

Gemma 3 — это новейшее семейство открытых ИИ-моделей от Google, созданное для того, чтобы быть легковесным, эффективным и широко доступным. С размером параметров от 270M до 27B серия предлагает гибкие варианты для всего: от быстрых экспериментов до корпоративных приложений.
В этой статье мы рассматриваем семейство моделей Gemma 3 в разрезе размера параметров, сравниваем их спецификации, результаты бенчмарков производительности, сильные и слабые стороны, сценарии использования для каждой модели, а также способы получения к ним доступа локально или через единый API Novita AI.
Модели Gemma 3: Основные характеристики и результаты бенчмарков

Семейство моделей Gemma 3: Основные характеристики
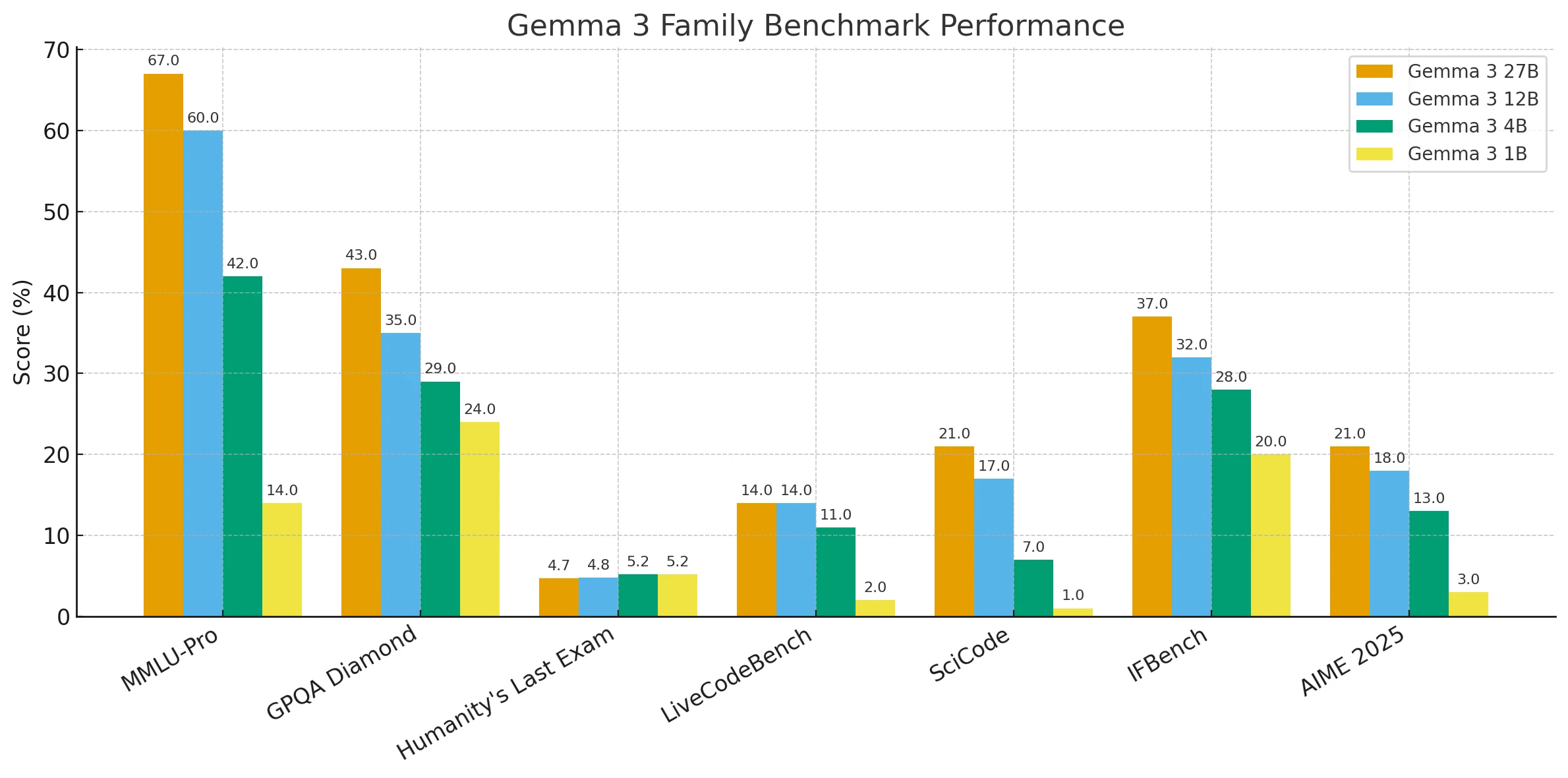
Сравнение результатов бенчмарков моделей Gemma 3
В целом, результаты показывают четкую тенденцию: модели с большим размером параметров стабильно демонстрируют более высокую производительность в бенчмарках на рассуждение, знания и программирование, в то время как меньшие модели, хотя и более легковесные и простые в развертывании, отстают в решении сложных задач.
Детальный анализ моделей Gemma 3 по размеру параметров
Модель с 270M параметрами
| Аспект | Плюсы | Минусы / Ограничения |
|---|---|---|
| Производительность и сценарии использования | 1) Генерирует связные предложения для своего размера. 2) Предоставляет легковесную базу для дообучения на узких задачах. 3) После дообучения достаточно хорошо справляется с структурированными выводами (например, простая классификация, тегирование, JSON). 4) Может поддерживать спекулятивное декодирование или базовое суммирование на мобильных устройствах. |
1) Значительно слабее более крупных моделей Gemma в задачах на рассуждение и знания. 2) Отсутствуют фактические/общие знания; склонна к галлюцинациям. 3) Полезность из коробки минимальна, требуется дообучение. 4) Малый размер увеличивает риск переобучения. |
| Ресурсы и скорость | 1) Экстремально легковесная (~400 МБ). 2) Очень быстрая, работает на ЦП, недорогих ноутбуках и мобильных устройствах. 3) Дообучение возможно на обычном потребительском оборудовании. |
1) Не подходит для сложных задач или задач с длинным контекстом. 2) Чувствительна к настройкам квантования и оптимизации. |
Модель с 1B параметрами
| Аспект | Плюсы | Минусы / Ограничения |
|---|---|---|
| Производительность и сценарии использования | 1) Легковесная и стабильно работает. Полезна для спекулятивного декодирования для ускорения работы более крупных моделей. 2) Хорошо подходит для быстрого мозгового штурма или исправления синтаксиса JSON. |
1) Слабая способность следовать инструкциям. 2) Очень низкая общая производительность. Ограничена только текстовыми задачами, склонна к галлюцинациям. |
| Ресурсы и скорость | 1) Экстремально маленькая (≈800 МБ). 2) Оптимизирована для мобильных устройств и конфигураций RAG (генерации с дополнением поиском). |
— |
Модель с 4B параметрами
| Аспект | Плюсы | Минусы / Ограничения |
|---|---|---|
| Производительность и сценарии использования | Сочетает баланс размера и производительности. Способна к ролевым играм и работе в легковесных приложениях. Дает относительно сильные результаты в расширении запросов. |
Склонна к галлюцинациям. Испытывает трудности со структурированным рассуждением и выводом корректного JSON. Работает медленнее, чем 1B, и больше нагружает системные ресурсы. |
| Ресурсы и скорость | Достаточно быстрая для генерации кода. | Требует больше ресурсов, чем 1B. |
Модель с 12B параметрами
| Аспект | Плюсы | Минусы / Ограничения |
|---|---|---|
| Производительность и сценарии использования | 1) Значительное улучшение по сравнению с моделью 4B. 2) Надежные выводы с сниженным уровнем галлюцинаций. 3) Дает качественные результаты в генерации кода и расширении запросов. |
1) Слишком медленная для генерации кода в реальных условиях на скромных по мощности системах. 2) Производительность падает при недостатке видеопамяти (при переключении между GPU и CPU). |
| Ресурсы и скорость | 1) Сбалансированное соотношение производительности и размера модели. 2) Практичный вариант для пользователей без дискретных GPU. |
— |
Модель с 27B параметрами
| Аспект | Плюсы | Минусы / Ограничения |
|---|---|---|
| Производительность и сценарии использования | 1) Обеспечивает производительность высшего уровня. 2) Отлично справляется с программированием (например, SQL) и задачами классификации/перевода. 3) Точно определяет достопримечательности и хорошо интегрируется с инструментами для разработчиков. |
1) Требует мощного оборудования. 2) Крайне медленная без высокопроизводительных GPU. 3) Все еще испытывает трудности с отрицанием, пространственным рассуждением и мультимодальными задачами, например, с историческими изображениями. |
| Ресурсы и скорость | 1) Высокая отзывчивость на корпоративных GPU (например, H100). 2) Большой объем занимаемого места (~17 ГБ), для конфигурации draft+main требуется ~28 ГБ оперативной памяти. |
1) Высокие требования к видеопамяти (≥32 ГБ). |
Модели Gemma 3: Соответствие сценариям использования
Семейство Gemma 3 предлагает модели с широким диапазоном размеров параметров, каждая из которых оптимизирована для разных сценариев развертывания.
- Модель 270M предназначена для ультралегковесных экспериментов, обучения и дообучения на узких задачах, легко запускается на недорогом оборудовании.
- Модель 1B обеспечивает большую стабильность и может использоваться для экспериментов на мобильных устройствах, поддержки спекулятивного декодирования и простых служебных задач.
- При 4B параметрах Gemma 3 становится более практичной, позволяя выполнять легковесные ролевые игры, генерацию креативного текста и эксперименты с RAG (генерацией с дополнением поиском) на ранних стадиях.
- Модель 12B сочетает баланс производительности и требований к ресурсам, что делает ее надежным выбором для сред без выделенных GPU, а также поддерживает более стабильную креативную генерацию.
- Модель 27B предназначена для корпоративных приложений, отлично справляется с продвинутым программированием, классификацией текста и задачами на рассуждение с высокой производительностью, хотя для эффективной работы требует мощного GPU-оборудования.
Модели Gemma 3: Требования к локальному развертыванию
| Параметры | BF16 (16-бит) | SFP8 (8-бит) | Q4_0 (4-бит) | Рекомендуемое оборудование |
|---|---|---|---|---|
| Gemma 3 270M | 400 МБ | 297 МБ | 240 МБ | Работает на ЦП; любой современный ноутбук/телефон; начальные GPU (GTX 1650, RTX 3050). |
| Gemma 3 1B | 1,5 ГБ | 1,1 ГБ | 892 МБ | Начальные GPU (RTX 3050/3060); также возможна работа на ЦП для легких задач. |
| Gemma 3 4B | 6,4 ГБ | 4,4 ГБ | 3,4 ГБ | GPU среднего класса (RTX 3060 12 ГБ, RTX 4060/4070). |
| Gemma 3 12B | 20 ГБ | 12,2 ГБ | 8,7 ГБ | Высокопроизводительные потребительские или полупрофессиональные GPU (RTX 3090/4090, RTX 4080, A6000). |
| Gemma 3 27B | 46,4 ГБ | 29,1 ГБ | 21 ГБ | Корпоративные GPU (A100, H100) или конфигурации с несколькими GPU. |
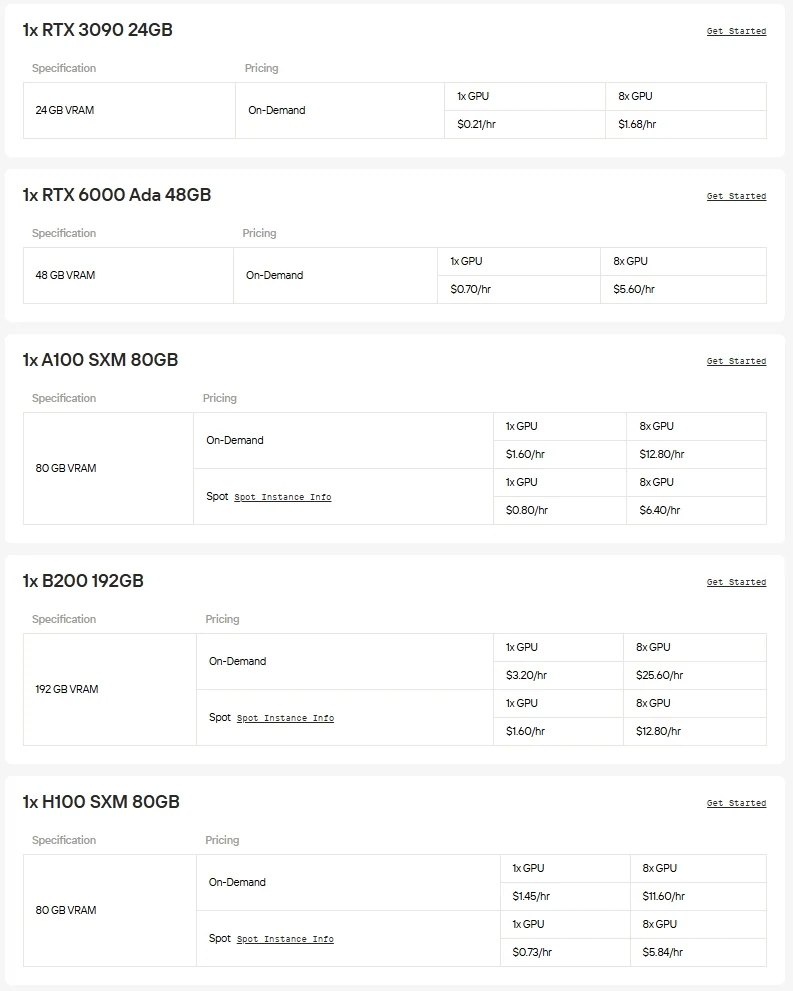
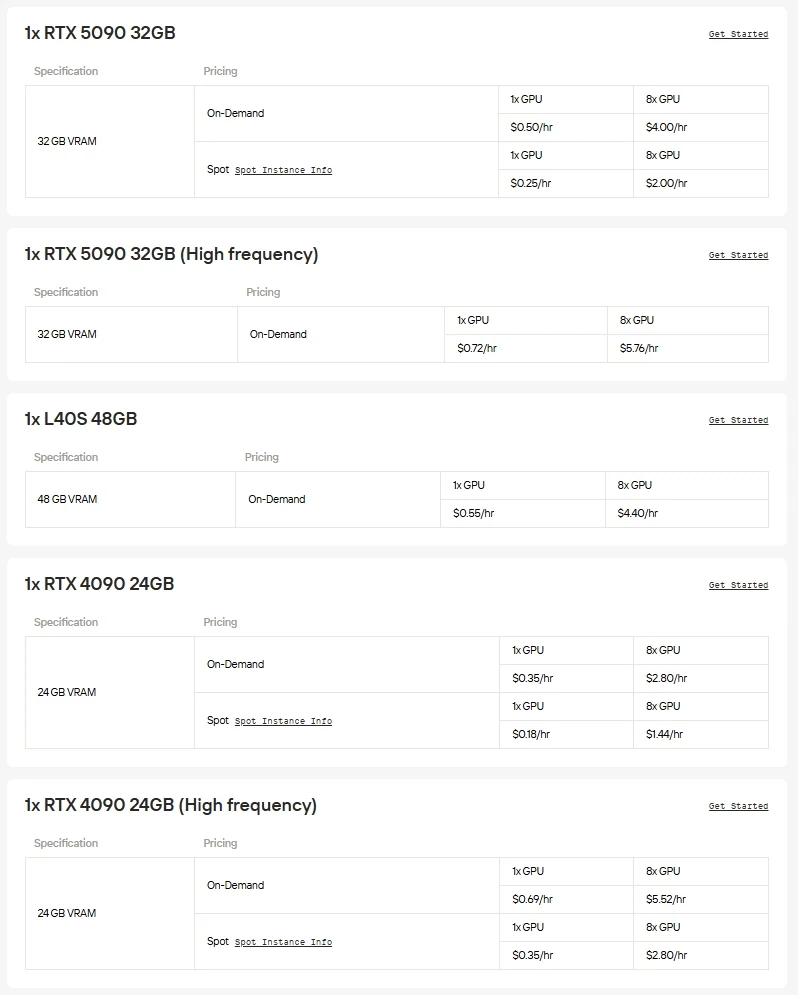
Хотя меньшие модели Gemma 3 (270M и 1B) могут работать на ЦП или начальных GPU, локальное развертывание версий 12B или 27B требует высокопроизводительного или корпоративного оборудования с 20–50 ГБ видеопамяти. Для тех, кто хочет исследовать весь потенциал Gemma 3 без инвестиций в дорогостоящую инфраструктуру, практической альтернативой являются облачные GPU-инстансы.
Novita AI предоставляет доступ по запросу к высокопроизводительным GPU, таким как NVIDIA A100, H100, H200 и B200, а также продвинутым потребительским картам, таким как RTX 3090, RTX 4090 и RTX 6000 Ada. Это позволяет вам бесшовно запускать крупномасштабные модели, масштабировать ресурсы по необходимости и платить только за то, что вы используете.
Разверните свои модели Gemma 3 сейчас
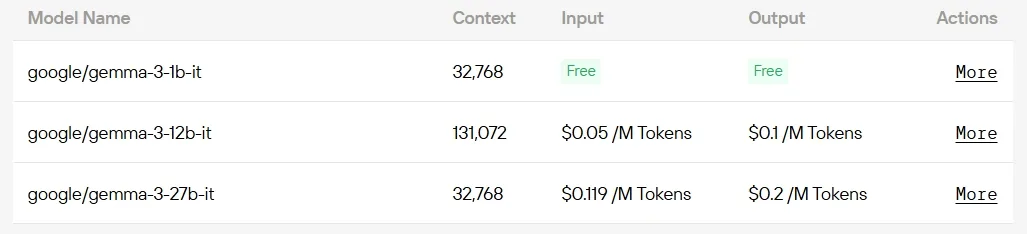
Если вы хотите избежать хлопот с оборудованием и настройкой, то единый API Novita AI — это самый быстрый способ получить доступ к Gemma 3. Получите мгновенный доступ к различным моделям без загрузок и инфраструктуры, чтобы сосредоточиться на разработке, масштабировании и создании ценности.
Начните бесплатный пробный период на Novita AI сейчас!
Доступ к моделям Gemma 3 через API
Шаг 1: Войдите в систему и откройте библиотеку моделей

Шаг 2: Выберите модель
Просмотрите доступные варианты и выберите модель, которая подходит вашим потребностям.
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы исследовать возможности выбранной модели.
Шаг 4: Получите ваш API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки аккаунта», вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API (в качестве примера используется Gemma 3 12B)
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с LLM Novita AI. Это пример использования API завершения чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-3-12b-it",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
Семейство моделей Gemma 3 наглядно показывает, как масштаб модели влияет как на возможности, так и на требования к развертыванию. Модель 270M демонстрирует, как далеко можно зайти в плане эффективности: ультралегковесная, быстрая и простая в дообучении, но с очень ограниченными возможностями в рассуждении и знаниях. Модель 1B остается компактной, предлагая при этом немного больше стабильности, хотя все еще значительно уступает более крупным моделям в точности и глубине. Модель 4B попадает в более практичный диапазон, давая более сильные результаты в креативных задачах и задачах на рассуждение, хотя галлюцинации остаются распространенным явлением. Модель 12B обеспечивает заметный баланс производительности и доступности, выдавая надежные результаты без необходимости использования корпоративного оборудования. Модель 27B представляет собой пик возможностей Gemma 3, отлично справляясь со сложными рассуждениями и программированием, но требующая значительных ресурсов GPU для эффективной работы.
Для разработчиков, ищущих экономически эффективный доступ, Novita AI предлагает бесшовное развертывание моделей Gemma 3 через API — при этом некоторые из них доступны совершенно бесплатно.
Часто задаваемые вопросы
Какие размеры параметров предлагает Gemma 3?
Gemma 3 доступна в размерах параметров 270M, 1B, 4B, 12B и 27B, каждая из которых разработана для разных потребностей в развертывании и уровней производительности.
Какая модель Gemma 3 предлагает лучший баланс между производительностью и требованиями к ресурсам?
Модель 12B часто считается «золотой серединой», предлагая высокую производительность без необходимости использования корпоративных GPU.
Могут ли модели Gemma 3 работать на потребительском оборудовании, таком как ноутбуки или настольные компьютеры?
Да. Модели 270M и 1B легко работают на ЦП и начальных GPU, в то время как модели 4B и 12B требуют GPU среднего и высокого класса. Модель 27B обычно требует корпоративных GPU, таких как A100 или H100.
Novita AI — это универсальная облачная платформа, которая помогает реализовать ваши амбиции в области ИИ. Интегрированные API, бессерверные решения, GPU-инстансы — доступные инструменты, которые вам нужны. Избавьтесь от инфраструктуры, начните бесплатно и воплотите ваше видение ИИ в реальность.



