

Les modèles DeepSeek sont devenus un choix incontournable dans l’univers des LLM, offrant des performances impressionnantes à des coûts compétitifs. Bien que ces modèles présentent des capacités puissantes, un déploiement réussi nécessite une infrastructure robuste et efficace. Ce guide vous montre comment tirer parti de la plateforme cloud Novita AI pour un déploiement optimal des modèles DeepSeek, alliant hautes performances et rentabilité.
Présentation des variantes de modèles
Versions distillées
- Basées sur des modèles open source (séries Qwen2.5 et Llama)
- Plages de paramètres : 1,5B, 7B, 8B, 14B, 32B et 70B
- Optimisées pour une inférence efficace tout en conservant des performances élevées
- Idéales pour des déploiements privés économiques
- Facilement déployables via la solution en un clic de Novita AI
Version complète
- DeepSeek-R1-671B
- Construite sur l’architecture DeepSeek-V3
- Dispose de 671 milliards de paramètres pour des performances maximales
- Nécessite d’importantes ressources de calcul
- Disponible via notre service API optimisé
Guide de déploiement
Étape 1 : Accès à la plateforme Novita AI
- Visitez le site officiel de Novita AI : https://novita.ai/
[Essayez Novita AI maintenant](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Deploying DeepSeek Models on Novita AI Cloud Platform: A Comprehensive Guide)
- Créez un compte ou connectez-vous à votre compte existant

Étape 2 : Accès à la configuration des instances GPU
- Cliquez sur « GPUs » dans la navigation principale
- Cliquez sur « Get Started » pour continuer
Étape 3 : Sélectionner et configurer le modèle DeepSeek
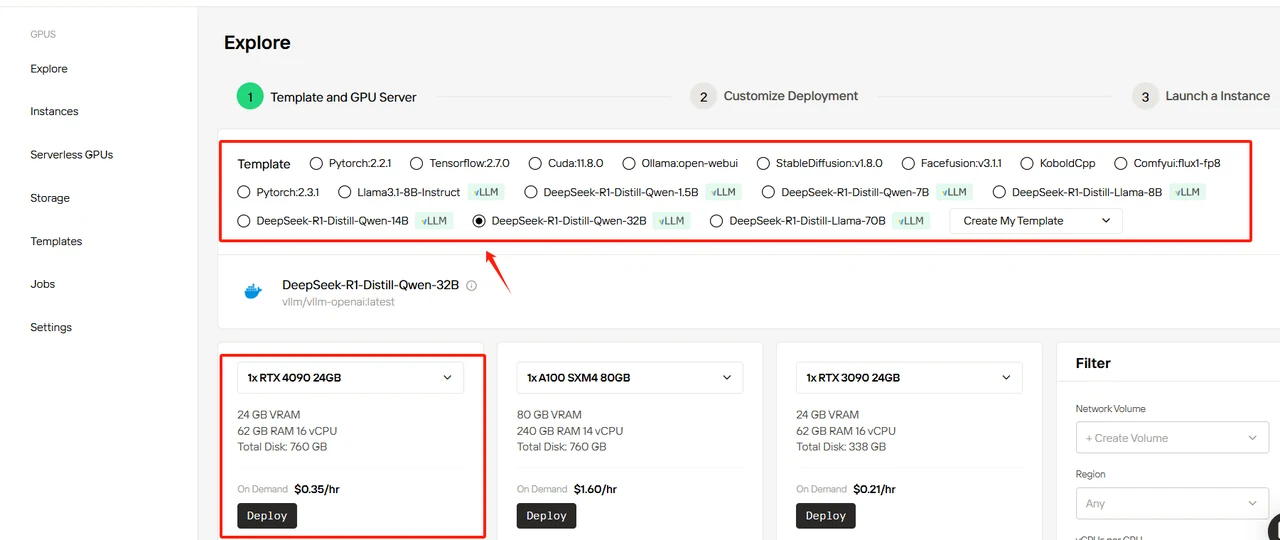
Dans ce guide, nous utiliserons DeepSeek-R1-Distill-Llama-32B comme exemple. Vous pouvez choisir n’importe quel modèle selon vos besoins, mais ce modèle définit les paramètres de base. Vous devrez configurer le nombre de GPU requis – nous recommandons d’utiliser RTX 4090 pour ce déploiement. Tous les modèles utilisent les modèles officiels DeepSeek avec une précision BF16 par défaut. Voici nos configurations recommandées :
| Modèle | GPU | GPU | Quantité |
| DeepSeek-R1-Distill-Qwen-1.5B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Qwen-7B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Llama-8B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Qwen-14B | BF16 | RTX 4090 | 2 |
| DeepSeek-R1-Distill-Qwen-32B | BF16 | RTX 4090 | 4 |
| DeepSeek-R1-Distill-Llama-70B | BF16 | RTX 4090 | 8 |
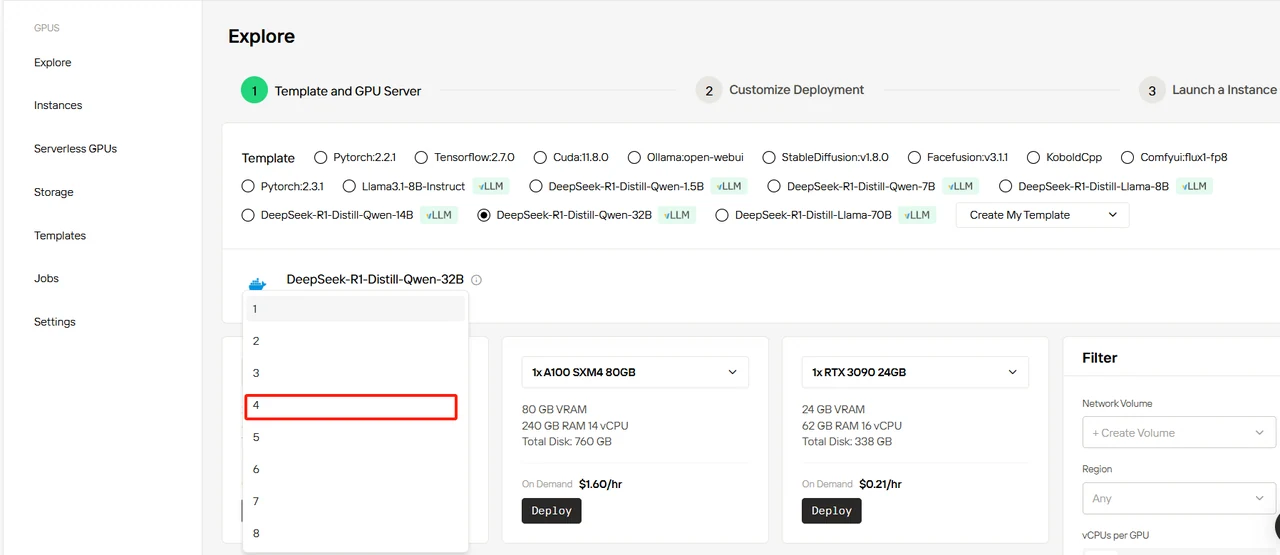
Sélectionnez le modèle DeepSeek-R1-Distill-Qwen-32B, définissez 4 GPU et cliquez sur « Deploy ».
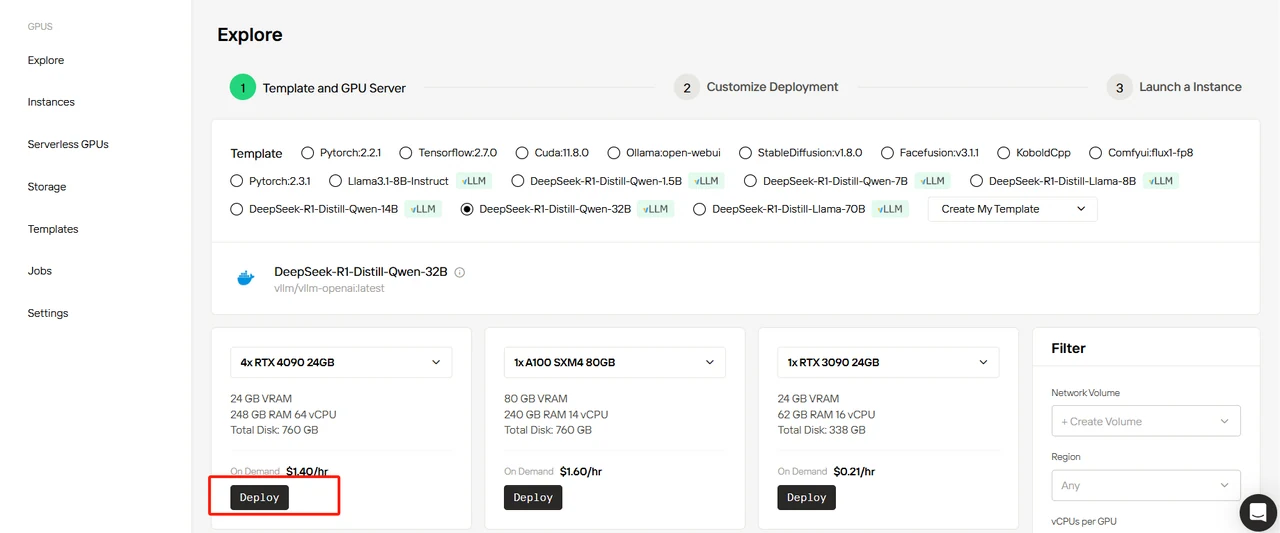
Étape 4 : Personnaliser le déploiement
Confirmez les paramètres du modèle et assurez-vous de remplir la variable HF_TOKEN.
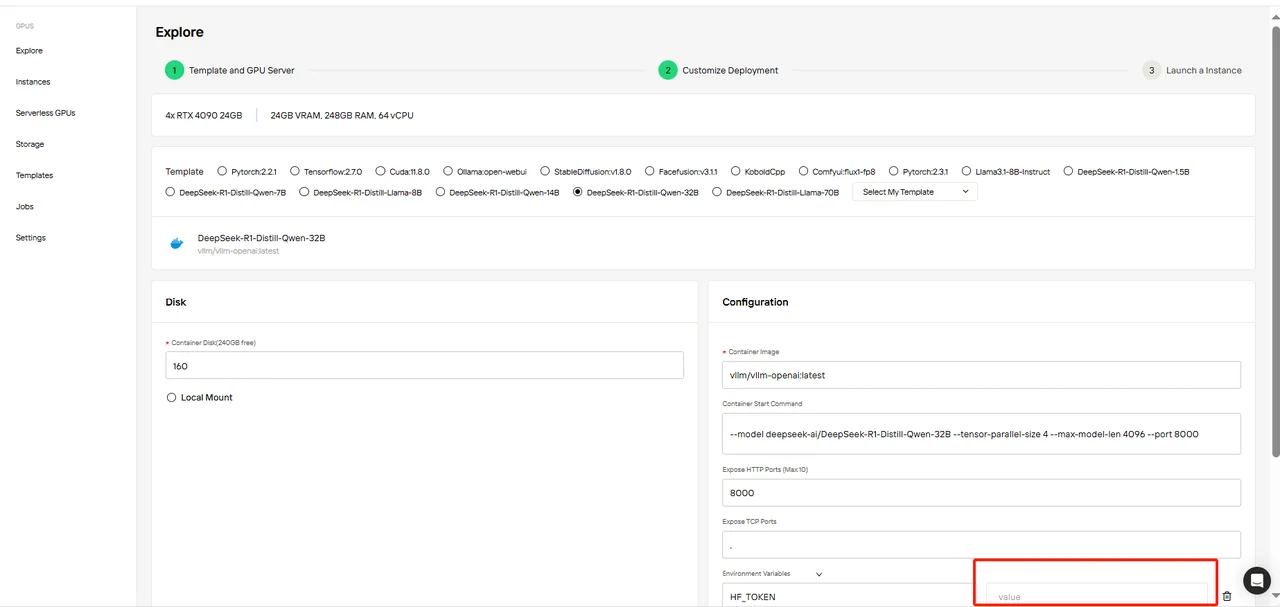
Vous pouvez obtenir le HF_TOKEN en suivant ces conseils :
-
Rendez-vous sur huggingface.co : https://huggingface.co/
-
Cliquez sur « Log In » en haut à droite pour vous connecter, ou sur « Sign Up » pour créer un nouveau compte
-
Après connexion, cliquez sur votre photo de profil en haut à droite et sélectionnez « Access Tokens » dans le menu de gauche
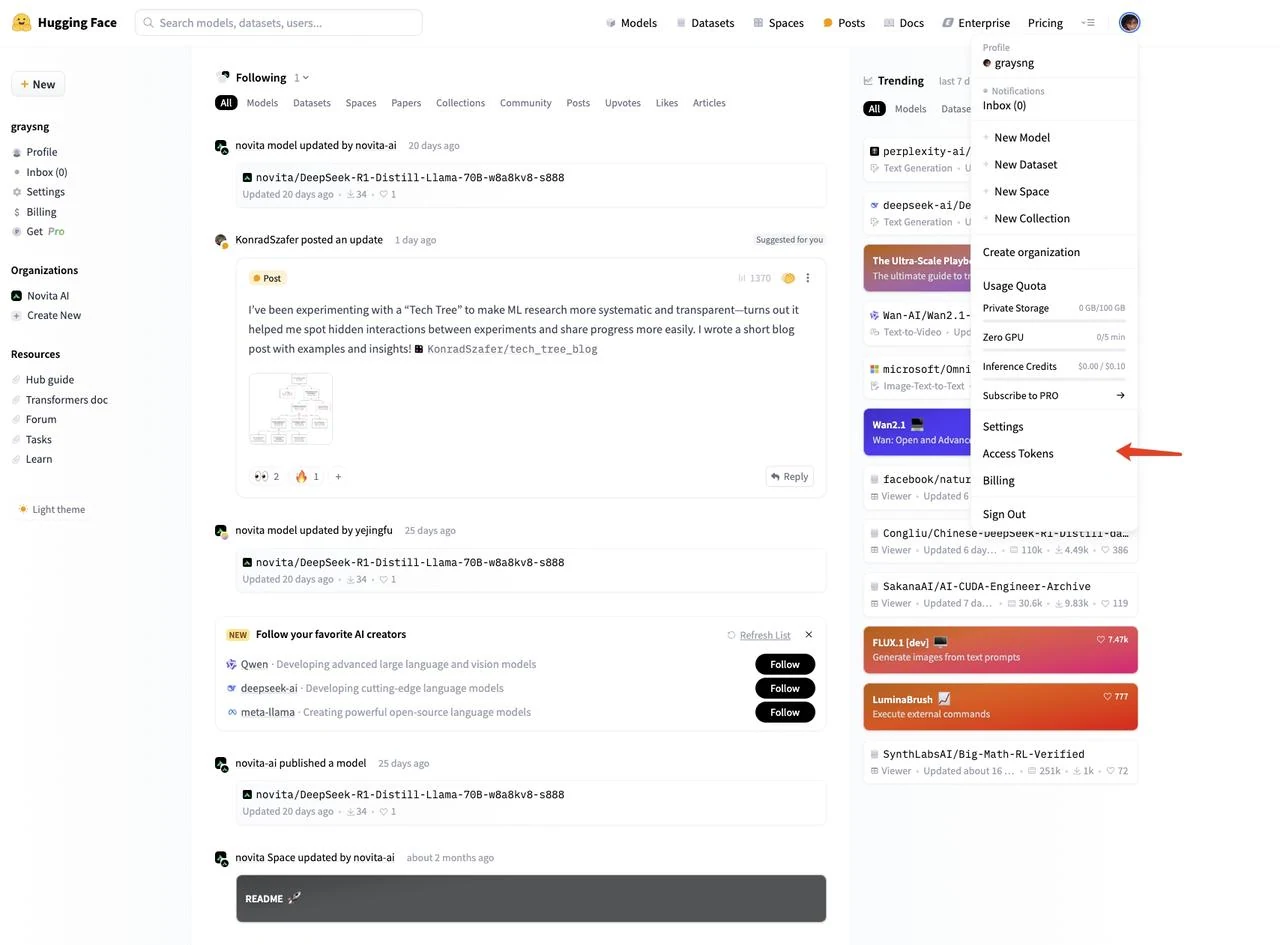
- Cliquez sur « New token » pour créer un nouveau token d’accès
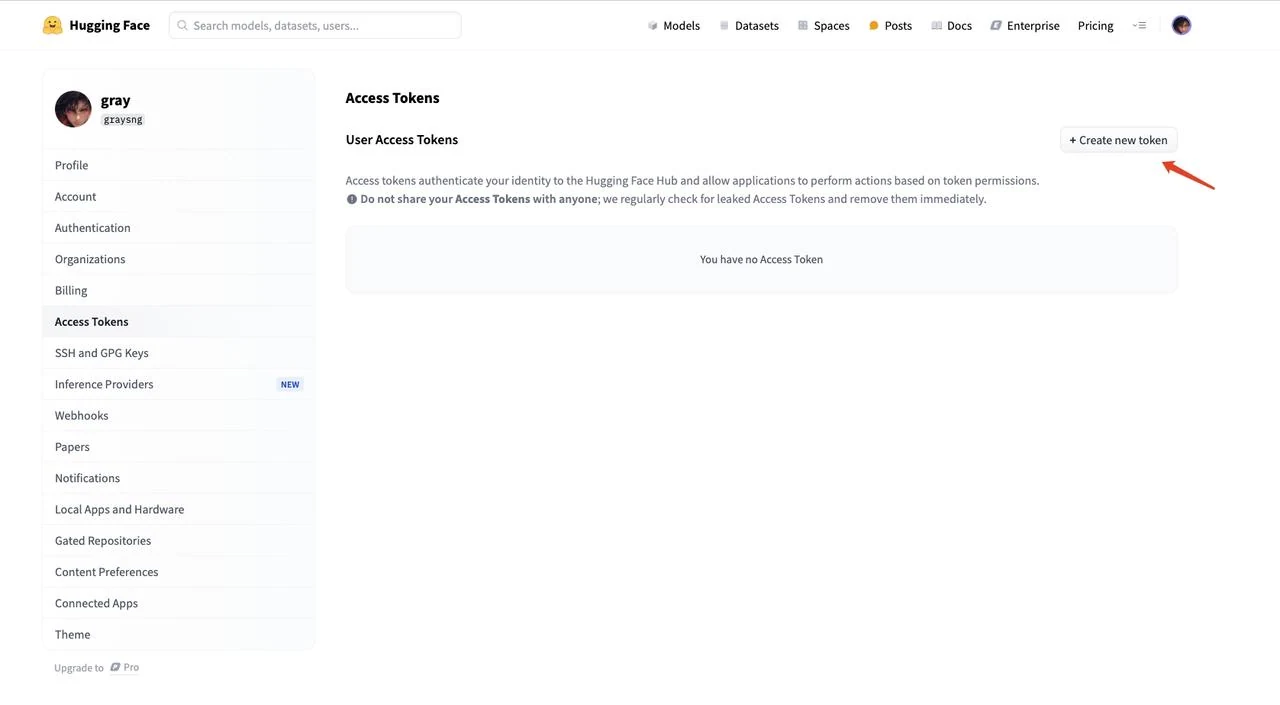
- Sélectionnez « Read » pour le type de token, donnez un nom à votre token (par exemple, « text ») et cliquez sur « Create token » pour générer le token.
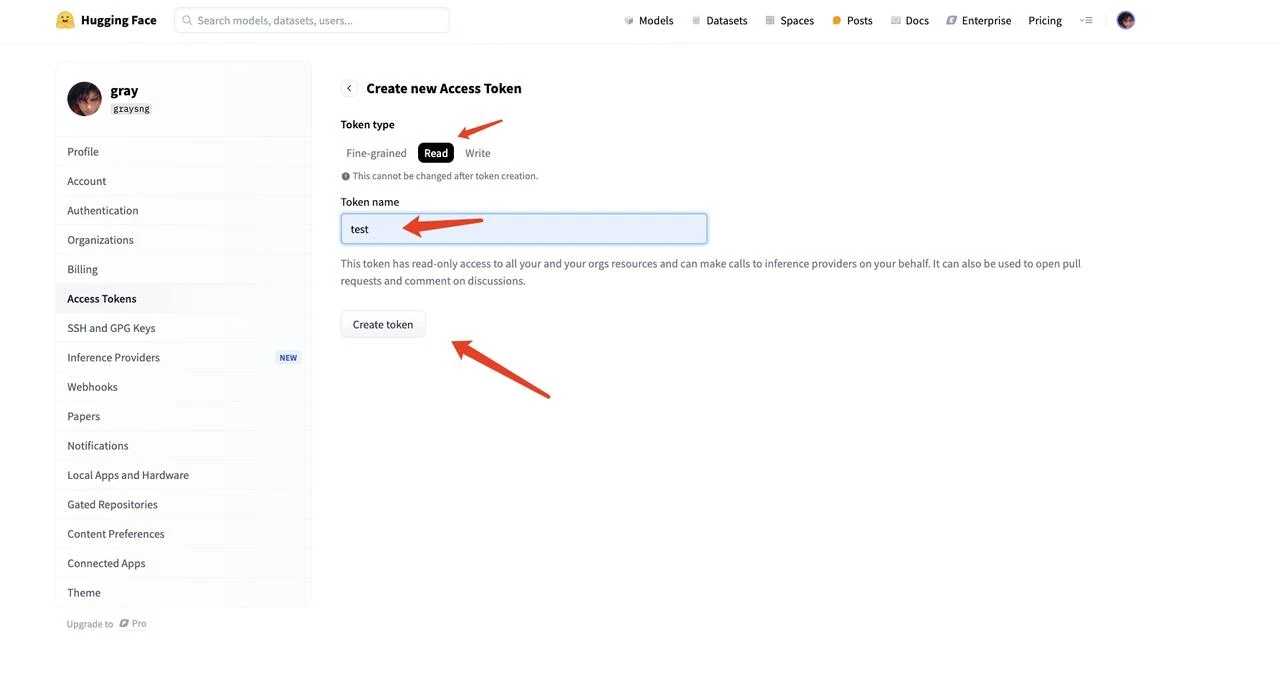
- Copiez la chaîne du token généré
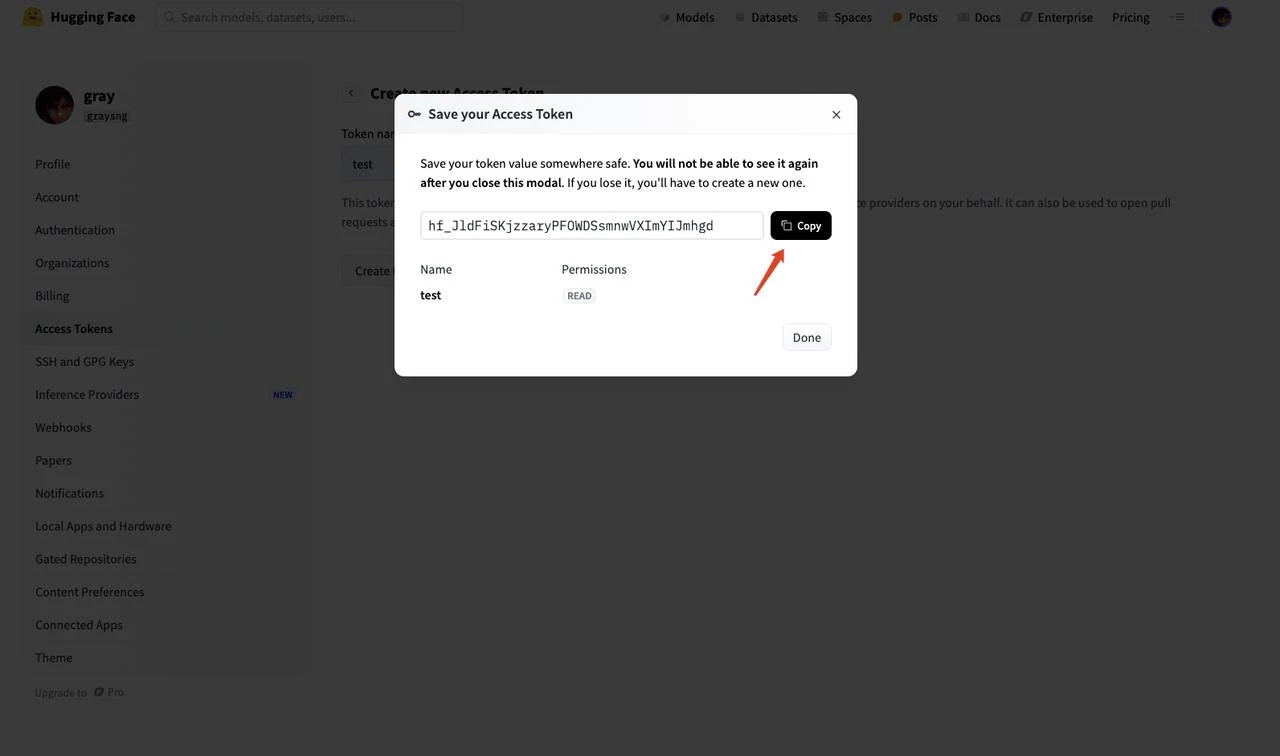
Après avoir obtenu le token, saisissez-le dans la variable d’environnement HF_TOKEN du modèle. Cliquez ensuite sur « Next ».
Étape 5 : Lancer une instance
Cliquez sur « Launch Instance » pour déployer votre environnement configuré.
Patientez quelques minutes pendant que l’instance est configurée et gérée.
Cliquez sur le menu déroulant pour consulter les journaux de l’instance.

Une fois l’instance démarrée, elle commencera à télécharger le modèle. Cliquez sur « Logs » → « Instance Logs » pour surveiller la progression du téléchargement.
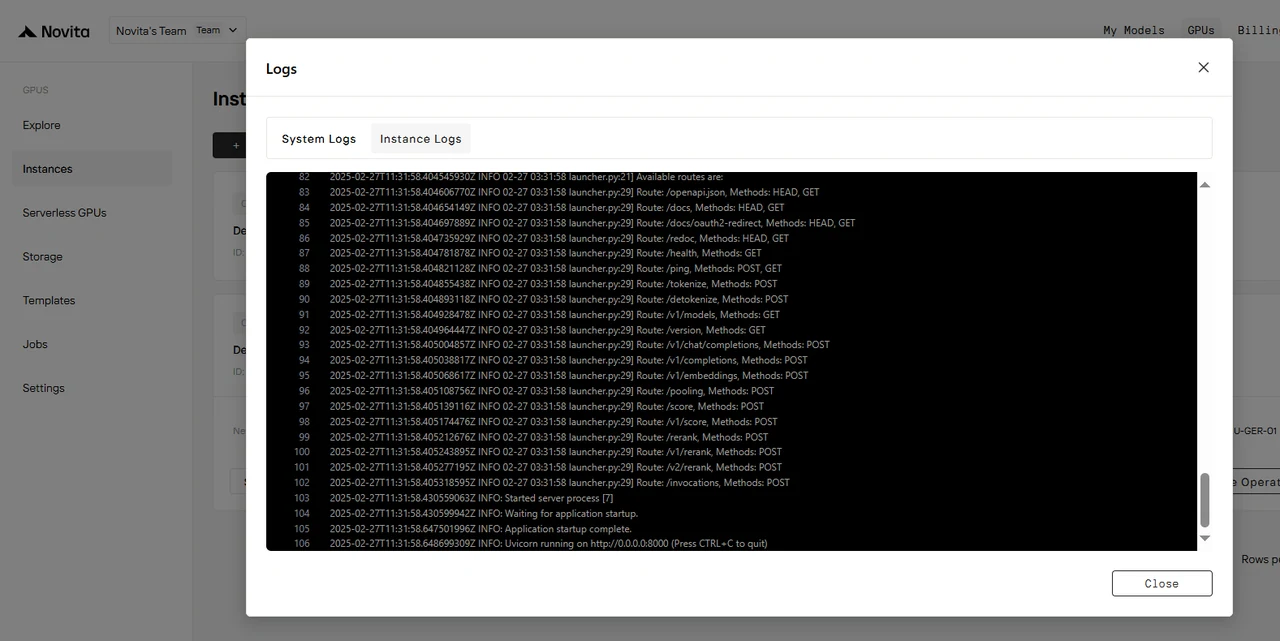
Lorsque le journal affiche « INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit) », le démarrage est réussi. Accédons maintenant à votre modèle privé !
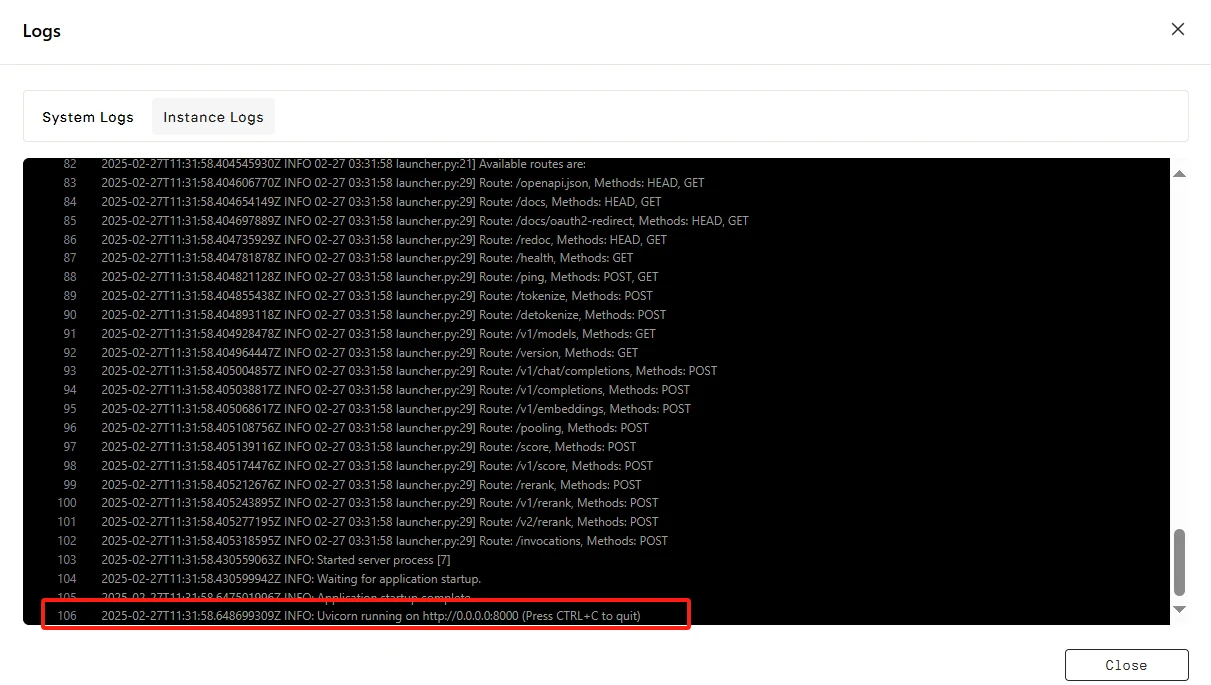
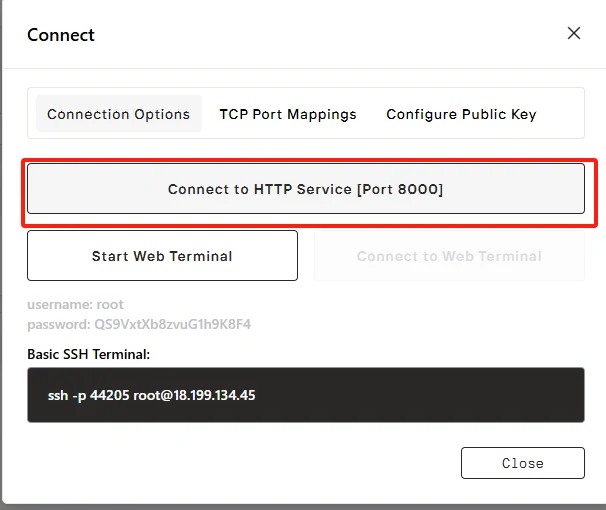
Cliquez sur « Connect », puis sur « Connect to HTTP Service [Port 8000] ». Comme il s’agit d’un service API, vous devrez copier l’adresse.


Pour envoyer des requêtes à votre modèle privé, veuillez remplacer « https://f6d29cb6f71e585e-8000.us-ca-1.gpu-instance.novita.ai » par votre adresse exposée réelle. Copiez le code suivant pour accéder à votre modèle privé !
$ curl https://f6d29cb6f71e585e-8000.us-ca-1.gpu-instance.novita.ai/v1/chat/completions \
-H "Content-Type: application/json" -d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"messages": [{"role": "user", "content": "hello"}]
}'
{"id":"chatcmpl-57b3296f87f54dd4b69cfb6d2196f48e","object":"chat.completion","created":1740711405,"model":"deepseek-ai/DeepSeek-R1-Distill-Qwen-32B","choices":[{"index":0,"message":{"role":"assistant","content":"Alright, the user said \"hello.\" That's a friendly greeting. I should respond in a welcoming manner.\
\
Maybe I can acknowledge their greeting and offer assistance.\
\
It's important to sound approachable and ready to help.\
\
I'll keep it simple and polite.\
response\
\
Hello! How can I assist you today?","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":6,"total_tokens":70,"completion_tokens":64,"prompt_tokens_details":null},"prompt_logprobs":null}

Configurez l’adresse API dans vos applications comme Chatbox, et vous aurez votre propre assistant personnel !
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Deploying DeepSeek Models on Novita AI Cloud Platform: A Comprehensive Guide) est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant le cloud GPU abordable et fiable pour construire et passer à l’échelle.



