

Если вы хотите полностью раскрыть потенциал DeepSeek R1 0528 в конкретных областях, тонкая настройка — наиболее эффективный метод. Хотя модель уже превосходно справляется с продвинутыми рассуждениями, математикой и программированием, тонкая настройка позволяет специализировать её в таких областях, как генерация естественного языка, экспертиза в предметной области или мультимодальные задачи. В этой статье вы найдёте конкретное руководство по тонкой настройке DeepSeek R1 0528.
В чём DeepSeek R1 0528 превосходит остальных?
Карточка модели
- Размер модели: 685B параметров
- Открытый исходный код: Да
- Архитектура: Mixture of Experts (MoE)
- Поддержка языков: Многоязычная (превосходно работает с английским и китайским)
- Мультимодальные возможности: Да (текст-в-текст)
- Обучение: Последнее обновление DeepSeek R1 использует увеличенные вычислительные ресурсы и алгоритмические пост-тренировочные оптимизации. Это значительно улучшило глубину рассуждений и способности к выводу.
Производительность модели
| Бенчмарк | DeepSeek R1 0528 | Выше, чем |
|---|---|---|
| AIME 2024 | 91.4 | Все (кроме OpenAI-o3, почти одинаково) |
| AIME 2025 | 87.5 | Все |
| GPQA Diamond | 81.0 | Qwen3-235B, DeepSeek-R1 |
| LiveCodeBench | 73.3 | Все |
| Aider | 71.6 | Qwen3-235B, DeepSeek-R1 |
| Humanity’s Last Exam | 17.7 | Qwen3-235B, DeepSeek-R1 |
- Превосходно справляется с продвинутыми математическими рассуждениями и решением задач
- Демонстрирует мощные способности к программированию и генерации кода
- Эффективно обрабатывает сложные логические и аналитические задачи
Поскольку DeepSeek R1 0528 уже силён в математике, программировании и логике, ваше наилучшее направление тонкой настройки — нацелиться на области, где он менее доминирует, такие как генерация естественного языка, предметная экспертиза, мультимодальные задачи или безопасность и согласование. Это сделает модель более универсальной и полезной для более широкого круга приложений.
Когда стоит выбрать тонкую настройку?
Тонкая настройка — это процесс адаптации предварительно обученной большой языковой модели (LLM) для выполнения конкретной задачи или работы с определённым набором данных, улучшая её способность давать оптимальные результаты для целевых задач.
| Аспект | Инженерия промптов | Тонкая настройка |
|---|---|---|
| Основная идея | Инструктирование общего мозга | Обучение специализированного мозга |
| Стоимость | Низкая (в основном время и токены) | Высокая (данные и вычисления) |
| Знания | Использует общие знания модели | Встраивает ваши специализированные знания |
| Надёжность | Средняя; может быть непостоянной | Высокая; поведение встроено |
Посмотрите, какой из следующих сценариев лучше всего подходит для вашего проекта.
Вам стоит выбрать тонкую настройку, если нужно:
-
Глубокая предметная экспертиза
- Сценарий: Вам нужно, чтобы модель изучила вашу частную кодовую базу, обширную документацию по продукту или узкоспециализированные научные статьи. Это знания, которые она не может найти в открытом интернете.
-
Строгая структурная надёжность
- Сценарий: Ваше приложение требует, чтобы модель последовательно выдавала идеальный JSON или XML, без пропущенных полей или лишнего диалогового текста.
-
Уникальный, глубоко укоренившийся стиль
- Сценарий: Вы хотите, чтобы модель использовала определённый голос бренда, стиль вымышленного персонажа или терапевтическую коммуникационную систему, которые ощущаются глубоко интегрированными.
Вам стоит выбрать инженерию промптов, если нужно:
-
Выполнять общие задачи
- Сценарий: Вам просто нужна помощь в написании писем, составлении summary статей, переводе текста или генерации идей.
-
Быстро прототипировать и итерировать
- Сценарий: Вы хотите быстро протестировать новую AI-функцию, не имея времени или ресурсов для создания большого высококачественного набора данных.
-
Обрабатывать разнообразные разовые задачи
- Сценарий: Вам нужно, чтобы модель обрабатывала множество временных запросов, которые не следуют фиксированному шаблону.
Что нужно для тонкой настройки DeepSeek R1 0528?
| Описание позиции | Цена за единицу (USD) | Количество | Итого (USD) |
|---|---|---|---|
| NVIDIA A100 80GB GPUs | $22,217.71 | 116 | $2,577,251.96 |
| Серверные узлы (два A100) | $50,000 | 58 | $2,900,000 |
| Высокоскоростная сеть (InfiniBand) | $100,000 | 1 | $100,000 |
| Хранилище (NVMe SSD, 100TB) | $20,000 | 1 | $20,000 |
| Система жидкостного охлаждения | $80,000 | 1 | $80,000 |
| Блок питания и ИБП | $50,000 | 1 | $50,000 |
| Стойка | $10,000 | 1 | $10,000 |
| Лицензии на ПО (ОС, фреймворки) | $10,000 | 1 | $10,000 |
| Годовое обслуживание и поддержка | $100,000 | 1 | $100,000 |
| Электроэнергия (год, 700W на GPU) | $0.15/кВт·ч | 1 | $50,000 |
| Общая оценочная стоимость | $5,887,251.96 |
Тонкая настройка больших языковых моделей (LLM) включает различные техники и стратегии, такие как Parameter-Efficient Fine-Tuning (PEFT), оптимизация параметров обучения и предобработка данных. Хотя эти методы эффективны, они часто требуют значительных человеческих и материальных ресурсов, включая специализированные технические команды, мощные вычислительные мощности и много времени. Поэтому выбор стабильного и экономически эффективного облачного провайдера становится более эффективным решением.
Стабильный и экономически эффективный выбор: Novita AI Cloud GPU
Когда речь идёт о развёртывании в производственных масштабах, крайне важно найти идеальный баланс между производительностью и стоимостью. Novita AI выделяется конкурентоспособными ценами, предлагая самые доступные почасовые ставки для выделенных H100 и H200 GPU среди ведущих провайдеров — обеспечивая максимальную вычислительную мощность при минимальных затратах!
| Провайдер | A100 (1 карта/ч) | H100 (1 карта/ч) | H200 (1 карта/ч) |
| Novita AI | $1.6 | $2.41 | $2.99 |
| Fireworks AI | $2.9 | $5.80 | $9.99 |
| Friendli AI | $2.9 | $4.90 | $5.90 |
| Deepinfra | $1.5 | $2.40 | $3.00 |
Шаги по развёртыванию и руководство по использованию
Шаг 1: Зарегистрируйте аккаунт
Создайте аккаунт Novita AI на нашем сайте. После регистрации перейдите в раздел “Explore” на левой боковой панели, чтобы увидеть наши предложения GPU и начать свой путь AI-разработки.

Шаг 2: Изучение шаблонов и GPU-серверов
Выберите шаблон, такой как PyTorch, TensorFlow или CUDA, который соответствует потребностям вашего проекта. Затем выберите желаемую конфигурацию GPU — доступны такие мощные варианты, как L40S, RTX 4090 или A100 SXM4, каждый с различными характеристиками VRAM, RAM и хранилища.
Шаг 3: Настройте развёртывание
Настройте среду, выбрав предпочтительную операционную систему и параметры конфигурации, чтобы обеспечить оптимальную производительность для ваших конкретных AI-нагрузок и потребностей разработки.
Шаг 4: Запустите экземпляр
Выберите “Launch Instance”, чтобы начать развёртывание. Ваша высокопроизводительная GPU-среда будет готова в течение нескольких минут, позволяя немедленно приступить к проектам машинного обучения, рендеринга или вычислительным проектам.
Для производительности, безопасности и экономии выберите выделенную конечную точку
Выделенная конечная точка в Novita AI предоставляет значительные преимущества, включая стабильную высокую производительность с гарантированной пропускной способностью, полную конфиденциальность данных благодаря изолированным ресурсам и возможность развёртывания пользовательских или доработанных моделей Hugging Face. Она также предлагает гибкое масштабирование до 8 GPU (или больше для корпоративных пользователей), прозрачные и предсказуемые цены для постоянных нагрузок и SLA 99.5% для производственной надёжности.
Шаги по развёртыванию и руководство по использованию
1. Доступ к консоли
- Войдите в Консоль Novita AI.
- На левой боковой панели нажмите LLM Dedicated Endpoints.
2. Создайте новую конечную точку
- Нажмите кнопку + New Endpoint в правом верхнем углу.
3. Настройте конечную точку
Заполните форму конфигурации, используя следующие параметры:
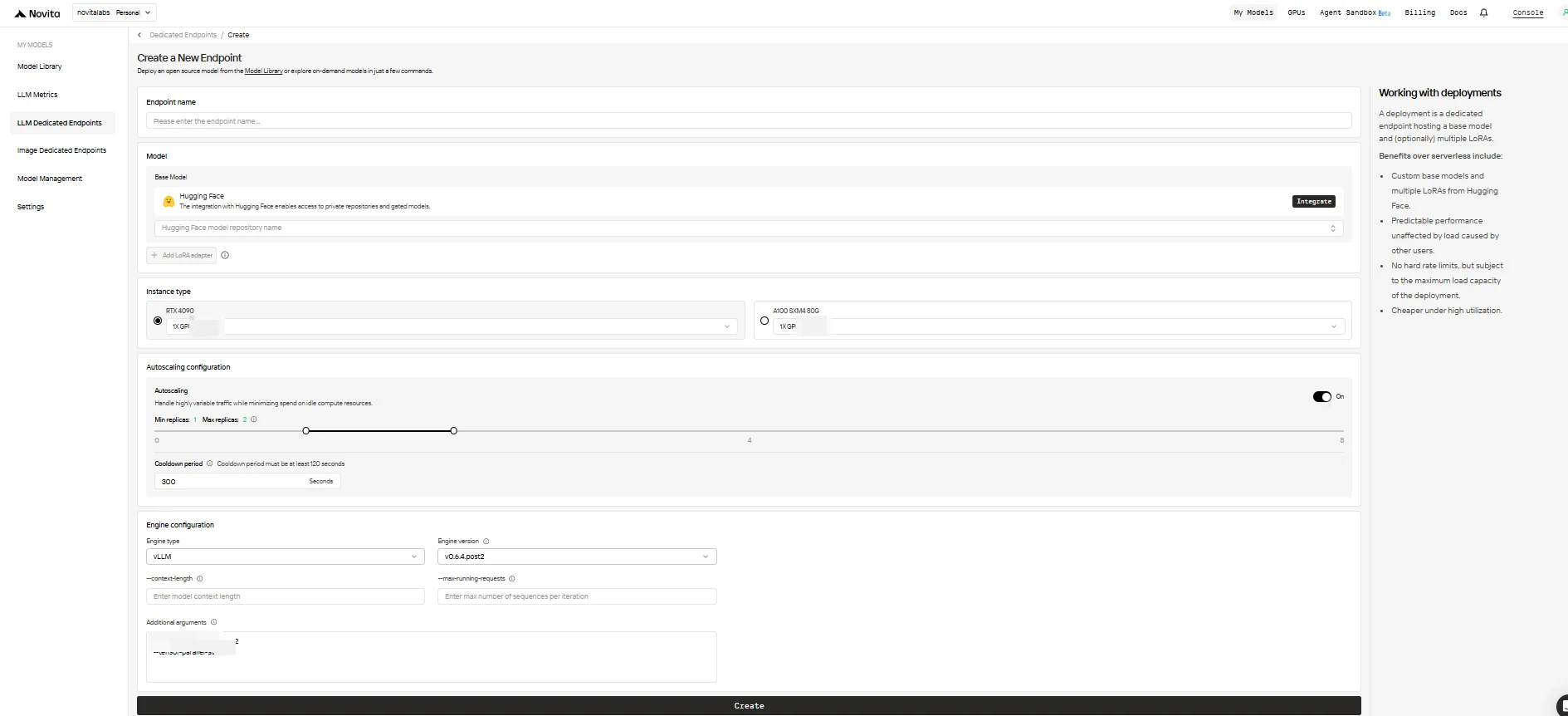
-
Endpoint Name: Присвойте вашему развёртыванию уникальное и описательное имя.
-
Base Model: Введите имя репозитория Hugging Face для вашей базовой модели (поддерживаются только модели Hugging Face, включая публичные, приватные или с ограниченным доступом).
-
LoRA Adapters (опционально): Добавьте один или несколько идентификаторов модели Hugging Face, чтобы прикрепить LoRA-адаптеры к вашей базовой модели.
-
Instance Type: Выберите GPU-оборудование (например, H100, H200, RTX4090). Каждый пользователь может использовать до 8 GPU во всех конечных точках.
-
Autoscaling Configuration:
- Minimum Replicas: Установите
0, чтобы конечная точка “засыпала” при простое (экономия средств), или большее значение, чтобы всегда поддерживать минимальное количество активных реплик. - Maximum Replicas: Установите максимальное количество реплик для масштабирования (до 10).
- Cooldown Period: Установите задержку (в секундах) перед масштабированием реплик вниз, чтобы избежать преждевременного уменьшения при кратковременных падениях трафика.
- Minimum Replicas: Установите
-
Engine Configuration:
- Engine Type: Выберите инференс-движок (
vLLMилиSGLang). - Engine Version: Используйте версию по умолчанию (последнюю) или укажите конкретную.
- Context Length: При необходимости установите максимальную длину контекста в токенах; если опущено, будет взято из конфигурации модели.
- Max Running Requests: Установите максимальное количество последовательностей, обрабатываемых за одну итерацию.
- Additional Arguments: Добавьте любые дополнительные параметры движка для расширенной настройки.
- Engine Type: Выберите инференс-движок (
Когда закончите, нажмите Create, чтобы развернуть конечную точку.
4. Статус развёртывания конечной точки
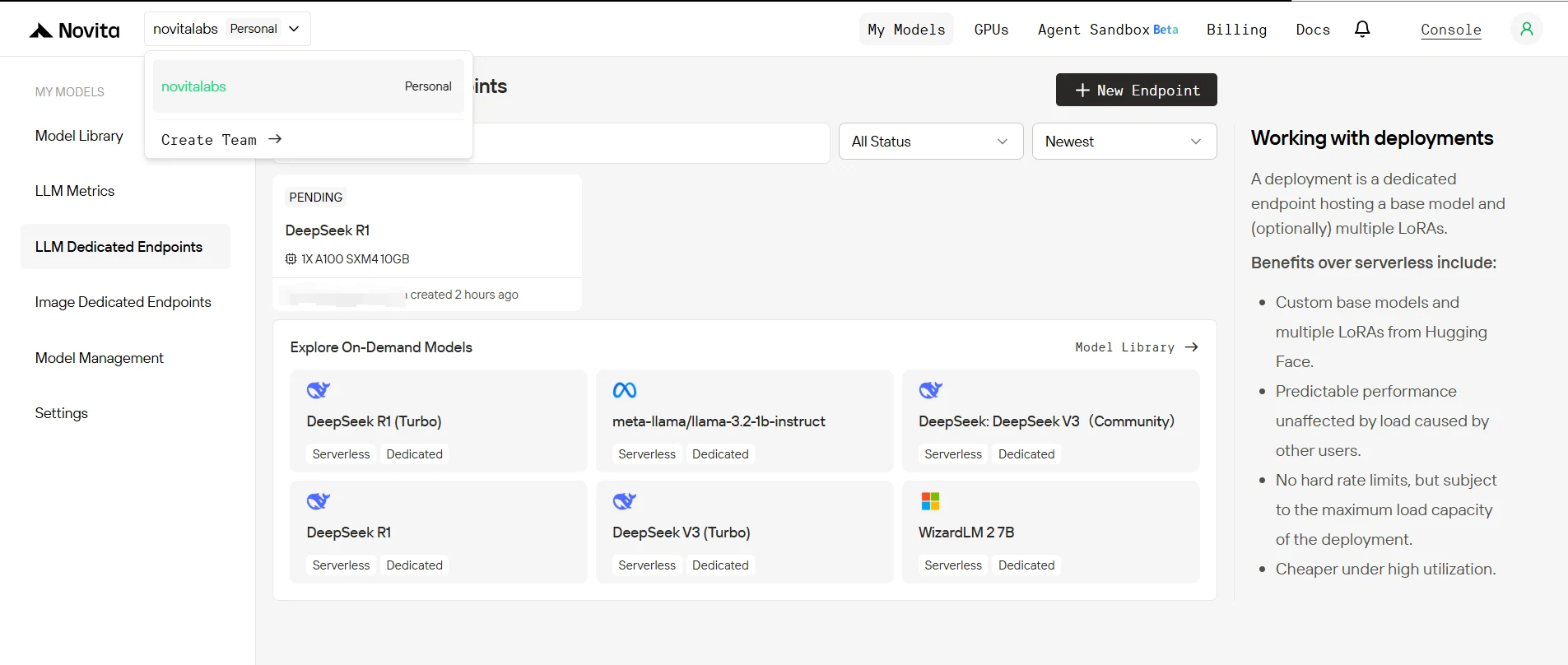
После создания ваша конечная точка будет проходить через несколько статусов:
- Sleeping: Конечная точка простаивает, не потребляя вычислительные ресурсы (если минимальное количество реплик установлено на 0).
- Pending: Развёртывание инициализируется.
- Rolling: Модель и инфраструктура настраиваются.
- Running: Конечная точка активна и готова обрабатывать запросы.
Вы можете отслеживать этот статус на странице Endpoints в консоли.
5. Тестирование конечной точки в Playground
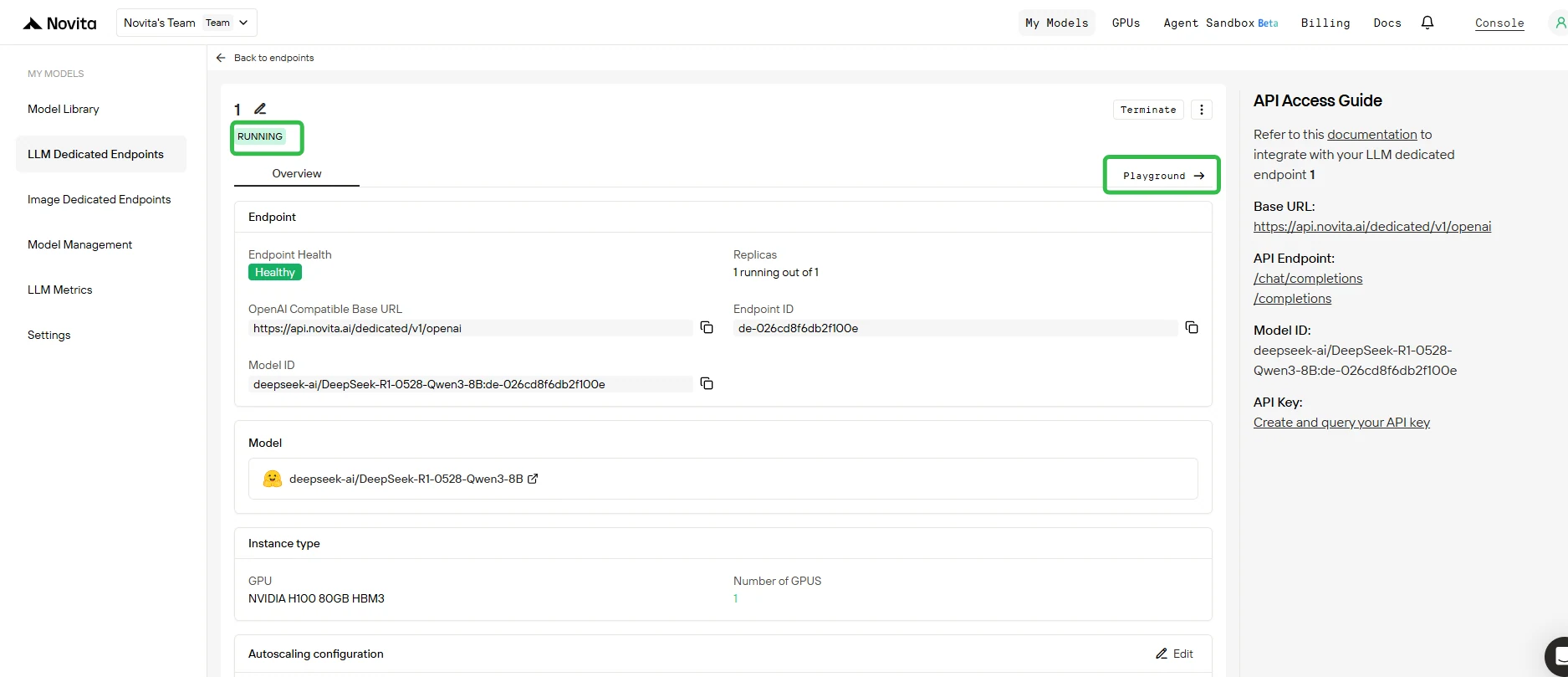
- Когда развёртывание завершено и статус Running, нажмите на вашу конечную точку и откройте вкладку Playground.
- В Playground вы можете:
- Отправлять тестовые промпты к вашей базовой модели и любым прикреплённым LoRA-адаптерам.
- Мгновенно сравнивать вывод разных адаптеров с выводом базовой модели.
Попробуйте выделенную конечную точку сейчас
6. Дальнейшие шаги
- Multi-LoRA Endpoints: Разверните несколько LoRA-адаптеров на одной конечной точке для гибкого переключения моделей.
- Интеграция через API: Используйте предоставленные конечные точки API для отправки запросов и интеграции вашей модели в собственные приложения.
- Оптимизация и масштабирование: Настройте автомасштабирование, конфигурацию движка и квоту GPU по мере роста ваших потребностей.
- Нужно больше ресурсов? Обратитесь к нашей команде продаж для корпоративного решения, если вам нужно более 8 GPU или требуются функции корпоративного уровня.
Примеры кода (для пользователей Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/dedicated/v1/openai",
api_key="<Ваш API-ключ>",
)
model = "deepseek-ai/DeepSeek-R1-0528-"
stream = True # или False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Вы профессиональный AI-помощник.",
},
{
"role": "user",
"content": "Где можно адаптировать пример GPU, предоставляемый novita ai?",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Тонкая настройка DeepSeek R1 0528 позволяет использовать весь его потенциал для задач в конкретных областях, обеспечивая точные, надёжные и настраиваемые результаты. Используя эффективные техники, такие как LoRA-адаптеры, и развёртывая модель на экономичных платформах, таких как Novita AI, вы можете сократить расходы, достигая высокой производительности. Нужна ли вам глубокая экспертиза, строгая надёжность или уникальный стиль, тонкая настройка гарантирует, что модель соответствует вашим конкретным требованиям.
Часто задаваемые вопросы
Какова стоимость тонкой настройки DeepSeek R1 0528?
Оценочная стоимость создания собственной инфраструктуры составляет около $5.89M. Однако использование облачных GPU Novita AI значительно сокращает первоначальные затраты: H100 GPU начинаются от $2.41/час.
Как убедиться, что доработанная модель соответствует моим потребностям?
Подготовьте чистый, релевантный набор данных и используйте LoRA-адаптеры или методы PEFT для эффективной тонкой настройки определённых слоёв модели. Это обеспечивает высокую производительность без переобучения.
Могу ли я развернуть свою доработанную модель на Novita AI?
Да, Novita AI поддерживает развёртывание доработанных моделей в виде выделенных конечных точек, с возможностями автомасштабирования, мульти-LoRA настроек и интеграции через API для бесшовного использования в ваших приложениях.
Novita AI — это облачная AI-платформа, которая предлагает разработчикам простой способ развёртывания AI-моделей с помощью нашего простого API, а также предоставляет доступное и надёжное GPU-облако для сборки и масштабирования.



