

Gemma 3 ist Googles neueste Familie von Open-Source-KI-Modellen, die leichtgewichtig, effizient und breit zugänglich konzipiert sind. Mit Parameterzahlen von 270M bis 27B bietet die Serie flexible Optionen für alles von schnellen Experimenten bis hin zu unternehmensweiten Anwendungen.
Dieser Artikel untersucht die Gemma 3-Modellfamilie nach Parameteranzahl, vergleicht deren Spezifikationen, Leistungsbenchmarks, Stärken und Einschränkungen, die Anwendungsfälle für jedes Modell sowie die Möglichkeit des lokalen Zugriffs oder über Novita AIs einheitliche API.
Gemma 3-Modelle: Grundlegende Funktionen und Benchmarks

Gemma 3-Modellfamilie: Grundlagen
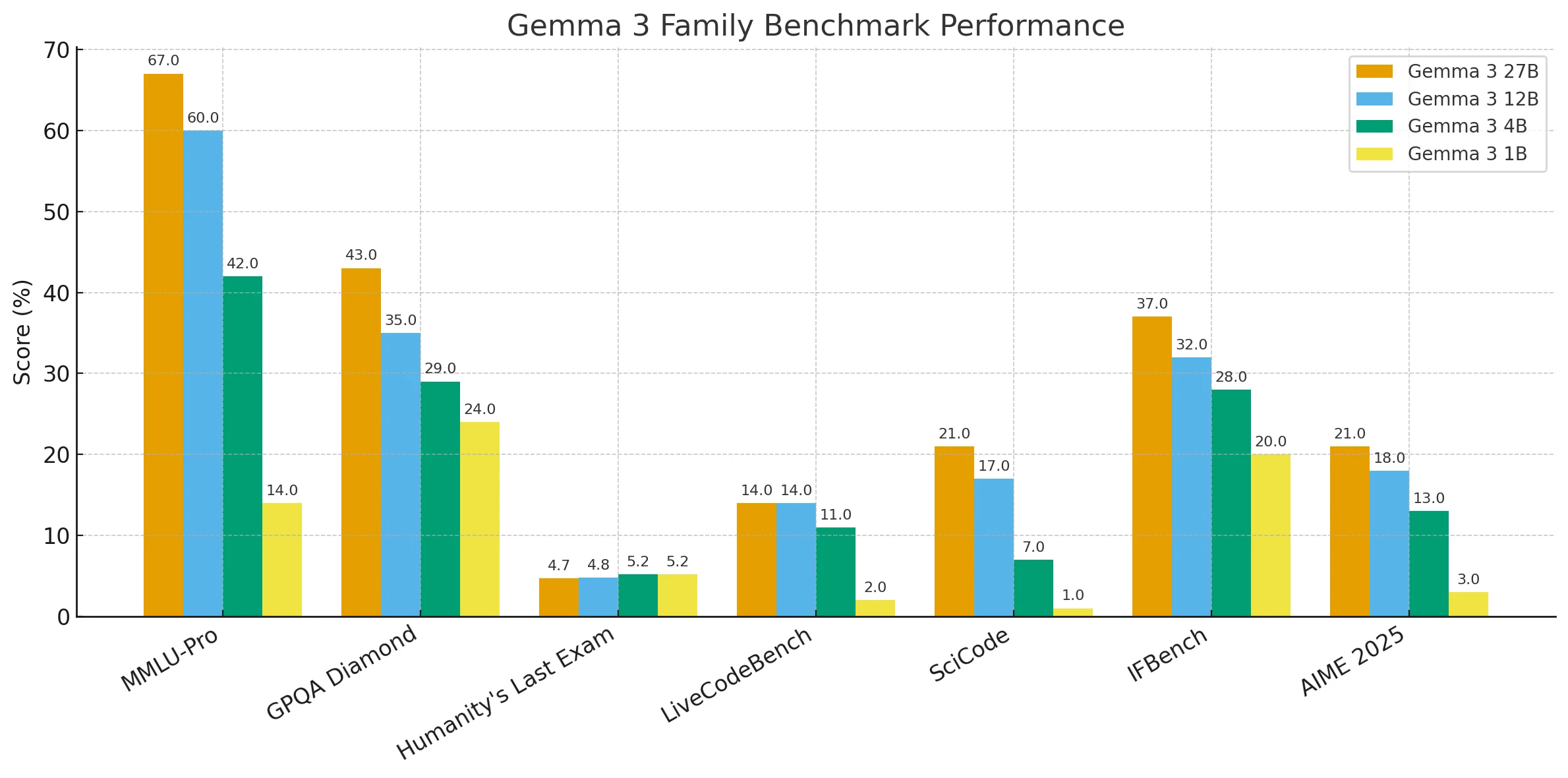
Vergleich der Gemma 3-Modell-Benchmarks
Insgesamt zeigt sich ein klarer Trend: Größere Parameterzahlen liefern durchgängig stärkere Leistungen in Reasoning-, Wissens- und Coding-Benchmarks, während kleinere Modelle, obwohl sie leichtergewichtig und einfacher bereitzustellen sind, bei komplexen Aufgaben zurückbleiben.
Detaillierte Analyse der Gemma 3-Modelle nach Parameteranzahl
270M-Parameter-Modell
| Aspekt | Vorteile | Nachteile / Einschränkungen |
|---|---|---|
| Leistung & Anwendungsfälle | 1) Erzeugt kohärente Sätze für seine Größe. 2) Bietet eine leichtgewichtige Basis für Fine-Tuning bei engen Aufgabenstellungen. 3) Funktioniert nach dem Fine-Tuning gut für strukturierte Ausgaben (z. B. einfache Klassifizierung, Tagging, JSON). 4) Kann spekulative Dekodierung oder einfache Zusammenfassungen auf Mobilgeräten unterstützen. |
1) Deutlich schwächer als größere Gemma-Modelle bei Reasoning- und Wissensaufgaben. 2) Verfügt über kein faktisches/Weltwissen; anfällig für Halluzinationen. 3) Der nutzbare Nutzen ab Werk ist minimal und erfordert Fine-Tuning. 4) Die geringe Größe erhöht das Risiko von Overfitting. |
| Ressourcen & Geschwindigkeit | 1) Extrem leichtgewichtig (~400 MB). 2) Sehr schnell, läuft auf CPUs, Low-End-Laptops und Mobilgeräten. 3) Fine-Tuning ist auf Commodity-Hardware möglich. |
1) Ungeeignet für komplexe oder Langkontext-Workloads. 2) Sensibel gegenüber Quantisierungs- und Optimierungseinstellungen. |
1B-Parameter-Modell
| Aspekt | Vorteile | Nachteile / Einschränkungen |
|---|---|---|
| Leistung & Anwendungsfälle | 1) Leichtgewichtig und läuft reibungslos. Nützlich für spekulative Dekodierung zur Beschleunigung größerer Modelle. 2) Gut für schnelles Brainstorming oder JSON-Syntaxreparatur. |
1) Schwache Anweisungsbefolgungsfähigkeit. 2) Sehr eingeschränkte Gesamtleistung. Beschränkt auf rein textbasierte Aufgaben und anfällig für Halluzinationen. |
| Ressourcen & Geschwindigkeit | 1) Extrem klein (≈800 MB). 2) Optimiert für Mobilgeräte und RAG-Setups. |
— |
4B-Parameter-Modell
| Aspekt | Vorteile | Nachteile / Einschränkungen |
|---|---|---|
| Leistung & Anwendungsfälle | Bietet eine Balance aus Größe und Leistung. Ist zu Rollenspielen und leichtgewichtigen Anwendungen fähig. Liefert relativ starke Ergebnisse bei der Prompt-Erweiterung. |
Anfällig für Halluzinationen. Hat Schwierigkeiten mit strukturiertem Reasoning und gültigen JSON-Ausgaben. Langsamer als das 1B-Modell und ressourcenintensiver. |
| Ressourcen & Geschwindigkeit | Ziemlich schnell für Code-Generierung. | Ressourcenintensiver als das 1B-Modell. |
12B-Parameter-Modell
| Aspekt | Vorteile | Nachteile / Einschränkungen |
|---|---|---|
| Leistung & Anwendungsfälle | 1) Deutliche Verbesserung gegenüber dem 4B-Modell. 2) Zuverlässige Ausgaben mit reduzierten Halluzinationen. 3) Liefert ansprechende Ergebnisse bei Code und Prompt-Erweiterung. |
1) Zu langsam für Code-Generierung in realen Anwendungsfällen auf bescheidenen Systemen. 2) Leistung sinkt, wenn der VRAM nicht ausreicht (GPU-CPU-Auslagerung). |
| Ressourcen & Geschwindigkeit | 1) Ausgewogenes Verhältnis von Leistung zu Modellgröße. 2) Praktische Option für Nutzer ohne GPUs. |
— |
27B-Parameter-Modell
| Aspekt | Vorteile | Nachteile / Einschränkungen |
|---|---|---|
| Leistung & Anwendungsfälle | 1) Liefert erstklassige Leistung. 2) Zeichnet sich bei Coding (z. B. SQL) sowie Klassifizierungs- und Übersetzungsaufgaben aus. 3) Ist genau bei der Identifizierung von Wahrzeichen und integriert sich gut in Entwicklertools. |
1) Erfordert leistungsstarke Hardware. 2) Extrem langsam ohne High-End-GPUs. 3) Hat immer noch Schwierigkeiten mit Negation, räumlichem Reasoning und multimodalen Aufgaben wie historischen Bildern. |
| Ressourcen & Geschwindigkeit | 1) Sehr reaktionsschnell auf Enterprise-GPUs (z. B. H100). 2) Großer Speicherbedarf (~17 GB), ca. 28 GB RAM werden im Draft+Main-Setup benötigt. |
1) Hoher VRAM-Bedarf (≥32 GB). |
Gemma 3-Modelle: Zuordnungen von Anwendungsfällen
Die Gemma 3-Familie bietet Modelle in einem weiten Bereich von Parameterzahlen, die jeweils für unterschiedliche Bereitstellungsszenarien optimiert sind.
- Das 270M-Modell ist für ultraleichte Experimente, Bildung und Fine-Tuning bei engen Aufgaben konzipiert und läuft problemlos auf Low-End-Hardware.
- Das 1B-Modell bietet mehr Stabilität und kann für mobile Experimente, Unterstützung bei spekulativer Dekodierung und einfache Hilfsaufgaben verwendet werden.
- Bei 4B Parametern wird Gemma 3 praktisch nützlich und ermöglicht leichtgewichtige Rollenspiele, kreative Textgenerierung und erste RAG-Experimente (Retrieval-Augmented Generation, abrufgestützte Generierung).
- Das 12B-Modell bietet eine ausgewogene Balance zwischen Leistung und Ressourcenanforderungen, was es zu einer soliden Wahl für Umgebungen ohne dedizierte GPU macht, und unterstützt zudem konsistentere kreative Generierung.
- Das 27B-Modell ist für unternehmensweite Anwendungen konzipiert, zeichnet sich bei fortgeschrittenem Coding, Textklassifizierung und leistungsstarken Reasoning-Aufgaben aus, erfordert aber leistungsstarke GPU-Hardware, um effektiv zu laufen.
Lokale Bereitstellungsanforderungen für Gemma 3-Modelle
| Parameter | BF16 (16-bit) | SFP8 (8-bit) | Q4_0 (4-bit) | Empfohlene Hardware |
|---|---|---|---|---|
| Gemma 3 270M | 400 MB | 297 MB | 240 MB | Läuft auf CPU; jeder moderne Laptop/Handy; Einstiegs-GPUs (GTX 1650, RTX 3050). |
| Gemma 3 1B | 1,5 GB | 1,1 GB | 892 MB | Einstiegs-GPUs (RTX 3050/3060); auch für leichte Nutzung auf CPU möglich. |
| Gemma 3 4B | 6,4 GB | 4,4 GB | 3,4 GB | Mittelklasse-GPUs (RTX 3060 12GB, RTX 4060/4070). |
| Gemma 3 12B | 20 GB | 12,2 GB | 8,7 GB | High-End-Consumer- oder Prosumer-GPUs (RTX 3090/4090, RTX 4080, A6000). |
| Gemma 3 27B | 46,4 GB | 29,1 GB | 21 GB | Enterprise-GPUs (A100, H100) oder Multi-GPU-Setups. |
Während kleinere Gemma 3-Modelle (270M und 1B) auf CPUs oder Einstiegs-GPUs laufen können, erfordert die lokale Bereitstellung der 12B- oder 27B-Versionen High-End- oder Enterprise-Hardware mit 20–50 GB VRAM. Für alle, die das volle Potenzial von Gemma 3 ohne Investitionen in kostspielige Infrastruktur nutzen möchten, sind cloudbasierte GPU-Instanzen eine praktische Alternative.
Novita AI bietet On-Demand-Zugriff auf leistungsstarke GPUs wie die NVIDIA A100, H100, H200 und B200 sowie fortschrittliche Consumer-Grafikkarten wie die RTX 3090, RTX 4090 und RTX 6000 Ada. Damit können Sie großskalige Modelle nahtlos ausführen, Ressourcen nach Bedarf skalieren und nur bezahlen, was Sie nutzen.
Bereitstellen Sie Ihre Gemma 3-Modelle jetzt
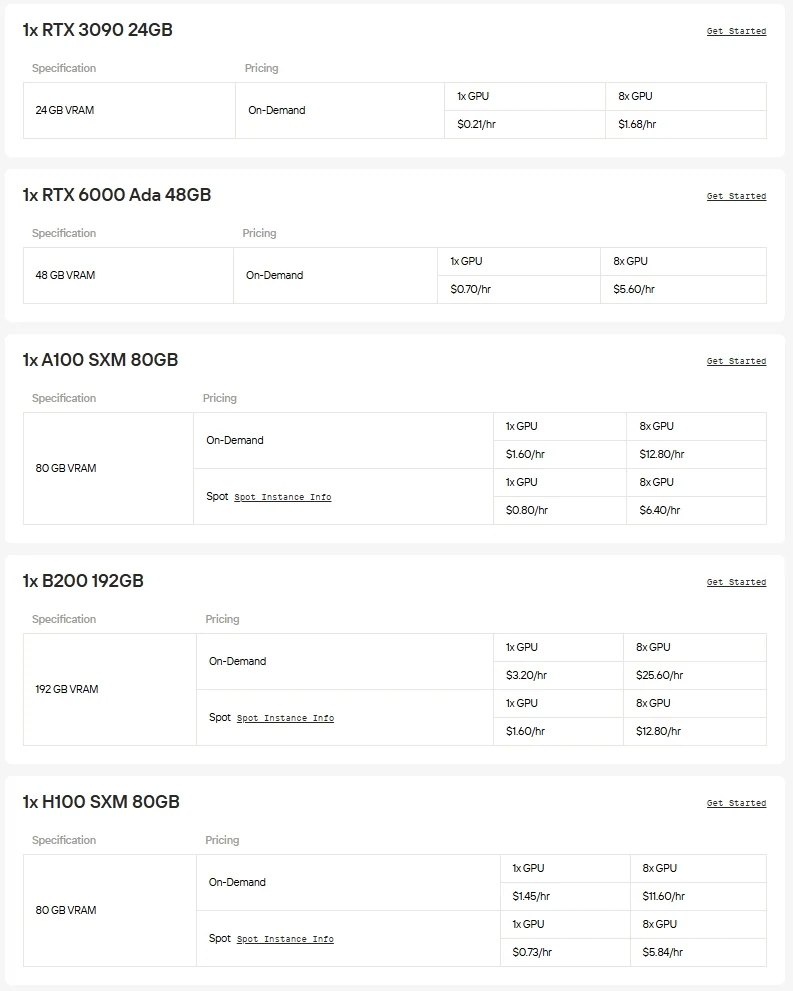
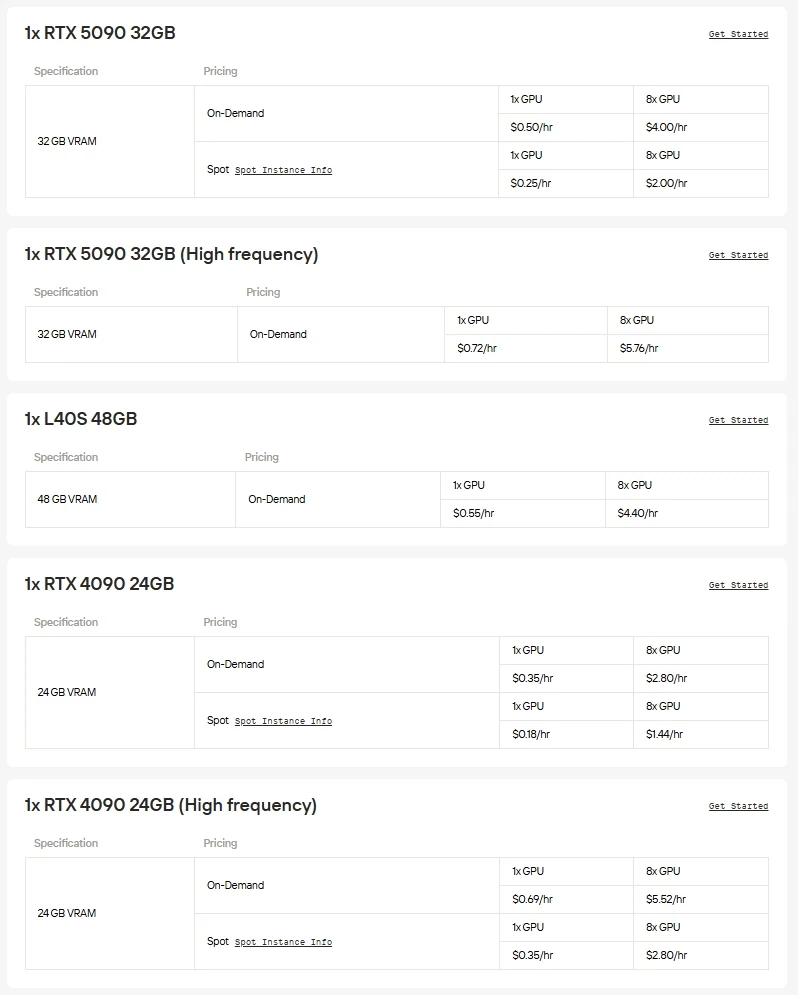
Wenn Sie den Aufwand mit Hardware und Einrichtung vermeiden möchten, ist Novita AIs einheitliche API der schnellste Weg, um Gemma 3 zu nutzen. Erhalten Sie sofortigen Zugriff auf verschiedene Modelle – ohne Downloads oder Infrastruktur, sodass Sie sich auf die Entwicklung, Skalierung und Bereitstellung von Mehrwert konzentrieren können.
Starten Sie jetzt Ihre kostenlose Testversion auf Novita AI!
So greifen Sie über eine API auf Gemma 3-Modelle zu
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Kontoeinstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

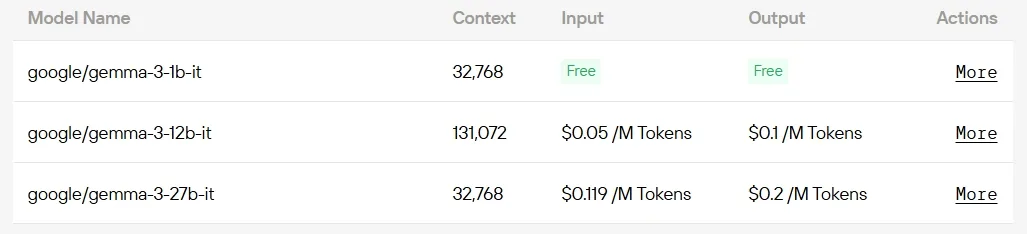
Schritt 5: Installieren Sie die API (Gemma 3 12B als Beispiel)
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AIs LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-3-12b-it",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
Die Gemma 3-Modellfamilie zeigt, wie der Maßstab von Modellen sowohl Fähigkeiten als auch Bereitstellungsanforderungen beeinflusst. Das 270M-Modell zeigt, wie weit Effizienz optimiert werden kann – ultraleichtgewichtig, schnell und einfach zu fine-tunen, aber mit sehr eingeschränktem Reasoning und Weltwissen. Das 1B-Modell bleibt kompakt und bietet etwas mehr Stabilität, liegt aber bei Genauigkeit und Tiefe immer noch weit hinter größeren Modellen zurück. Das 4B-Modell erreicht einen praktischeren Bereich, liefert stärkere Ergebnisse für kreative und Reasoning-Aufgaben, Halluzinationen sind aber immer noch häufig. Das 12B-Modell bietet eine bemerkenswerte Balance aus Leistung und Zugänglichkeit, liefert zuverlässige Ausgaben, ohne Enterprise-Hardware zu erfordern. Das 27B-Modell stellt die Spitze der Leistungsfähigkeit von Gemma 3 dar, zeichnet sich bei komplexem Reasoning und Coding aus, erfordert aber erhebliche GPU-Ressourcen, um effektiv zu laufen.
Für Entwickler, die kostengünstigen Zugriff suchen, bietet Novita AI eine nahtlose Bereitstellung von Gemma 3-Modellen über API – teilweise sogar vollständig kostenlos.
Häufig gestellte Fragen
Welche Parameterzahlen bietet Gemma 3? Gemma 3 ist in den Parameterzahlen 270M, 1B, 4B, 12B und 27B verfügbar, die jeweils für unterschiedliche Bereitstellungsanforderungen und Leistungsniveaus konzipiert sind.
Welches Gemma 3-Modell bietet die beste Balance zwischen Leistung und Ressourcenanforderungen? Das 12B-Modell wird oft als „Sweet Spot“ bezeichnet, da es starke Leistung bietet, ohne Enterprise-GPUs zu erfordern.
Können Gemma 3-Modelle auf Consumer-Hardware wie Laptops oder Desktops laufen? Ja. Die 270M- und 1B-Modelle laufen problemlos auf CPUs und Einstiegs-GPUs, während die 4B- und 12B-Modelle Mittelklasse- bis High-End-GPUs erfordern. Das 27B-Modell benötigt in der Regel Enterprise-GPUs wie die A100 oder H100.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen ermöglicht. Integrierte APIs, Serverless, GPU-Instanzen – die kostengünstigen Tools, die Sie brauchen. Eliminieren Sie Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



