

Gemma 3 是 Google 最新推出的開源 AI 模型系列,設計目標是輕量、高效且廣泛易用。參數量範圍從 270M 到 27B,提供了從快速實驗到企業級應用的彈性選擇。
本文將依參數量解析 Gemma 3 模型系列,比較各模型的規格、效能基準、優缺點、適用場景,以及如何在本機或透過 Novita AI 的统一 API 存取。
Gemma 3 模型:基本特性與效能基準

Gemma 3 模型系列:基本特性
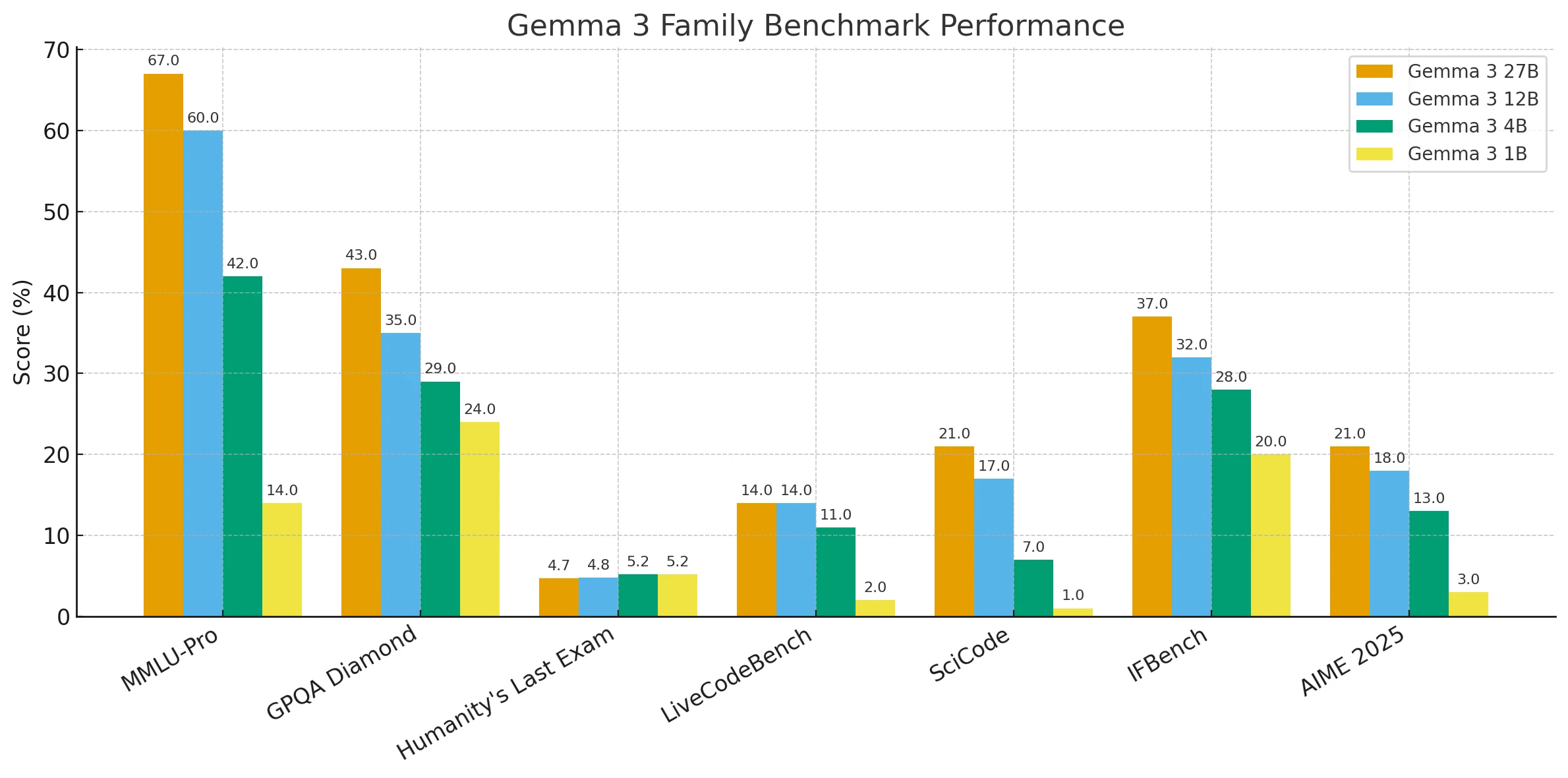
Gemma 3 模型基準效能比較
總體而言,結果呈現明顯趨勢:參數量越大的模型,在推理、知識和程式碼基準測試中始終能提供更強的效能,而較小的模型雖然更輕量、更容易部署,在複雜任務上的表現則落後一截。
Gemma 3 模型依參數量詳細解析
270M 參數量模型
| 面向 | 優點 | 缺點 / 限制 |
|---|---|---|
| 效能與使用場景 | 1) 在同等參數量下能生成連貫的句子。 2) 提供輕量的基礎,適合用於窄域任務的微調。 3) 微調後在結構化輸出(例如簡單分類、標記、JSON)的表現尚可。 4) 可支援推測解碼,或在行動裝置上執行基礎摘要任務。 |
1) 在推理和知識任務上的表現遠遜於更大的 Gemma 模型。 2) 缺乏事實與 worldly 知識,容易產生幻覺。 3) 開箱即用的實用性極低,需要進行微調。 4) 模型尺寸小會增加過擬合的風險。 |
| 資源與速度 | 1) 極度輕量(約 400MB)。 2) 速度非常快,可在 CPU、入門級筆電和行動裝置上運行。 3) 可在普通硬體上進行微調。 |
1) 不適合複雜或長文本上下文的工作負載。 2) 對量化和優化設定非常敏感。 |
1B 參數量模型
| 面向 | 優點 | 缺點 / 限制 |
|---|---|---|
| 效能與使用場景 | 1) 輕量且運行流暢,可用於推測解碼來加速更大的模型。 2) 適合快速腦力激盪或 JSON 語法修復。 |
1) 指令遵循能力弱。 2) 整體效能非常有限,僅能處理純文字任務,容易產生幻覺。 |
| 資源與速度 | 1) 體積極小(約 800MB)。 2) 針對行動裝置和 RAG(檢索增強生成)場景優化。 |
— |
4B 參數量模型
| 面向 | 優點 | 缺點 / 限制 |
|---|---|---|
| 效能與使用場景 | 在尺寸與效能間取得平衡。 能勝任角色扮演與輕量級應用。 在提示詞擴展任務上的表現相對出色。 |
容易產生幻覺。 在結構化推理與有效 JSON 輸出上表現不佳。 速度比 1B 模型慢,且更耗費系統資源。 |
| 資源與速度 | 程式碼生成速度尚可。 | 比 1B 模型更耗資源。 |
12B 參數量模型
| 面向 | 優點 | 缺點 / 限制 |
|---|---|---|
| 效能與使用場景 | 1) 效能比 4B 模型有顯著提升。 2) 輸出結果可靠,幻覺問題大幅減少。 3) 在程式碼生成與提示詞擴展任務上的表現優異。 |
1) 在普通硬體上執行真實世界程式碼生成時速度過慢。 2) 當顯存不足時效能會下降(會觸發 GPU 與 CPU 的資料交換)。 |
| 資源與速度 | 1) 效能與模型尺寸的比例均衡。 2) 對於沒有獨立 GPU 的使用者來說是實用的選擇。 |
— |
27B 參數量模型
| 面向 | 優點 | 缺點 / 限制 |
|---|---|---|
| 效能與使用場景 | 1) 提供頂級效能。 2) 在程式碼(例如 SQL)以及分類/翻譯任務上表現優異。 3) 地標識別準確,且能與開發者工具良好整合。 |
1) 需要強勁的硬體支援。 2) 沒有高端 GPU 的情況下運行速度極慢。 3) 在否定推理、空間推理以及歷史影像等多模態任務上仍有不足。 |
| 資源與速度 | 1) 在企業級 GPU(例如 H100)上運行時響應速度極快。 2) 模型佔用空間大(約 17GB),在草稿+主模型架構下需要約 28GB 的記憶體。 |
1) 顯存需求高(需 ≥32GB)。 |
Gemma 3 模型:使用場景對應
Gemma 3 系列提供了涵蓋廣泛參數量的模型,每個模型都針對不同的部署場景進行了優化。
- 270M 模型:專為超輕量實驗、教育用途以及窄域任務微調設計,可在入門級硬體上輕鬆運行。
- 1B 模型:穩定性更高,可用於行動裝置實驗、推測解碼支援以及簡單的實用任務。
- 4B 參數量:Gemma 3 在此尺寸下實用性大幅提升,可支援輕量角色扮演、創意文字生成以及早期階段的 RAG(檢索增強生成)實驗。
- 12B 模型:在效能與資源需求間取得平衡,是沒有獨立 GPU 的環境的穩健選擇,同時也能支援更穩定的創意生成。
- 27B 模型:針對企業級應用設計,在進階程式碼編寫、文字分類和高性能推理任務上表現優異,但需要強勁的 GPU 硬體才能有效運行。
Gemma 3 模型:本機部署需求
| 參數量 | BF16(16位元) | SFP8(8位元) | Q4_0(4位元) | 推薦硬體 |
|---|---|---|---|---|
| Gemma 3 270M | 400 MB | 297 MB | 240 MB | 可在 CPU 上運行;任何現代筆電/手機;入門級 GPU(GTX 1650、RTX 3050)。 |
| Gemma 3 1B | 1.5 GB | 1.1 GB | 892 MB | 入門級 GPU(RTX 3050/3060);輕度使用也可在 CPU 上運行。 |
| Gemma 3 4B | 6.4 GB | 4.4 GB | 3.4 GB | 中階 GPU(RTX 3060 12GB、RTX 4060/4070)。 |
| Gemma 3 12B | 20 GB | 12.2 GB | 8.7 GB | 高端消費級或專業級 GPU(RTX 3090/4090、RTX 4080、A6000)。 |
| Gemma 3 27B | 46.4 GB | 29.1 GB | 21 GB | 企業級 GPU(A100、H100)或多 GPU 架構。 |
較小的 Gemma 3 模型(270M 和 1B)可在 CPU 或入門級 GPU 上運行,但要在本機部署 12B 或 27B 版本,需要配備 20-50GB 顯存的高端或企業級硬體。對於想探索 Gemma 3 全部潛力、又不想投入昂貴基礎設施的使用者來說,雲端 GPU 實例是實用的替代方案。
Novita AI 提供隨選即用的高效能 GPU 存取服務,包含 NVIDIA A100、H100、H200、B200 等企業級 GPU,以及 RTX 3090、RTX 4090、RTX 6000 Ada 等高端消費級顯卡。你可以無縫運行大規模模型,依需求擴展資源,且僅需為實際使用的資源付費。
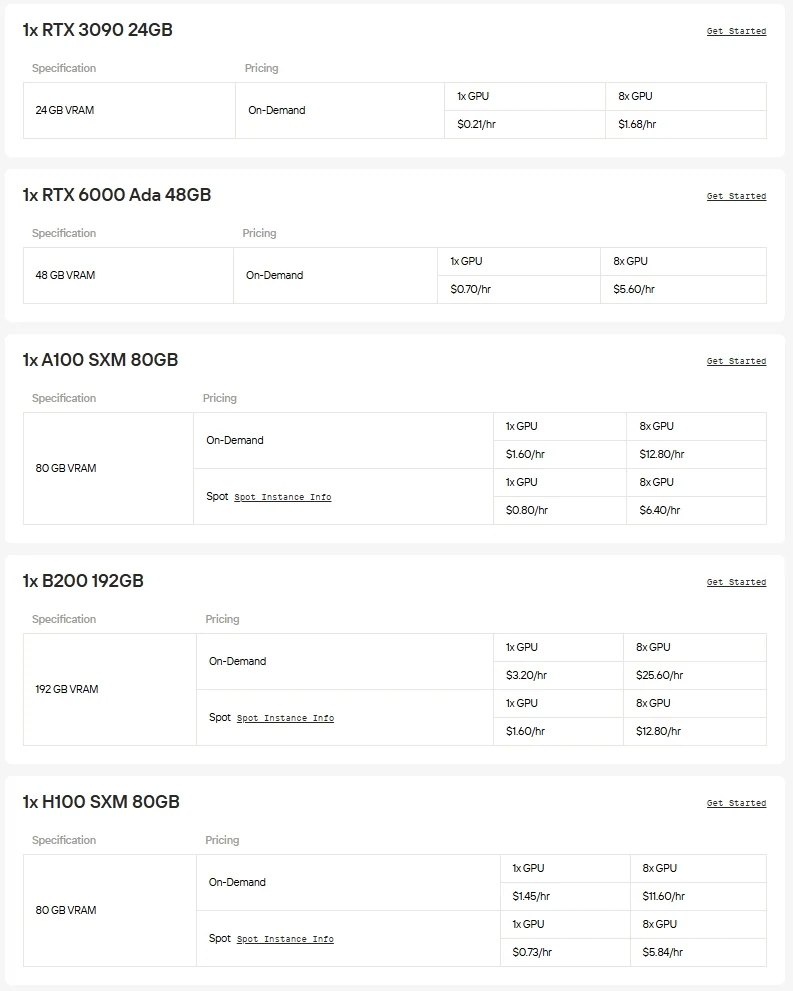
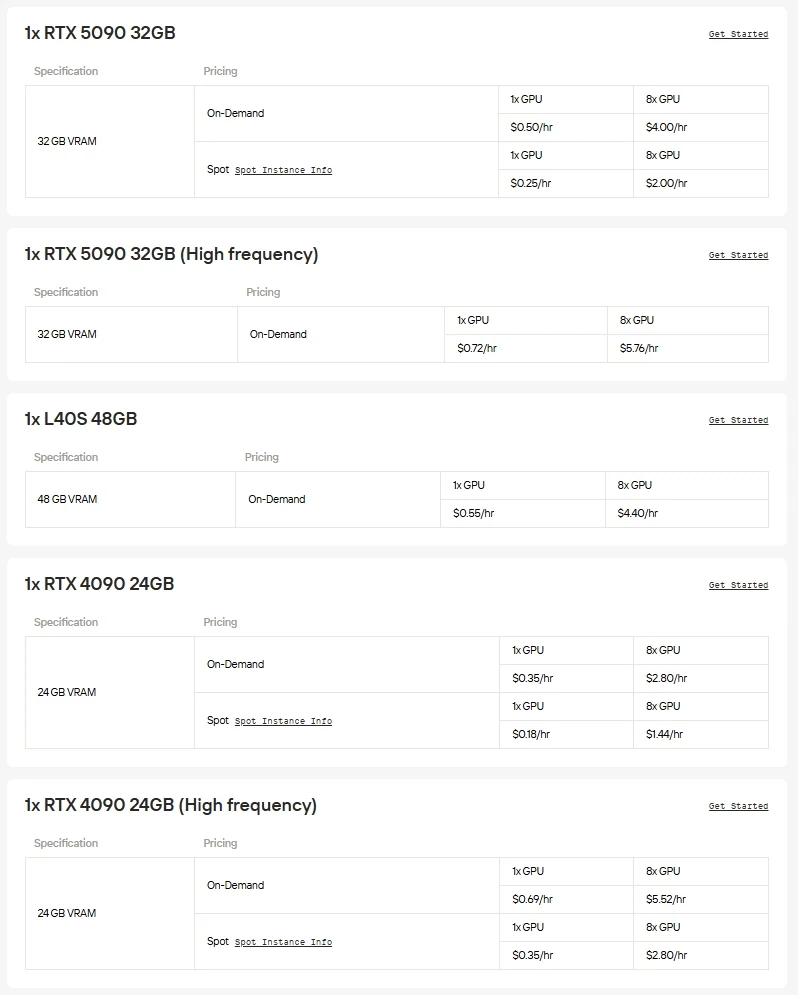
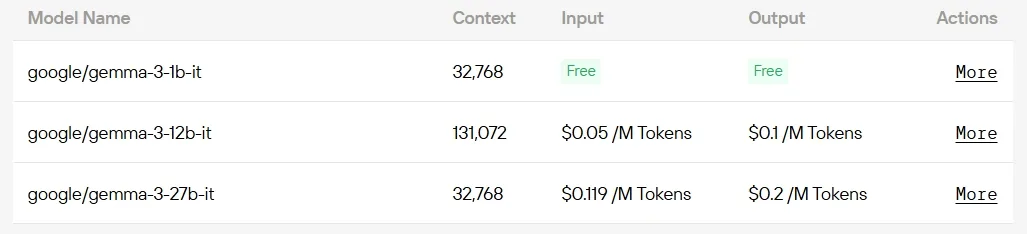
如果你想跳過硬體配置與設定的繁瑣流程,Novita AI 的统一 API 是你解鎖 Gemma 3 最快的方式。無需下載模型或搭建基礎設施,即可即時存取各種模型,讓你能專注於構建、擴展和創造價值。
如何透過 API 存取 Gemma 3 模型
步驟 1:登入並存取模型庫

步驟 2:選擇模型
瀏覽可用的選項,選擇符合你需求的模型。
步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
步驟 4:取得 API 金鑰
要進行 API 身份驗證,我們會提供你新的 API 金鑰。進入「帳戶設定」頁面後,即可按照圖片指示複製 API 金鑰。

步驟 5:安裝 API(以 Gemma 3 12B 為例)
使用對應程式語言的套件管理器安裝 API。安裝完成後,將必要的函式庫匯入你的開發環境,使用你的 API 金鑰初始化 API,即可開始與 Novita AI LLM 互動。以下是以 Python 使用者為例的聊天完成 API 使用範例。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-3-12b-it",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
Gemma 3 模型系列展現了模型規模如何同時影響能力與部署需求。270M 模型展現了效率的極限——超輕量、速度快、易於微調,但推理與知識能力非常有限。1B 模型維持緊湊的尺寸,穩定性略有提升,但在準確度與深度上仍遠遜於更大的模型。4B 模型進入更實用的範圍,在創意與推理任務上的表現更強,但幻覺問題仍舊常見。12B 模型在效能與易用性之間取得了顯著的平衡,無需企業級硬體即可輸出可靠的結果。27B 模型代表了 Gemma 3 的能力巔峰,在複雜推理與程式碼編寫上表現優異,但需要大量的 GPU 資源才能有效運行。
對於開發者來說,如果想以更低的成本存取 Gemma 3,Novita AI 提供了透過 API 無縫部署 Gemma 3 模型的服务,部分模型甚至完全免費。
常見問題
Gemma 3 提供哪些參數量選項?
Gemma 3 提供 270M、1B、4B、12B、27B 五種參數量選項,每個尺寸都針對不同的部署需求與效能水平設計。
哪款 Gemma 3 模型在效能與資源需求間有最佳平衡?
12B 模型通常被認為是「甜點點(sweet spot)」,在提供強勁效能的同時,無需企業級 GPU 即可運行。
Gemma 3 模型能否在筆電、桌機等消費級硬體上運行?
可以。270M 和 1B 模型可在 CPU 和入門級 GPU 上輕鬆運行,4B 和 12B 模型則需要中高階 GPU。27B 模型通常需要 A100 或 H100 等企業級 GPU 才能運行。
Novita AI 是全能雲端平台,助力你實現 AI 抱負。整合 API、無伺服器架構、GPU 實例——都是你需要的低成本工具。告別基礎設施搭建,免費開始使用,讓你的 AI 願景成為現實。



