

如果你想在特定领域充分释放 DeepSeek R1 0528 的潜力,微调是最有效的方法。该模型虽已在高级推理、数学和编程方面表现出色,但微调能使其专注于自然语言生成、领域专业知识或多模态任务等领域。本文将为你提供一份关于微调 DeepSeek R1 0528 的具体指南。
DeepSeek R1 0528 在哪些方面表现出色?
模型卡片
- 模型大小: 685B 参数
- 开源: 是
- 架构: 混合专家(MoE)
- 语言支持: 多语言(擅长英文和中文)
- 多模态能力: 是(文本到文本)
- 训练: DeepSeek R1 的最新更新利用了更多计算资源和算法后训练优化,显著提升了推理深度和推断能力。
模型性能
| 基准测试 | DeepSeek R1 0528 | 高于 |
|---|---|---|
| AIME 2024 | 91.4 | 所有(除 OpenAI-o3,几乎并列) |
| AIME 2025 | 87.5 | 所有 |
| GPQA Diamond | 81.0 | Qwen3-235B, DeepSeek-R1 |
| LiveCodeBench | 73.3 | 所有 |
| Aider | 71.6 | Qwen3-235B, DeepSeek-R1 |
| Humanity’s Last Exam | 17.7 | Qwen3-235B, DeepSeek-R1 |
- 在高级数学推理和问题解决方面表现出色
- 展现出强大的编程和代码生成能力
- 高效处理复杂逻辑和分析任务
由于 DeepSeek R1 0528 在数学、代码和逻辑方面已经很强,你的最佳微调方向应针对其相对薄弱的领域,例如自然语言生成、领域专业知识、多模态任务或安全与对齐。这将使模型更加通用,适用于更广泛的应用场景。
何时应选择微调?
微调是将预训练的大语言模型(LLM)适配到特定任务或数据集的过程,以增强其在目标任务上的表现。
| 方面 | 提示工程 | 微调 |
|---|---|---|
| **核心思想 ** | ** 指导 **一个通用大脑 | ** 训练**一个专家大脑 |
| 成本 | 低(主要是时间和 Token) | 高(数据和算力) |
| **知识 ** | 使用模型的** 通用 **知识 | 植入你的** 专家**知识 |
| 可靠性 | 中等;可能不一致 | 高;行为被固化 |
看看以下哪种场景最适合你的项目。
如果你的需求属于以下情况,应选择微调:
- 深度领域专业知识
- 场景: 你需要模型学习公司的私有代码库、大量产品文档或专业科学论文。这些是它在公共互联网上找不到的知识。
- 严格的结构可靠性
- 场景: 你的应用要求模型始终输出完美的 JSON 或 XML,没有缺失字段或多余的对话文本。
- 独特且内在化的个性
- 场景: 你希望模型采用特定的品牌语调、虚构角色的风格或治疗性沟通框架,并且感觉这些特征已深度融入。
如果你的需求属于以下情况,应选择提示工程:
- 执行通用任务
- 场景: 你只需要帮助撰写邮件、总结文章、翻译文本或进行头脑风暴。
- 快速原型设计和迭代
- 场景: 你想快速测试新的 AI 功能,但没有时间和资源创建大规模高质量数据集。
- 处理多样化的零散任务
- 场景: 你需要模型处理各种临时请求,这些请求没有固定模式。
微调 DeepSeek R1 0528 需要什么?
| **项目描述 ** | ** 单价(美元)** | ** 数量 ** | ** 合计(美元)** |
|---|---|---|---|
| NVIDIA A100 80GB GPU | $22,217.71 | 116 | $2,577,251.96 |
| 服务器节点(双 A100) | $50,000 | 58 | $2,900,000 |
| 高速网络(InfiniBand) | $100,000 | 1 | $100,000 |
| 存储(NVMe SSD,100TB) | $20,000 | 1 | $20,000 |
| 液冷系统 | $80,000 | 1 | $80,000 |
| 电源及 UPS | $50,000 | 1 | $50,000 |
| 机柜 | $10,000 | 1 | $10,000 |
| 软件许可(操作系统、框架) | $10,000 | 1 | $10,000 |
| 年度维护与支持 | $100,000 | 1 | $100,000 |
| 电力(年度,每 GPU 700W) | $0.15/kWh | 1 | $50,000 |
| **总估算成本 ** | $5,887,251.96 |
微调大语言模型涉及多种技术和策略,例如参数高效微调(PEFT)、优化训练参数、数据预处理等。虽然这些方法有效,但通常需要大量人力和物力,包括专业的技术团队、强大的计算硬件和充足的时间。因此,选择一个稳定且成本效益高的云服务提供商成为更高效的解决方案。
稳定且经济的选择:Novita AI 云 GPU
在生产级部署中,性能与成本的完美平衡至关重要。Novita AI 以行业领先的定价脱颖而出,在主要提供商中提供最实惠的专用 H100 和 H200 GPU 小时费率——以最低成本实现最大计算能力!
| 提供商 | A100(1卡/小时) | H100(1卡/小时) | H200(1卡/小时) |
|---|---|---|---|
| Novita AI | $1.6 | $2.41 | $2.99 |
| Fireworks AI | $2.9 | $5.80 | $9.99 |
| Friendli AI | $2.9 | $4.90 | $5.90 |
| Deepinfra | $1.5 | $2.40 | $3.00 |
部署步骤与使用指南
第一步:注册账号
通过我们的网站创建你的 Novita AI 账号。注册后,在左侧边栏导航到 “探索” 部分,查看我们的 GPU 产品,开始你的 AI 开发之旅。

第二步:探索模板与 GPU 服务器
从 PyTorch、TensorFlow 或 CUDA 等模板中选择符合项目需求的选项。然后选择你偏好的 GPU 配置——可选配强大的 L40S、RTX 4090 或 A100 SXM4,每种配置都有不同的显存、内存和存储规格。
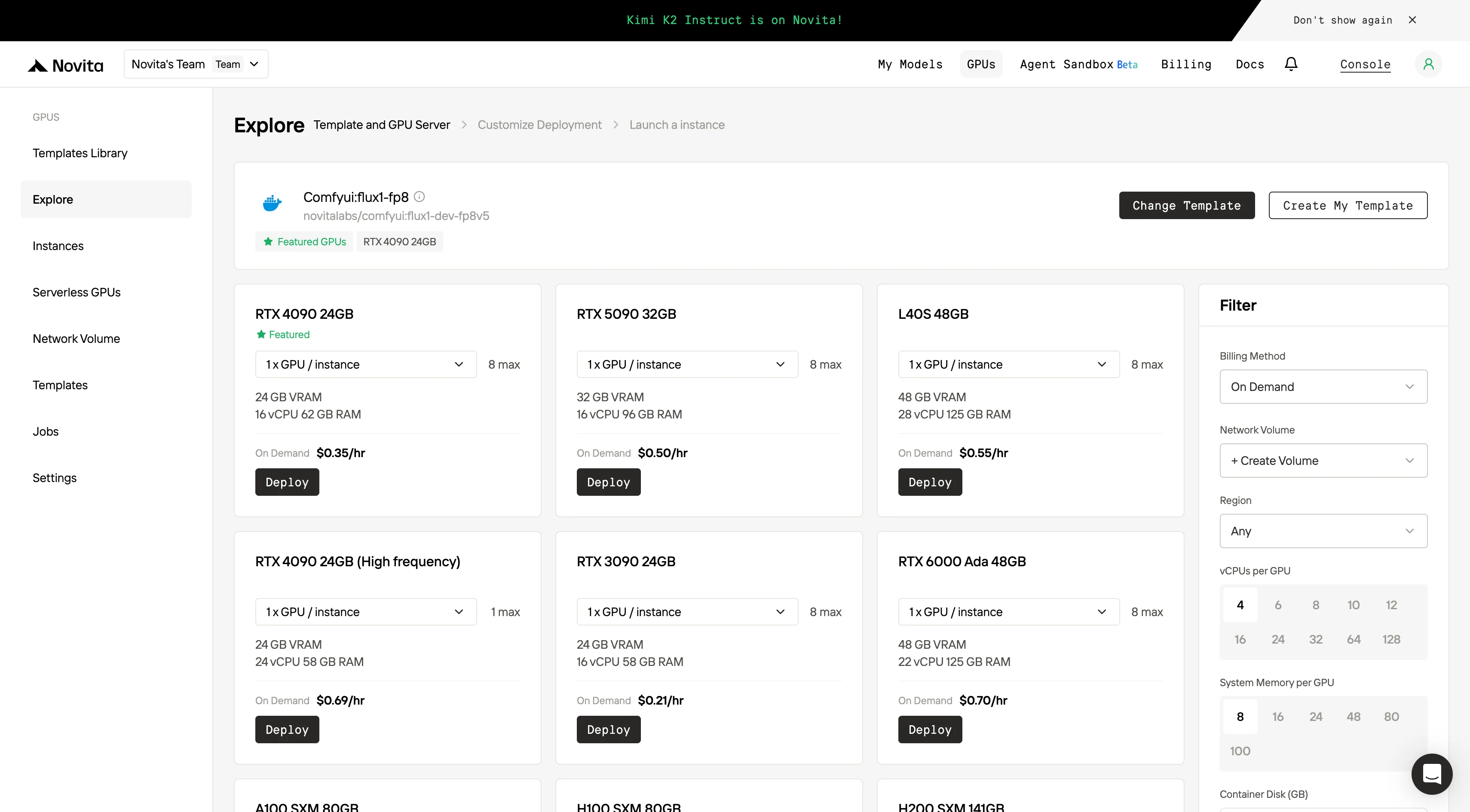
第三步:定制你的部署
通过选择偏好操作系统和配置选项定制你的环境,确保特定 AI 工作负载和开发需求的最佳性能。
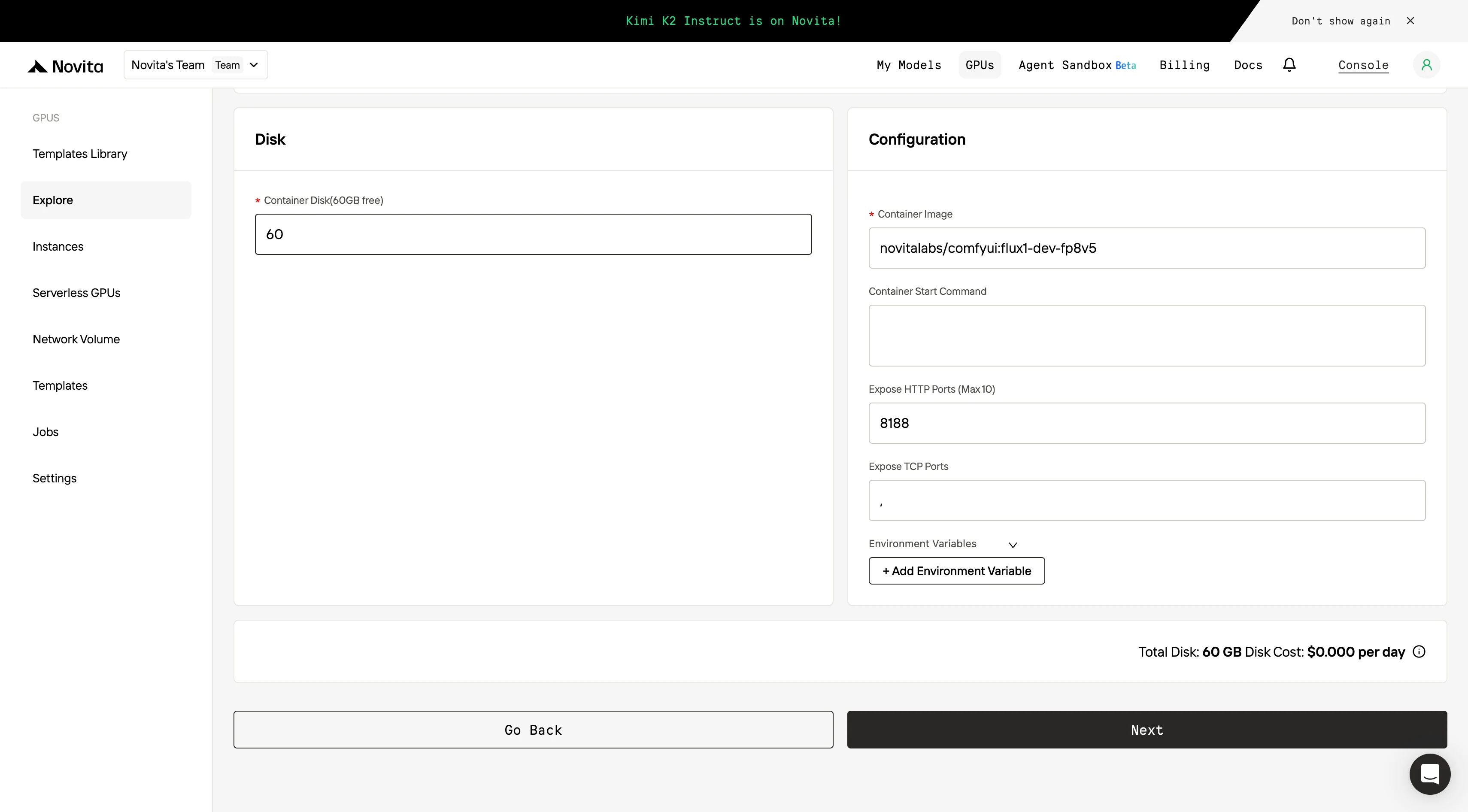
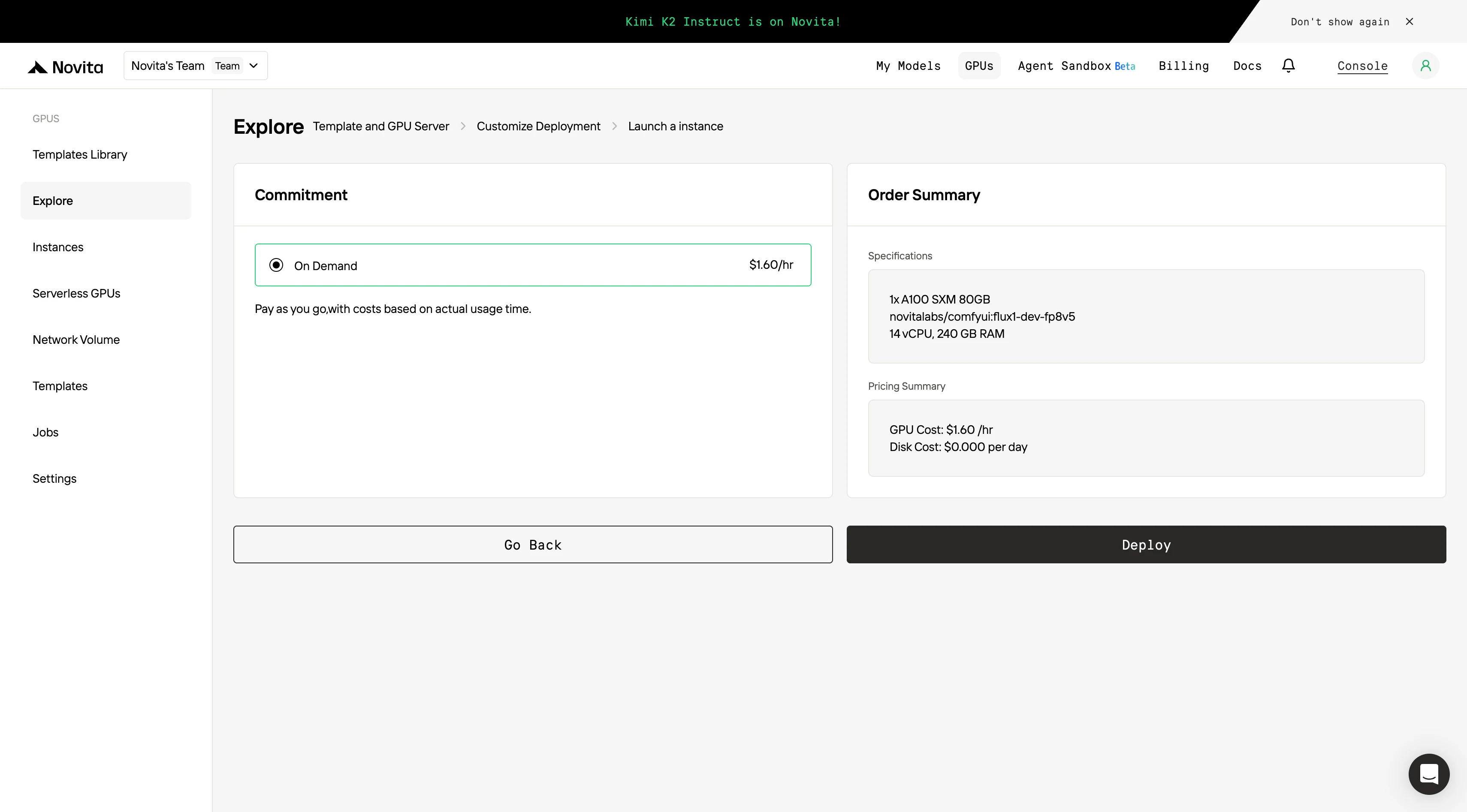
第四步:启动实例
选择 “启动实例” 开始部署。你的高性能 GPU 环境将在几分钟内准备就绪,可立即开始机器学习、渲染或计算项目。
为性能、安全和节省成本,选择专用端点
Novita AI 上的 专用端点 提供了显著的优势,包括一致的高性能(保证吞吐量)、通过隔离资源实现完全的数据隐私,以及部署自定义或微调的 Hugging Face 模型的能力。它还提供灵活扩展(最多 8 个 GPU,企业用户可更多)、持续工作负载的透明可预测定价,以及 99.5% 的 SLA 生产级可靠性。
部署步骤与使用指南
1. 访问控制台
- 登录你的 Novita AI 控制台。
- 在左侧边栏中,点击 “LLM 专用端点”。
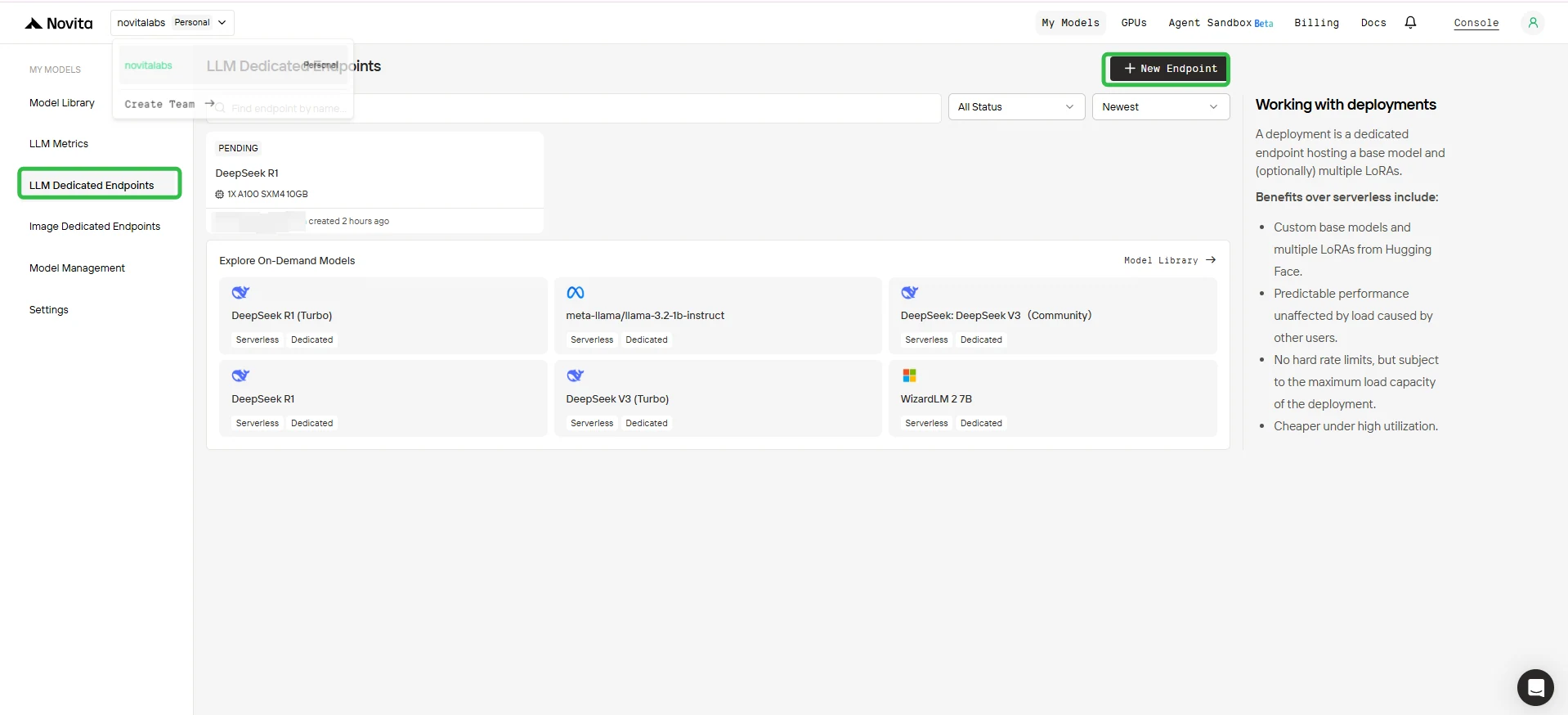
2. 创建新端点
- 点击右上角的 “+ 新端点” 按钮。
3. 配置你的端点
填写配置表单,选择以下选项:
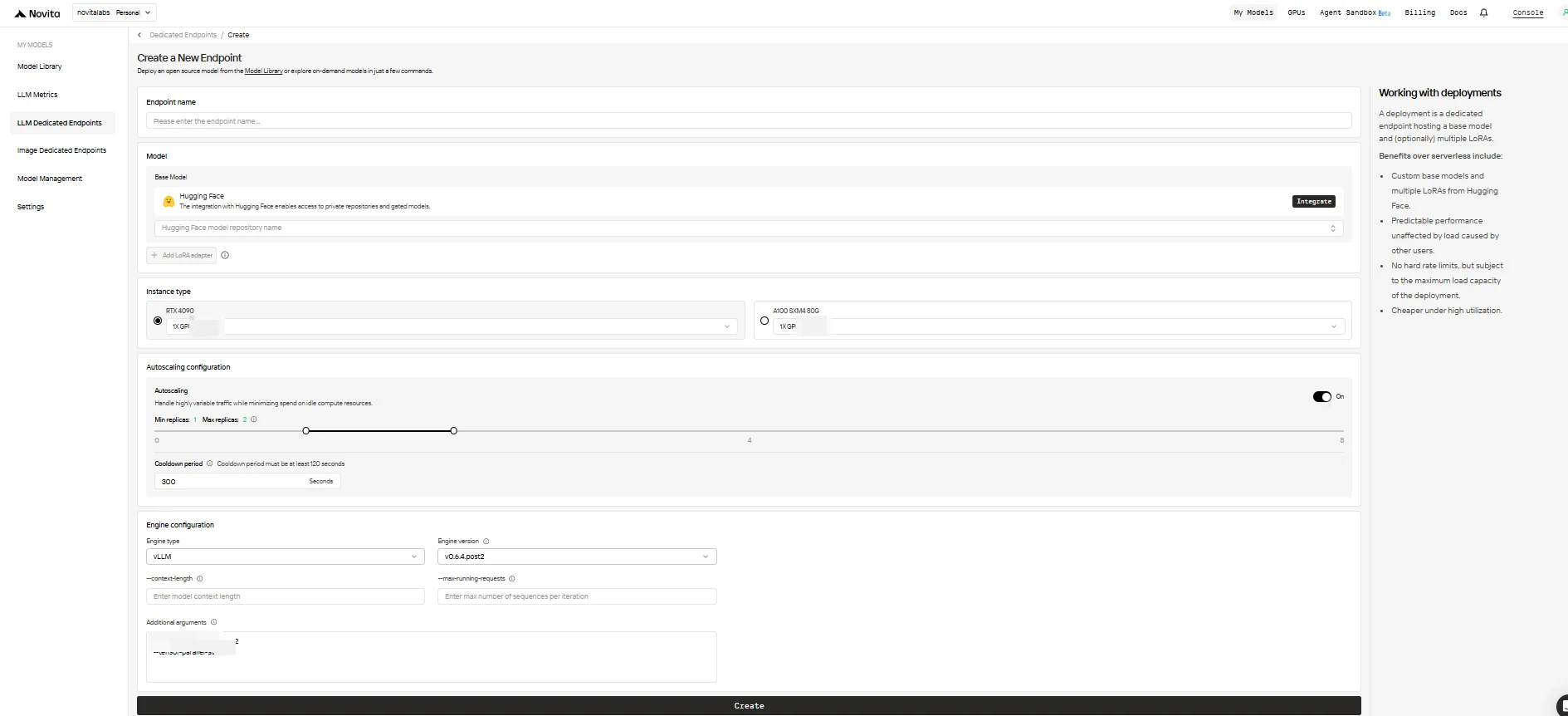
- 端点名称: 为你的部署指定一个唯一且描述性的名称。
- 基础模型: 输入基础模型的 Hugging Face 仓库名称(仅支持 Hugging Face 模型,包括公开、私有或受限模型)。
- LoRA 适配器(可选): 添加一个或多个 Hugging Face 模型 ID,将 LoRA 适配器附加到基础模型。
- 实例类型: 选择 GPU 硬件(例如 H100、H200、RTX4090)。每个用户在所有端点中最多可使用 8 个 GPU。
- 自动缩放配置:
- 最小副本数: 设置为
0可使端点空闲时休眠(节省成本),或设置更高值以始终保持最小数量的活跃副本。 - 最大副本数: 设置用于缩放的副本数上限(最多 10 个)。
- 冷却期: 设置缩容前的延迟时间(秒),避免在短暂流量下降时过早缩容。
- 最小副本数: 设置为
- 引擎配置:
- 引擎类型: 选择推理引擎(
vLLM或SGLang)。 - 引擎版本: 使用默认(最新)或指定版本。
- 上下文长度: 可选设置最大 token 上下文长度;如果省略,将从模型配置中自动推导。
- 最大运行请求数: 设置每次迭代处理的序列数量上限。
- 附加参数: 添加额外的引擎参数用于高级定制。
- 引擎类型: 选择推理引擎(
完成后,点击 “创建” 部署你的端点。
4. 端点部署状态
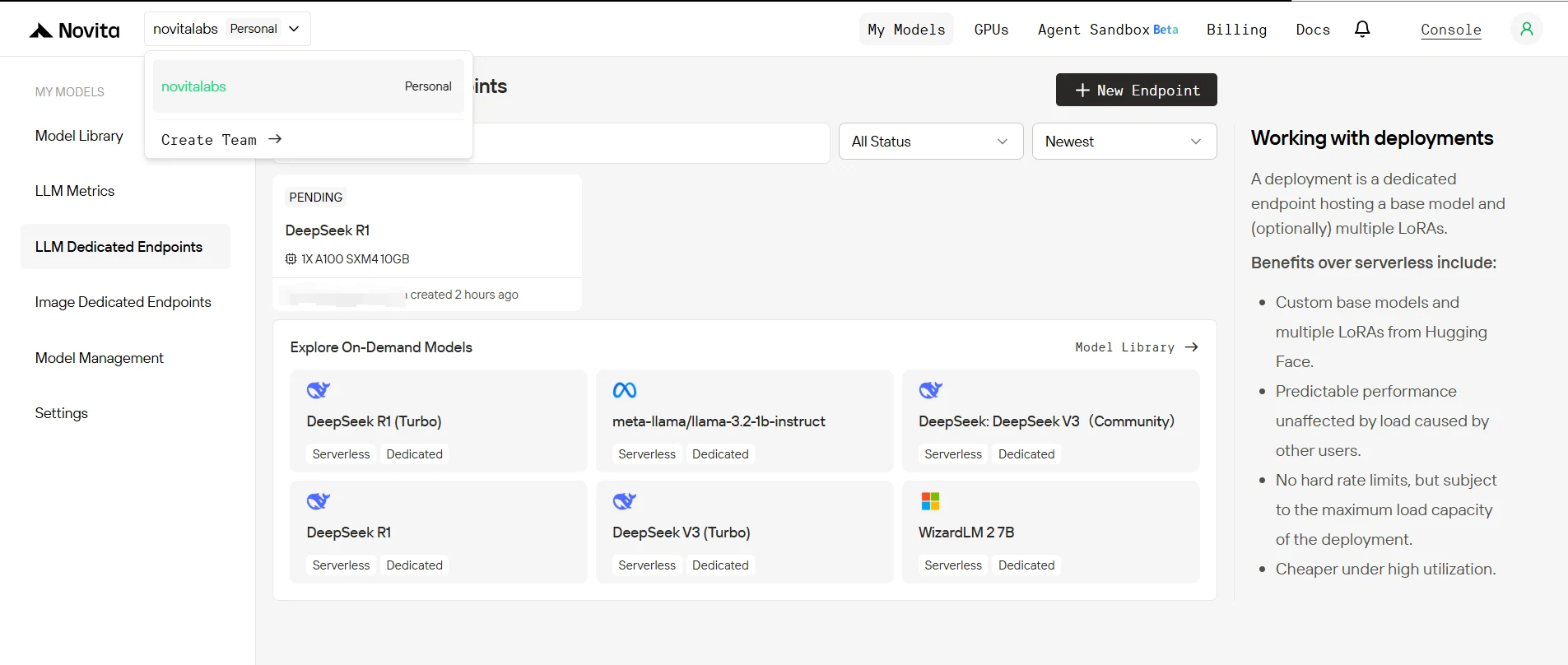
创建后,你的端点将经历多个状态:
- 休眠: 端点空闲,不消耗计算资源(如果最小副本数设为 0)。
- 待处理: 部署正在初始化。
- 滚动中: 模型和基础设施正在设置。
- 运行中: 端点处于活跃状态,可处理请求。
你可以在控制台的端点页面监控此状态。
5. 在 Playground 中测试端点
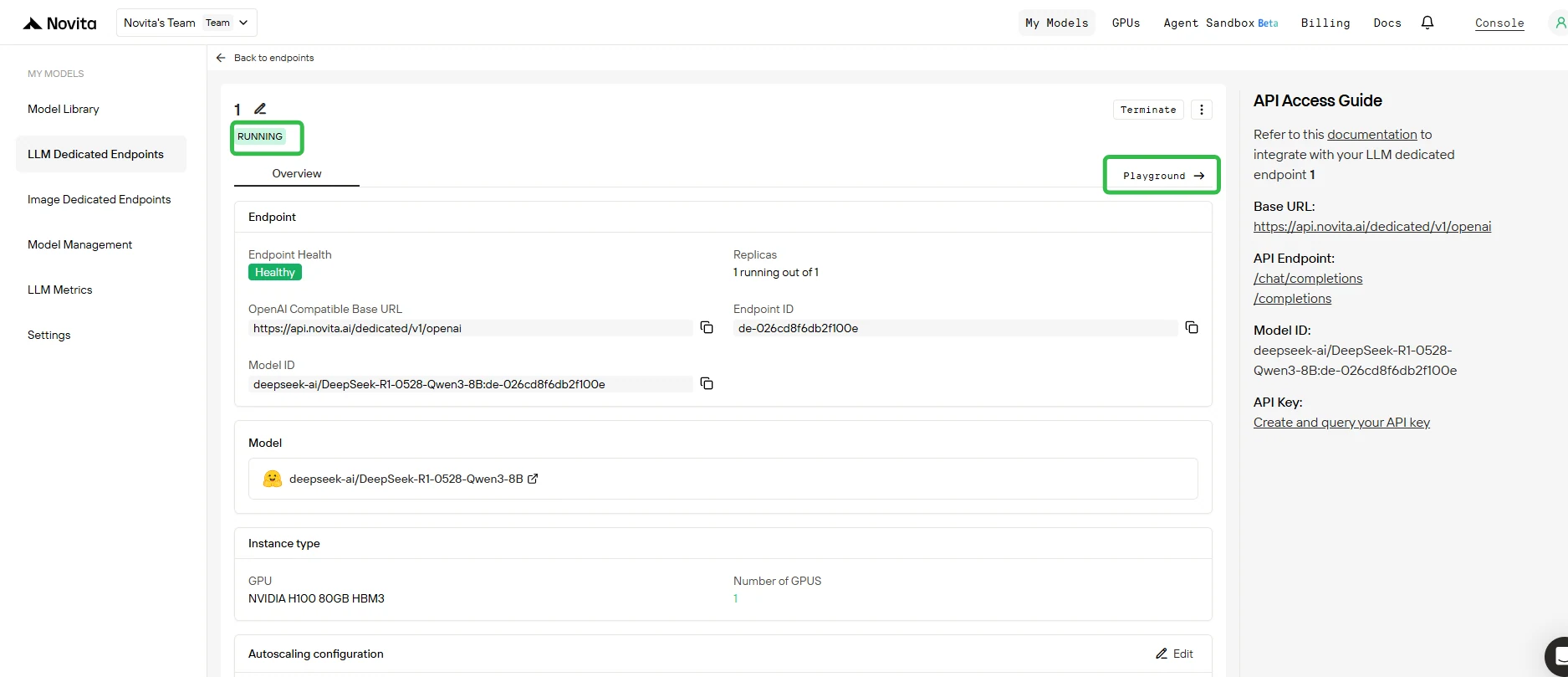
- 部署完成且状态为 **运行中 ** 后,点击你的端点并打开 “Playground” 标签。
- 在 Playground 中,你可以:
- 向基础模型和任何附加的 LoRA 适配器发送测试提示。
- 即时比较不同适配器与基础模型的输出。
6. 后续步骤
- 多 LoRA 端点: 在单个端点上部署多个 LoRA 适配器,实现灵活的模型切换。
- API 集成: 使用提供的 API 端点发送请求,将模型集成到自己的应用中。
- 优化与扩展: 根据需要调整自动缩放、引擎配置和 GPU 配额。
- 需要更多资源? 如果需要超过 8 个 GPU 或企业级功能,请联系我们的 销售团队 获取企业解决方案。
代码示例(适用于 Python 用户)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/dedicated/v1/openai",
api_key="<Your API Key>",
)
model = "deepseek-ai/DeepSeek-R1-0528-"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "you are a professional AI helper.",
},
{
"role": "user",
"content": "Where can the example of GPU provided by novita ai be adapted?",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
微调 DeepSeek R1 0528 让你能够为领域特定任务释放其全部潜力,从而提供精确、可靠且定制化的输出。通过利用 LoRA 适配器等高效技术,并部署在 Novita AI 等经济高效的平台上,你可以在降低成本的同时实现高性能。无论你需要深度专业知识、严格可靠性还是独特个性,微调都能确保模型满足你的具体要求。
常见问题
微调 DeepSeek R1 0528 的成本是多少?
构建自有基础设施的估算成本约为 **$589 万 **。然而,使用 Novita AI 的云 GPU 可大幅降低前期成本,H100 GPU 起价为 $2.41/小时。
如何确保微调后的模型满足我的需求?
准备一个 **干净、相关的数据集 **,并使用 **LoRA 适配器 ** 或 PEFT 方法 高效地微调模型的特定层。这可以确保高性能而不会过拟合。
我可以在 Novita AI 上部署微调后的模型吗?
可以。Novita AI 支持将微调模型部署为 专用端点,并提供自动缩放、多 LoRA 设置和 API 集成选项,方便在你的应用中无缝使用。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。



