

如果你想在特定領域中充分釋放 DeepSeek R1 0528 的潛力,微調 是最有效的方法。儘管該模型在進階推理、數學和程式碼方面已表現出色,但微調能讓它在自然語言生成、領域專業知識或多模態任務等領域更加專精。本文將提供一份關於微調 DeepSeek R1 0528 的具體指南。
DeepSeek R1 0528 在哪些方面表現優異?
模型卡
- 模型大小: 685B 參數
- 開源: 是
- 架構: 混合專家 (MoE)
- 語言支援: 多語言(英文和中文表現出色)
- 多模態能力: 是(文字到文字)
- 訓練: DeepSeek R1 的最新更新利用了增加的計算資源和演算法後訓練最佳化。這顯著提升了其推理深度和推論能力。
模型效能
| 基準 | DeepSeek R1 0528 | 高於 |
|---|---|---|
| AIME 2024 | 91.4 | 所有(除 OpenAI-o3,幾乎持平) |
| AIME 2025 | 87.5 | 所有 |
| GPQA Diamond | 81.0 | Qwen3-235B、DeepSeek-R1 |
| LiveCodeBench | 73.3 | 所有 |
| Aider | 71.6 | Qwen3-235B、DeepSeek-R1 |
| Humanity’s Last Exam | 17.7 | Qwen3-235B、DeepSeek-R1 |
- 在進階數學推理和問題解決方面表現出色
- 展現強大的程式設計和程式碼生成能力
- 有效處理複雜邏輯和分析任務
由於 DeepSeek R1 0528 在數學、程式碼和邏輯方面已經很強大,你最好的微調方向是針對它較不擅長的領域,例如自然語言生成、領域專業知識、多模態任務,或是安全與對齊。這將使模型更具通用性,並能應用於更廣泛的場景。
何時該選擇微調?
微調是調整預訓練大型語言模型 (LLM) 以服務特定目的或資料集的過程,增強其為目標任務提供最佳結果的能力。
| 方面 | 提示工程 | 微調 |
|---|---|---|
| **核心概念 ** | ** 指示 **通用大腦 | ** 訓練**專家大腦 |
| 成本 | 低(主要是時間與 Token) | 高(資料與計算) |
| **知識 ** | 使用模型的** 通用 **知識 | 植入你的** 專家**知識 |
| 可靠性 | 中等;可能不一致 | 高;行為已固化 |
請參考以下哪個情境最符合你的專案。
如果你想微調,需要滿足:
-
深層領域專業知識
- 情境: 你需要模型學習你公司的私有程式碼庫、大量的產品文件,或專業領域的科學論文。這些是它在公開網路上找不到的知識。
-
嚴格的結構可靠性
- 情境: 你的應用需要模型持續輸出完美的 JSON 或 XML,不能缺少欄位或多餘的對話文字。
-
獨特且內化的個性
- 情境: 你希望模型採用特定的品牌語氣、虛構角色的風格,或一套深度整合的治療溝通框架。
如果你選擇提示工程,需要滿足:
-
執行一般任務
- 情境: 你只需要協助撰寫電子郵件、總結文章、翻譯文字或腦力激盪想法。
-
快速原型設計與迭代
- 情境: 你想快速測試新 AI 功能,但沒有時間或資源建立大量高品質的資料集。
-
處理多樣化的一次性任務
- 情境: 你需要模型處理各種臨時請求,這些請求沒有固定模式。
微調 DeepSeek R1 0528 需要什麼?
| **項目說明 ** | ** 單價 (USD)** | ** 數量 ** | ** 總計 (USD)** |
|---|---|---|---|
| NVIDIA A100 80GB GPU | $22,217.71 | 116 | $2,577,251.96 |
| 伺服器節點 (雙 A100) | $50,000 | 58 | $2,900,000 |
| 高速網路 (InfiniBand) | $100,000 | 1 | $100,000 |
| 儲存 (NVMe SSD,100TB) | $20,000 | 1 | $20,000 |
| 液冷系統 | $80,000 | 1 | $80,000 |
| 電源供應與 UPS | $50,000 | 1 | $50,000 |
| 機櫃 | $10,000 | 1 | $10,000 |
| 軟體授權 (作業系統、框架) | $10,000 | 1 | $10,000 |
| 年度維護與支援 | $100,000 | 1 | $100,000 |
| 電費 (年度,每 GPU 700W) | $0.15/kWh | 1 | $50,000 |
| **總預估成本 ** | $5,887,251.96 |
微調大型語言模型 (LLM) 涉及多種技術和策略,例如參數高效微調 (PEFT)、最佳化訓練參數和資料預處理。雖然這些方法有效,但通常需要大量人力和物力資源,包括專業技術團隊、強大的運算硬體和充足的時間。因此,選擇穩定且成本效益高的雲端服務供應商是更有效率的解決方案。
穩定且具成本效益的選擇:Novita AI 雲端 GPU
在生產規模部署中,在效能與成本之間取得完美平衡至關重要。Novita AI 以業界領先的定價脫穎而出,在頂級供應商中提供最實惠的專用 H100 和 H200 GPU 每小時費率——以最低成本提供最大運算力!
| 供應商 | A100 (1 卡/小時) | H100 (1 卡/小時) | H200 (1 卡/小時) |
| Novita AI | $1.6 | $2.41 | $2.99 |
| Fireworks AI | $2.9 | $5.80 | $9.99 |
| Friendli AI | $2.9 | $4.90 | $5.90 |
| Deepinfra | $1.5 | $2.40 | $3.00 |
部署步驟與使用指南
步驟 1:註冊帳戶
透過我們的網站建立你的 Novita AI 帳戶。註冊後,點擊左側邊欄的「Explore」區塊,查看我們的 GPU 產品,開始你的 AI 開發之旅。

步驟 2:探索模板與 GPU 伺服器
選擇符合專案需求的模板,例如 PyTorch、TensorFlow 或 CUDA。接著選擇你偏好的 GPU 配置——選項包括強大的 L40S、RTX 4090 或 A100 SXM4,每種都提供不同的 VRAM、RAM 和儲存規格。
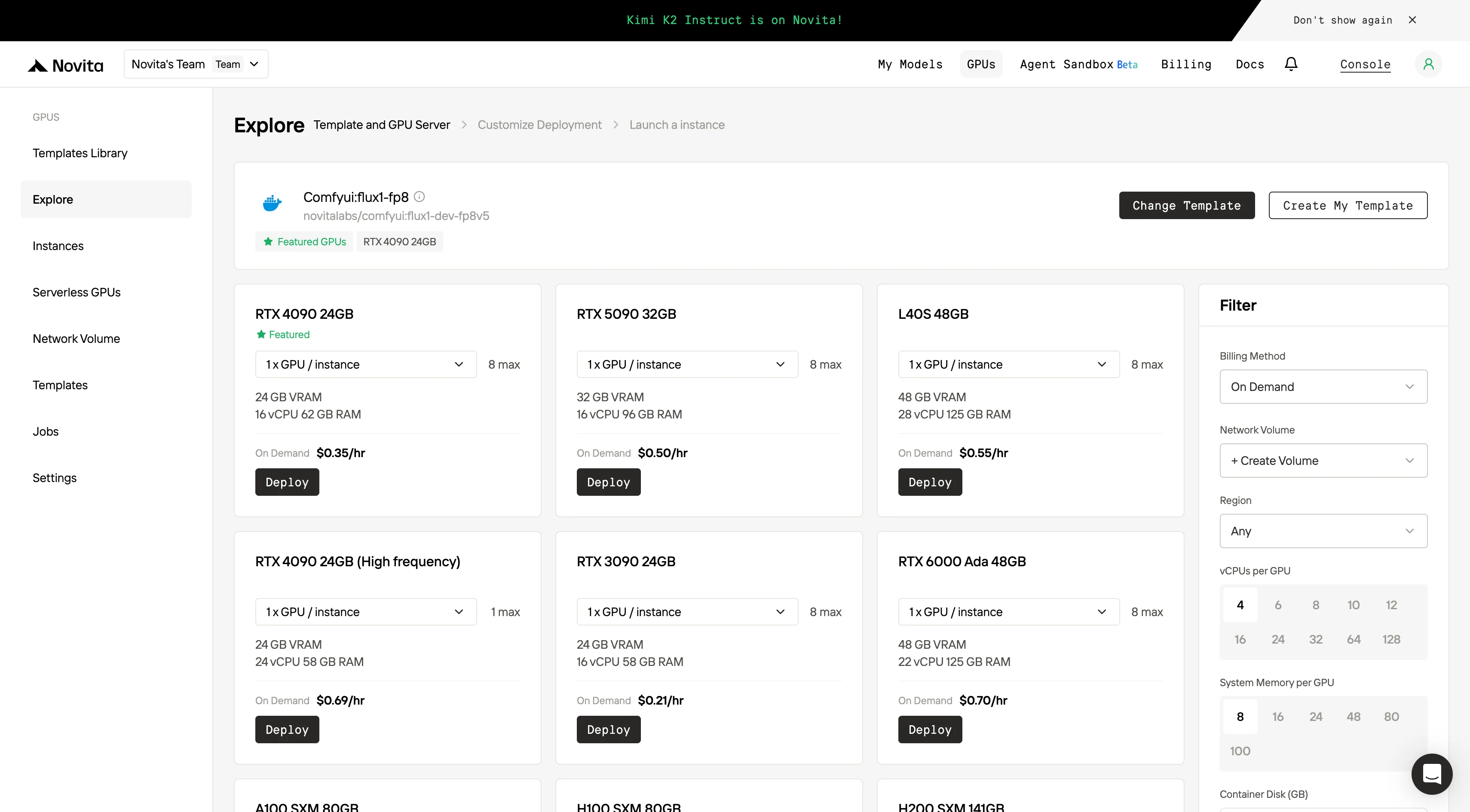
步驟 3:自訂部署
透過選擇偏好的作業系統和配置選項來自訂環境,確保特定 AI 工作負載和開發需求達到最佳效能。
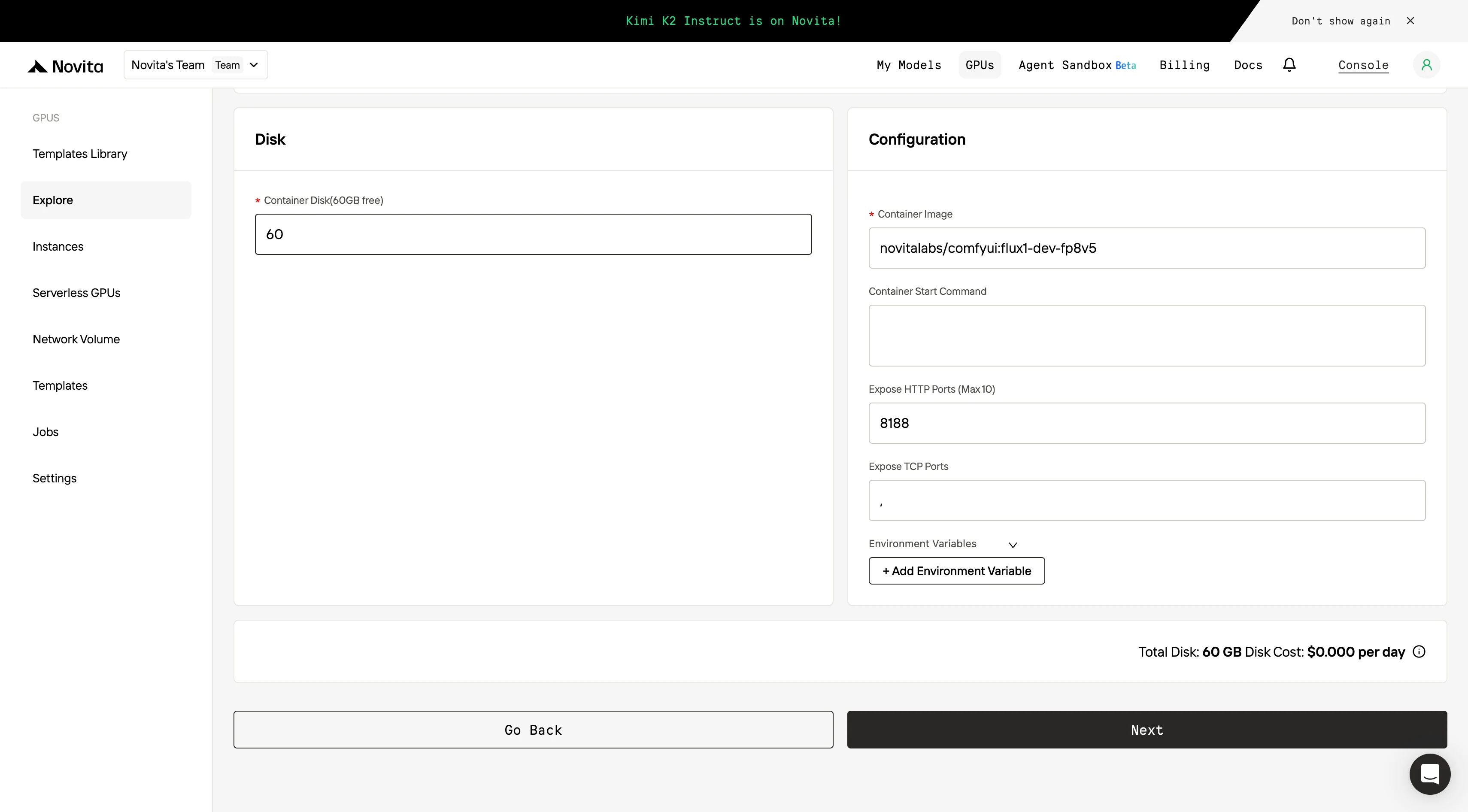
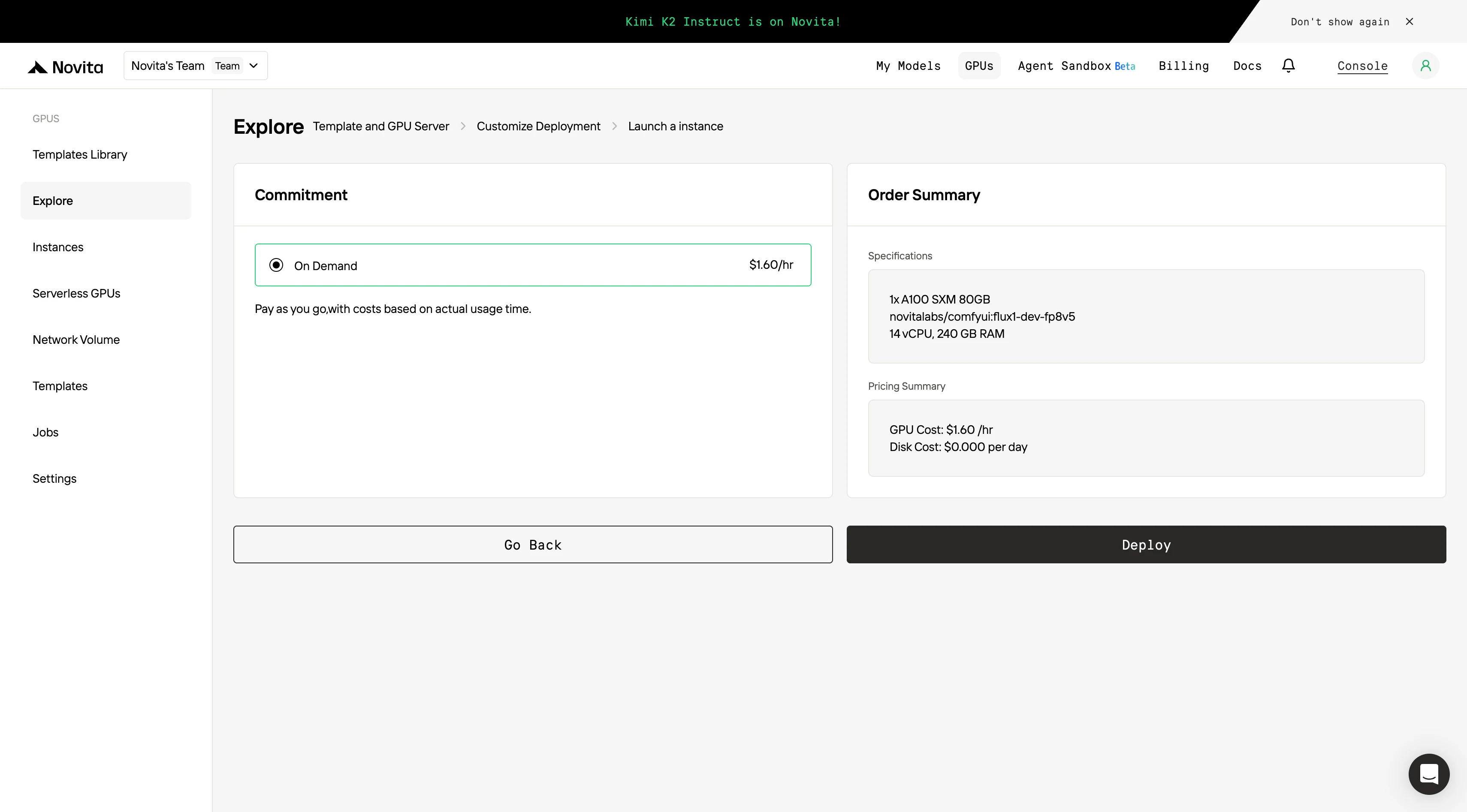
步驟 4:啟動實例
選擇「Launch Instance」開始部署。高效能的 GPU 環境將在幾分鐘內準備就緒,讓你能立即開始機器學習、渲染或運算專案。
為了效能、安全與節省成本,請選擇專用端點
專用端點 在 Novita AI 上提供顯著優勢,包括持續的高效能與保證吞吐量、透過隔離資源實現完整的資料隱私,以及部署自訂或微調的 Hugging Face 模型的能力。它還提供最多 8 個 GPU 的靈活擴展(企業用戶可更多)、持續工作負載的透明且可預測定價,以及 99.5% SLA 的生產級可靠性。
部署步驟與使用指南
1. 進入控制台
- 登入你的 Novita AI 控制台。
- 在左側邊欄中,點擊 LLM 專用端點。
2. 建立新端點
- 點擊右上角的 + New Endpoint 按鈕。
3. 配置端點
填寫配置表單,包含以下選項:
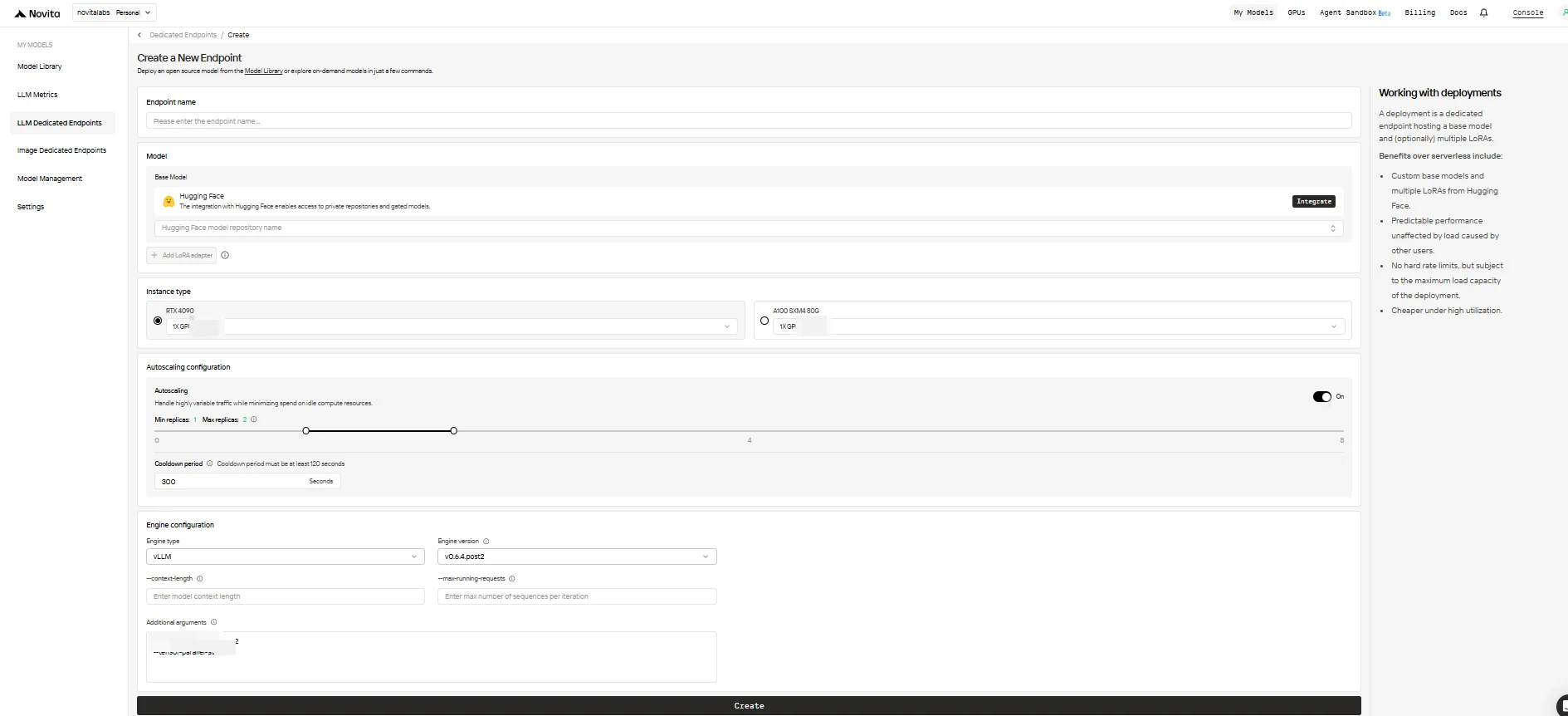
-
端點名稱: 為你的部署指定一個獨特且描述性的名稱。
-
基礎模型: 輸入基礎模型的 Hugging Face 儲存庫名稱(僅支援 Hugging Face 模型,包括公開、私有或受限制的模型)。
-
LoRA 適配器(可選): 新增一個或多個 Hugging Face 模型 ID,將 LoRA 適配器附加到基礎模型。
-
實例類型: 選擇 GPU 硬體(例如 H100、H200、RTX4090)。每個用戶在所有端點最多可使用 8 個 GPU。
-
自動擴展配置:
- 最小副本: 設為
0可讓端點在閒置時休眠(節省成本),或設定較高值以始終保持最小數量的活躍副本。 - 最大副本: 設定擴展時的最大副本數量(最多 10 個)。
- 冷卻時間: 設定縮減副本前的延遲時間(秒),避免在短暫流量下降時過早縮減。
- 最小副本: 設為
-
引擎配置:
- 引擎類型: 選擇推理引擎(
vLLM或SGLang)。 - 引擎版本: 使用預設(最新)或指定版本。
- 上下文長度: 可選設定最大 Token 上下文長度;若省略,則從模型配置中推導。
- 最大執行中請求: 設定每次迭代處理的最大序列數。
- 額外參數: 新增其他引擎參數以進行進階自訂。
- 引擎類型: 選擇推理引擎(
完成後,點擊 Create 部署端點。
4. 端點部署狀態
建立後,端點將經歷以下狀態:
- Sleeping: 端點閒置,不消耗運算資源(若最小副本設為 0)。
- Pending: 部署正在初始化。
- Rolling: 模型和基礎設施正在設定中。
- Running: 端點已啟用,準備好處理請求。
你可以在控制台的端點頁面上監控此狀態。
5. 在 Playground 測試端點
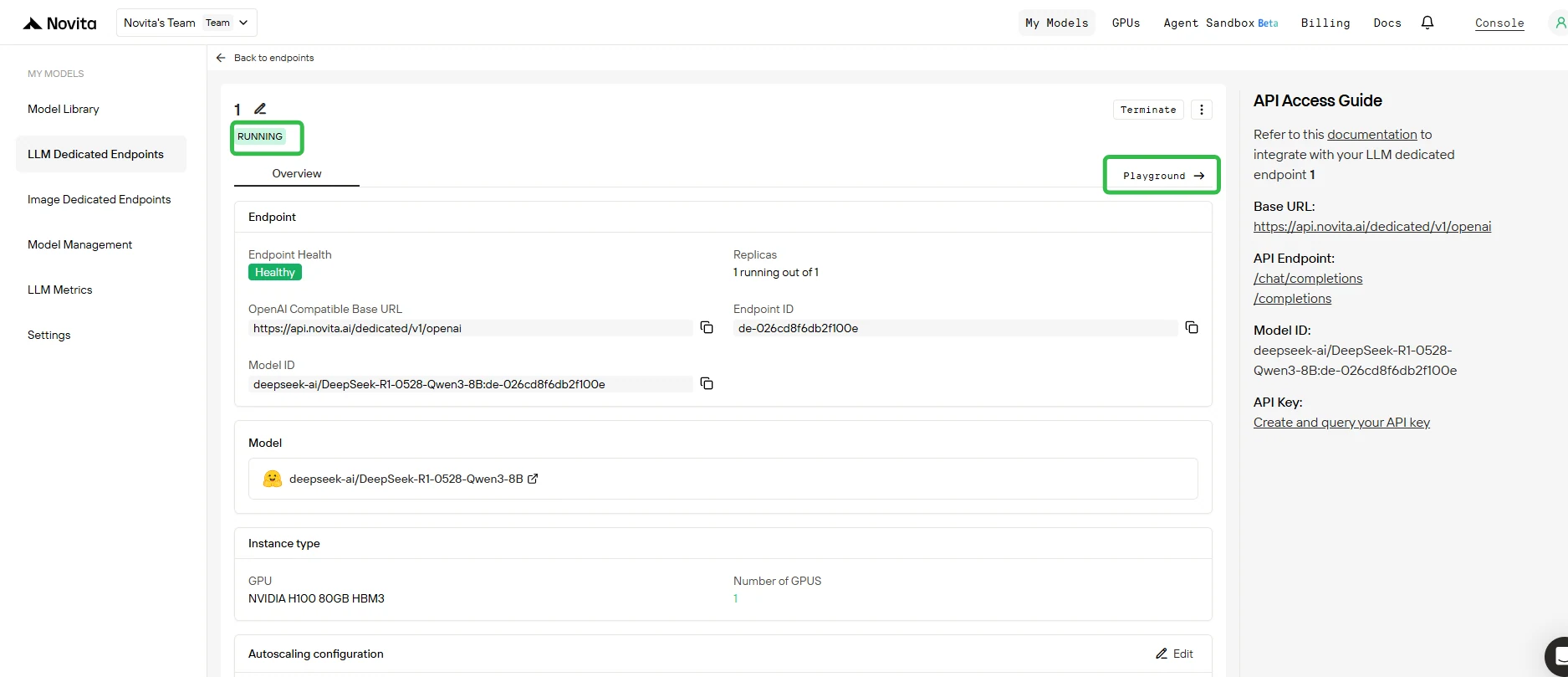
- 部署完成且狀態變為 Running 後,點擊端點並開啟 Playground 標籤。
- 在 Playground 中,你可以:
- 向基礎模型及附加的 LoRA 適配器發送測試提示。
- 即時比較不同適配器與基礎模型的輸出。
6. 後續步驟
- 多 LoRA 端點: 在單一端點上部署多個 LoRA 適配器,實現靈活的模型切換。
- API 整合: 使用提供的 API 端點發送請求,並將模型整合到你自己的應用程式中。
- 最佳化與擴展: 根據需求調整自動擴展、引擎配置和 GPU 配額。
- 需要更多資源? 若你需要超過 8 個 GPU 或需要企業級功能,請聯絡我們的銷售團隊以獲得企業解決方案。
程式碼範例(適用於 Python 使用者)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/dedicated/v1/openai",
api_key="<Your API Key>",
)
model = "deepseek-ai/DeepSeek-R1-0528-"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "you are a professional AI helper.",
},
{
"role": "user",
"content": "Where can the example of GPU provided by novita ai be adapted?",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
微調 DeepSeek R1 0528 能讓你充分發揮其在特定領域任務上的潛力,使其產出精確、可靠且客製化的輸出。透過利用 LoRA 適配器等高效技術,並在 Novita AI 等成本效益高的平台上部署,你可以降低費用同時實現高效能。無論你需要深層專業知識、嚴格的可靠性,還是獨特的個性,微調都能確保模型滿足你的特定需求。
常見問題
微調 DeepSeek R1 0528 的成本是多少?
建立自有基礎設施的估計成本約為 **589 萬美元 **。然而,使用 Novita AI 的雲端 GPU 能顯著降低前期成本,H100 GPU 每小時起價為 2.41 美元。
如何確保微調後的模型符合我的需求?
準備 乾淨且相關的資料集,並使用 **LoRA 適配器 ** 或 PEFT 方法 高效微調模型的特定層。這能確保高效能,同時避免過度擬合。
我可以在 Novita AI 上部署微調後的模型嗎?
可以。Novita AI 支援將微調後的模型部署為 專用端點,並提供自動擴展、多 LoRA 設定和 API 整合選項,讓你無縫整合到應用程式中。
Novita AI 是一個 AI 雲端平台,為開發者提供簡易的 API 來部署 AI 模型,同時也提供價格實惠且可靠的 GPU 雲端。



