

Gemma 3は、Googleの最新のオープンソースAIモデルファミリーで、軽量かつ効率的で広くアクセス可能なように設計されています。パラメータサイズは270Mから27Bまであり、迅速な実験からエンタープライズ規模のアプリケーションまで、柔軟な選択肢を提供します。
この記事では、Gemma 3モデルファミリーをパラメータサイズごとに詳しく解説し、仕様、性能ベンチマーク、強みと限界、各モデルのユースケース、さらにローカルまたはNovita AIの統一API経由でのアクセス方法を比較します。
Gemma 3モデル:基本機能とベンチマーク

Gemma 3モデルファミリー:基本
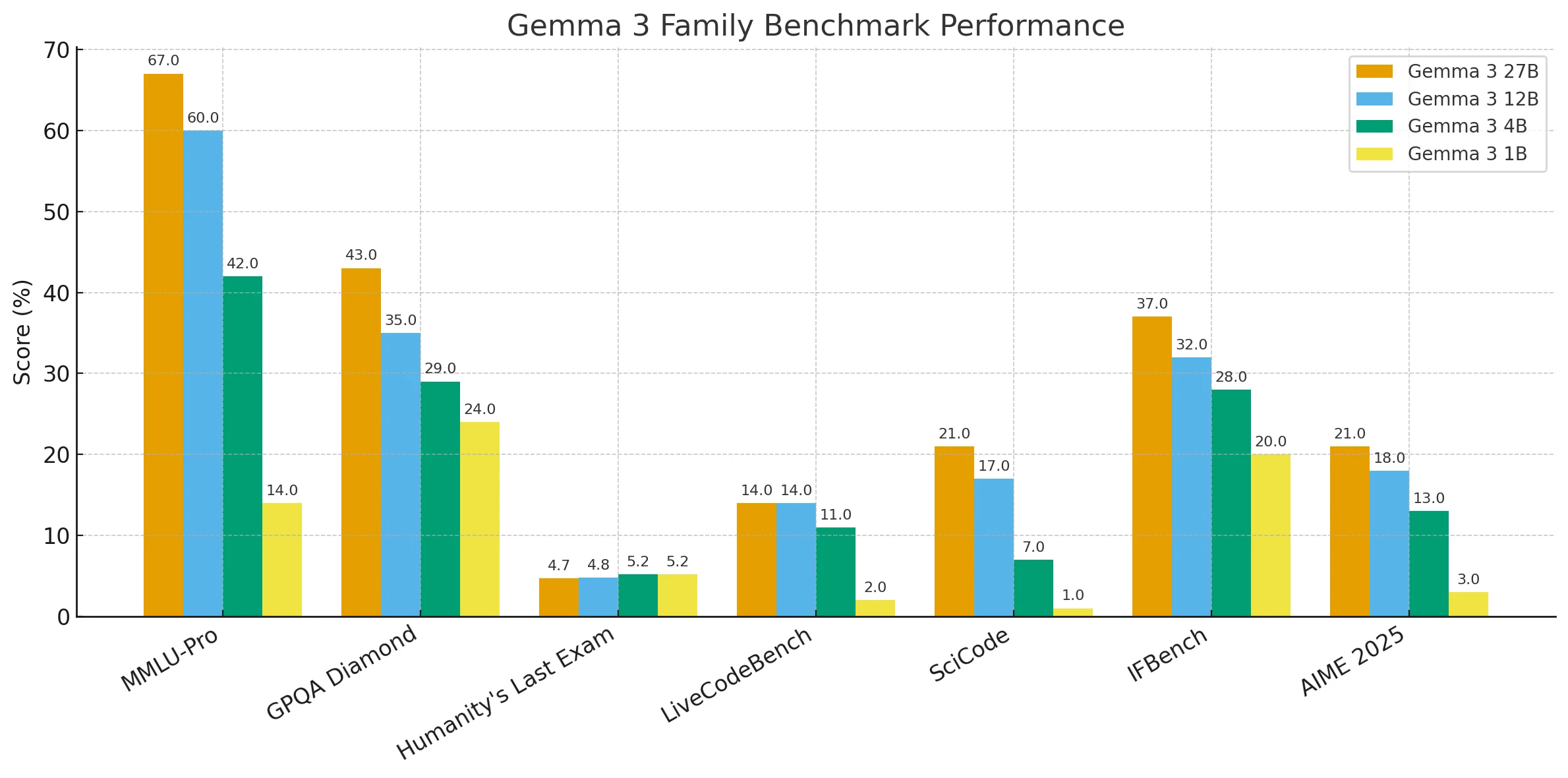
Gemma 3モデルベンチマーク比較
全体的に、結果は明確な傾向を示しています。パラメータサイズが大きいほど、推論、知識、コーディングのベンチマークで一貫して高いパフォーマンスを発揮する一方、小さいモデルは軽量でデプロイしやすいものの、複雑なタスクでは劣ります。
Gemma 3モデル:パラメータサイズ別詳細分析
270Mパラメータモデル
| 側面 | 長所 | 短所・制限 |
|---|---|---|
| パフォーマンス&ユースケース | 1) サイズの割に一貫性のある文を生成。 2) 狭いタスクのファインチューニング向けの軽量ベースを提供。 3) チューニング後、構造化出力(単純な分類、タグ付け、JSONなど)で妥当に動作。 4) 投機的復号やモバイル上の簡易要約をサポート可能。 |
1) 大きなGemmaモデルに比べ、推論・知識タスクで大幅に弱い。 2) 事実・世界知識が不足し、幻覚を起こしやすい。 3) そのままでは使い道がほとんどなく、ファインチューニングが必要。 4) サイズが小さいため過学習のリスクが高い。 |
| リソース&速度 | 1) 非常に軽量(約400MB)。 2) 非常に高速で、CPU、低スペックノートPC、モバイル端末でも動作。 3) 市販ハードウェアでファインチューニングが可能。 |
1) 複雑なタスクや長いコンテキストのワークロードには不向き。 2) 量子化や最適化設定に敏感。 |
1Bパラメータモデル
| 側面 | 長所 | 短所・制限 |
|---|---|---|
| パフォーマンス&ユースケース | 1) 軽量でスムーズに動作。大きなモデルを高速化する投機的復号に有用。 2) クイックなブレインストーミングやJSON構文修正に適している。 |
1) 指示追従能力が弱い。 2) 全体的な性能が非常に限定的。テキストのみのタスクに限定され、幻覚を起こしやすい。 |
| リソース&速度 | 1) 非常に小さい(約800MB)。 2) モバイルやRAG構成に最適化。 |
— |
4Bパラメータモデル
| 側面 | 長所 | 短所・制限 |
|---|---|---|
| パフォーマンス&ユースケース | サイズとパフォーマンスのバランスが取れている。 ロールプレイや軽量アプリケーションが可能。 プロンプト拡張で比較的強い結果を提供。 |
幻覚が起きやすい。 構造化推論や有効なJSON出力が苦手。 1Bより遅く、システムリソースをより消費。 |
| リソース&速度 | コード生成ではそこそこ高速。 | 1Bよりリソースを消費。 |
12Bパラメータモデル
| 側面 | 長所 | 短所・制限 |
|---|---|---|
| パフォーマンス&ユースケース | 1) 4Bから大幅に改善。 2) 幻覚が減り、信頼性の高い出力。 3) コードやプロンプト拡張で魅力的な結果を生成。 |
1) 中程度のシステムでは現実的なコード生成には遅すぎる。 2) VRAM不足時にパフォーマンスが低下(GPU-CPUスワップ)。 |
| リソース&速度 | 1) パフォーマンスとモデルサイズのバランスが良い。 2) GPUを持たないユーザーにも実用的な選択肢。 |
— |
27Bパラメータモデル
| 側面 | 長所 | 短所・制限 |
|---|---|---|
| パフォーマンス&ユースケース | 1) トップクラスのパフォーマンス。 2) コーディング(SQLなど)や分類・翻訳タスクで優れる。 3) ランドマーク識別が正確で、開発者ツールとの統合も良好。 |
1) 強力なハードウェアが必要。 2) 高性能GPUがないと極端に遅い。 3) 否定、空間推論、歴史的画像のようなマルチモーダルタスクには依然として課題あり。 |
| リソース&速度 | 1) エンタープライズグレードGPU(例:H100)で高い応答性。 2) フットプリントが大きい(〜17GB)、ドラフト+メイン構成で約28GB RAM必要。 |
1) 高いVRAM要件(≥32GB)。 |
Gemma 3モデル:ユースケースマッピング
Gemma 3ファミリーは、さまざまなパラメータサイズのモデルを提供し、それぞれ異なる展開シナリオに最適化されています。
- 270Mモデルは、超軽量の実験、教育、狭いタスクのファインチューニング向けに設計され、低スペックハードウェアで簡単に動作します。
- 1Bモデルはより安定しており、モバイル実験、投機的復号のサポート、単純なユーティリティタスクに使用できます。
- 4Bパラメータになると、Gemma 3はより実用的になり、軽量ロールプレイ、クリエイティブなテキスト生成、初期段階のRAG(検索拡張生成)実験が可能になります。
- 12Bモデルはパフォーマンスとリソース要求のバランスが取れており、専用GPUがない環境でも堅実な選択肢であり、より一貫したクリエイティブ生成をサポートします。
- 27Bモデルはエンタープライズレベルのアプリケーションを対象としており、高度なコーディング、テキスト分類、高性能推論タスクで優れていますが、効果的に動作させるには強力なGPUハードウェアが必要です。
Gemma 3モデル:ローカルデプロイ要件
| パラメータ | BF16(16ビット) | SFP8(8ビット) | Q4_0(4ビット) | 推奨ハードウェア |
|---|---|---|---|---|
| Gemma 3 270M | 400 MB | 297 MB | 240 MB | CPUで動作。最新のノートPC/スマートフォン、エントリーレベルGPU(GTX 1650、RTX 3050)。 |
| Gemma 3 1B | 1.5 GB | 1.1 GB | 892 MB | エントリーレベルGPU(RTX 3050/3060)。軽い用途ならCPUでも可。 |
| Gemma 3 4B | 6.4 GB | 4.4 GB | 3.4 GB | ミッドレンジGPU(RTX 3060 12GB、RTX 4060/4070)。 |
| Gemma 3 12B | 20 GB | 12.2 GB | 8.7 GB | ハイエンドコンシューマーまたはプロシューマーGPU(RTX 3090/4090、RTX 4080、A6000)。 |
| Gemma 3 27B | 46.4 GB | 29.1 GB | 21 GB | エンタープライズGPU(A100、H100)またはマルチGPU構成。 |
小規模なGemma 3モデル(270M、1B)はCPUやエントリーレベルGPUで動作しますが、12Bや27Bをローカルにデプロイするには、20~50GBのVRAMを持つハイエンドまたはエンタープライズグレードのハードウェアが必要です。高価なインフラに投資せずにGemma 3の可能性を最大限に試したい方には、クラウドベースのGPUインスタンスが実用的な代替手段となります。
Novita AI は、NVIDIA A100、H100、H200、B200などの高性能GPUや、RTX 3090、RTX 4090、RTX 6000 Adaなどの先進的なコンシューマーカードへのオンデマンドアクセスを提供します。これにより、大規模モデルをシームレスに実行し、必要に応じてリソースを拡張し、使用した分だけ支払うことができます。
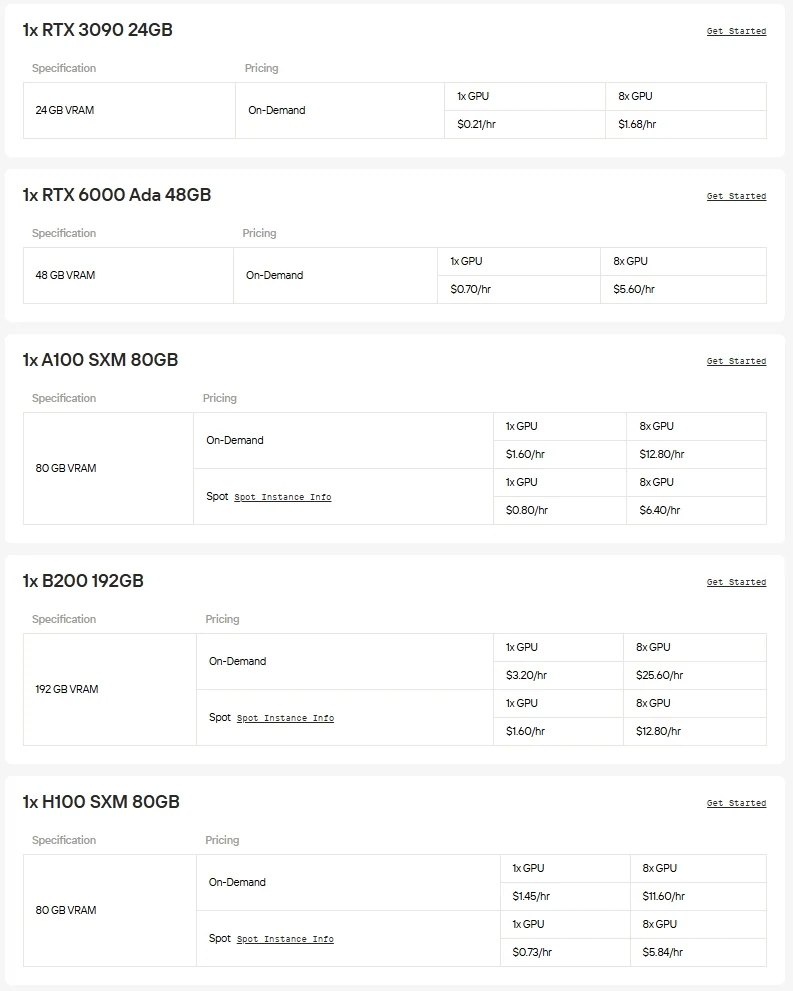
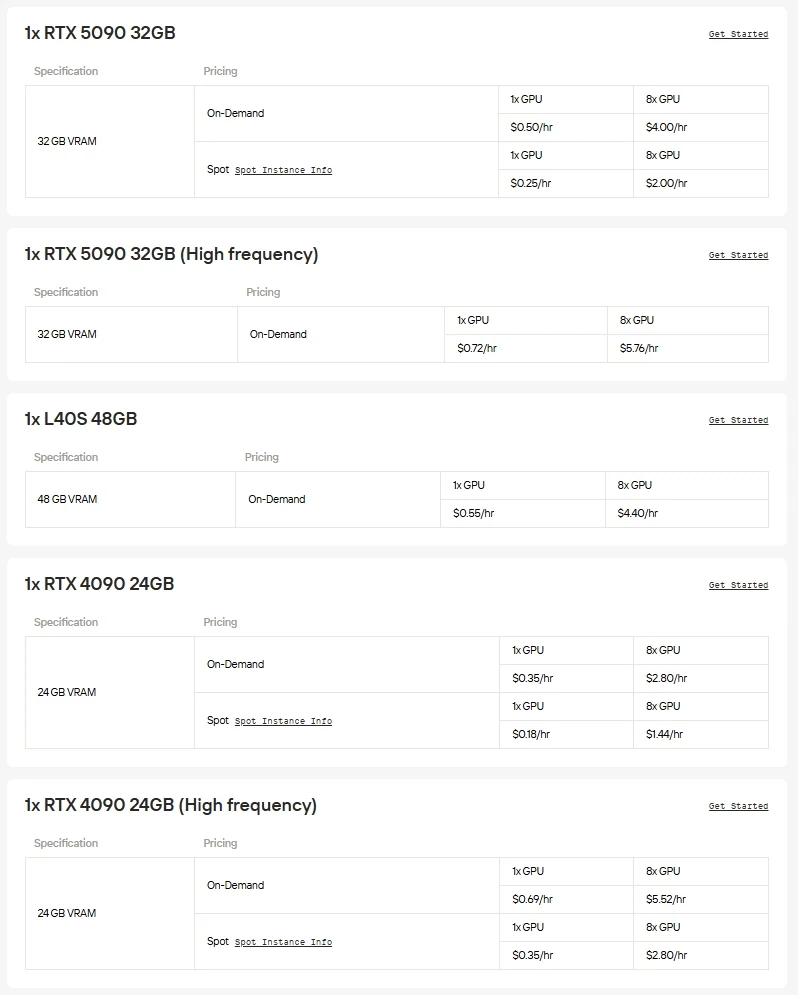
ハードウェアやセットアップの手間を省きたいなら、Novita AIの統一APIがGemma 3を最速で利用する方法です。ダウンロードやインフラなしでさまざまなモデルに即座にアクセスできるため、構築、スケーリング、価値の提供に集中できます。
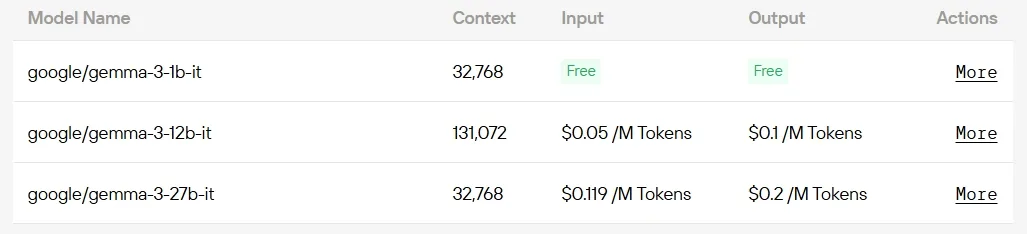
API経由でGemma 3モデルにアクセスする方法
ステップ1:ログインしてモデルライブラリにアクセス

ステップ2:モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。
ステップ3:無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
ステップ4:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「アカウント設定」ページに移動し、画像の指示に従ってAPIキーをコピーします。

ステップ5:APIをインストール(例:Gemma 3 12B)
使用するプログラミング言語に応じたパッケージマネージャーを使用してAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーを使ってAPIを初期化し、Novita AI LLMとの対話を開始します。これはPythonユーザー向けのチャット補完APIの例です。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-3-12b-it",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
Gemma 3モデルファミリーは、モデル規模が能力とデプロイ要件にどのように影響するかを示しています。270Mモデルは効率性の限界を示しており、超軽量、高速、ファインチューニングが容易ですが、推論と知識は非常に限定的です。1Bモデルはコンパクトながらやや安定性が向上していますが、精度と深さでは大きなモデルに大きく劣ります。4Bモデルはより実用的な範囲に入り、クリエイティブなタスクや推論タスクでより強力な結果を提供しますが、幻覚は依然として一般的です。12Bモデルはパフォーマンスとアクセシビリティの顕著なバランスを提供し、エンタープライズグレードのハードウェアを必要とせずに信頼性の高い出力を生成します。27BモデルはGemma 3の能力の頂点を表し、複雑な推論やコーディングで優れていますが、効果的に動作させるにはかなりのGPUリソースが必要です。
コスト効率の良いアクセスを求める開発者向けに、Novita AIはAPIを通じてGemma 3モデルのシームレスなデプロイを提供します。一部は完全に無料で利用できます。
よくある質問
Gemma 3はどのようなパラメータサイズを提供していますか?
Gemma 3は270M、1B、4B、12B、27Bのパラメータサイズで利用可能で、それぞれ異なるデプロイニーズとパフォーマンスレベルに合わせて設計されています。
パフォーマンスとリソース要件の最良のバランスを提供するGemma 3モデルはどれですか?
12Bモデルはしばしば「スイートスポット」と見なされ、エンタープライズレベルのGPUを必要とせずに強力なパフォーマンスを提供します。
Gemma 3モデルはノートPCやデスクトップなどの消費者向けハードウェアで実行できますか?
はい。270Mおよび1BモデルはCPUやエントリーレベルGPUで簡単に動作します。4Bおよび12BモデルはミッドレンジからハイエンドのGPUが必要です。27Bモデルには通常、A100やH100などのエンタープライズGPUが必要です。
Novita AIは、AIの野望を実現するオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — コスト効率の高いツールを提供します。インフラを排除し、無料で始めて、AIのビジョンを現実にしましょう。



