

DeepSeekモデルは、LLM分野で魅力的な選択肢として浮上しており、競争力のあるコストで印象的なパフォーマンスを提供しています。これらのモデルは強力な能力を備えていますが、成功裏に展開するには堅牢で効率的なインフラストラクチャソリューションが必要です。このガイドでは、Novita AIのクラウドプラットフォームを活用して、ハイパフォーマンスとコスト効率を両立させた最適なDeepSeekモデル展開を実現する方法を紹介します。
モデルバリエーションの概要
蒸留版
- オープンソースモデル(Qwen2.5とLlamaシリーズ)に基づく
- パラメータ範囲:1.5B、7B、8B、14B、32B、70B
- 高いパフォーマンスを維持しながら効率的な推論に最適化
- コスト効果の高いプライベート展開に最適
- Novita AIのワンクリックソリューションで簡単に展開可能
フルスケール版
- DeepSeek-R1-671B
- DeepSeek-V3アーキテクチャをベースに構築
- 最大パフォーマンスのために671Bパラメータを搭載
- かなりの計算リソースが必要
- 最適化されたAPIサービスを通じて利用可能
展開ガイド
ステップ1:Novita AIプラットフォームへのアクセス
- Novita AIの公式ウェブサイトにアクセス:https://novita.ai/
[今すぐNovita AIを試す](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Deploying DeepSeek Models on Novita AI Cloud Platform: A Comprehensive Guide)
- アカウントを作成するか、既存のアカウントにサインイン

ステップ2:GPUインスタンス設定へのアクセス
- メインナビゲーションで「GPUs」をクリック
2.「Get Started」をクリックして進む
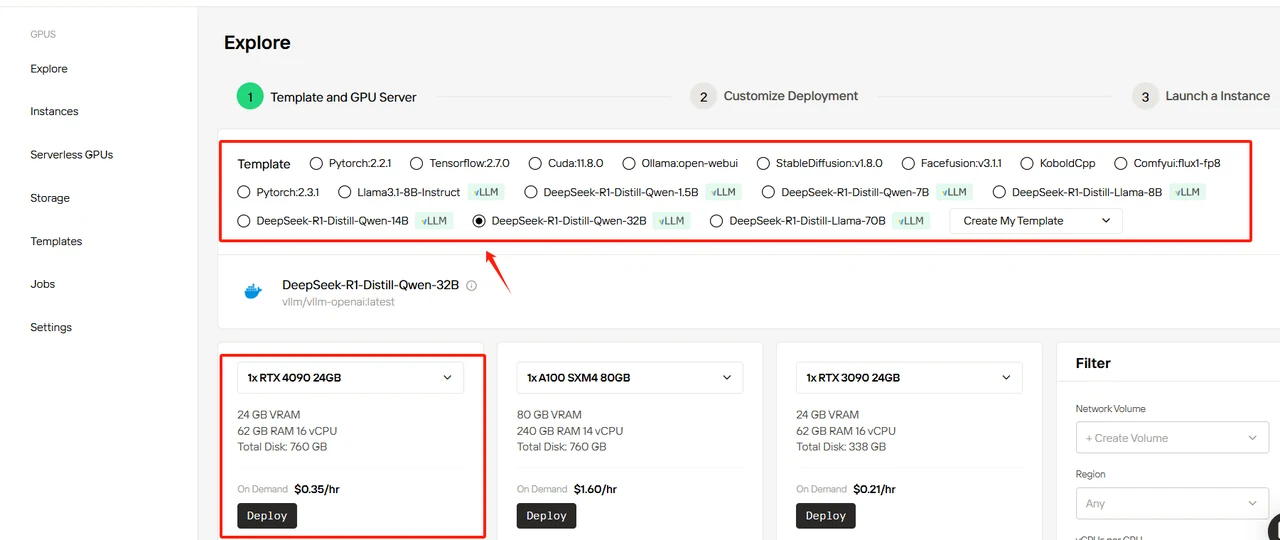
ステップ3:DeepSeekモデルの選択と設定
このガイドでは、例としてDeepSeek-R1-Distill-Llama-32Bを使用します。ニーズに応じて任意のテンプレートを選択できますが、このテンプレートがモデルの基本パラメータを定義します。必要なGPU数を設定する必要があります。この展開ではRTX 4090の使用をお勧めします。すべてのテンプレートは公式のDeepSeekモデルを使用し、デフォルトのBF16精度を採用しています。以下に推奨設定を示します。
| モデル | 精度 | GPU | 数量 |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Qwen-7B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Llama-8B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Qwen-14B | BF16 | RTX 4090 | 2 |
| DeepSeek-R1-Distill-Qwen-32B | BF16 | RTX 4090 | 4 |
| DeepSeek-R1-Distill-Llama-70B | BF16 | RTX 4090 | 8 |
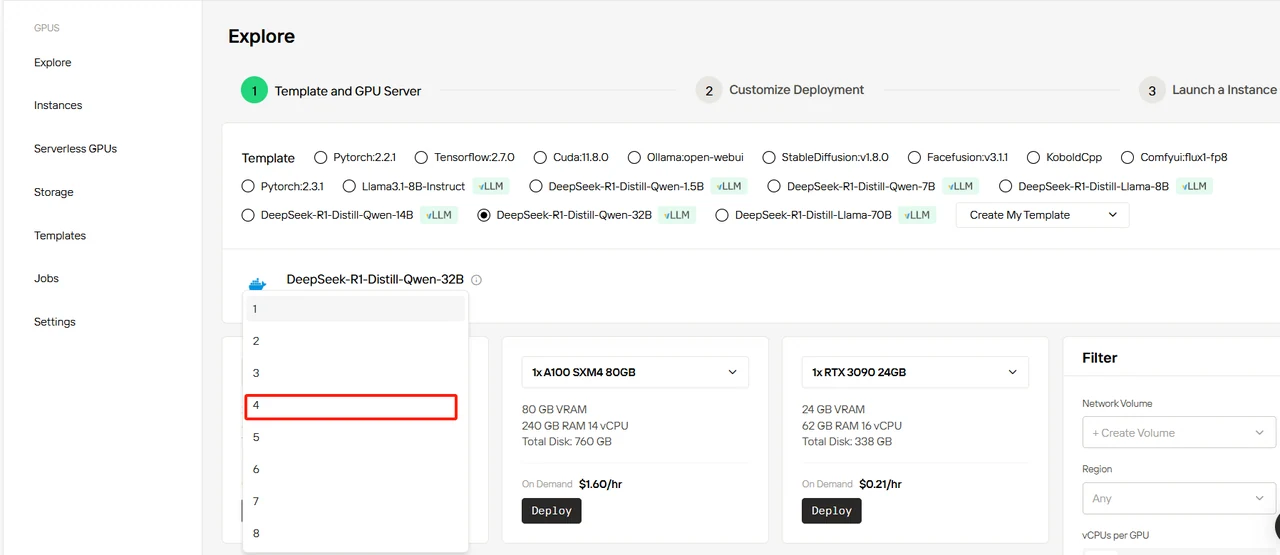
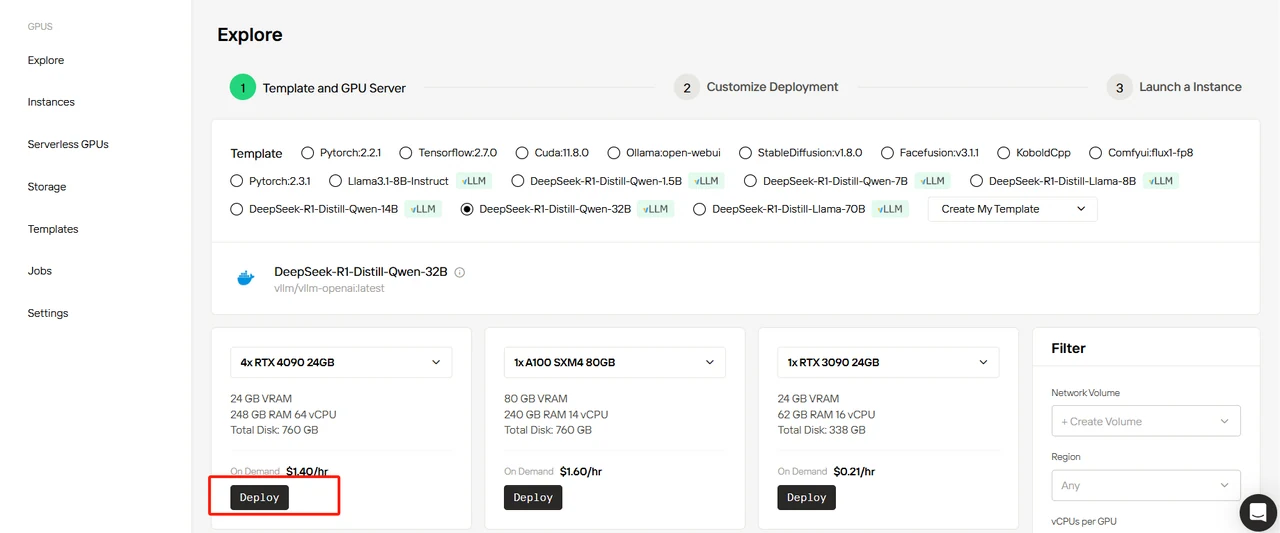
DeepSeek-R1-Distill-Qwen-32Bテンプレートを選択し、GPUを4に設定して「Deploy」をクリックします。
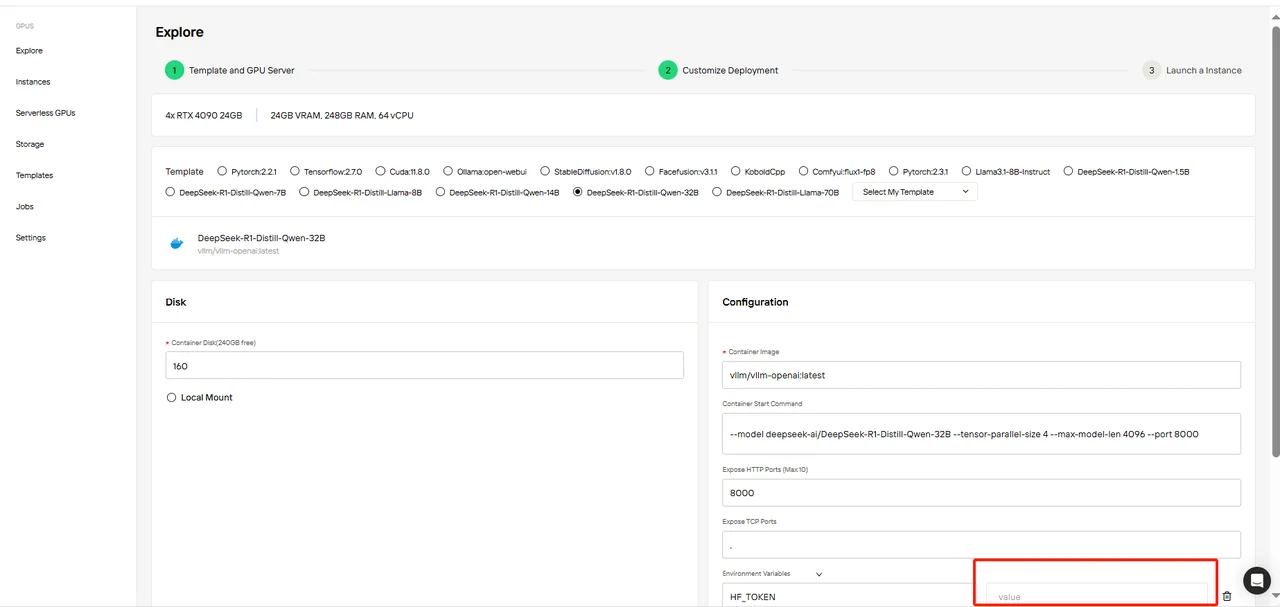
ステップ4:展開のカスタマイズ
テンプレートパラメータを確認し、HF_TOKEN 変数を必ず入力してください。
HF_TOKENの取得方法は以下の手順に従ってください。
-
huggingface.coにアクセス:https://huggingface.co/
-
右上の「Log In」をクリックしてサインイン、または「Sign Up」で新規アカウントを作成
-
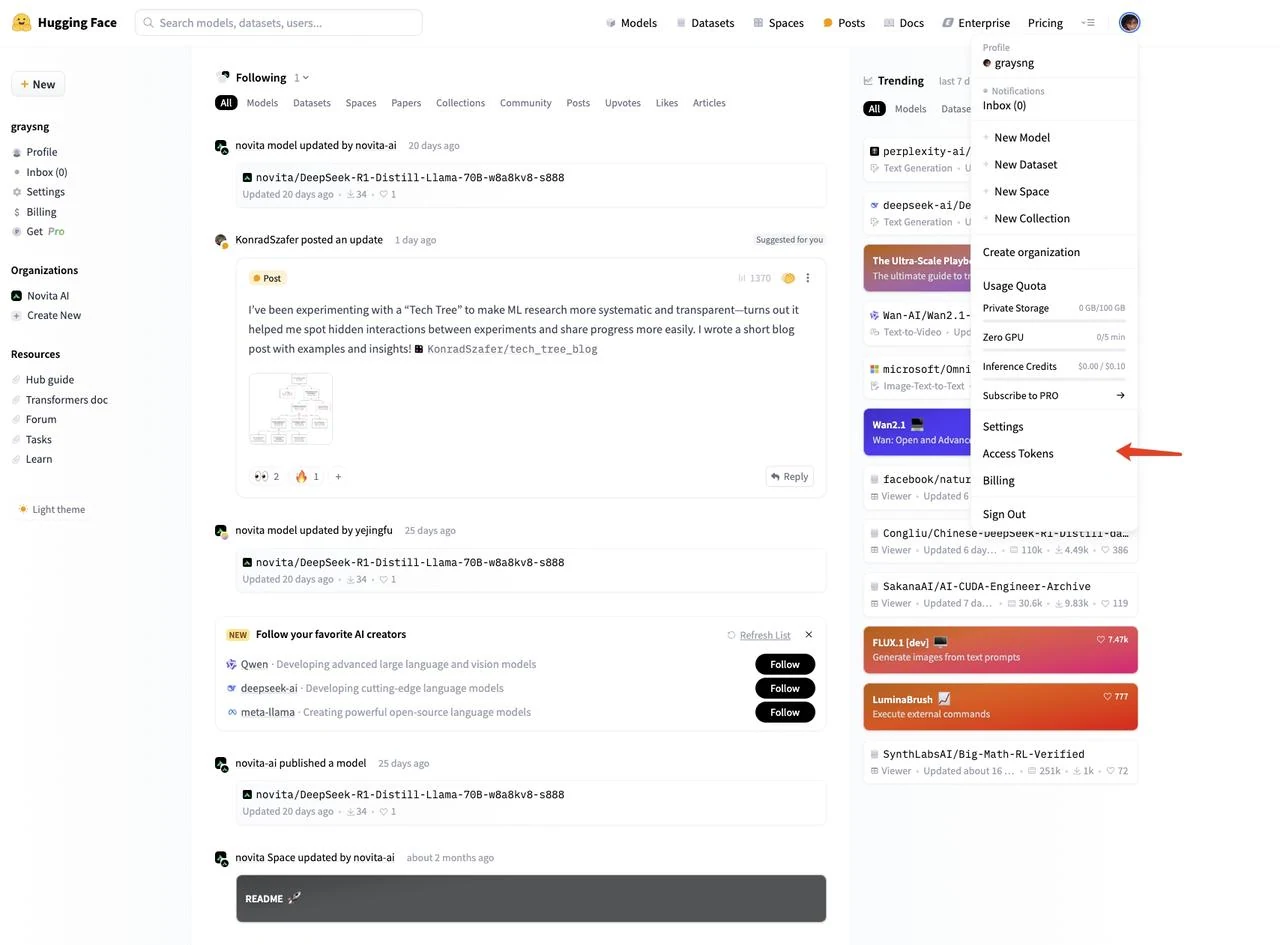
ログイン後、右上のプロフィール画像をクリックし、左メニューから「Access Tokens」を選択
4.「New token」をクリックして新しいアクセストークンを作成
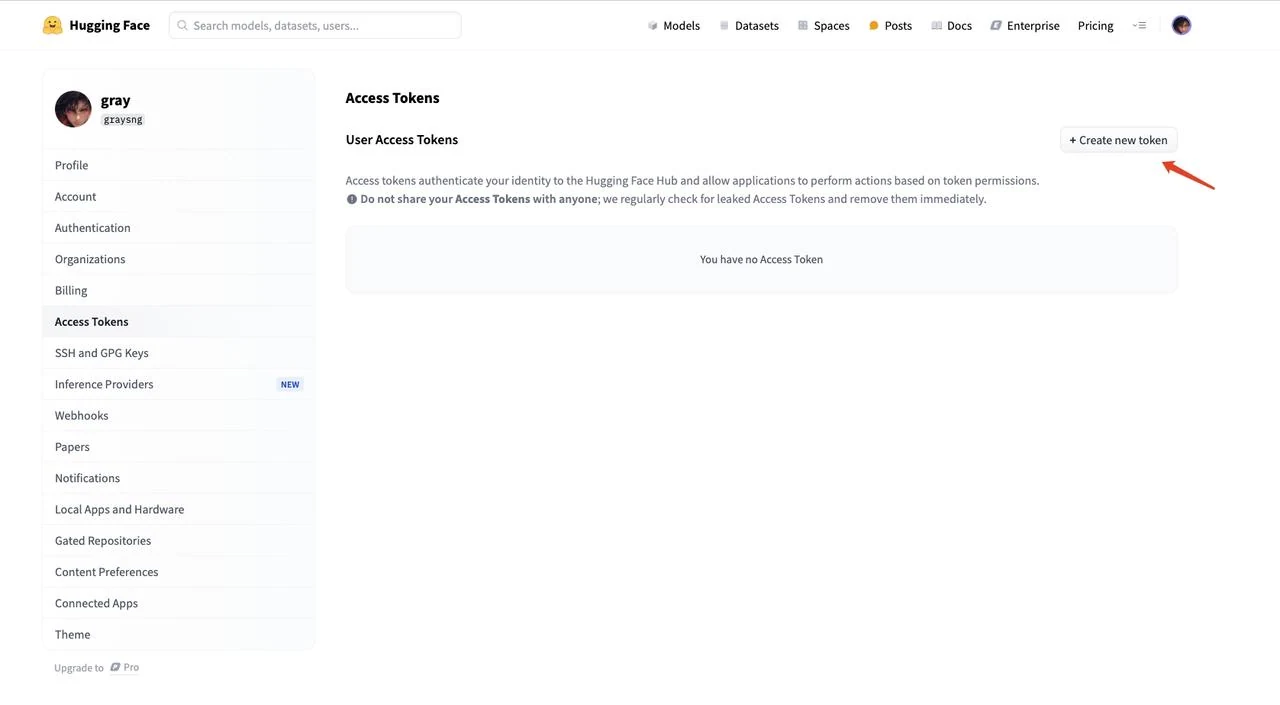
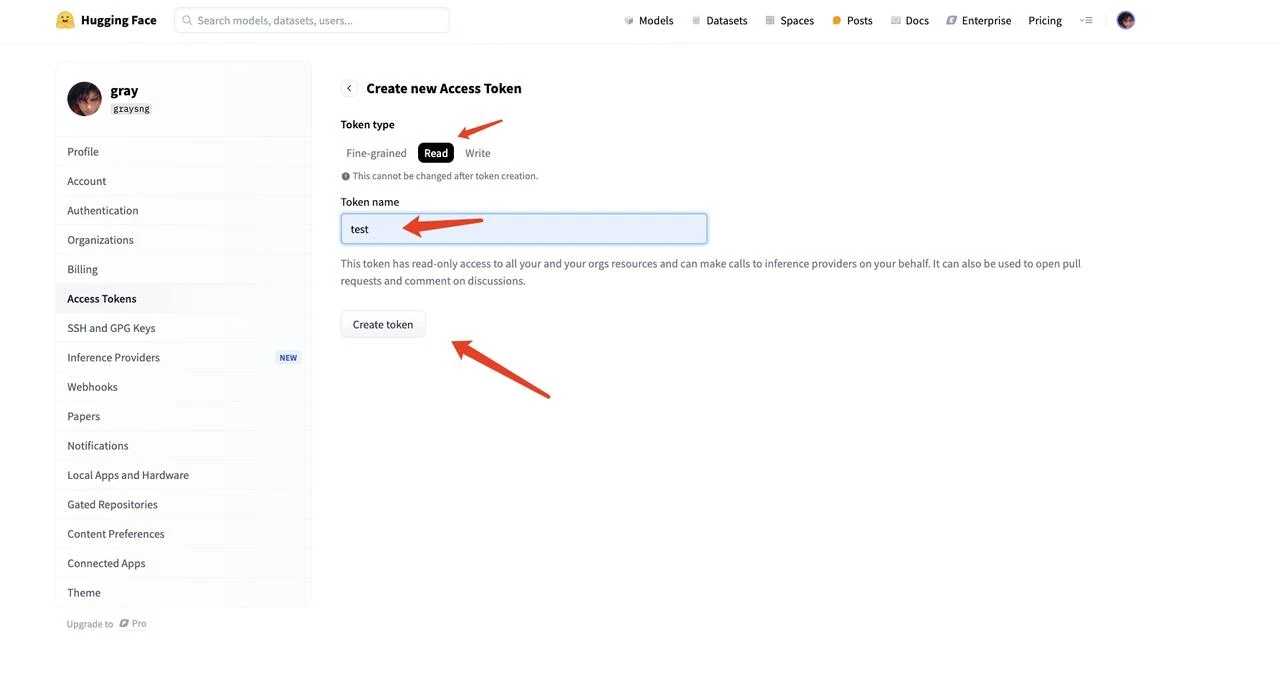
5.トークンの種類で「Read」を選択し、トークンに名前を付け(例:「text」)、「Create token」をクリックしてトークンを生成
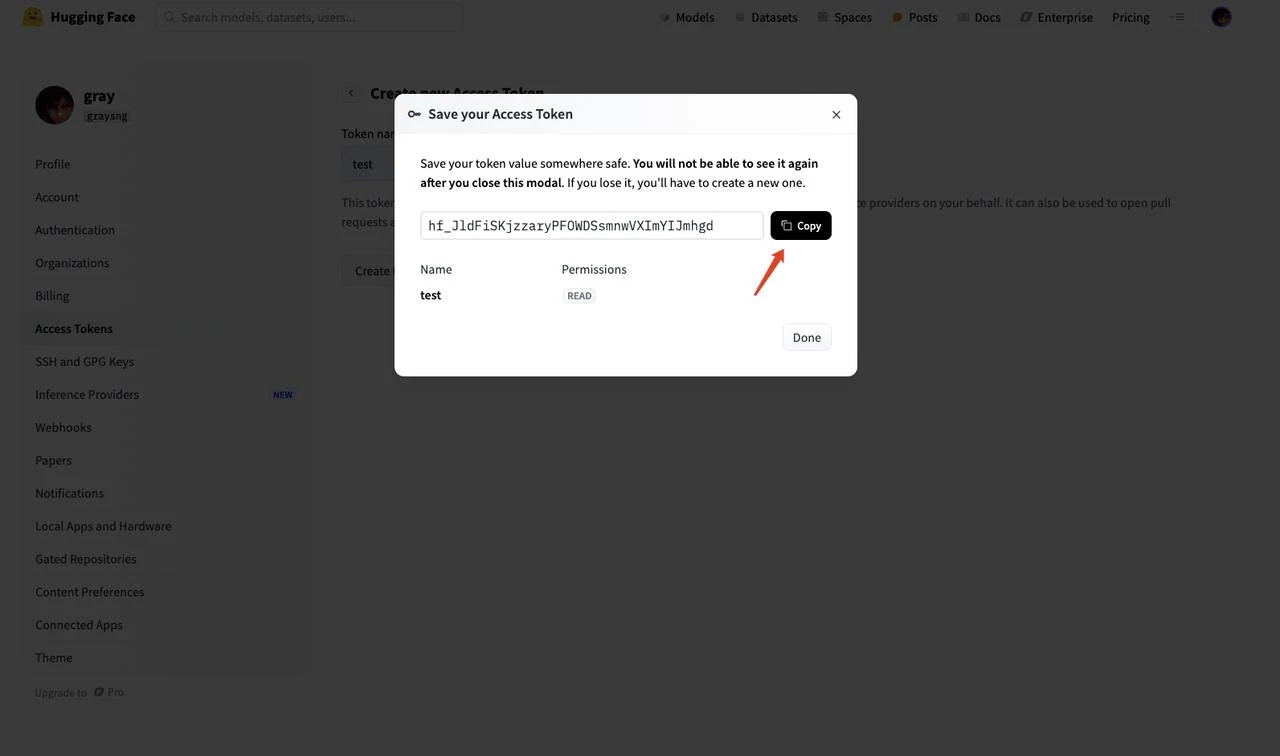
6.生成されたトークン文字列をコピー
トークンを取得したら、テンプレートのHF_TOKEN環境変数に入力します。その後、「Next」をクリックします。
ステップ5:インスタンスの起動
「Launch Instance」をクリックして、設定した環境を展開します。
インスタンスが設定および管理されるまで数分待ちます。
ドロップダウンメニューをクリックしてインスタンスログを表示します。

インスタンスが起動すると、モデルのプルが開始されます。「Logs」→「Instance Logs」をクリックして、モデルのダウンロード進捗を監視します。
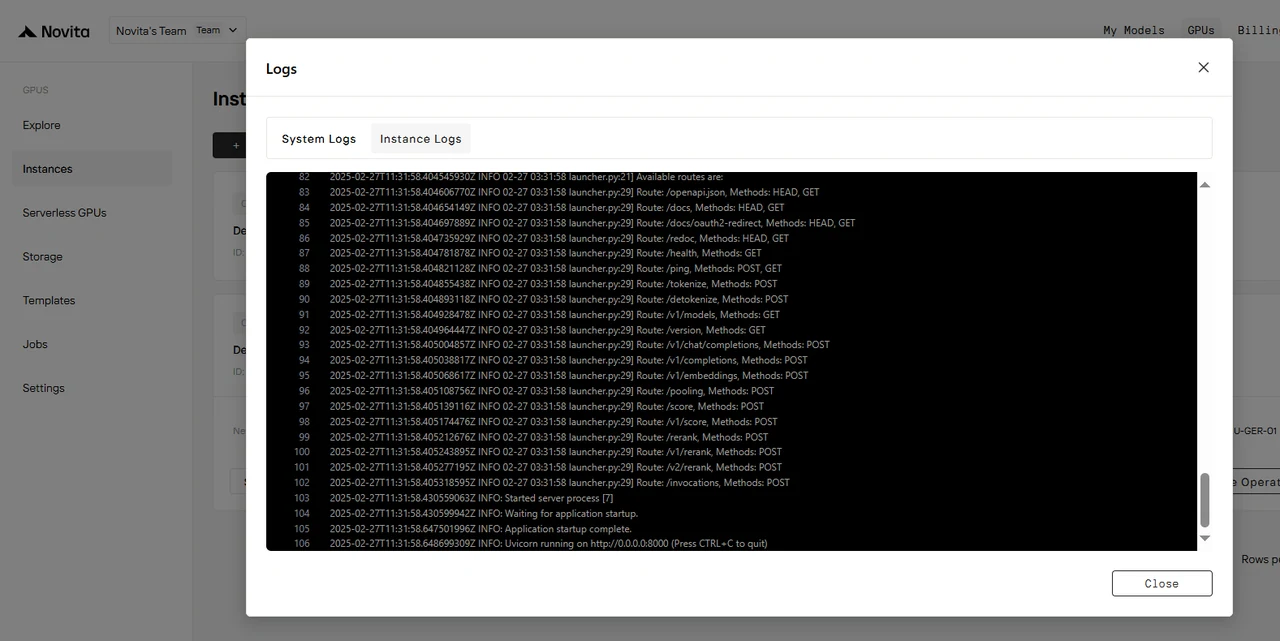
ログに「INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)」と表示されたら、起動成功です。これでプライベートモデルにアクセスできます!
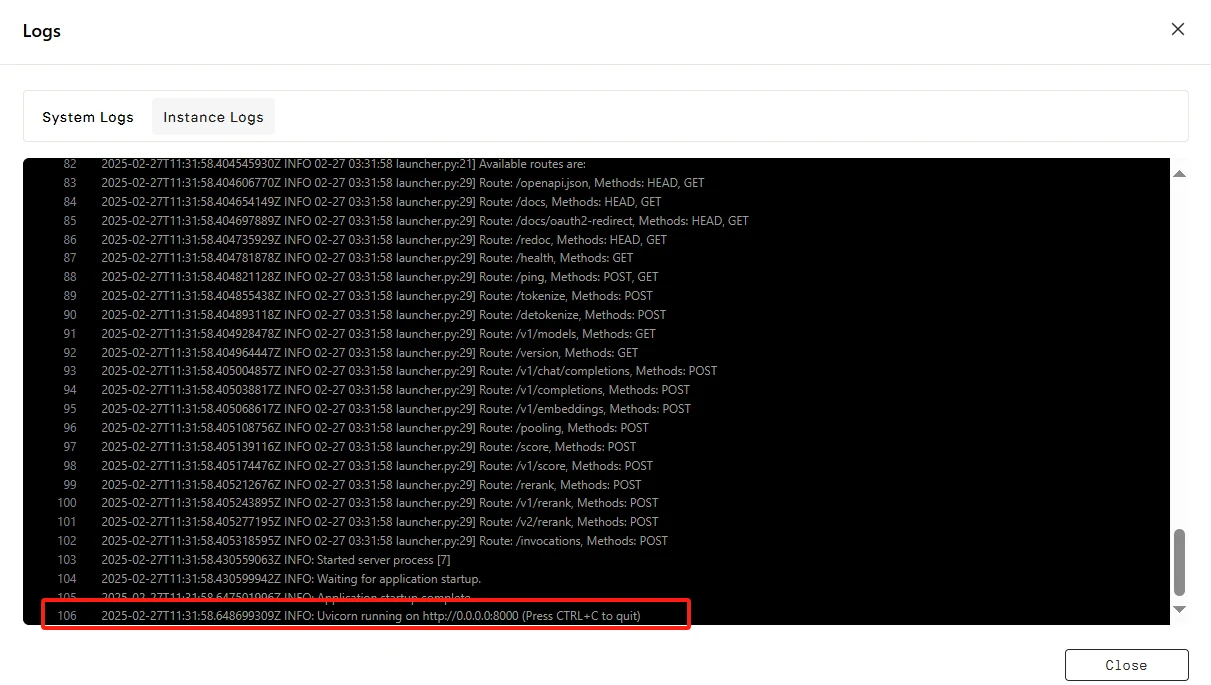
「Connect」をクリックし、次に「Connect to HTTP Service [Port 8000]」をクリックします。これはAPIサービスなので、アドレスをコピーする必要があります。


プライベートモデルにリクエストを送信するには、***“https://f6d29cb6f71e585e-8000.us-ca-1.gpu-instance.novita.ai”***を実際の公開アドレスに置き換えてください。以下のコードをコピーしてプライベートモデルにアクセスします!
$ curl https://f6d29cb6f71e585e-8000.us-ca-1.gpu-instance.novita.ai/v1/chat/completions \
-H "Content-Type: application/json" -d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"messages": [{"role": "user", "content": "hello"}]
}'
{"id":"chatcmpl-57b3296f87f54dd4b69cfb6d2196f48e","object":"chat.completion","created":1740711405,"model":"deepseek-ai/DeepSeek-R1-Distill-Qwen-32B","choices":[{"index":0,"message":{"role":"assistant","content":"Alright, the user said \"hello.\" That's a friendly greeting. I should respond in a welcoming manner.\
\
Maybe I can acknowledge their greeting and offer assistance.\
\
It's important to sound approachable and ready to help.\
\
I'll keep it simple and polite.\
response\
\
Hello! How can I assist you today?","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":6,"total_tokens":70,"completion_tokens":64,"prompt_tokens_details":null},"prompt_logprobs":null}

ChatboxなどのアプリケーションでAPIアドレスを設定すれば、自分だけのパーソナルアシスタントの完成です!
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Deploying DeepSeek Models on Novita AI Cloud Platform: A Comprehensive Guide)は、シンプルなAPIを使ってAIモデルを簡単に展開できるAIクラウドプラットフォームであり、手頃で信頼性の高いGPUクラウドを提供しています。



