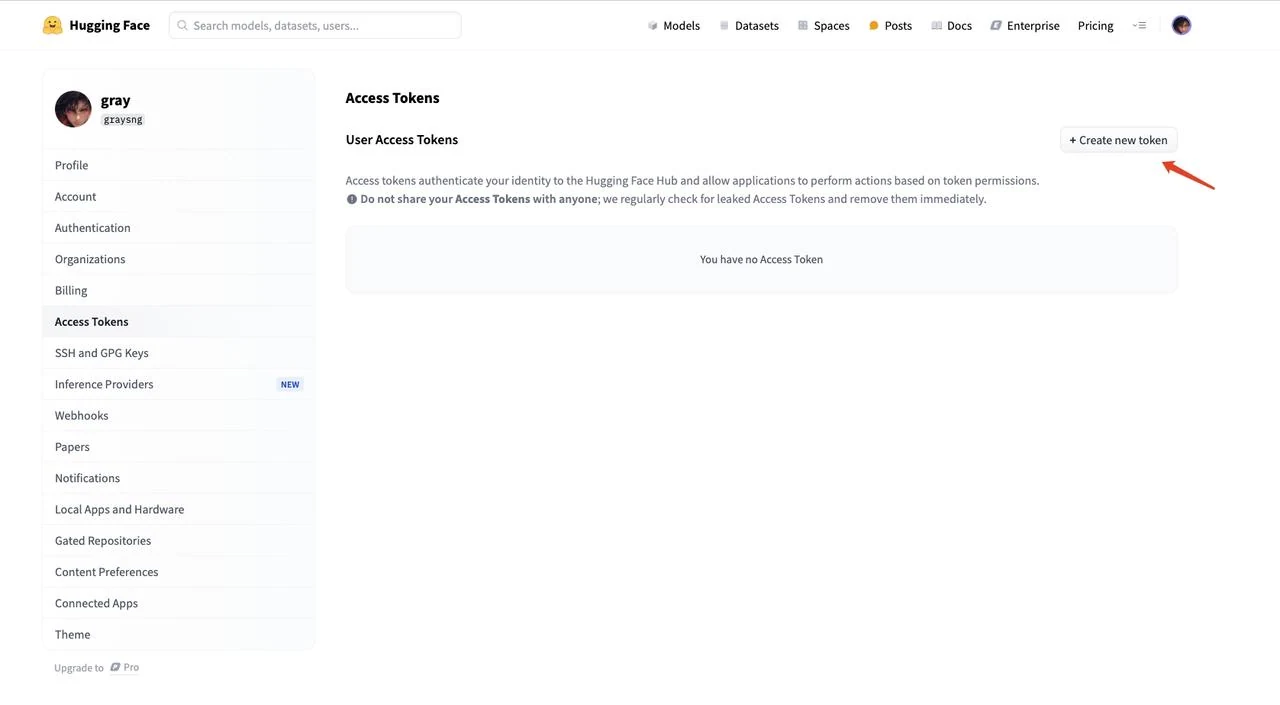
- 选择 “Read” 作为令牌类型,为令牌命名(例如 “text”),然后点击 “Create token” 生成令牌。
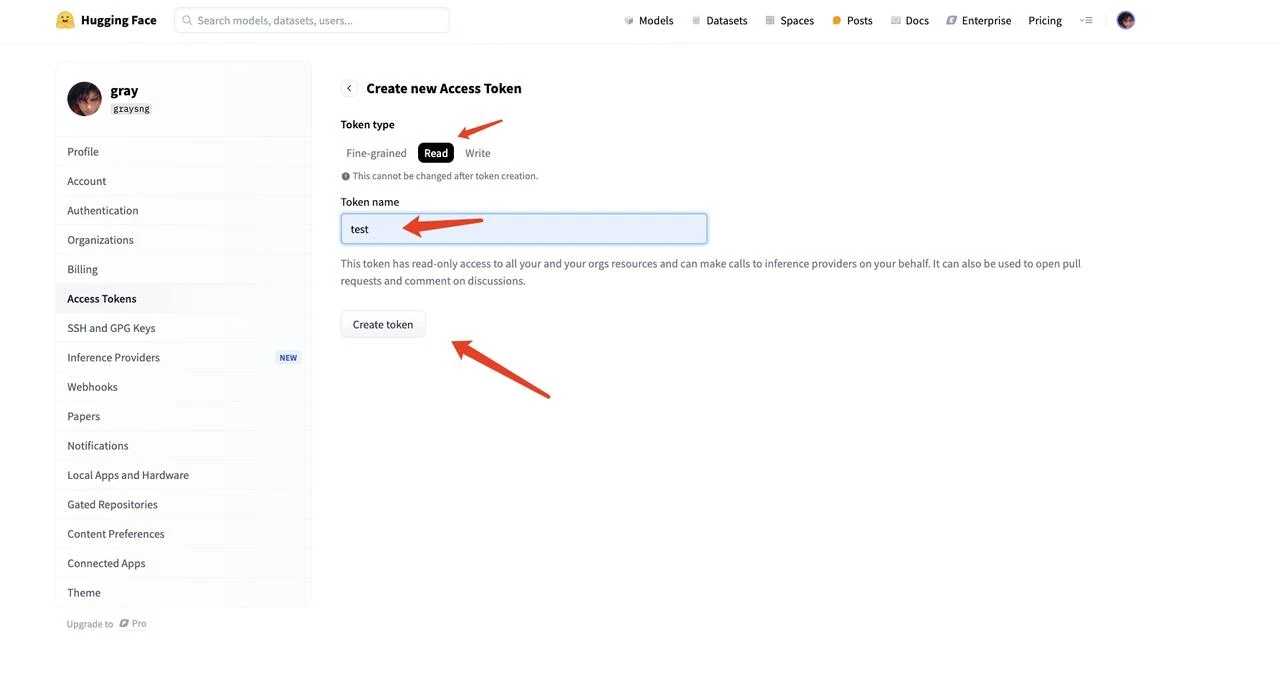
- 复制生成的令牌字符串
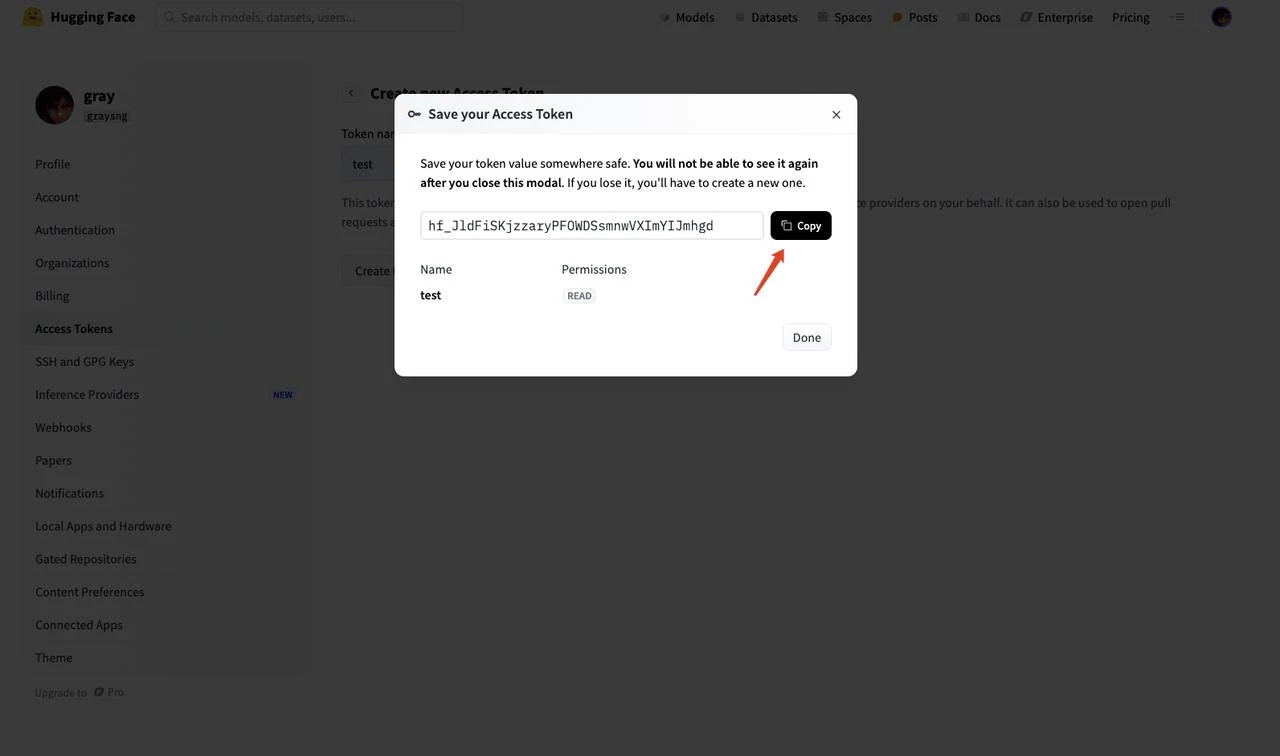
获取令牌后,将其填入模板中的 HF_TOKEN 环境变量。然后点击 “Next”。
第五步:启动实例
点击 “Launch Instance” 部署配置好的环境。
等待几分钟,等待实例配置和管理完成。
点击下拉菜单查看实例日志。

实例启动后,将开始拉取模型。点击 “Logs” --> “Instance Logs” 监控模型下载进度。
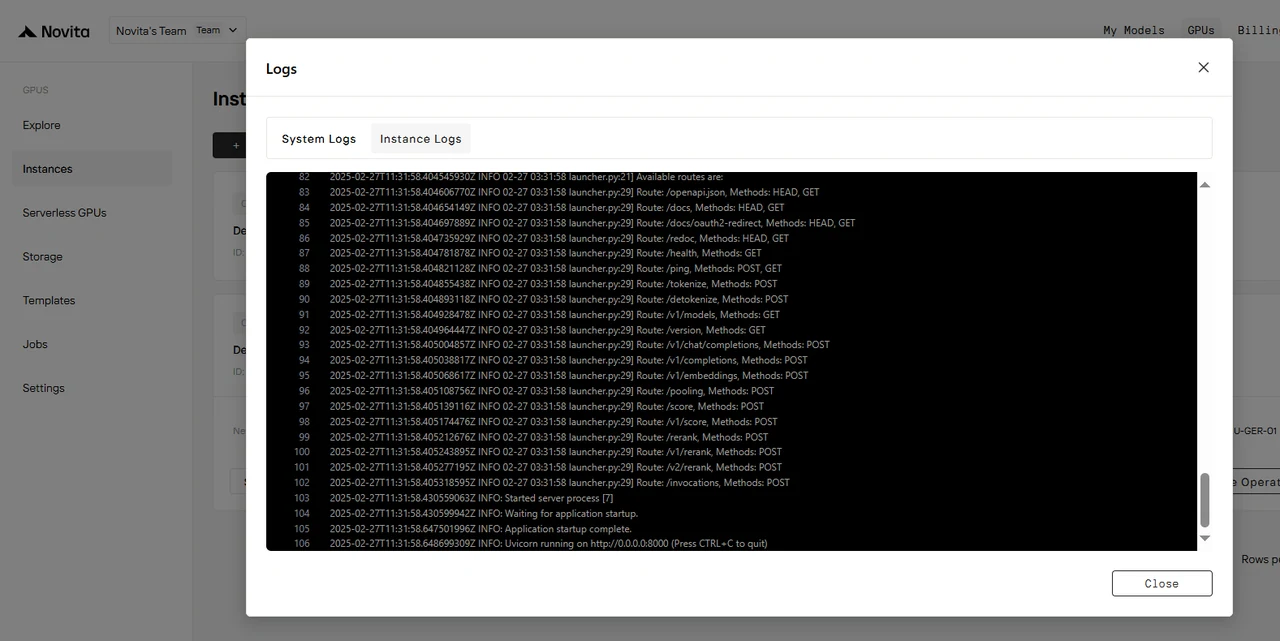
当日志显示 “INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)” 时,即表示启动成功。现在让我们访问您的私有模型!
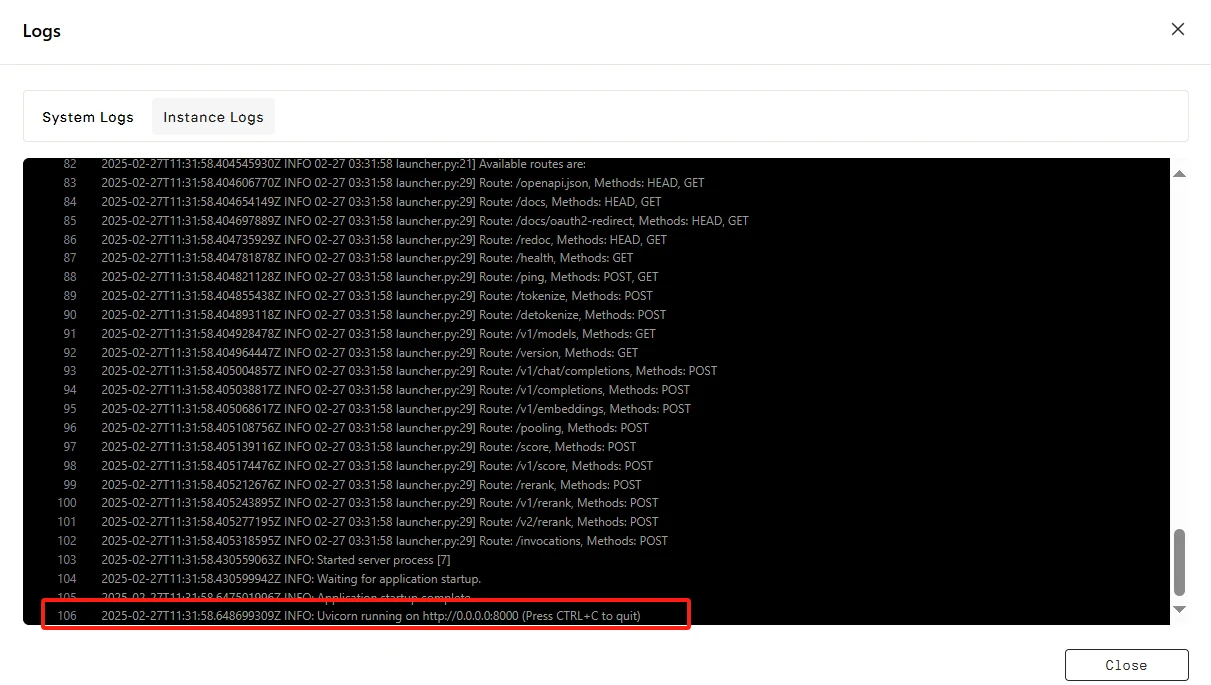
点击 “Connect”,然后点击 --> “Connect to HTTP Service [Port 8000]”。由于这是一个 API 服务,您需要复制地址。


要向您的私有模型发送请求,请将 “https://f6d29cb6f71e585e-8000.us-ca-1.gpu-instance.novita.ai” 替换为您的实际暴露地址。复制以下代码即可访问您的私有模型!
$ curl https://f6d29cb6f71e585e-8000.us-ca-1.gpu-instance.novita.ai/v1/chat/completions \
-H "Content-Type: application/json" -d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"messages": [{"role": "user", "content": "hello"}]
}'
{"id":"chatcmpl-57b3296f87f54dd4b69cfb6d2196f48e","object":"chat.completion","created":1740711405,"model":"deepseek-ai/DeepSeek-R1-Distill-Qwen-32B","choices":[{"index":0,"message":{"role":"assistant","content":"Alright, the user said \"hello.\" That's a friendly greeting. I should respond in a welcoming manner.\
\
Maybe I can acknowledge their greeting and offer assistance.\
\
It's important to sound approachable and ready to help.\
\
I'll keep it simple and polite.\
response\
\
Hello! How can I assist you today?","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":6,"total_tokens":70,"completion_tokens":64,"prompt_tokens_details":null},"prompt_logprobs":null}

在您的应用程序(如 Chatbox)中配置 API 地址,您就拥有了自己的私人助手!
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Deploying DeepSeek Models on Novita AI Cloud Platform: A Comprehensive Guide) 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时也提供经济实惠且可靠的 GPU 云用于构建和扩展。



