

Gemma 3 est la toute nouvelle famille de modèles d’IA open source de Google, conçue pour être légère, efficace et largement accessible. Avec des tailles de paramètres allant de 270M à 27B, cette série propose des options flexibles pour tous les usages, des expériences rapides aux applications à l’échelle enterprise.
Cet article explore la famille de modèles Gemma 3 par taille de paramètres, en comparant leurs spécifications, leurs benchmarks de performance, leurs forces et limites, les cas d’usage de chaque modèle, ainsi que la façon d’y accéder localement ou via l’API unifiée de Novita AI.
Modèles Gemma 3 : Fonctionnalités de base et benchmarks

Famille de modèles Gemma 3 : Fonctionnalités de base
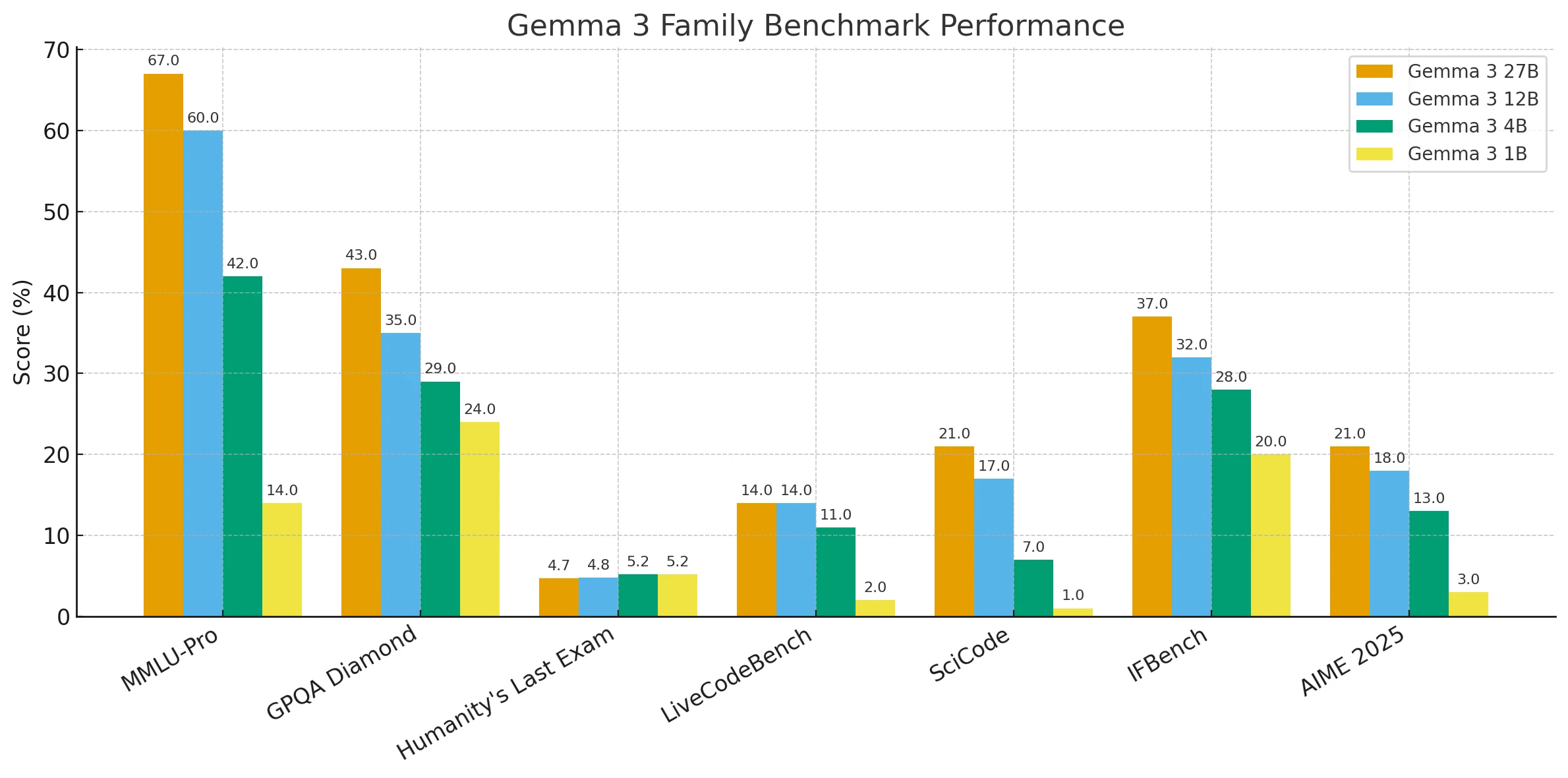
Comparaison des benchmarks des modèles Gemma 3
Dans l’ensemble, les résultats montrent une tendance claire : les tailles de paramètres plus importantes offrent systématiquement de meilleures performances sur les benchmarks de raisonnement, de connaissances et de codage, tandis que les modèles plus petits, bien que plus légers et faciles à déployer, sont en retard sur les tâches complexes.
Analyse détaillée des modèles Gemma 3 par taille de paramètres
Modèle 270M paramètres
| Aspect | Avantages | Inconvénients / Limites |
|---|---|---|
| Performance et cas d’usage | 1) Génère des phrases cohérentes pour sa taille. 2) Fournit une base légère pour le fine-tuning sur des tâches spécifiques. 3) Fonctionne raisonnablement bien pour les sorties structurées (ex. : classification simple, étiquetage, JSON) après ajustement. 4) Peut prendre en charge le décodage spéculatif ou la résumé basique sur mobile. |
1) Beaucoup moins performant que les modèles Gemma plus grands sur les tâches de raisonnement et de connaissances. 2) Manque de connaissances factuelles/mondiales ; sujet aux hallucinations. 3) Son utilité hors de la boîte est minimale et nécessite un fine-tuning. 4) Sa petite taille augmente le risque de surapprentissage. |
| Ressources et vitesse | 1) Extrêmement léger (~400 Mo). 2) Très rapide, fonctionne sur des CPU, des ordinateurs portables bas de gamme et des appareils mobiles. 3) Le fine-tuning est possible sur du matériel grand public. |
1) Inadapté aux charges de travail complexes ou à long contexte. 2) Sensible aux paramètres de quantification et d’optimisation. |
Modèle 1B paramètres
| Aspect | Avantages | Inconvénients / Limites |
|---|---|---|
| Performance et cas d’usage | 1) Léger et fonctionne fluidement. Utile pour le décodage spéculatif afin d’accélérer les modèles plus grands. 2) Adapté au brainstorming rapide ou à la réparation de syntaxe JSON. |
1) Capacité faible à suivre les instructions. 2) Performances globales très limitées. Restreint aux tâches texte uniquement et sujet aux hallucinations. |
| Ressources et vitesse | 1) Extrêmement petit (≈800 Mo). 2) Optimisé pour les configurations mobiles et RAG (génération augmentée par récupération). |
— |
Modèle 4B paramètres
| Aspect | Avantages | Inconvénients / Limites |
|---|---|---|
| Performance et cas d’usage | Offre un équilibre entre taille et performance. Capable de faire du jeu de rôle et des applications légères. Donne des résultats relativement solides pour l’expansion de prompts. |
Sujet aux hallucinations. Peine avec le raisonnement structuré et la production de JSON valide. Plus lent que le modèle 1B et plus gourmand en ressources système. |
| Ressources et vitesse | Rapidité raisonnable pour la génération de code. | Plus gourmand en ressources que le modèle 1B. |
Modèle 12B paramètres
| Aspect | Avantages | Inconvénients / Limites |
|---|---|---|
| Performance et cas d’usage | 1) Amélioration significative par rapport au modèle 4B. 2) Sorties fiables avec moins d’hallucinations. 3) Donne des résultats convaincants pour le codage et l’expansion de prompts. |
1) Trop lent pour la génération de code dans des cas réels sur des systèmes modestes. 2) Les performances chutent lorsque la VRAM est insuffisante (échange GPU-CPU). |
| Ressources et vitesse | 1) Ratio équilibré entre performance et taille du modèle. 2) Option pratique pour les utilisateurs sans GPU. |
— |
Modèle 27B paramètres
| Aspect | Avantages | Inconvénients / Limites |
|---|---|---|
| Performance et cas d’usage | 1) Offre des performances de haut niveau. 2) Excelle dans le codage (ex. : SQL) et les tâches de classification/traduction. 3) Précis pour l’identification de points de repère et s’intègre bien aux outils de développement. |
1) Nécessite du matériel puissant. 2) Extrêmement lent sans GPU haut de gamme. 3) Peine toujours avec la négation, le raisonnement spatial et les tâches multimodales comme l’imagerie historique. |
| Ressources et vitesse | 1) Très réactif sur des GPU de classe enterprise (ex. : H100). 2) Empreinte importante (~17 Go), avec ~28 Go de RAM nécessaires pour une configuration brouillon + principal. |
1) Exigence élevée en VRAM (≥32 Go). |
Modèles Gemma 3 : Correspondance des cas d’usage
La famille Gemma 3 propose des modèles dans une large gamme de tailles de paramètres, chacun optimisé pour des scénarios de déploiement différents.
- Le modèle 270M est conçu pour l’expérimentation ultra-légère, l’éducation et le fine-tuning sur des tâches spécifiques, fonctionnant facilement sur du matériel bas de gamme.
- Le modèle 1B offre plus de stabilité et peut être utilisé pour l’expérimentation mobile, le support de décodage spéculatif et des tâches utilitaires simples.
- Avec 4B paramètres, Gemma 3 devient plus pratique, permettant le jeu de rôle léger, la génération de texte créatif et les expériences RAG (génération augmentée par récupération) en phase initiale.
- Le modèle 12B trouve un équilibre entre performance et exigences en ressources, ce qui en fait un choix solide pour les environnements sans GPU dédié, tout en prenant en charge une génération créative plus cohérente.
- Le modèle 27B est destiné aux applications de classe enterprise, excellant dans le codage avancé, la classification de texte et les tâches de raisonnement haute performance, bien qu’il nécessite du matériel GPU puissant pour fonctionner efficacement.
Modèles Gemma 3 : Exigences de déploiement local
| Paramètres | BF16 (16-bit) | SFP8 (8-bit) | Q4_0 (4-bit) | Matériel recommandé |
|---|---|---|---|---|
| Gemma 3 270M | 400 Mo | 297 Mo | 240 Mo | Fonctionne sur CPU ; tout ordinateur portable/téléphone moderne ; GPU d’entrée de gamme (GTX 1650, RTX 3050). |
| Gemma 3 1B | 1,5 Go | 1,1 Go | 892 Mo | GPU d’entrée de gamme (RTX 3050/3060) ; également possible sur CPU pour des utilisations légères. |
| Gemma 3 4B | 6,4 Go | 4,4 Go | 3,4 Go | GPU de milieu de gamme (RTX 3060 12 Go, RTX 4060/4070). |
| Gemma 3 12B | 20 Go | 12,2 Go | 8,7 Go | GPU grand public ou prosumer haut de gamme (RTX 3090/4090, RTX 4080, A6000). |
| Gemma 3 27B | 46,4 Go | 29,1 Go | 21 Go | GPU de classe enterprise (A100, H100) ou configurations multi-GPU. |
Si les modèles Gemma 3 plus petits (270M et 1B) peuvent fonctionner sur des CPU ou des GPU d’entrée de gamme, le déploiement local des versions 12B ou 27B nécessite du matériel haut de gamme ou de classe enterprise avec 20 à 50 Go de VRAM. Pour ceux qui souhaitent explorer tout le potentiel de Gemma 3 sans investir dans une infrastructure coûteuse, les instances GPU cloud constituent une alternative pratique.
Novita AI propose un accès à la demande à des GPU haute performance tels que les NVIDIA A100, H100, H200 et B200, ainsi qu’à des cartes grand public avancées comme les RTX 3090, RTX 4090 et RTX 6000 Ada. Cela vous permet d’exécuter des modèles à grande échelle de manière transparente, de mettre à l’échelle les ressources selon vos besoins et de ne payer que ce que vous utilisez.
Déployez vos modèles Gemma 3 dès maintenant
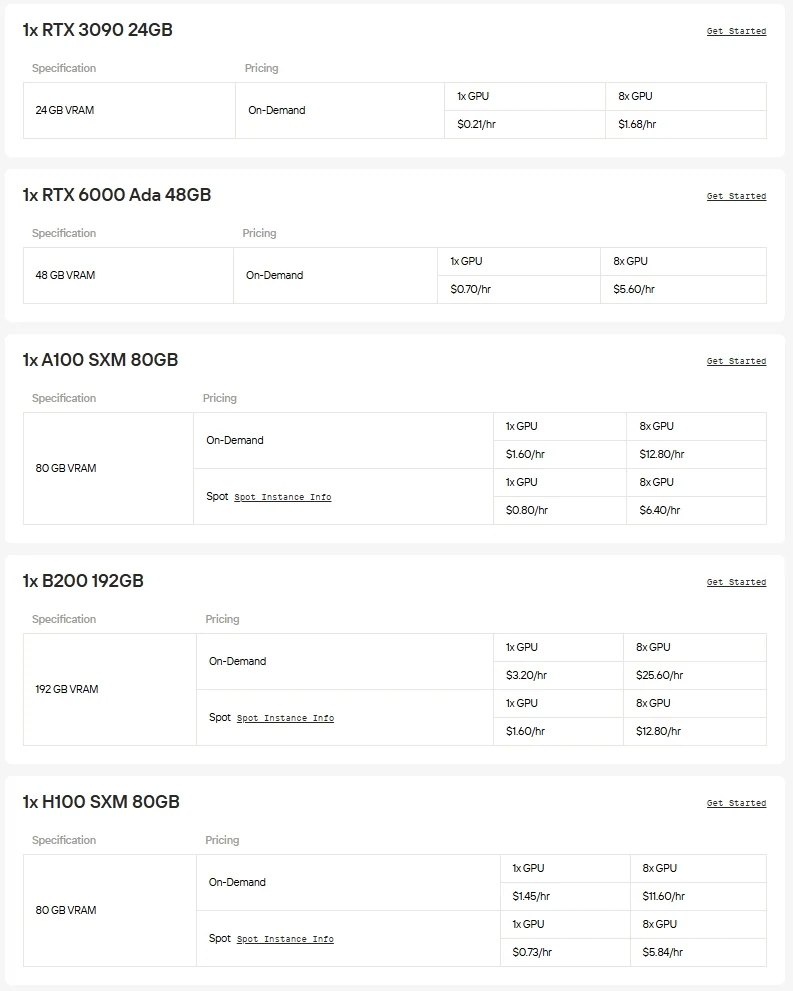
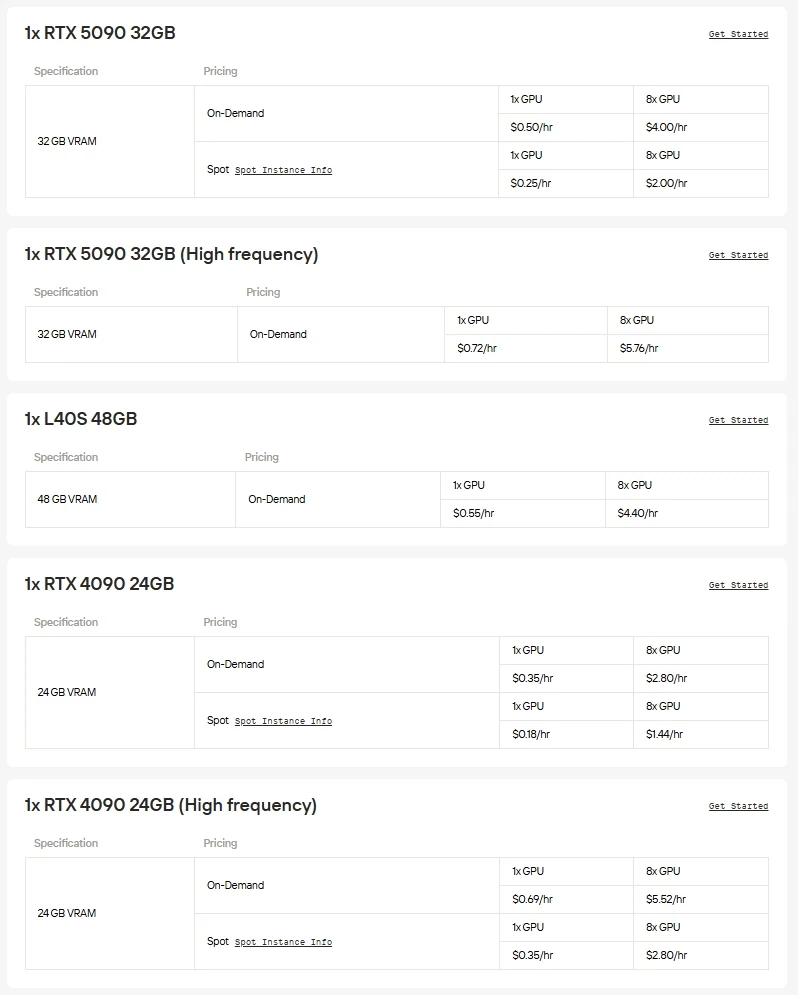
Si vous souhaitez éviter les tracas liés au matériel et à la configuration, l’API unifiée de Novita AI est le moyen le plus rapide de débloquer Gemma 3. Accédez instantanément à différents modèles, sans téléchargement ni infrastructure, pour vous concentrer sur la construction, la mise à l’échelle et la création de valeur.
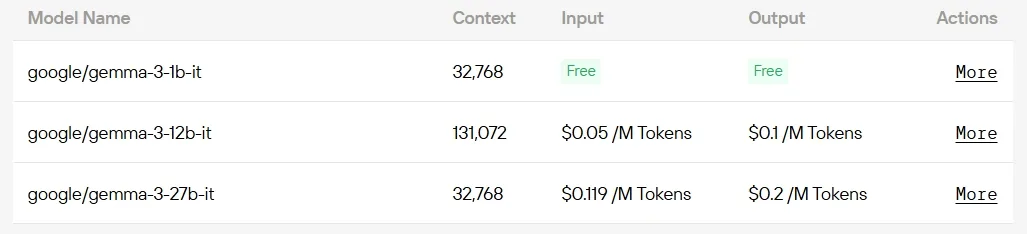
Commencez votre essai gratuit sur Novita AI dès maintenant !
Comment accéder aux modèles Gemma 3 via une API
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En vous rendant sur la page « Paramètres du compte », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API (exemple avec Gemma 3 12B)
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM de Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-3-12b-it",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
La famille de modèles Gemma 3 illustre comment l’échelle des modèles influence à la fois les capacités et les besoins de déploiement. Le modèle 270M montre jusqu’où l’efficacité peut être poussée : ultra-léger, rapide et facile à fine-tuner, mais avec des capacités de raisonnement et de connaissances très limitées. Le modèle 1B reste compact tout en offrant une stabilité légèrement accrue, bien qu’il soit toujours très en retard par rapport aux modèles plus grands en termes de précision et de profondeur. Le modèle 4B entre dans une gamme plus pratique, donnant de meilleurs résultats pour les tâches créatives et de raisonnement, même si les hallucinations restent fréquentes. Le modèle 12B offre un équilibre notable entre performance et accessibilité, produisant des sorties fiables sans nécessiter de matériel de classe enterprise. Le modèle 27B représente le summum des capacités de Gemma 3, excellant dans le raisonnement complexe et le codage, mais nécessitant des ressources GPU importantes pour fonctionner efficacement.
Pour les développeurs souhaitant un accès rentable, Novita AI propose un déploiement transparent des modèles Gemma 3 via API, dont certains sont entièrement gratuits.
Questions fréquemment posées
Quelles tailles de paramètres propose Gemma 3 ?
Gemma 3 est disponible dans les tailles de paramètres 270M, 1B, 4B, 12B et 27B, chacune conçue pour des besoins de déploiement et des niveaux de performance différents.
Quel modèle Gemma 3 offre le meilleur équilibre entre performance et exigences en ressources ?
Le modèle 12B est souvent considéré comme le « juste milieu », offrant de bonnes performances sans nécessiter de GPU de classe enterprise.
Les modèles Gemma 3 peuvent-ils fonctionner sur du matériel grand public comme des ordinateurs portables ou des ordinateurs de bureau ?
Oui. Les modèles 270M et 1B fonctionnent facilement sur des CPU et des GPU d’entrée de gamme, tandis que les modèles 4B et 12B nécessitent des GPU de milieu à haut de gamme. Le modèle 27B nécessite généralement des GPU de classe enterprise comme l’A100 ou le H100.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions en IA. APIs intégrées, serverless, instances GPU : les outils rentables dont vous avez besoin. Éliminez les problèmes d’infrastructure, commencez gratuitement et concrétisez votre vision de l’IA.



