

O Gemma 3 é a família mais recente de modelos de IA de código aberto do Google, projetada para ser leve, eficiente e amplamente acessível. Com tamanhos de parâmetros variando de 270M a 27B, a série oferece opções flexíveis para tudo, desde experimentos rápidos até aplicações em escala empresarial.
Este artigo explora a família de modelos Gemma 3 por tamanho de parâmetros, comparando suas especificações, benchmarks de desempenho, pontos fortes e limitações, casos de uso para cada modelo, além de como acessá-los localmente ou via API unificada da Novita AI.
Modelos Gemma 3: Recursos Básicos e Benchmarks

Família de Modelos Gemma 3: Básicos
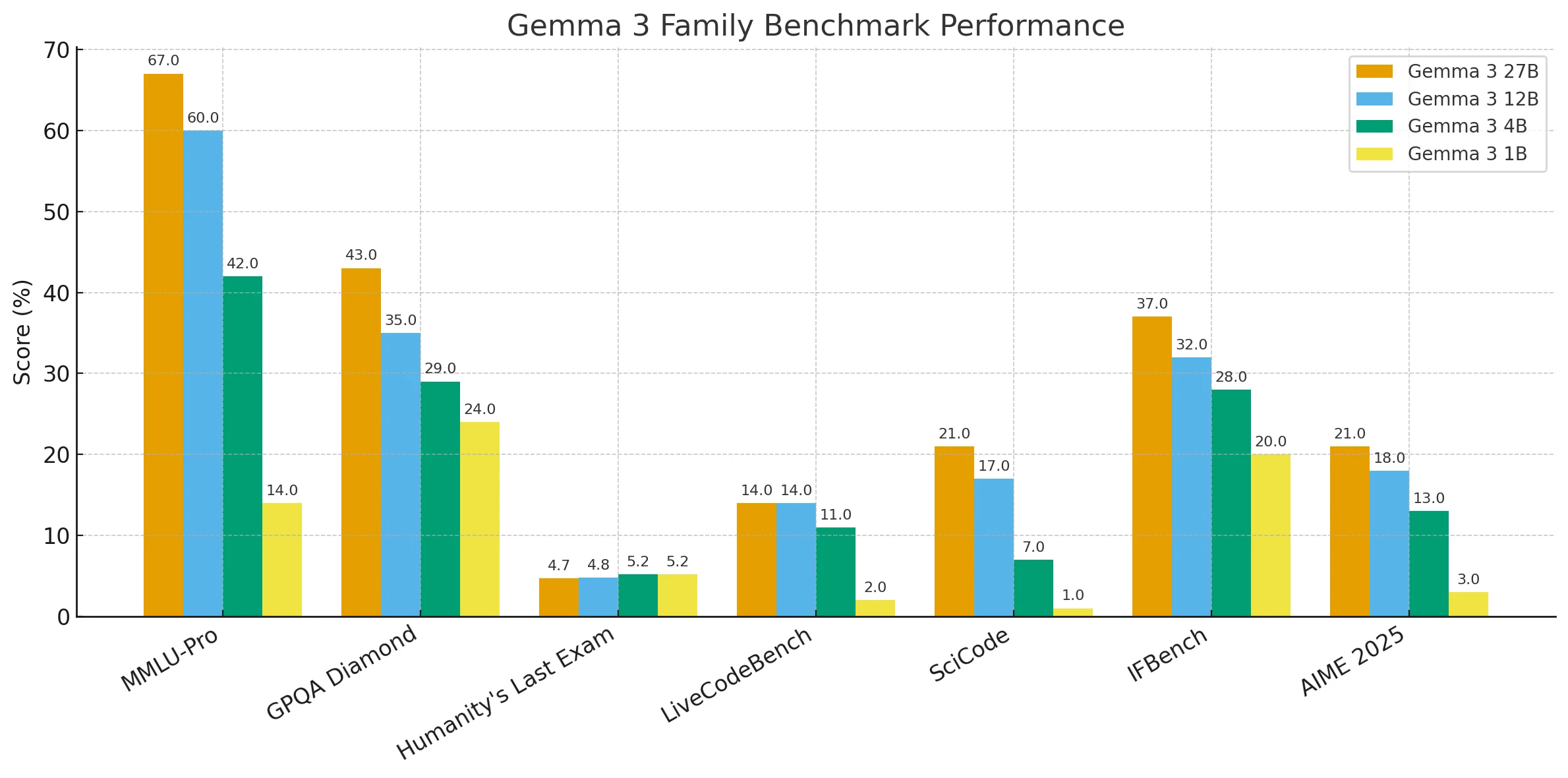
Comparação de Benchmarks dos Modelos Gemma 3
No geral, os resultados mostram uma tendência clara: tamanhos de parâmetros maiores entregam consistentemente desempenho mais forte em benchmarks de raciocínio, conhecimento e codificação, enquanto modelos menores, embora mais leves e fáceis de implantar, ficam atrás em tarefas complexas.
Análise Detalhada dos Modelos Gemma 3 por Tamanho de Parâmetros
Modelo de 270M de Parâmetros
| Aspecto | Prós | Contras / Limitações |
|---|---|---|
| Desempenho e Casos de Uso | 1) Gera frases coerentes para o seu tamanho. 2) Fornece uma base leve para ajuste fino em tarefas específicas. 3) Funciona razoavelmente bem para saídas estruturadas (ex: classificação simples, marcação, JSON) após o ajuste. 4) Pode suportar decodificação especulativa ou sumarização básica em dispositivos móveis. |
1) Muito mais fraco que os modelos Gemma maiores em tarefas de raciocínio e conhecimento. 2) Não possui conhecimento factual/mundial; propenso a alucinações. 3) A utilidade pronta para uso é mínima e requer ajuste fino. 4) O tamanho pequeno aumenta o risco de overfitting. |
| Recursos e Velocidade | 1) Extremamente leve (~400MB). 2) Muito rápido, executa em CPUs, laptops de baixo custo e dispositivos móveis. 3) Ajuste fino viável em hardware comum. |
1) Inadequado para cargas de trabalho complexas ou de longo contexto. 2) Sensível a configurações de quantização e otimização. |
Modelo de 1B de Parâmetros
| Aspecto | Prós | Contras / Limitações |
|---|---|---|
| Desempenho e Casos de Uso | 1) Leve e executa sem problemas. Útil para decodificação especulativa para acelerar modelos maiores. 2) Bom para brainstorming rápido ou reparo de sintaxe JSON. |
1) Habilidade fraca de seguir instruções. 2) Desempenho geral muito limitado. Restrito a tarefas apenas de texto e propenso a alucinações. |
| Recursos e Velocidade | 1) Extremamente pequeno (≈800MB). 2) Otimizado para configurações móveis e RAG. |
— |
Modelo de 4B de Parâmetros
| Aspecto | Prós | Contras / Limitações |
|---|---|---|
| Desempenho e Casos de Uso | Oferece um equilíbrio entre tamanho e desempenho. Capaz de interpretação de papéis (role-play) e aplicações leves. Fornece resultados relativamente fortes em expansão de prompts. |
Suscetível a alucinações. Luta com raciocínio estruturado e saída JSON válida. Mais lento que o modelo de 1B e mais pesado em recursos do sistema. |
| Recursos e Velocidade | Razoavelmente rápido para geração de código. | Mais intensivo em recursos que o modelo de 1B. |
Modelo de 12B de Parâmetros
| Aspecto | Prós | Contras / Limitações |
|---|---|---|
| Desempenho e Casos de Uso | 1) Melhoria significativa em relação ao modelo de 4B. 2) Saídas confiáveis com alucinação reduzida. 3) Produz resultados atraentes em codificação e expansão de prompts. |
1) Muito lento para geração de código em cenários reais em sistemas modestos. 2) O desempenho diminui quando a VRAM é insuficiente (troca entre GPU e CPU). |
| Recursos e Velocidade | 1) Proporção equilibrada entre desempenho e tamanho do modelo. 2) Opção prática para usuários sem GPUs. |
— |
Modelo de 27B de Parâmetros
| Aspecto | Prós | Contras / Limitações |
|---|---|---|
| Desempenho e Casos de Uso | 1) Entrega desempenho de primeira linha. 2) Se destaca em codificação (ex: SQL) e tarefas de classificação/tradução. 3) Preciso na identificação de pontos de referência e se integra bem com ferramentas de desenvolvedor. |
1) Requer hardware potente. 2) Extremamente lento sem GPUs de alta gama. 3) Ainda tem dificuldades com negação, raciocínio espacial e tarefas multimodais como imagens históricas. |
| Recursos e Velocidade | 1) Altamente responsivo em GPUs de nível empresarial (ex: H100). 2) Grande ocupação de armazenamento (~17GB), com ~28GB de RAM necessários na configuração de rascunho + principal. |
1) Requisito alto de VRAM (≥32GB). |
Modelos Gemma 3: Mapeamento de Casos de Uso
A família Gemma 3 oferece modelos em uma ampla gama de tamanhos de parâmetros, cada um otimizado para diferentes cenários de implantação.
- O modelo de 270M é projetado para experimentação ultra-leve, educação e ajuste fino em tarefas específicas, executando facilmente em hardware de baixo custo.
- O modelo de 1B oferece mais estabilidade e pode ser usado para experimentação em dispositivos móveis, suporte a decodificação especulativa e tarefas utilitárias simples.
- Com 4B de parâmetros, o Gemma 3 se torna mais praticamente útil, permitindo interpretação de papéis leve, geração de texto criativo e experimentos iniciais de RAG (Geração Aumentada por Recuperação).
- O modelo de 12B equilibra desempenho e demandas de recursos, sendo uma escolha sólida para ambientes sem GPU dedicada, além de suportar geração criativa mais consistente.
- O modelo de 27B é voltado para aplicações de nível empresarial, se destacando em codificação avançada, classificação de texto e tarefas de raciocínio de alto desempenho, embora exija hardware de GPU potente para executar de forma eficaz.
Modelos Gemma 3: Requisitos de Implantação Local
| Parâmetros | BF16 (16-bit) | SFP8 (8-bit) | Q4_0 (4-bit) | Hardware Recomendado |
|---|---|---|---|---|
| Gemma 3 270M | 400 MB | 297 MB | 240 MB | Executa em CPU; qualquer laptop/smartphone moderno; GPUs de entrada (GTX 1650, RTX 3050). |
| Gemma 3 1B | 1,5 GB | 1,1 GB | 892 MB | GPUs de entrada (RTX 3050/3060); também viável em CPU para uso leve. |
| Gemma 3 4B | 6,4 GB | 4,4 GB | 3,4 GB | GPUs de gama média (RTX 3060 12GB, RTX 4060/4070). |
| Gemma 3 12B | 20 GB | 12,2 GB | 8,7 GB | GPUs de alto desempenho para consumidor ou prosumer (RTX 3090/4090, RTX 4080, A6000). |
| Gemma 3 27B | 46,4 GB | 29,1 GB | 21 GB | GPUs empresariais (A100, H100) ou configurações multi-GPU. |
Enquanto os modelos menores do Gemma 3 (270M e 1B) podem executar em CPUs ou GPUs de entrada, implantar as versões de 12B ou 27B localmente requer hardware de alto desempenho ou nível empresarial com 20 a 50GB de VRAM. Para quem quer explorar todo o potencial do Gemma 3 sem investir em infraestrutura cara, instâncias de GPU baseadas em nuvem são uma alternativa prática.
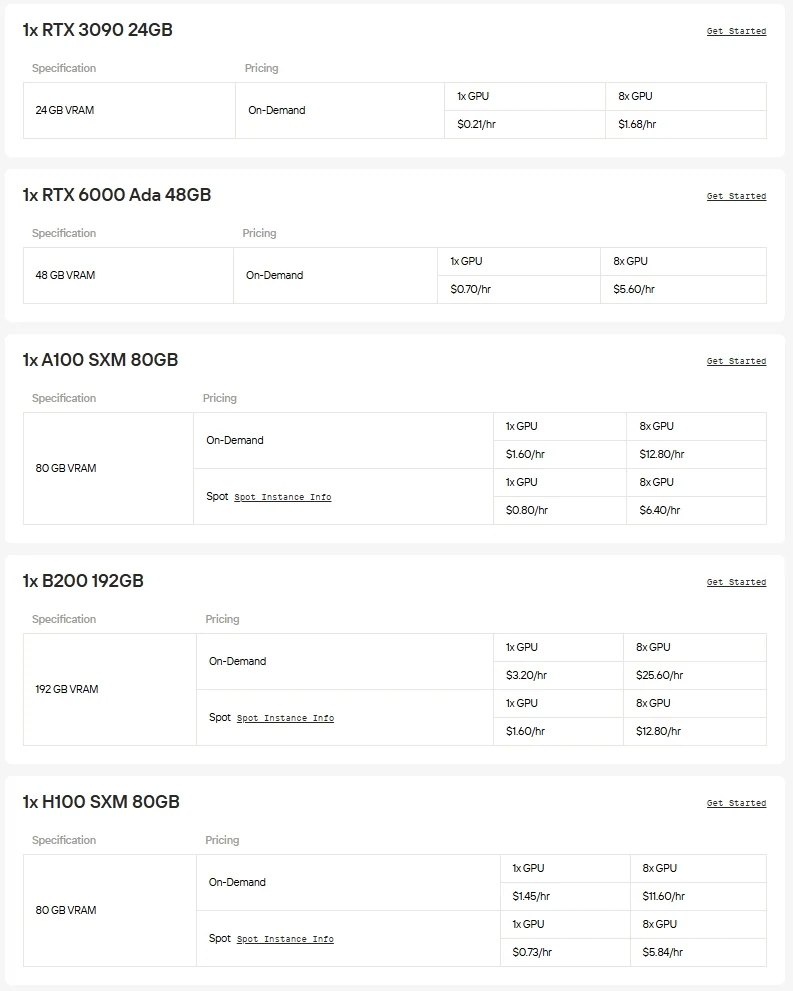
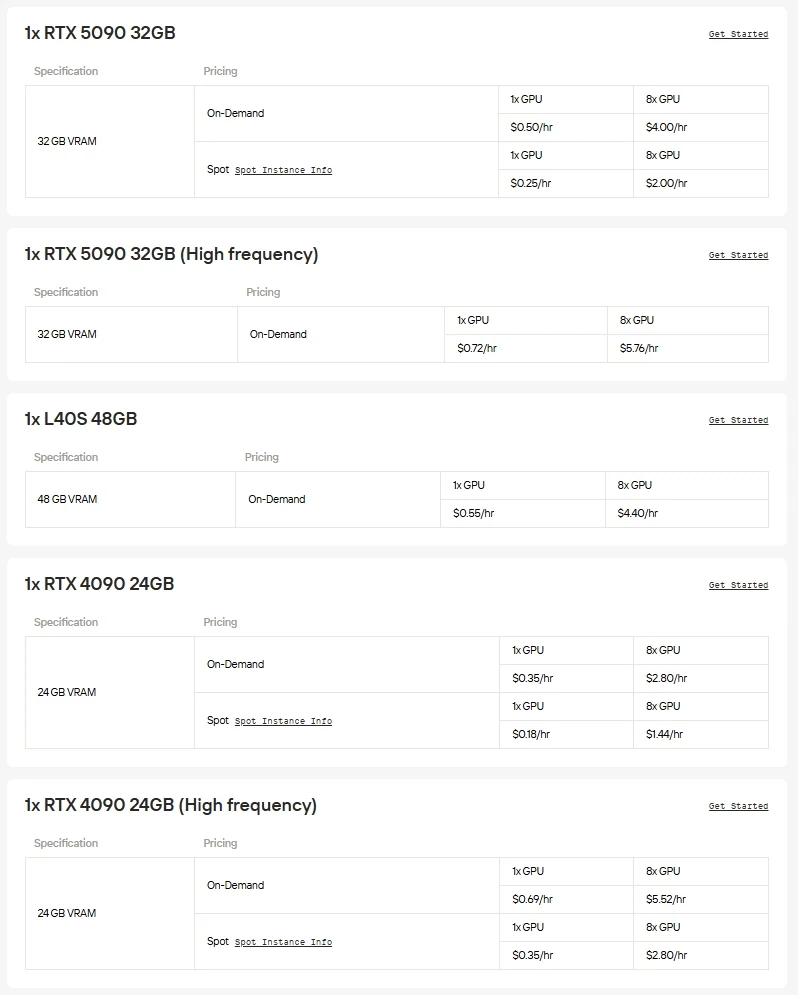
A Novita AI oferece acesso sob demanda a GPUs de alto desempenho como as NVIDIA A100, H100, H200 e B200, além de placas de consumidor avançadas como as RTX 3090, RTX 4090 e RTX 6000 Ada. Isso permite executar modelos em grande escala sem interrupções, escalar recursos conforme necessário e pagar apenas pelo que você usa.
Implante Seus Modelos Gemma 3 Agora
Se você quer evitar o trabalho com hardware e configuração, a API unificada da Novita AI é a forma mais rápida de liberar todo o potencial do Gemma 3. Tenha acesso instantâneo a vários modelos — sem downloads ou infraestrutura, para que você possa se concentrar em construir, escalar e entregar valor.
Comece Seu Teste Gratuito na Novita AI Agora!
Como Acessar Modelos Gemma 3 via API
Passo 1: Faça Login e Acesse a Biblioteca de Modelos

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página “Configurações da Conta”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API (Usando o Gemma 3 12B como Exemplo)
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="google/gemma-3-12b-it",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
A família de modelos Gemma 3 ilustra como a escala do modelo molda tanto a capacidade quanto as necessidades de implantação. O modelo de 270M mostra até onde a eficiência pode ser levada — ultra-leve, rápido e fácil de ajustar, mas com raciocínio e conhecimento muito limitados. O modelo de 1B permanece compacto enquanto oferece um pouco mais de estabilidade, embora ainda esteja muito atrás de modelos maiores em precisão e profundidade. O modelo de 4B entra em uma faixa mais prática, entregando resultados mais fortes para tarefas criativas e de raciocínio, embora alucinações ainda sejam comuns. O modelo de 12B oferece um equilíbrio notável entre desempenho e acessibilidade, produzindo saídas confiáveis sem exigir hardware de nível empresarial. O modelo de 27B representa o pico de capacidade do Gemma 3, se destacando em raciocínio complexo e codificação, mas exigindo recursos significativos de GPU para executar de forma eficaz.
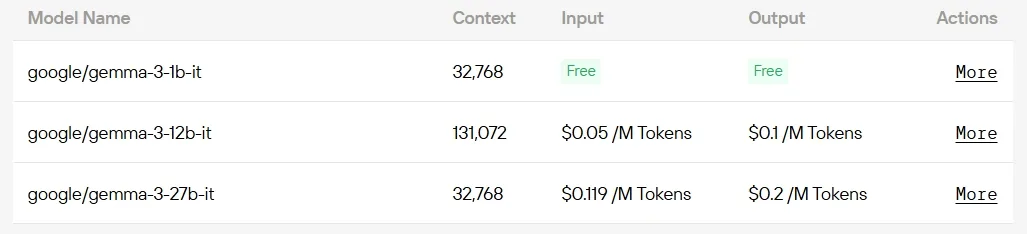
Para desenvolvedores que buscam acesso econômico, a Novita AI oferece implantação perfeita de modelos Gemma 3 via API — com alguns disponíveis totalmente gratuitos.
Perguntas Frequentes
Quais tamanhos de parâmetros o Gemma 3 oferece?
O Gemma 3 está disponível nos tamanhos de parâmetros 270M, 1B, 4B, 12B e 27B, cada um projetado para diferentes necessidades de implantação e níveis de desempenho.
Qual modelo Gemma 3 oferece o melhor equilíbrio entre desempenho e requisitos de recursos?
O modelo de 12B é frequentemente considerado o “ponto ideal”, oferecendo desempenho forte sem exigir GPUs de nível empresarial.
Os modelos Gemma 3 podem executar em hardware de consumidor como laptops ou desktops?
Sim. Os modelos de 270M e 1B executam facilmente em CPUs e GPUs de entrada, enquanto os modelos de 4B e 12B exigem GPUs de gama média a alta. O modelo de 27B geralmente requer GPUs empresariais como a A100 ou H100.
A Novita AI é a plataforma de nuvem tudo-em-um que potencializa suas ambições de IA. APIs integradas, serverless, Instâncias de GPU — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA uma realidade.



