

Модели DeepSeek стали привлекательным выбором в пространстве LLM, предлагая впечатляющую производительность при конкурентоспособных затратах. Хотя эти модели обладают мощными возможностями, успешное развертывание требует надежной и эффективной инфраструктурной платформы. В этом руководстве показано, как использовать облачную платформу Novita AI для оптимального развертывания моделей DeepSeek, сочетая высокую производительность с экономической эффективностью.
Обзор вариантов моделей
Дистиллированные версии
- Основаны на открытых моделях (серии Qwen2.5 и Llama)
- Диапазон параметров: 1,5B, 7B, 8B, 14B, 32B и 70B
- Оптимизированы для эффективного инференса при сохранении высокой производительности
- Идеальны для экономичных частных развертываний
- Легко развертываются с помощью решения Novita AI в один клик
Полномасштабная версия
- DeepSeek-R1-671B
- Построена на архитектуре DeepSeek-V3
- Имеет 671B параметров для максимальной производительности
- Требует значительных вычислительных ресурсов
- Доступна через наш оптимизированный API-сервис
Руководство по развертыванию
Шаг 1: Доступ к платформе Novita AI
- Посетите официальный сайт Novita AI: https://novita.ai/
[Попробуйте Novita AI сейчас](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Deploying DeepSeek Models on Novita AI Cloud Platform: A Comprehensive Guide)
- Создайте аккаунт или войдите в существующий

Шаг 2: Доступ к конфигурации GPU-инстанса
- Нажмите “GPUs” в главной навигации
- Нажмите “Get Started”, чтобы продолжить
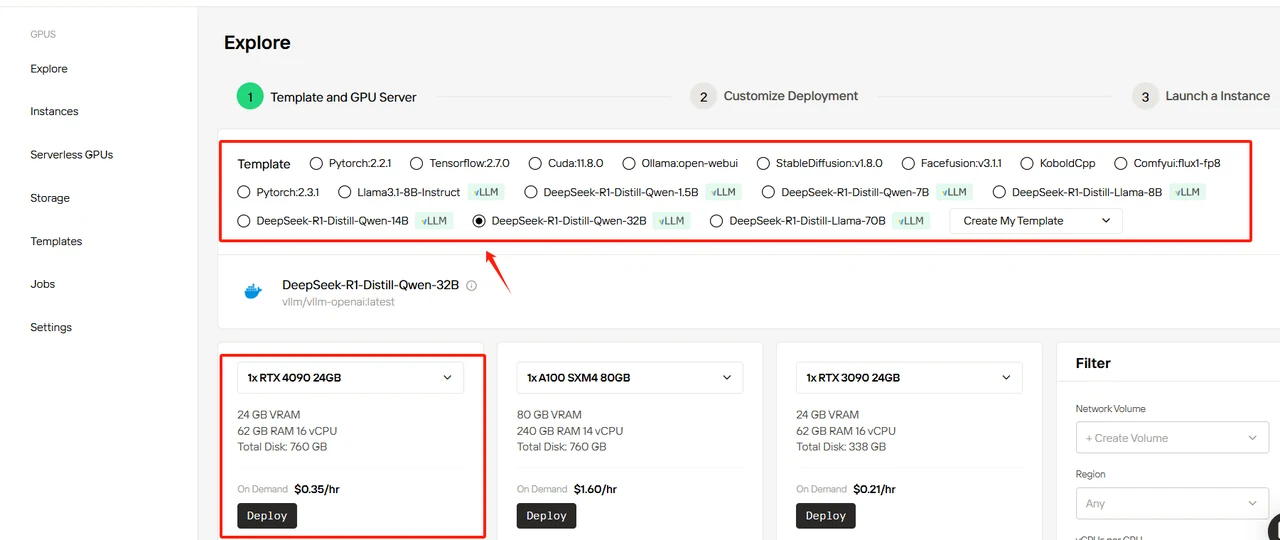
Шаг 3: Выбор и настройка модели DeepSeek
В этом руководстве в качестве примера будем использовать DeepSeek-R1-Distill-Llama-32B. Вы можете выбрать любой шаблон в зависимости от ваших потребностей, но этот шаблон определяет базовые параметры модели. Вам нужно настроить необходимое количество GPU — для этого развертывания мы рекомендуем использовать RTX 4090. Все шаблоны используют официальные модели DeepSeek с точностью BF16 по умолчанию. Ниже приведены наши рекомендуемые конфигурации:
| Модель | GPU | Точность | Количество |
| DeepSeek-R1-Distill-Qwen-1.5B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Qwen-7B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Llama-8B | BF16 | RTX 4090 | 1 |
| DeepSeek-R1-Distill-Qwen-14B | BF16 | RTX 4090 | 2 |
| DeepSeek-R1-Distill-Qwen-32B | BF16 | RTX 4090 | 4 |
| DeepSeek-R1-Distill-Llama-70B | BF16 | RTX 4090 | 8 |
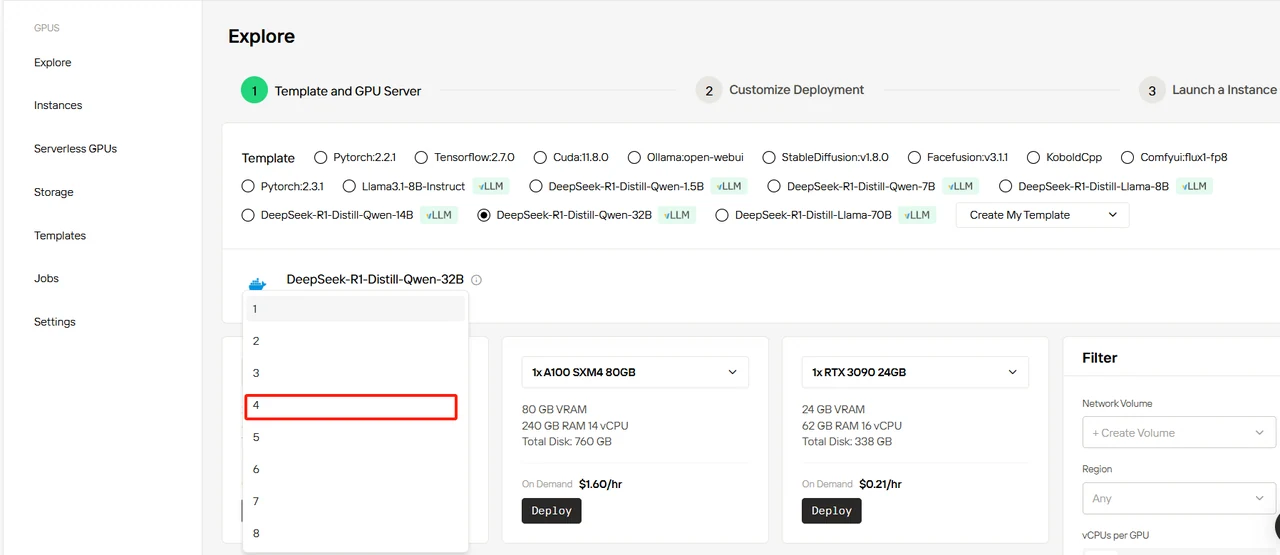
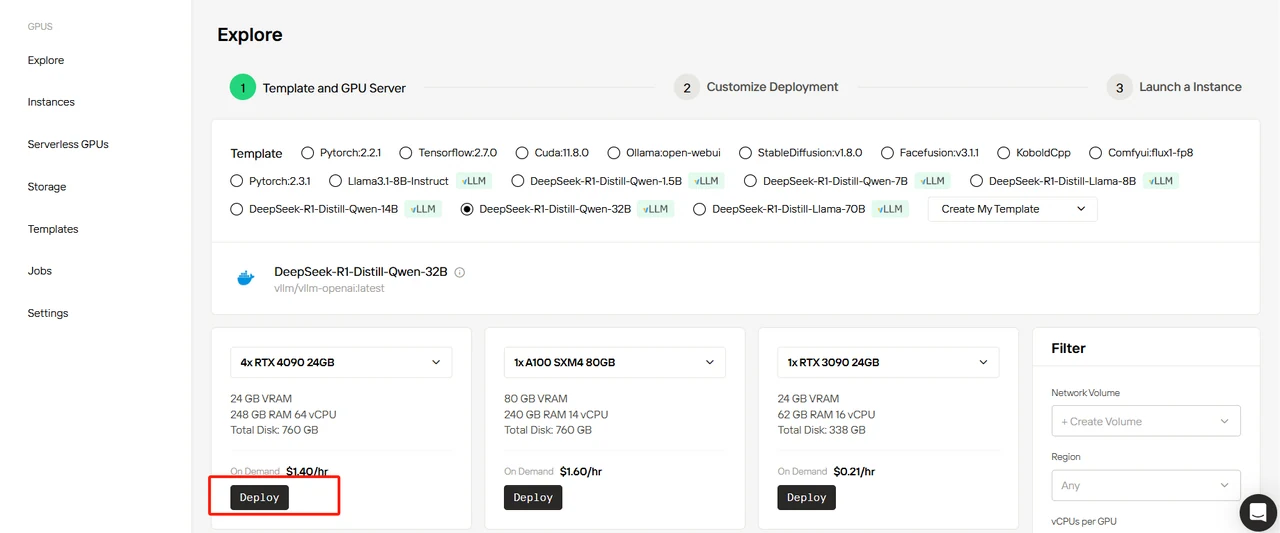
Выберите шаблон DeepSeek-R1-Distill-Qwen-32B, укажите 4 GPU и нажмите “Deploy”.
Шаг 4: Настройка развертывания
Подтвердите параметры шаблона и обязательно заполните переменную HF_TOKEN.
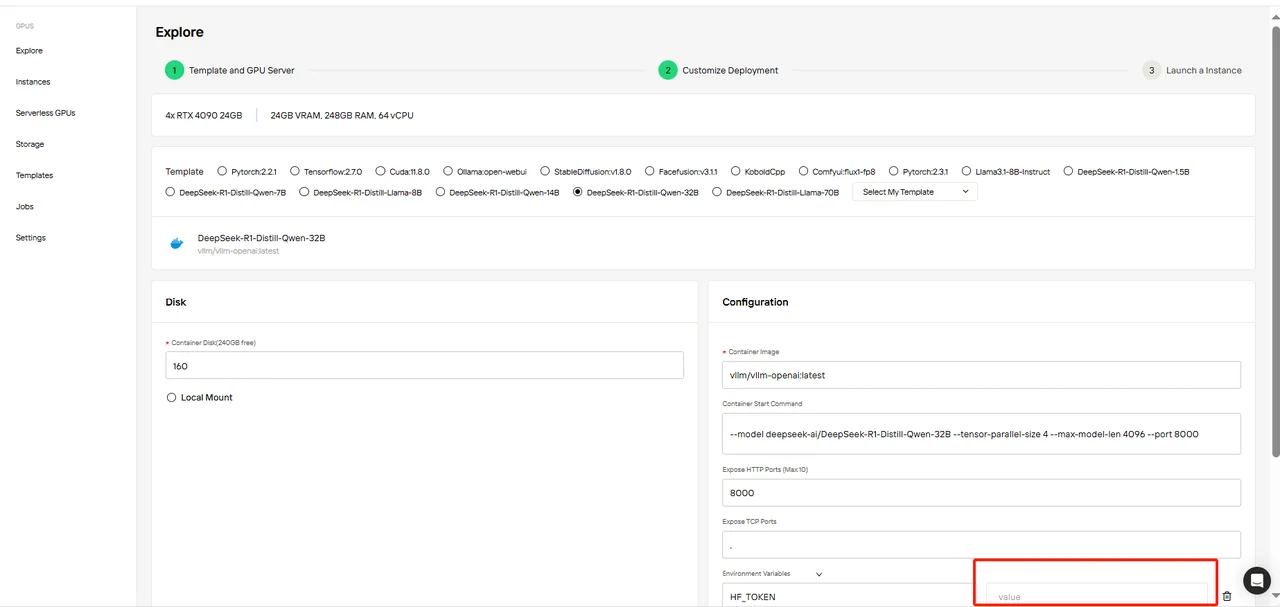
Вы можете получить HF_TOKEN, следуя этим подсказкам:
-
Перейдите на huggingface.co: https://huggingface.co/
-
Нажмите “Log In” в правом верхнем углу для входа или “Sign Up” для создания нового аккаунта
-
После входа нажмите на свою аватарку в правом верхнем углу и выберите “Access Tokens” в левом меню
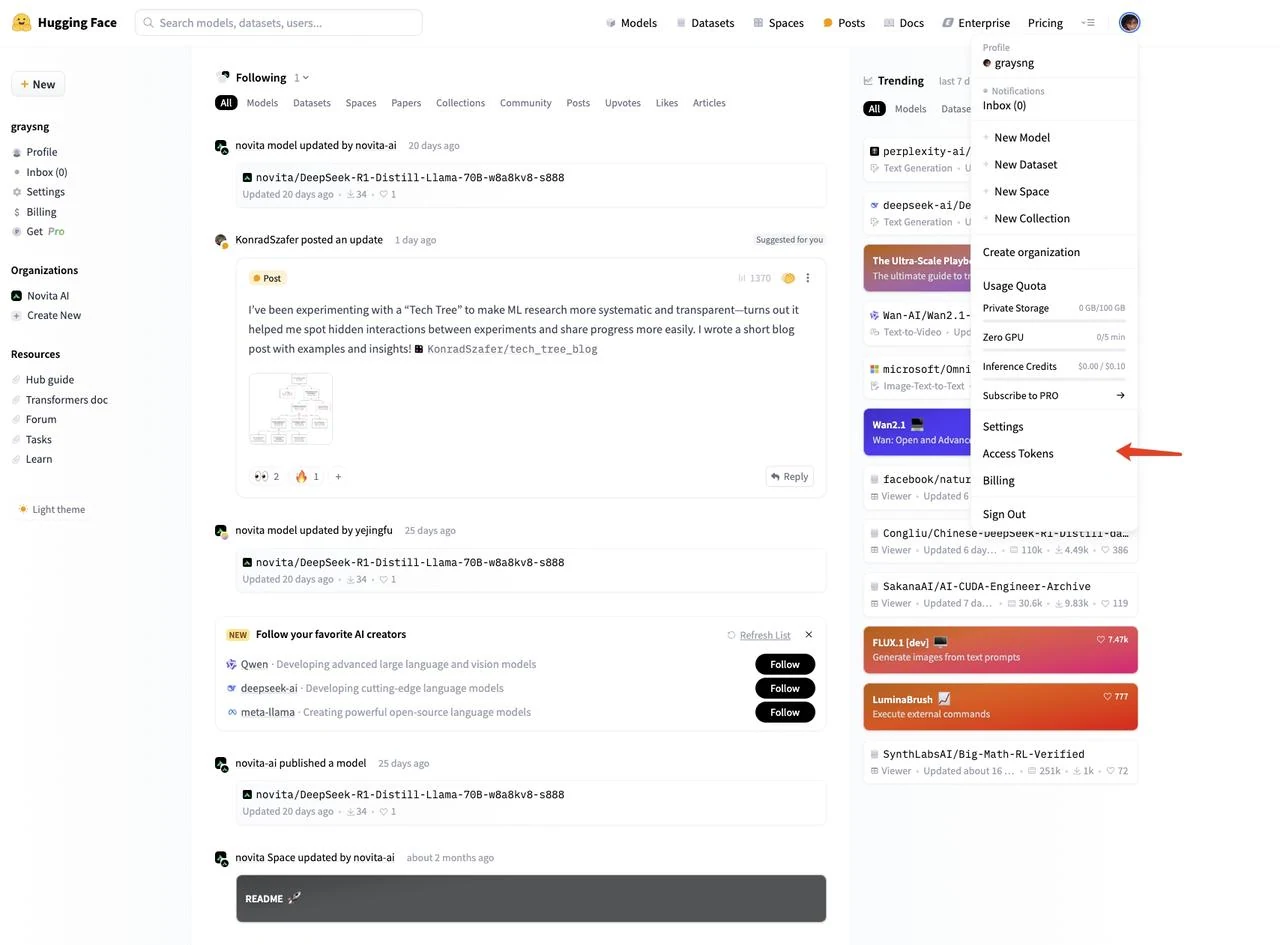
- Нажмите “New token”, чтобы создать новый токен доступа
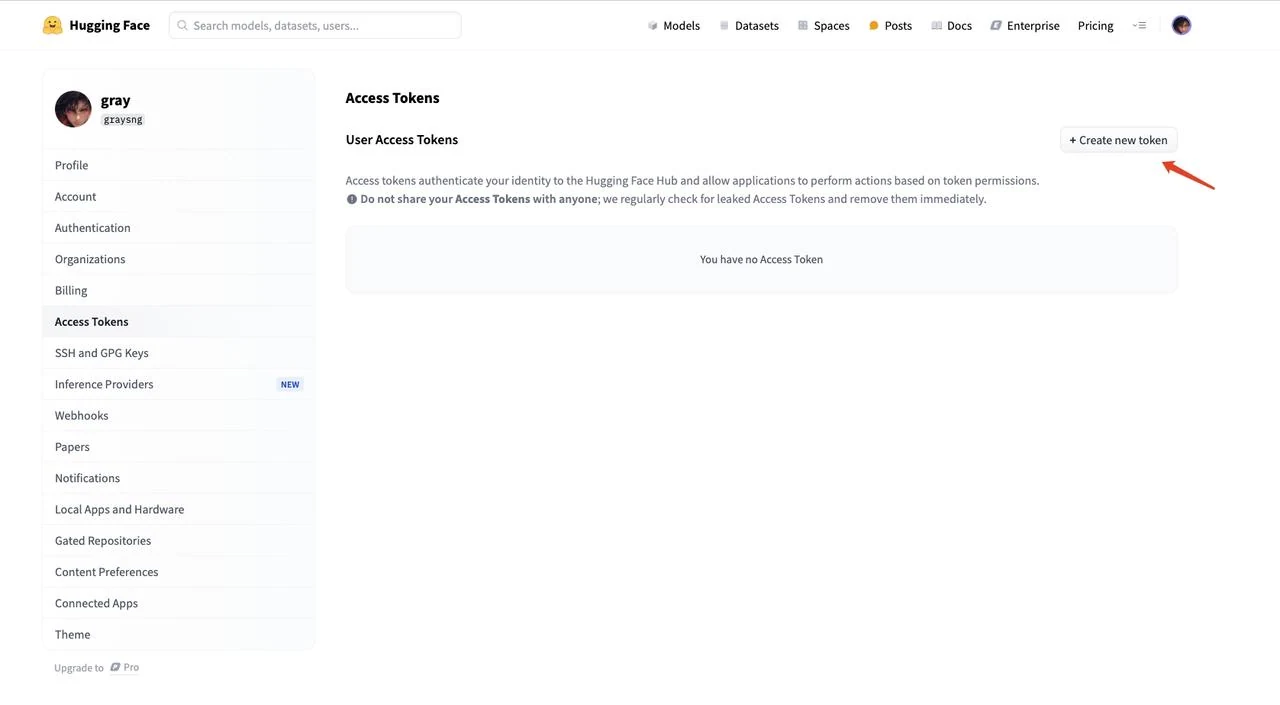
- Выберите “Read” для типа токена, дайте ему имя (например, “text”) и нажмите “Create token” для генерации токена
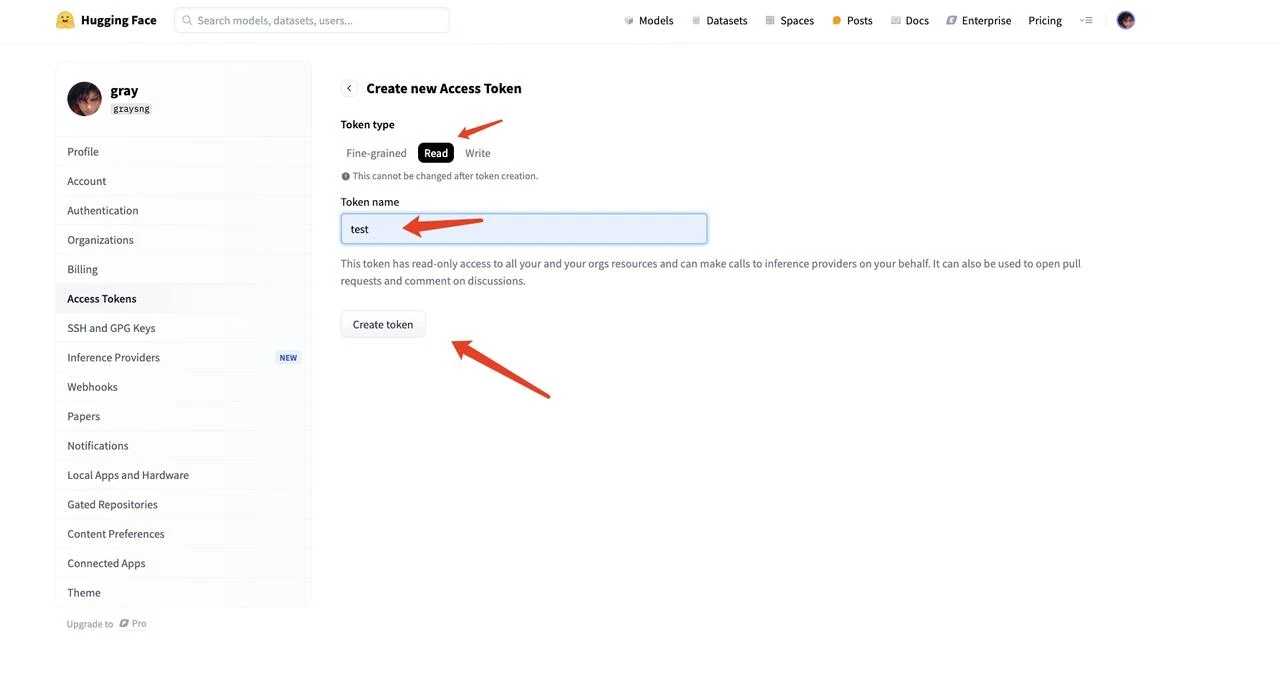
- Скопируйте сгенерированную строку токена
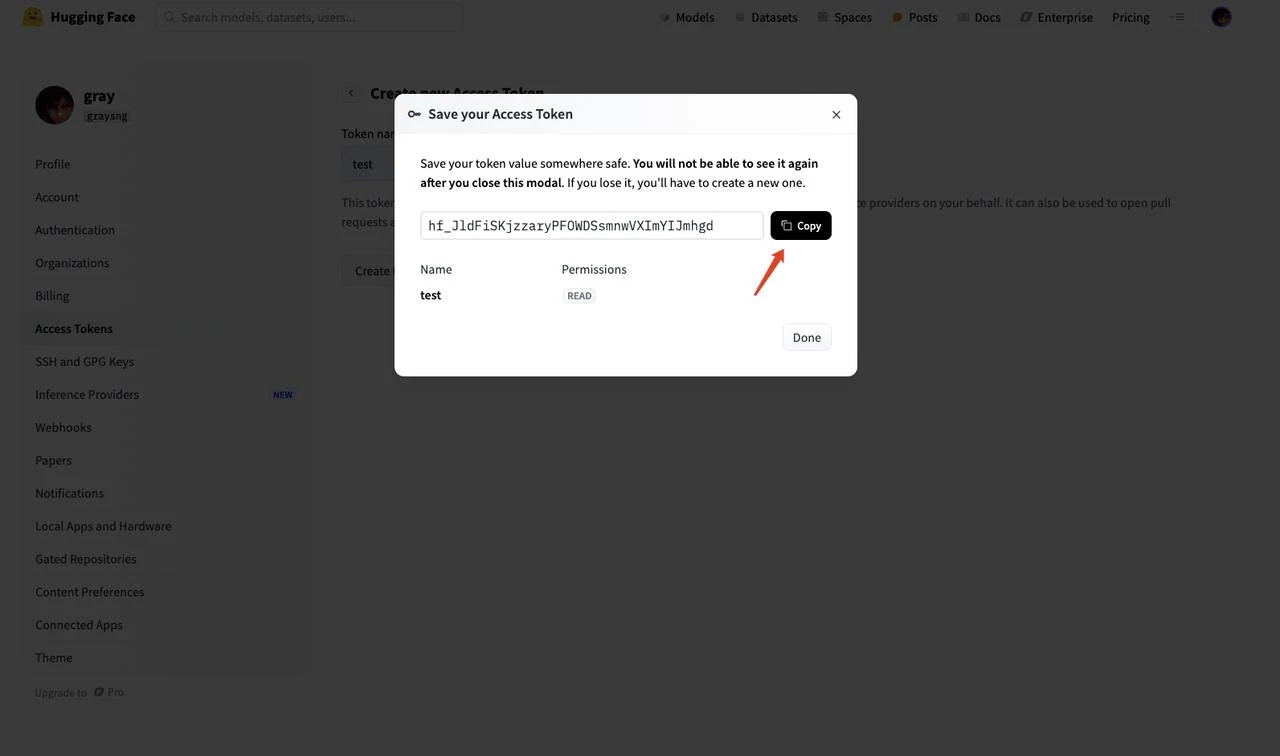
После получения токена введите его в переменную окружения HF_TOKEN в шаблоне. Затем нажмите “Next”.
Шаг 5: Запуск инстанса
Нажмите “Launch Instance”, чтобы развернуть настроенную среду.
Подождите несколько минут, пока инстанс настраивается и управляется.
Нажмите на выпадающее меню, чтобы просмотреть логи инстанса.

После запуска инстанса начнется загрузка модели. Нажмите “Logs” --> “Instance Logs”, чтобы отслеживать прогресс загрузки модели.
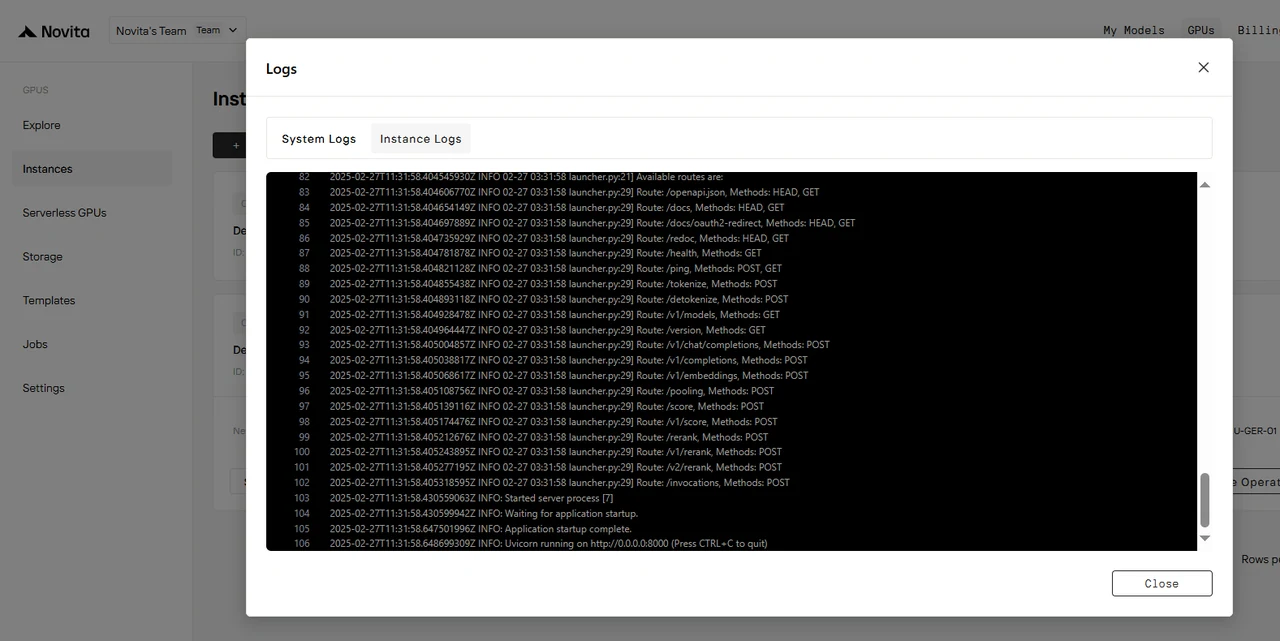
Когда в логах появится "INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)", запуск прошел успешно. Теперь давайте получим доступ к вашей частной модели!
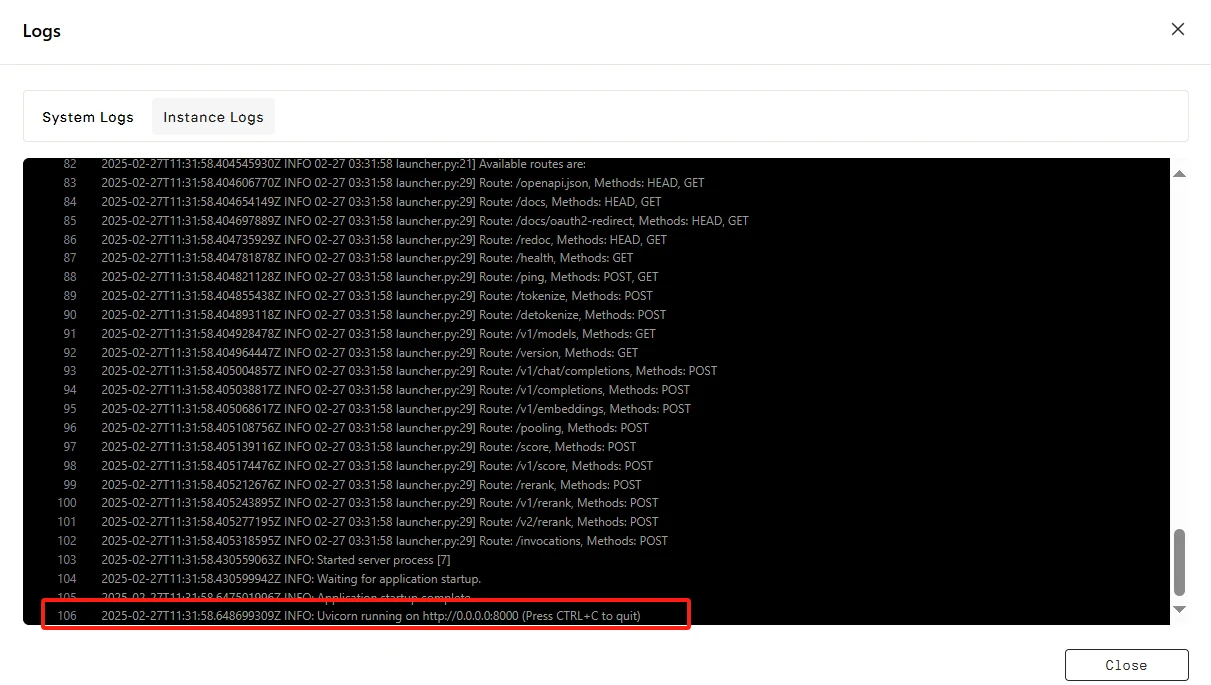
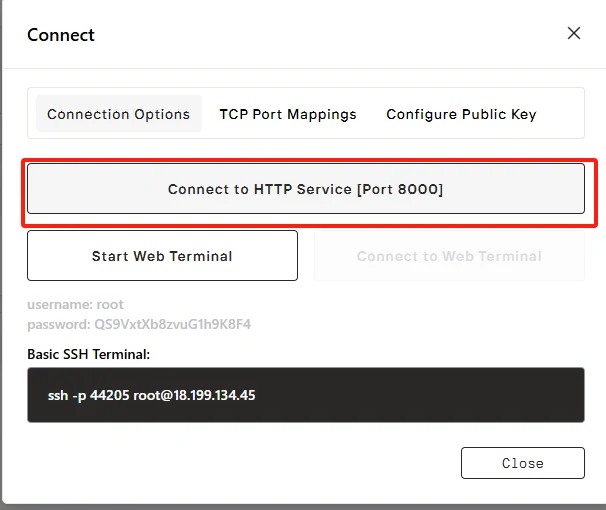
Нажмите “Connect”, затем --> “Connect to HTTP Service [Port 8000]”. Поскольку это API-сервис, вам нужно скопировать адрес.


Чтобы отправлять запросы к вашей частной модели, замените “https://f6d29cb6f71e585e-8000.us-ca-1.gpu-instance.novita.ai” на ваш фактический внешний адрес. Скопируйте следующий код для доступа к вашей частной модели!
$ curl https://f6d29cb6f71e585e-8000.us-ca-1.gpu-instance.novita.ai/v1/chat/completions \
-H "Content-Type: application/json" -d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"messages": [{"role": "user", "content": "hello"}]
}'
{"id":"chatcmpl-57b3296f87f54dd4b69cfb6d2196f48e","object":"chat.completion","created":1740711405,"model":"deepseek-ai/DeepSeek-R1-Distill-Qwen-32B","choices":[{"index":0,"message":{"role":"assistant","content":"Alright, the user said \"hello.\" That's a friendly greeting. I should respond in a welcoming manner.\
\
Maybe I can acknowledge their greeting and offer assistance.\
\
It's important to sound approachable and ready to help.\
\
I'll keep it simple and polite.\
response\
\
Hello! How can I assist you today?","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":6,"total_tokens":70,"completion_tokens":64,"prompt_tokens_details":null},"prompt_logprobs":null}

Настройте адрес API в своих приложениях, таких как Chatbox, и у вас будет собственный персональный ассистент!
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Deploying DeepSeek Models on Novita AI Cloud Platform: A Comprehensive Guide) — это облачная платформа ИИ, которая предоставляет разработчикам простой способ развертывания моделей ИИ с помощью нашего простого API, а также предлагает доступное и надежное GPU-облако для создания и масштабирования.



