

DeepSeek-Modelle haben sich als überzeugende Wahl im LLM-Bereich etabliert und bieten beeindruckende Leistung zu wettbewerbsfähigen Kosten. Obwohl diese Modelle leistungsstarke Fähigkeiten bieten, erfordert eine erfolgreiche Bereitstellung eine robuste und effiziente Infrastrukturlösung. Dieser Leitfaden zeigt, wie Sie die Cloud-Plattform von Novita AI für eine optimale DeepSeek-Modellbereitstellung nutzen können, die hohe Leistung mit Kosteneffizienz verbindet.
Übersicht über die Modellvarianten
Destillierte Versionen
- Basieren auf Open-Source-Modellen (Qwen2.5- und Llama-Serie)
- Parameterbereiche: 1,5B, 7B, 8B, 14B, 32B und 70B
- Optimiert für effiziente Inferenz bei gleichbleibend hoher Leistung
- Ideal für kosteneffiziente private Bereitstellungen
- Einfach bereitzustellen über die Ein-Klick-Lösung von Novita AI
Vollständige Version
- DeepSeek-R1-671B
- Basiert auf der DeepSeek-V3-Architektur
- Verfügt über 671B Parameter für maximale Leistung
- Erfordert erhebliche Rechenressourcen
- Verfügbar über unseren optimierten API-Dienst
Bereitstellungsleitfaden
Schritt 1: Zugriff auf die Novita AI-Plattform
- Besuchen Sie die offizielle Website von Novita AI:https://novita.ai/
[Jetzt Novita AI ausprobieren](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Deploying DeepSeek Models on Novita AI Cloud Platform: A Comprehensive Guide)
- Erstellen Sie ein Konto oder melden Sie sich in Ihrem bestehenden Konto an

Schritt 2: Zugriff auf die GPU-Instanzkonfiguration
- Klicken Sie in der Hauptnavigation auf „GPUs“
- Klicken Sie auf „Loslegen“, um fortzufahren
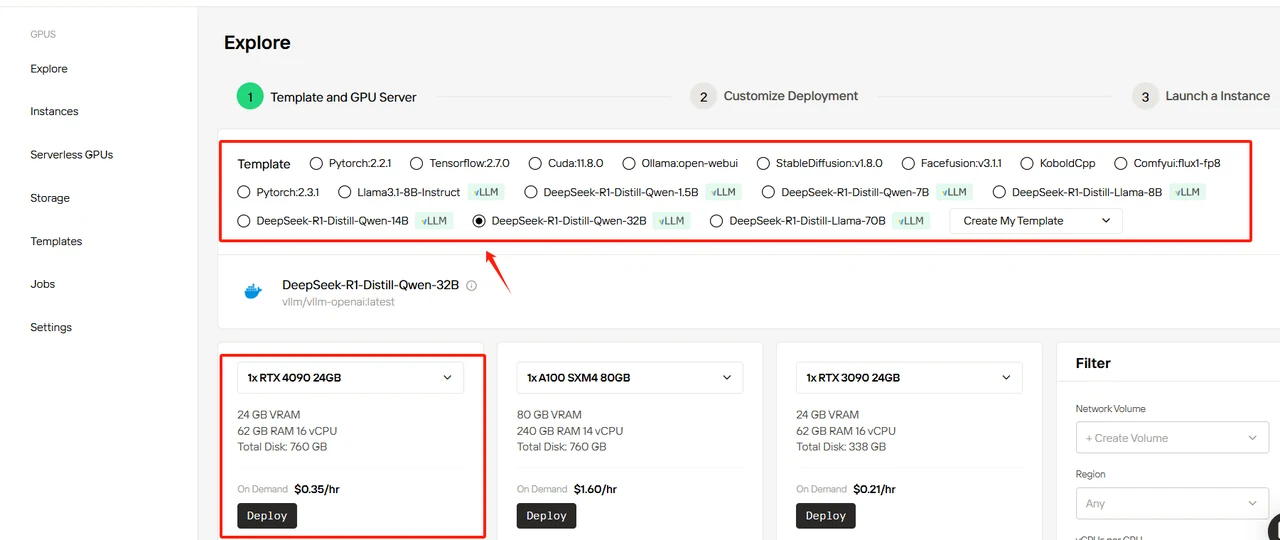
Schritt 3: DeepSeek-Modell auswählen und konfigurieren
In diesem Leitfaden verwenden wir DeepSeek-R1-Distill-Llama-32B als Beispiel. Sie können jede Vorlage basierend auf Ihren Anforderungen auswählen. Diese Vorlage definiert die Basiseinstellungen des Modells. Sie müssen die erforderliche Anzahl von GPUs konfigurieren – wir empfehlen die Verwendung der RTX 4090 für diese Bereitstellung. Alle Vorlagen verwenden offizielle DeepSeek-Modelle mit einer Standard-BF16-Präzision. Nachfolgend finden Sie unsere empfohlenen Konfigurationen:
| Modell | GPU | GPU | Anzahl |
| DeepSeek-R1-Distill-Qwen-1.5B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Qwen-7B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Llama-8B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Qwen-14B | BF16 | RTX 4090 | 2 |
| DeepSeek-R1-Distill-Qwen-32B | BF16 | RTX 4090 | 4 |
| DeepSeek-R1-Distill-Llama-70B | BF16 | RTX 4090 | 8 |
Wählen Sie die Vorlage DeepSeek-R1-Distill-Qwen-32B aus, stellen Sie 4 GPUs ein und klicken Sie auf „Bereitstellen“.
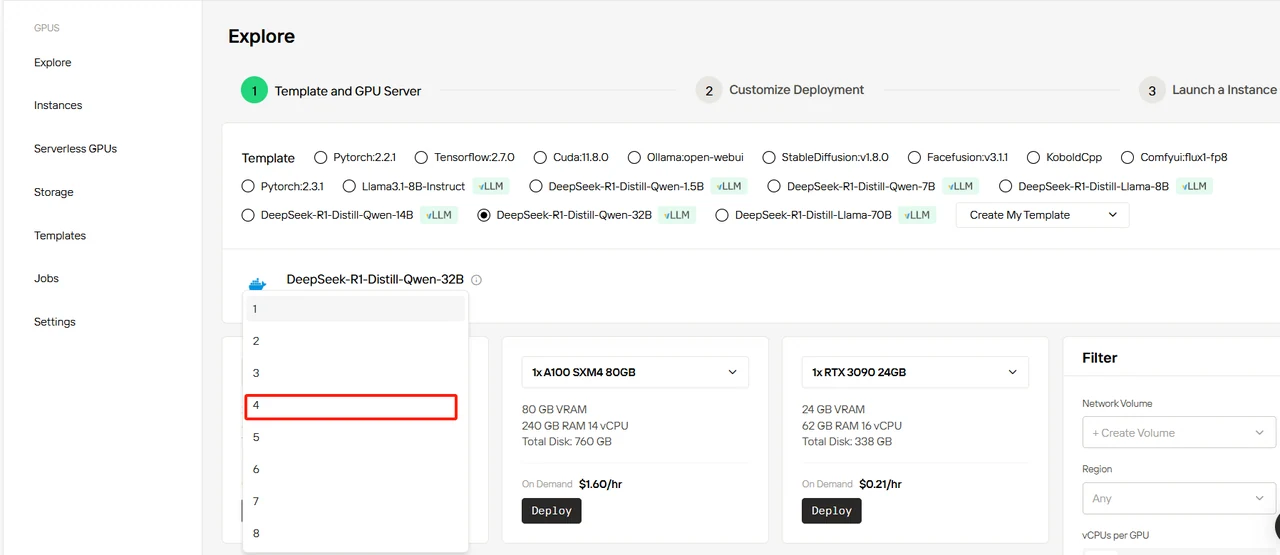
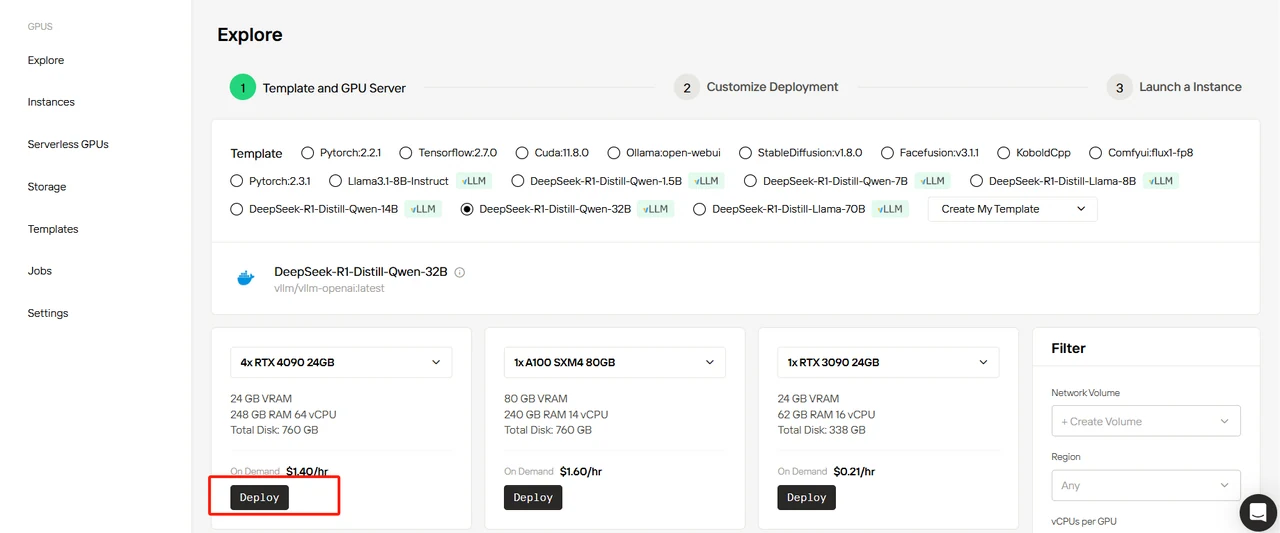
Schritt 4: Bereitstellung anpassen
Bestätigen Sie die Parameter der Vorlage und stellen Sie sicher, dass Sie die Variable HF_TOKEN ausfüllen.
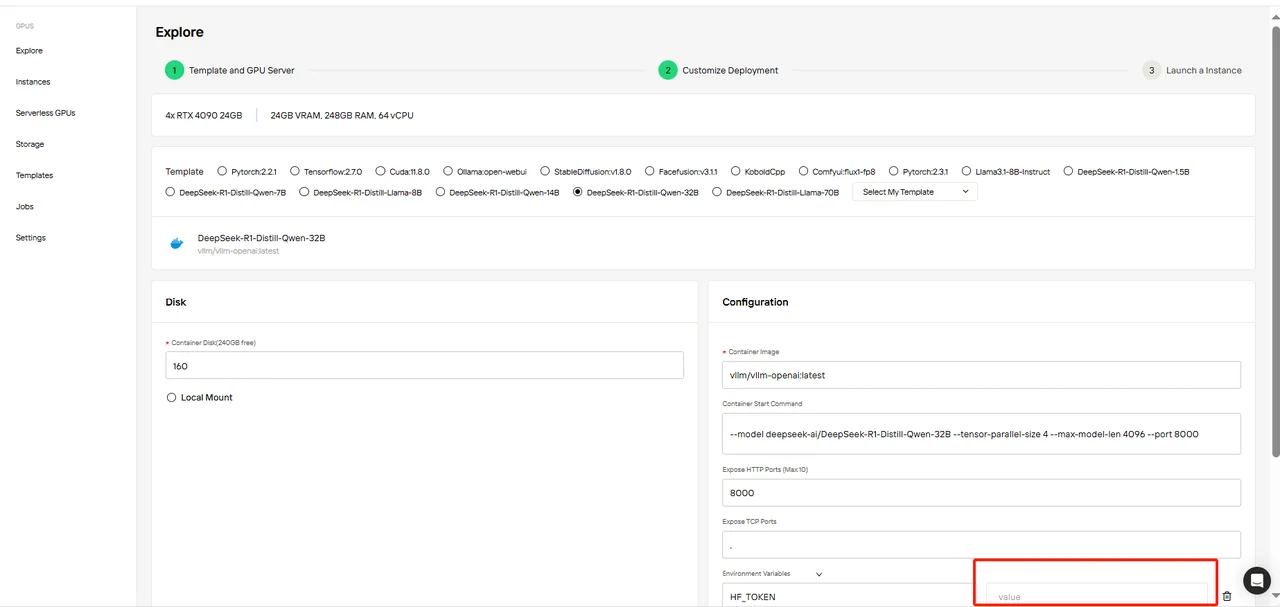
Sie können HF_TOKEN mit den folgenden Tipps erhalten:
-
Besuchen Sie huggingface.co:https://huggingface.co/
-
Klicken Sie oben rechts auf „Log In“ (Anmelden), um sich anzumelden, oder auf „Sign Up“ (Registrieren), um ein neues Konto zu erstellen
-
Klicken Sie nach der Anmeldung oben rechts auf Ihr Profilbild und wählen Sie im linken Menü „Access Tokens“ (Zugriffstoken) aus
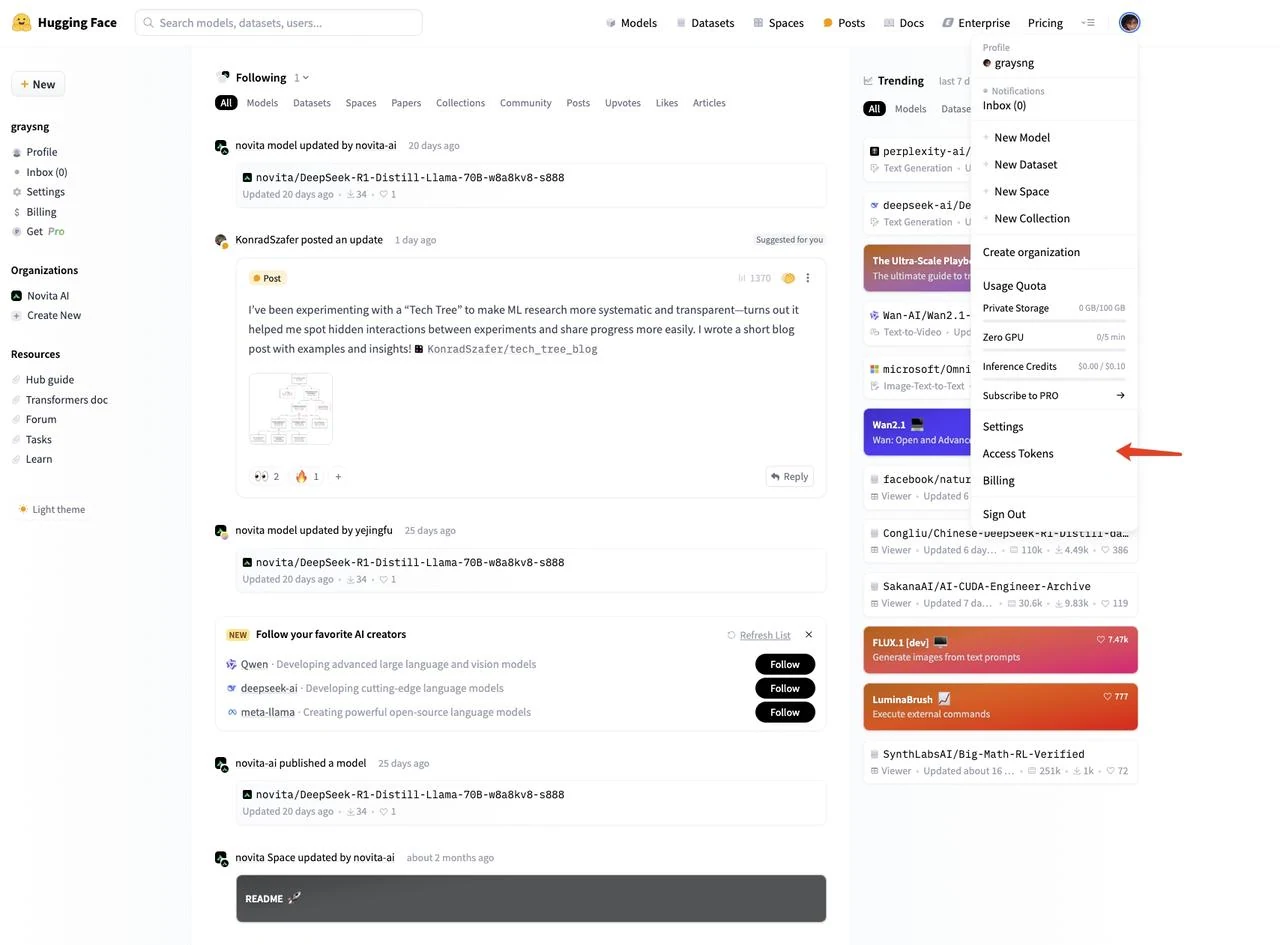
- Klicken Sie auf „New token“ (Neues Token), um ein neues Zugriffstoken zu erstellen
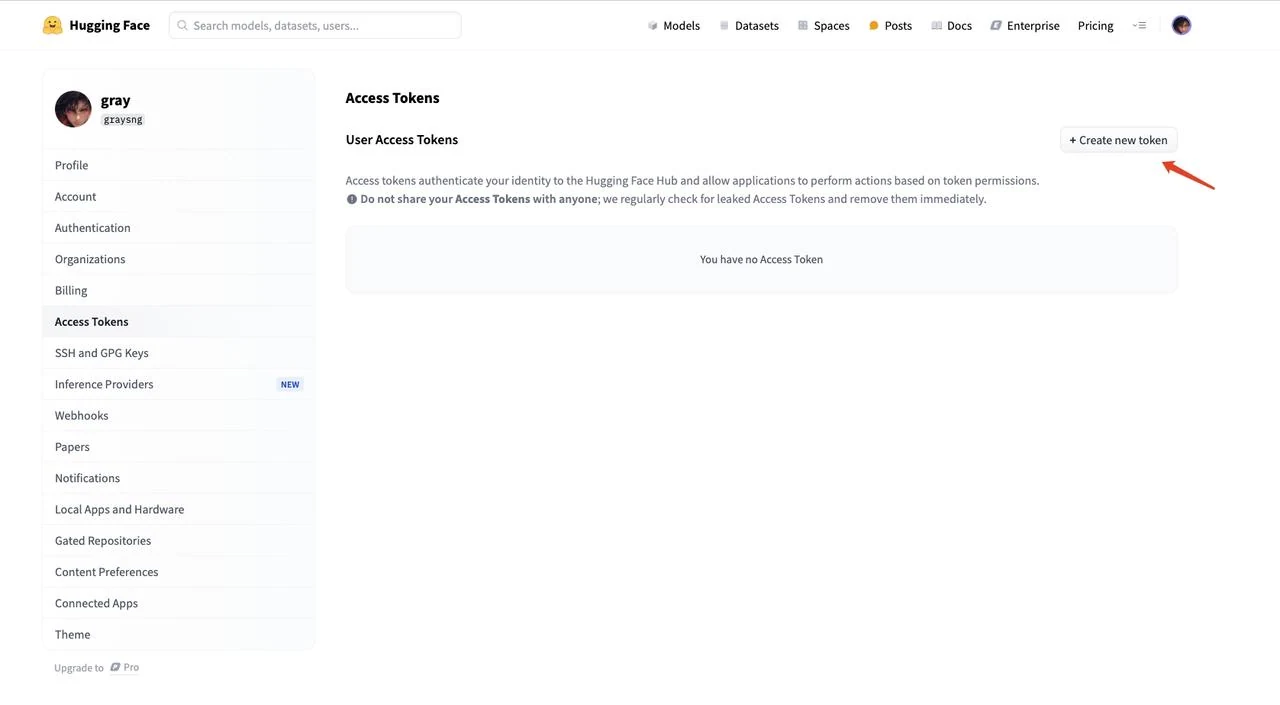
- Wählen Sie bei den Tokentypen „Read“ (Lesen) aus, geben Sie Ihrem Token einen Namen (z. B. „text“) und klicken Sie auf „Create token“ (Token erstellen), um das Token zu generieren.
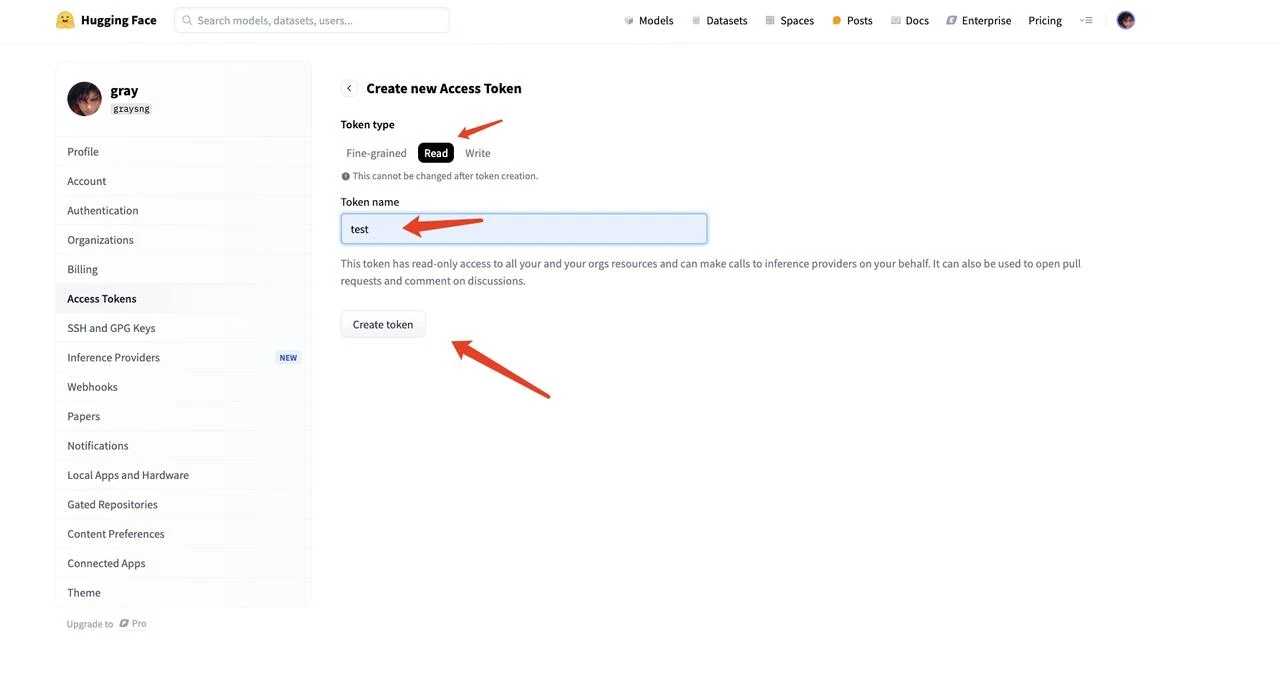
- Kopieren Sie die generierte Token-Zeichenfolge
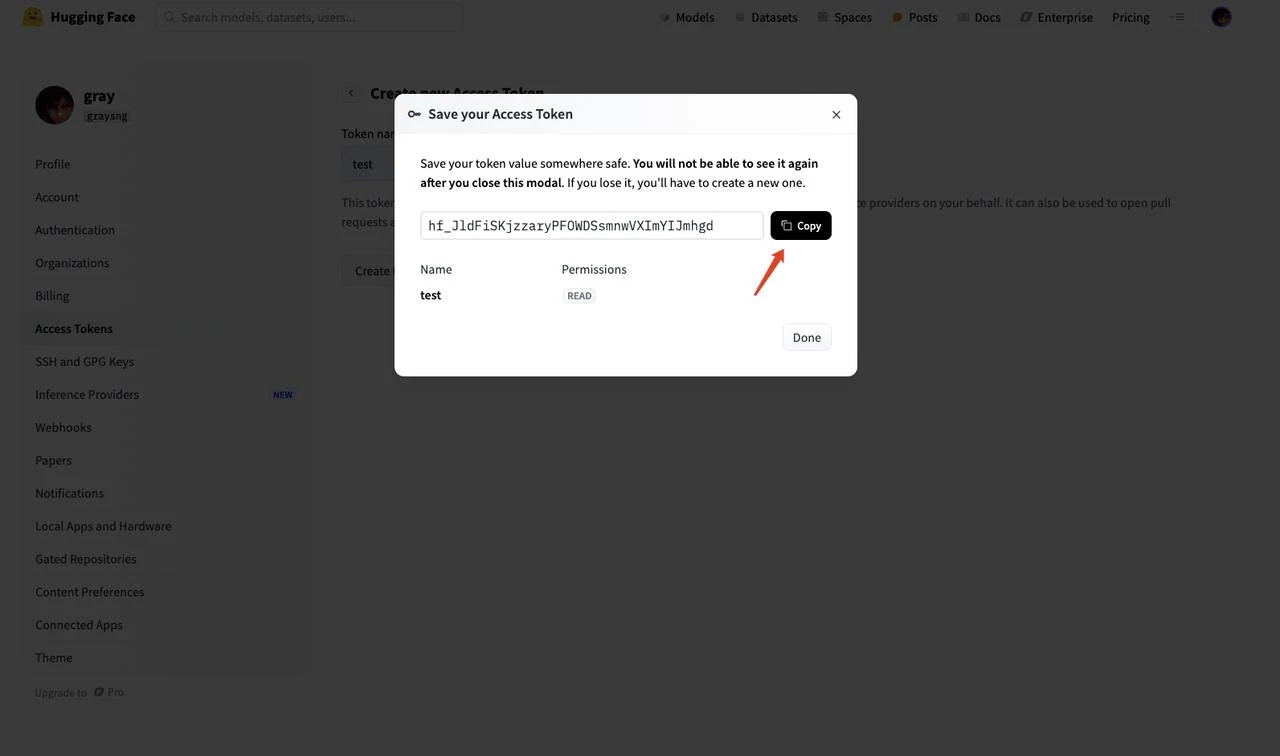
Geben Sie das erhaltene Token in die Umgebungsvariable HF_TOKEN in der Vorlage ein. Klicken Sie dann auf „Weiter“.
Schritt 5: Eine Instanz starten
Klicken Sie auf „Instanz starten“, um Ihre konfigurierte Umgebung bereitzustellen.
Warten Sie einige Minuten, während die Instanz konfiguriert und verwaltet wird.
Klicken Sie auf das Dropdown-Menü, um die Instanzprotokolle anzuzeigen.

Nachdem die Instanz gestartet ist, beginnt sie mit dem Herunterladen des Modells. Klicken Sie auf „Protokolle“ → „Instanzprotokolle“, um den Fortschritt des Modell-Downloads zu überwachen.
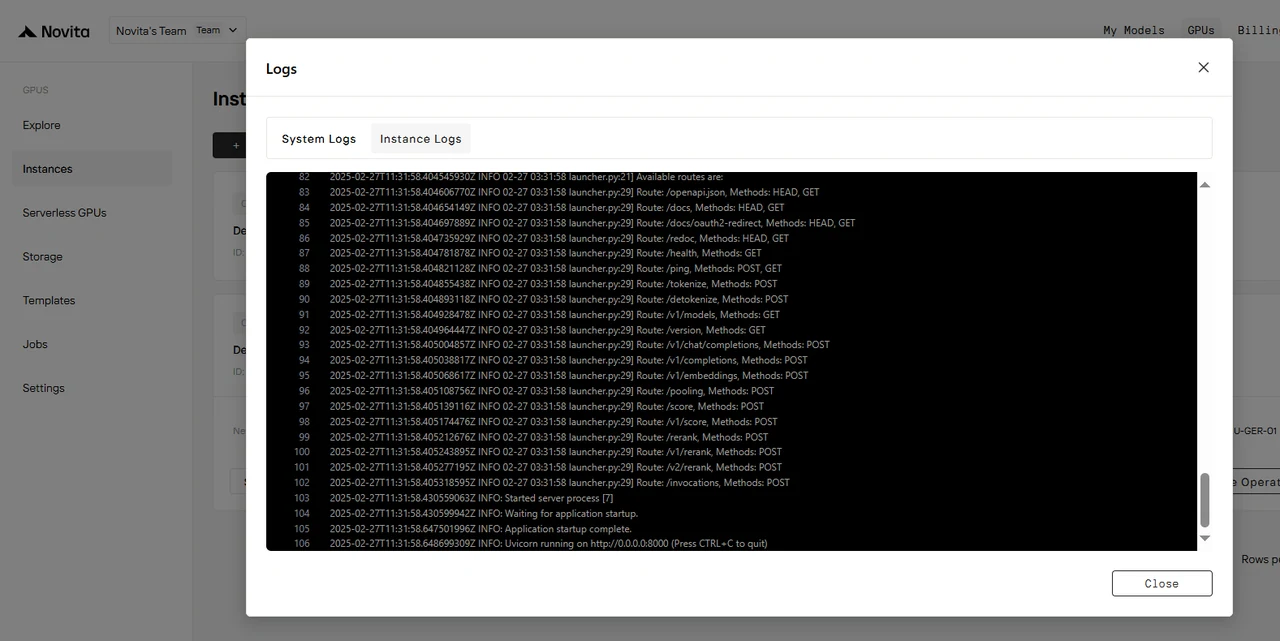
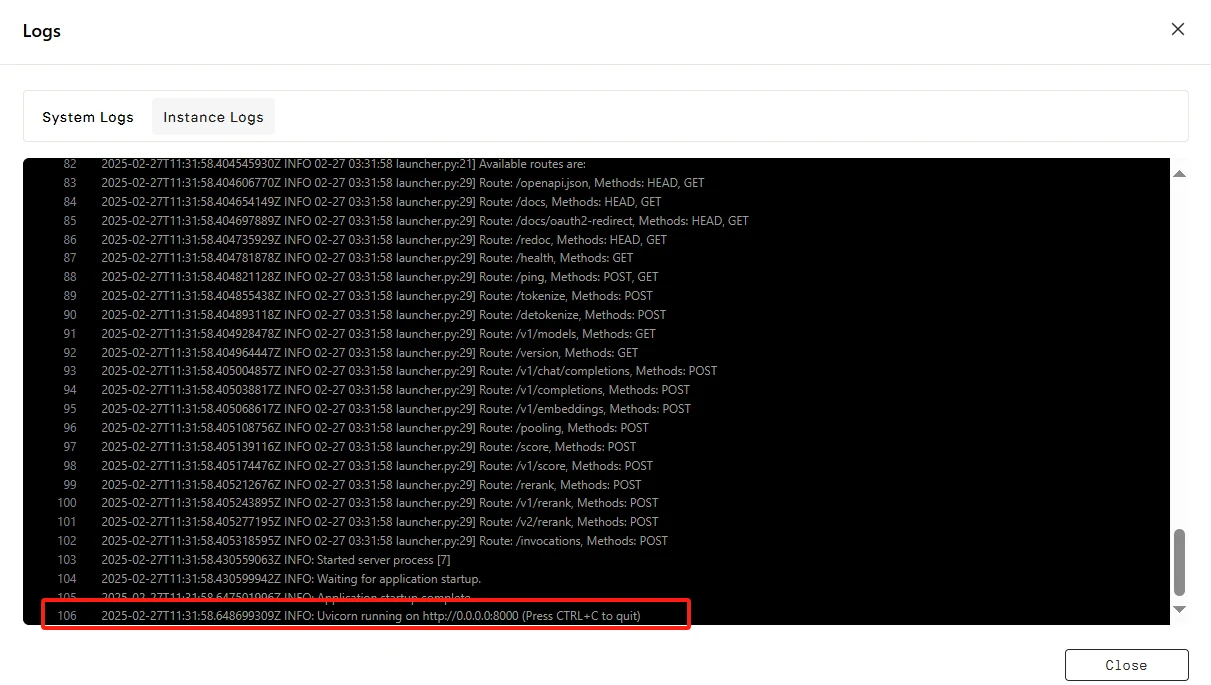
Wenn das Protokoll „INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)“ anzeigt, war der Start erfolgreich. Greifen wir nun auf Ihr privates Modell zu!
Klicken Sie auf „Verbinden“, dann auf → „Mit HTTP-Dienst verbinden [Port 8000]“. Da es sich um einen API-Dienst handelt, müssen Sie die Adresse kopieren.

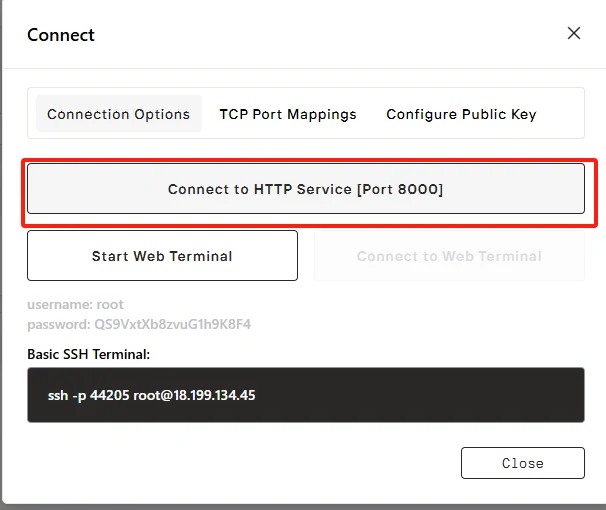

Um Anfragen an Ihr privates Modell zu stellen, ersetzen Sie bitte***„https://f6d29cb6f71e585e-8000.us-ca-1.gpu-instance.novita.ai“*** durch Ihre tatsächliche freigegebene Adresse. Kopieren Sie den folgenden Code, um auf Ihr privates Modell zuzugreifen!
$ curl https://f6d29cb6f71e585e-8000.us-ca-1.gpu-instance.novita.ai/v1/chat/completions \
-H "Content-Type: application/json" -d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"messages": [{"role": "user", "content": "hello"}]
}'
{"id":"chatcmpl-57b3296f87f54dd4b69cfb6d2196f48e","object":"chat.completion","created":1740711405,"model":"deepseek-ai/DeepSeek-R1-Distill-Qwen-32B","choices":[{"index":0,"message":{"role":"assistant","content":"Alright, the user said \"hello.\" That's a friendly greeting. I should respond in a welcoming manner.\
\
Maybe I can acknowledge their greeting and offer assistance.\
\
It's important to sound approachable and ready to help.\
\
I'll keep it simple and polite.\
response\
\
Hello! How can I assist you today?","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":6,"total_tokens":70,"completion_tokens":64,"prompt_tokens_details":null},"prompt_logprobs":null}

Konfigurieren Sie die API-Adresse in Ihren Anwendungen wie Chatbox und Sie haben Ihren eigenen persönlichen Assistenten!
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Deploying DeepSeek Models on Novita AI Cloud Platform: A Comprehensive Guide) ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig einen erschwinglichen und zuverlässigen GPU-Cloud-Service für die Entwicklung bereitstellt.



